 如何使用原生ClickHouse函数和表引擎在两个数据库之间迁移数据
如何使用原生ClickHouse函数和表引擎在两个数据库之间迁移数据
引言
这篇文章还是关于 ClickHouse 提供 Postgres 集成系列文章的一部分。在上一篇文章中,我们探讨了 Postgres 函数和表引擎,并以分析工作负载为例,演示了如何将事务数据从 Postgres 迁移到 ClickHouse。在这篇文章中,我们将展示如何结合使用 Postgres 数据与流行的 ClickHouse 字典功能来加速查询——特别是连接。在文章最后,我们将展示如何使用 Postgres 表引擎将分析查询的结果从 ClickHouse 推回 Postgres。当用户需要在终端用户应用程序中显示汇总数据,但又希望将统计数据的繁重计算工作卸载给 ClickHouse 时,就可以利用这种“反向 ETL”过程。
如果你想更深入地研究这些示例并重现它们,ClickHouse Cloud 是一个很好的起点——启动一个集群并获得 300 美元的免费额度,加载数据,处理下基础设施,然后进行查询!
对于本文的示例,我们还是只使用 ClickHouse Cloud 的一个开发实例。对于 Postgres 实例,我们还继续使用 Supabase,它提供的免费套餐已足够我们的示例使用。本文假设用户已经将英国房价数据集加载到 ClickHouse,这是上一篇博文中的一个步骤。数据集加载也可以不使用 Postgres,而是使用这里列出的步骤。
使用基于 Postgres 的词典
正如我们在之前的博文中重点介绍的那样,字典可以用来加速 ClickHouse 查询,特别是涉及连接的时候。考虑这样一个例子,我们的目标是找出英国在过去 20 年里价格变化最大的地区(根据 ISO 3166-2)。请注意,ISO 3166-2 编码不同于邮政编码,它代表的区域更大,但更重要的是,它在 Superset 这样的工具中可视化这类数据时非常有用。
在 JOIN 时,我们要使用一个邮政编码到区域编码的映射表,可以下载并加载到 codes 表中,如下所示。数据有 100 多万行,加载到 Supabase 免费实例大约需要一分钟。假设这份数据现在只在 Postgres 中,所以我们将在 Postgres 中连接这个数据来响应查询。
注意:ISO 3166-2 编码到邮政编码的映射表是从房价数据集生成的,并使用了 play.clickhouse.com 环境中的地区编码列表。虽然这个数据集可以满足我们的需求,但并不完整或详尽,仅涵盖房价数据集中的邮政编码。用于生成文件的查询可以从这里获取。
wget https://datasets-documentation.s3.amazonaws.com/uk-house-prices/postgres/uk_postcode_to_iso.sql psql -c "CREATE TABLE uk_postcode_to_iso ( id serial, postcode varchar(8) primary key, iso_code char(6) );" psql -c "CREATE INDEX ON uk_postcode_to_iso (iso_code);" psql < uk_postcode_to_iso.sql psql -c "select count(*) from uk_postcode_to_iso;" count --------- 1272836 (1 row) psql -c " iming" -c "SELECT iso_code, round(avg(((median_2022 - median_2002)/median_2002) * 100)) AS percent_change FROM ( SELECT postcode1 || ' ' || postcode2 AS postcode, PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY price) AS median_2002 FROM uk_price_paid WHERE extract(year from date) = '2002' GROUP BY postcode ) med_2002 INNER JOIN ( SELECT postcode1 || ' ' || postcode2 AS postcode, PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY price) AS median_2022 FROM uk_price_paid WHERE extract(year from date) = '2022' GROUP BY postcode ) med_2022 ON med_2002.postcode=med_2022.postcode INNER JOIN ( SELECT iso_code, postcode FROM uk_postcode_to_iso ) postcode_to_iso ON med_2022.postcode=postcode_to_iso.postcode GROUP BY iso_code ORDER BY percent_change DESC LIMIT 10;" Timing is on. iso_code | percent_change ----------+---------------- GB-TOF | 403 GB-KEC | 380 GB-MAN | 360 GB-SLF | 330 GB-BGW | 321 GB-HCK | 313 GB-MTY | 306 GB-AGY | 302 GB-RCT | 293 GB-BOL | 292 (10 rows) Time: 48523.927 ms (00:48.524)
