 使用LabVIEW实现 DeepLabv3+ 语义分割含源码
使用LabVIEW实现 DeepLabv3+ 语义分割含源码
前言
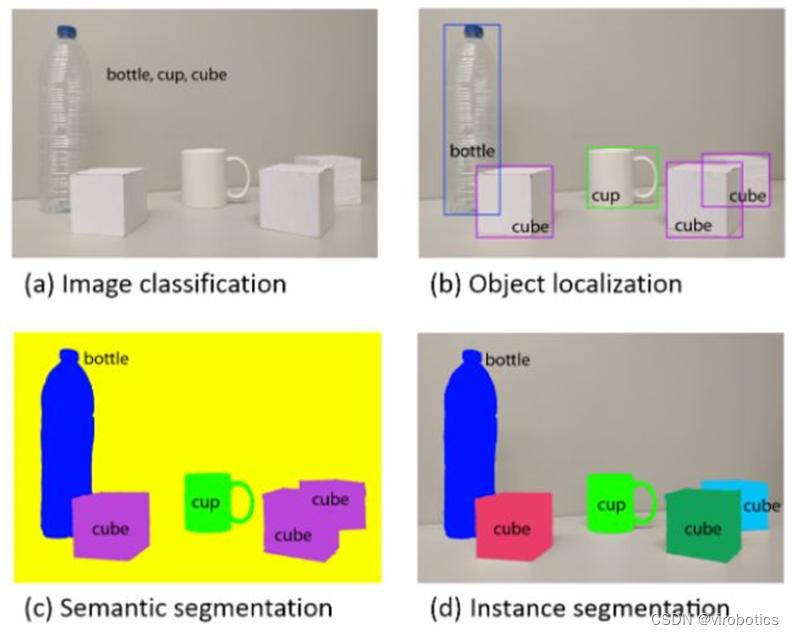
图像分割可以分为两类:语义分割(Semantic Segmentation)和实例分割(Instance Segmentation),前面已经给大家介绍过两者的区别,并就如何在labview上实现相关模型的部署也给大家做了讲解,今天和大家分享如何使用labview 实现deeplabv3+的语义分割,并就 Pascal VOC2012 (DeepLabv3Plus-MobileNet) 上的分割结果和城市景观的分割结果(DeepLabv3Plus-MobileNet)给大家做一个分享。
一、什么是deeplabv3+
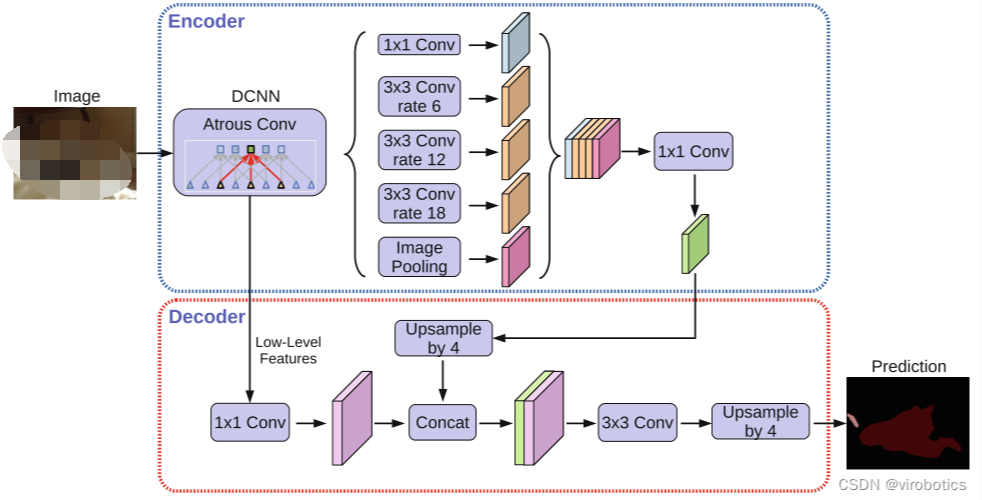
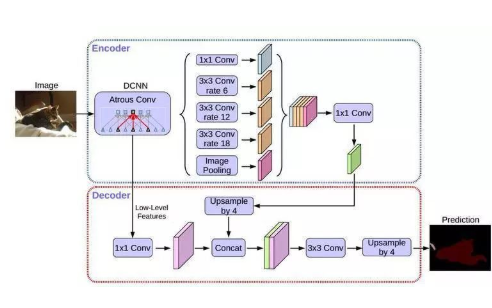
Deeplabv3+是一个语义分割网络,使用DeepLabv3作为Encoder模块,并添加一个简单且有效的Decoder模块来获得更清晰的分割。即网络主要分为两个部分:Encoder和Decoder;论文中采用的是Xception作为主干网络(在代码中也可以根据需求替换成MobileNet,本文示例中即使用的MobileNet),然后使用了ASPP结构,解决多尺度问题;为了将底层特征与高层特征融合,提高分割边界准确度,引入Decoder部分。
Encoder-Decoder网络已经成功应用于许多计算机视觉任务,通常,Encoder-Decoder网络包含:
- 逐步减少特征图并提取更高语义信息的Encoder模块
- 逐步恢复空间信息的Decoder模块
二、LabVIEW调用DeepLabv3+实现图像语义分割
1、模型获取及转换
-
下载预训练好的.pth模型文件,下载链接:https://share.weiyun.com/qqx78Pv5 ,我们选择主干网络为Mobilenet的模型
-
git上下载开源的整个项目文件,链接为:https://github.com/VainF/DeepLabV3Plus-Pytorch
-
根据requirements.txt 安装所需要的库