这个查询相当复杂,比我们上一篇文章中的查询成本更高,上一篇文章只计算了伦敦房价变化最大的地区的邮政编码。虽然我们可以利用 EXTRACT(year FROM date 索引(就像这个执行计划里那样),但并没有机会用到城镇索引。
我们还可以将 ISO 代码数据加载到 ClickHouse 表中,重新连接,并根据需要调整语法。或者,我们可能会倾向于将映射留在 Postgres 中,因为其变化相当频繁。如果在 ClickHouse 中执行连接,将产生以下查询。注意一下,与使用 postgres 函数相比,我们如何使用 PostgreSQL 表引擎创建 uk_postcode_to_iso 来简化查询语法。
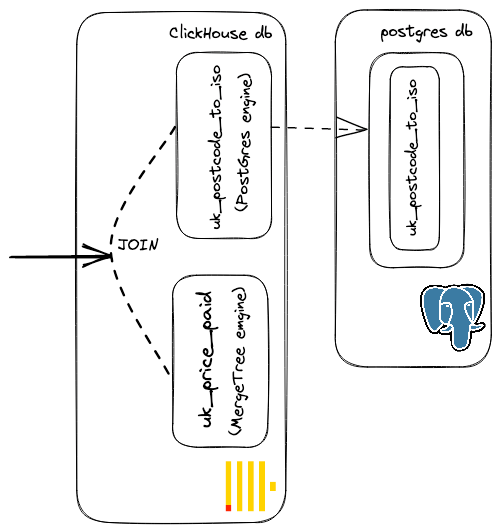
CREATE TABLE uk_postcode_to_iso AS postgresql('db.zcxfcrchxescrtxsnxuc.supabase.co', 'postgres', 'uk_postcode_to_iso', 'postgres', '')
SELECT
iso_code,
round(avg(percent_change)) AS avg_percent_change
FROM
(
SELECT
postcode,
medianIf(price, toYear(date) = 2002) AS median_2002,
medianIf(price, toYear(date) = 2022) AS median_2022,
((median_2022 - median_2002) / median_2002) * 100 AS percent_change
FROM uk_price_paid
GROUP BY concat(postcode1, ' ', postcode2) AS postcode
HAVING isNaN(percent_change) = 0
) AS med_by_postcode
INNER JOIN uk_postcode_to_iso ON uk_postcode_to_iso.postcode = med_by_postcode.postcode
GROUP BY iso_code
ORDER BY avg_percent_change DESC
LIMIT 10
┌─iso_code─┬─avg_percent_change─┐
│ GB-TOF │ 403 │
│ GB-KEC │ 380 │
│ GB-MAN │ 360 │
│ GB-SLF │ 330 │
│ GB-BGW │ 321 │
│ GB-HCK │ 313 │
│ GB-MTY │ 306 │
│ GB-AGY │ 302 │
│ GB-RCT │ 293 │
│ GB-BOL │ 292 │
└──────────┴────────────────────┘
10rowsinset.Elapsed:4.131sec.Processed29.01millionrows,305.27MB(7.02millionrows/s.,73.90MB/s.)
这并没有达到我们想要的效果。我们可以创建一个 PostgreSQL 支持的字典,而不是为映射创建一个 ClickHouse 表,如下所示:
CREATE DICTIONARY uk_postcode_to_iso_dict ( `postcode` String, `iso_code` String ) PRIMARY KEY postcode SOURCE(POSTGRESQL( port 5432 host 'db.ebsmckuuiwnvyiniuvdt.supabase.co' user 'postgres' password '' db 'postgres' table 'uk_postcode_to_iso' invalidate_query 'SELECT max(id) as mid FROM uk_postcode_to_iso' )) LIFETIME(300) LAYOUT(complex_key_hashed()) //force loading of dictionary SELECT dictGet('uk_postcode_to_iso_dict', 'iso_code', 'BA5 1PD') ┌─dictGet('uk_postcode_to_iso_dict', 'iso_code', 'BA5 1PD')─┐ │ GB-SOM │ └───────────────────────────────────────────────────────────┘ 1rowinset.Elapsed:0.885sec.
该字典将基于 LIFETIME 子句定期更新,并自动同步任何更改。在这种情况下,我们还定义了一个 invalidate_query 子句,它通过返回单个值来控制何时从数据源重新加载数据集。如果这个值发生变化,则重新加载字典——在这个例子中,是当最大 id 发生变化时。在生产场景中,我们可能会希望查询能够通过修改时间字段检测更新。
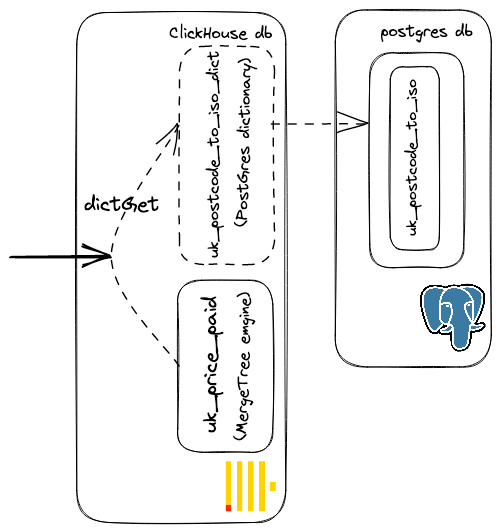
使用这个字典,我们现在可以修改查询,并利用表保存在本地内存中的事实进行快速查找。注意,我们也可以避免 join:
SELECT
iso_code,
round(avg(percent_change)) AS avg_percent_change
FROM
(
SELECT
dictGet('uk_postcode_to_iso_dict', 'iso_code', postcode) AS iso_code,
medianIf(price, toYear(date) = 2002) AS median_2002,
medianIf(price, toYear(date) = 2022) AS median_2022,
((median_2022 - median_2002) / median_2002) * 100 AS percent_change
FROM uk_price_paid
GROUP BY concat(postcode1, ' ', postcode2) AS postcode
HAVING isNaN(percent_change) = 0
)
GROUP BY iso_code
ORDER BY avg_percent_change DESC
LIMIT 10
┌─iso_code─┬─avg_percent_change─┐
│ GB-TOF │ 403 │
│ GB-KEC │ 380 │
│ GB-MAN │ 360 │
│ GB-SLF │ 330 │
│ GB-BGW │ 321 │
│ GB-HCK │ 313 │
│ GB-MTY │ 306 │
│ GB-AGY │ 302 │
│ GB-RCT │ 293 │
│ GB-BOL │ 292 │
└──────────┴────────────────────┘
10rowsinset.Elapsed:0.444sec.Processed27.73millionrows,319.84MB(62.47millionrows/s.,720.45MB/s.)
这样更好。感兴趣的话,可以在 Superset 等工具中将这些数据可视化,以便更好地理解这些 ISO 编码 —— 我们之前关于 Superset 的博文中提供了类似的例子。
将结果推回 Postgres
到目前为止,我们已经演示了将数据从 Postgres 迁移到 ClickHouse 用于分析工作负载的价值。如果将这个过程看成是一个 ETL 过程,那么在某些时候,我们可能会希望反转这个工作流,将分析结果加载回 Postgres 中。我们可以使用本系列之前的文章中介绍的表引擎来实现。
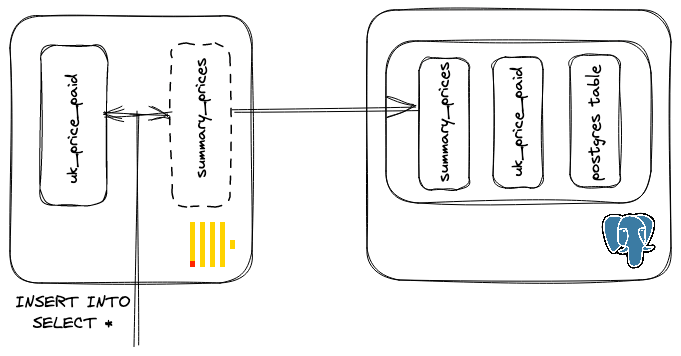
假设我们希望将每个月的销售统计数据汇总传回 Postgres,并按邮编、类型、是否是新房子,以及是永久产权还是租赁产权进行汇总。我们假想的网站将在列表的每一页上显示这些统计数据,帮助用户了解该地区的历史市场状况。此外,他们希望能够随着时间的推移显示这些统计数据。为了降低 Postgres 生产实例的负载,他们将计算过程卸载给 ClickHouse,并定期将结果推回汇总表。
实际上,这不是一个特别重的查询,可以在 Postgres 中调度。
下面,在创建表并插入分析查询的结果之前,我们创建了一个由 Postgres 支持的 ClickHouse 数据库。
CREATE TABLE summary_prices(
postcode1 varchar(8),
type varchar(13),
is_new SMALLINT,
duration varchar(9),
sold integer,
month Date,
avg_price integer,
quantile_prices integer[]);
// create Postgres engine table in ClickHouse
CREATE TABLE summary_prices AS postgresql('db.zcxfcrchxescrtxsnxuc.supabase.co', 'postgres', 'summary_prices', 'postgres', '')
//check connectivity
SELECT count()
FROM summary_prices
┌─count()─┐
│ 0 │
└─────────┘
1 row in set. Elapsed: 0.337 sec.