pip install -r requirements.txt
- 原项目中使用的模型为.pth,我们将其转onnx模型,
- 将best_deeplabv3plus_mobilenet_voc_os16.pth转化为deeplabv3plus_mobilenet.onnx,具体转化模型代码如下:
import network
import numpy as np
import torch
from torch.autograd import Variable
from torchvision import models
import os
import re
dirname, filename = os.path.split(os.path.abspath(__file__))
print(dirname)
def get_pytorch_onnx_model(original_model):
# define the directory for further converted model save
onnx_model_path = dirname
# define the name of further converted model
onnx_model_name = "deeplabv3plus_mobilenet.onnx"
# create directory for further converted model
os.makedirs(onnx_model_path, exist_ok=True)
# get full path to the converted model
full_model_path = os.path.join(onnx_model_path, onnx_model_name)
# generate model input
generated_input = Variable(
torch.randn(1, 3, 513, 513)
)
# model export into ONNX format
torch.onnx.export(
original_model,
generated_input,
full_model_path,
verbose=True,
input_names=["input"],
output_names=["output"],
opset_version=11
)
return full_model_path
model = network.modeling.__dict__["deeplabv3plus_mobilenet"](num_classes=21, output_stride=8)
checkpoint = torch.load("best_deeplabv3plus_mobilenet_voc_os16.pth", map_location=torch.device('cpu'))
model.load_state_dict(checkpoint["model_state"])
full_model_path = get_pytorch_onnx_model(model)
- 将best_deeplabv3plus_mobilenet_cityscapes_os16.pth转化为deeplabv3plus_mobilenet_cityscapes.onnx,具体转化模型代码如下:
import network
import numpy as np
import torch
from torch.autograd import Variable
from torchvision import models
import os
import re
dirname, filename = os.path.split(os.path.abspath(__file__))
print(dirname)
def get_pytorch_onnx_model(original_model):
# define the directory for further converted model save
onnx_model_path = dirname
# define the name of further converted model
onnx_model_name = "deeplabv3plus_mobilenet_cityscapes.onnx"
# create directory for further converted model
os.makedirs(onnx_model_path, exist_ok=True)