// insert the result of our query to Postgres
INSERT INTO summary_prices SELECT
postcode1,
type,
is_new,
duration,
count() AS sold,
month,
avg(price) AS avg_price,
quantilesExactExclusive(0.25, 0.5, 0.75, 0.9, 0.95, 0.99)(price) AS quantile_prices
FROM uk_price_paid
WHERE postcode1 != ''
GROUP BY
toStartOfMonth(date) AS month,
postcode1,
type,
is_new,
duration
ORDER BY
postcode1 ASC,
type ASC,
is_new ASC,
duration ASC,
month ASC
0rowsinset.Elapsed:25.714sec.Processed27.69millionrows,276.98MB(775.43thousandrows/s.,7.76MB/s.)
现在,我们的站点可以运行一个简单的查询,获取一个区域中同一类型的房屋的历史价格统计。
postgres=> SELECT postcode1, month, avg_price, quantile_prices FROM summary_prices WHERE postcode1='BA5' AND type='detached' AND is_new=0 and duration='freehold' LIMIT 10;
postcode1 | month | avg_price | quantile_prices
-----------+------------+-----------+--------------------------------------------
BA5 | 1995-01-01 | 108000 | {64000,100000,160000,160000,160000,160000}
BA5 | 1995-02-01 | 95142 | {86500,100000,115000,130000,130000,130000}
BA5 | 1995-03-01 | 138991 | {89487,95500,174750,354000,354000,354000}
BA5 | 1995-04-01 | 91400 | {63750,69500,130000,165000,165000,165000}
BA5 | 1995-05-01 | 110625 | {83500,94500,149750,170000,170000,170000}
BA5 | 1995-06-01 | 124583 | {79375,118500,173750,185000,185000,185000}
BA5 | 1995-07-01 | 126375 | {88250,95500,185375,272500,272500,272500}
BA5 | 1995-08-01 | 104416 | {67500,95000,129750,200000,200000,200000}
BA5 | 1995-09-01 | 103000 | {70000,97000,143500,146000,146000,146000}
BA5 | 1995-10-01 | 90800 | {58375,72250,111250,213700,223000,223000}
(10rows)
小结
在本系列文章中,我们展示了 ClickHouse 和 Postgres 的互补性,并通过示例演示了如何使用原生 ClickHouse 函数和表引擎轻松地在两个数据库之间迁移数据。在这篇文章中,我们介绍了基于 Postgres 的字典,以及如何使用它来加速涉及频繁变化数据集的查询的连接。最后,我们执行了一个“反向 ETL”操作,将分析查询的结果推回 Postgres,供可能面向用户的应用程序使用。
-
数据库
+关注
关注
7文章
3795浏览量
64364 -
网站
+关注
关注
2文章
258浏览量
23157 -
函数
+关注
关注
3文章
4329浏览量
62575
原文标题:ClickHouse和PostgreSQL:“数据天堂”中的好搭档
文章出处:【微信号:AI前线,微信公众号:AI前线】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
正被别的用户或进程使用,数据库引擎无法锁定它。如何解决
ICDE:POLARDB定义云原生数据库
重新定义数据库的时刻,阿里云数据库专家带你了解POLARDB
云栖干货回顾 | 云原生数据库POLARDB专场“硬核”解析
Centos7下如何搭建ClickHouse列式存储数据库
数据库引擎及底层实现原理
常用的数据库引擎有哪些_数据库引擎分类

关系型数据库表结构的设计有什么技巧?两个设计技巧详细说明

ClickHouse列式存储数据库的性能特性及底层存储原理
华为云云原生数据库,激发数据活力
使用可计算SSD加速云原生数据库
传感器之外—两个数据库之间的“连接”查询





 工商网监
工商网监
评论