# get full path to the converted model
full_model_path = os.path.join(onnx_model_path, onnx_model_name)
# generate model input
generated_input = Variable(
torch.randn(1, 3, 513, 513)
)
# model export into ONNX format
torch.onnx.export(
original_model,
generated_input,
full_model_path,
verbose=True,
input_names=["input"],
output_names=["output"],
opset_version=11
)
return full_model_path
model = network.modeling.__dict__["deeplabv3plus_mobilenet"](num_classes=19, output_stride=8)
checkpoint = torch.load("best_deeplabv3plus_mobilenet_cityscapes_os16.pth", map_location=torch.device('cpu'))
model.load_state_dict(checkpoint["model_state"])
full_model_path = get_pytorch_onnx_model(model)
注意:我们需要将以上两个脚本保存并与network文件夹同路径
2、LabVIEW 调用基于 Pascal VOC2012训练的deeplabv3+实现图像语义分割 (deeplabv3+_onnx.vi)
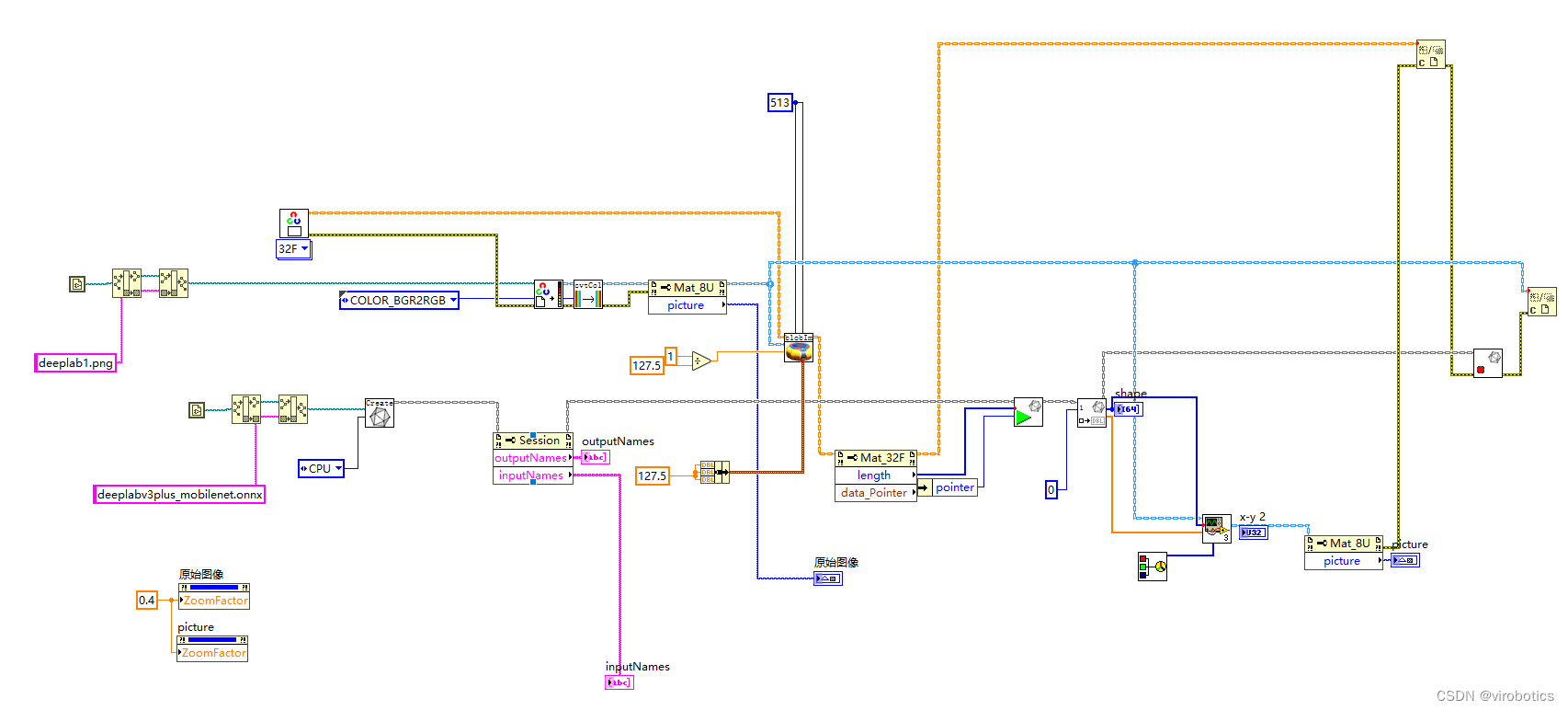
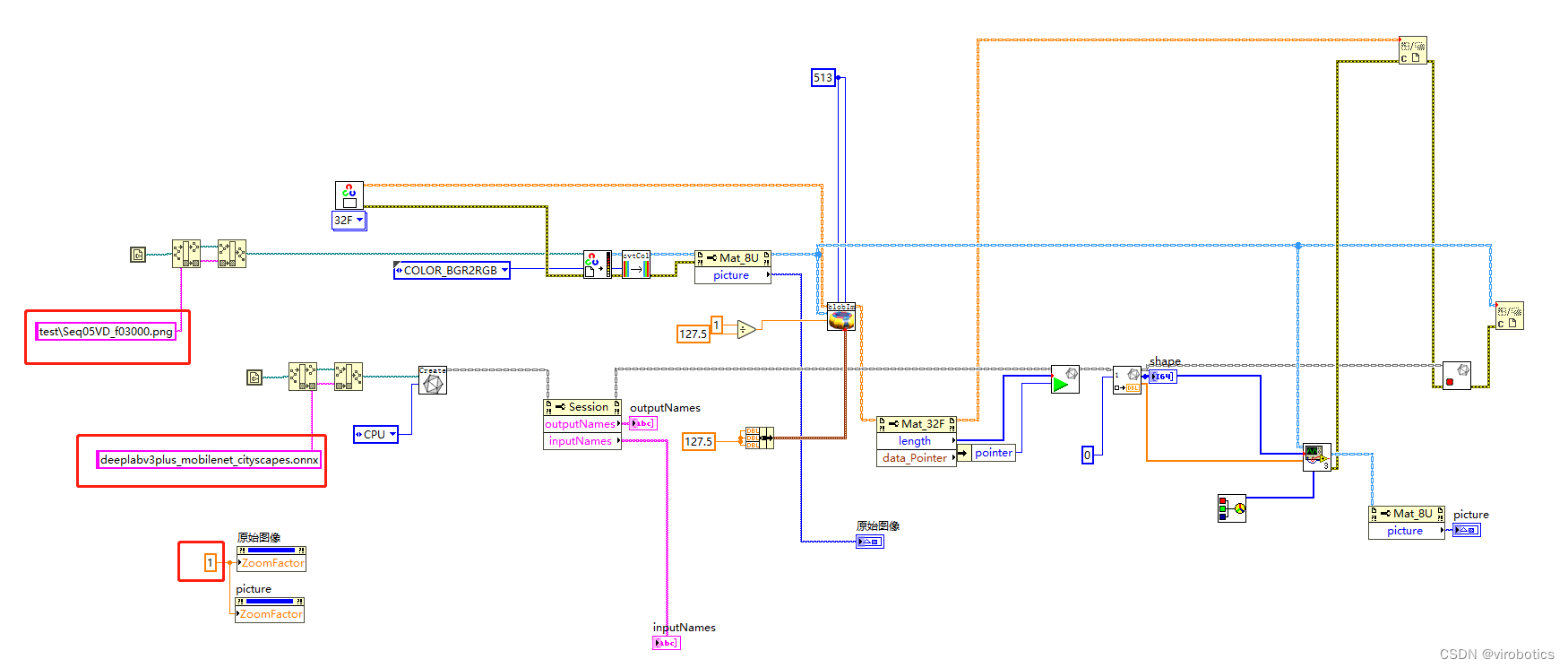
经过实验发现,opencv dnn因缺少一些算子,所以无法加载deeplabv3+ onnx模型,所以我们选择使用LabVIEW开放神经网络交互工具包【ONNX】来加载并推理整个模型,实现语义分割,程序源码如下:
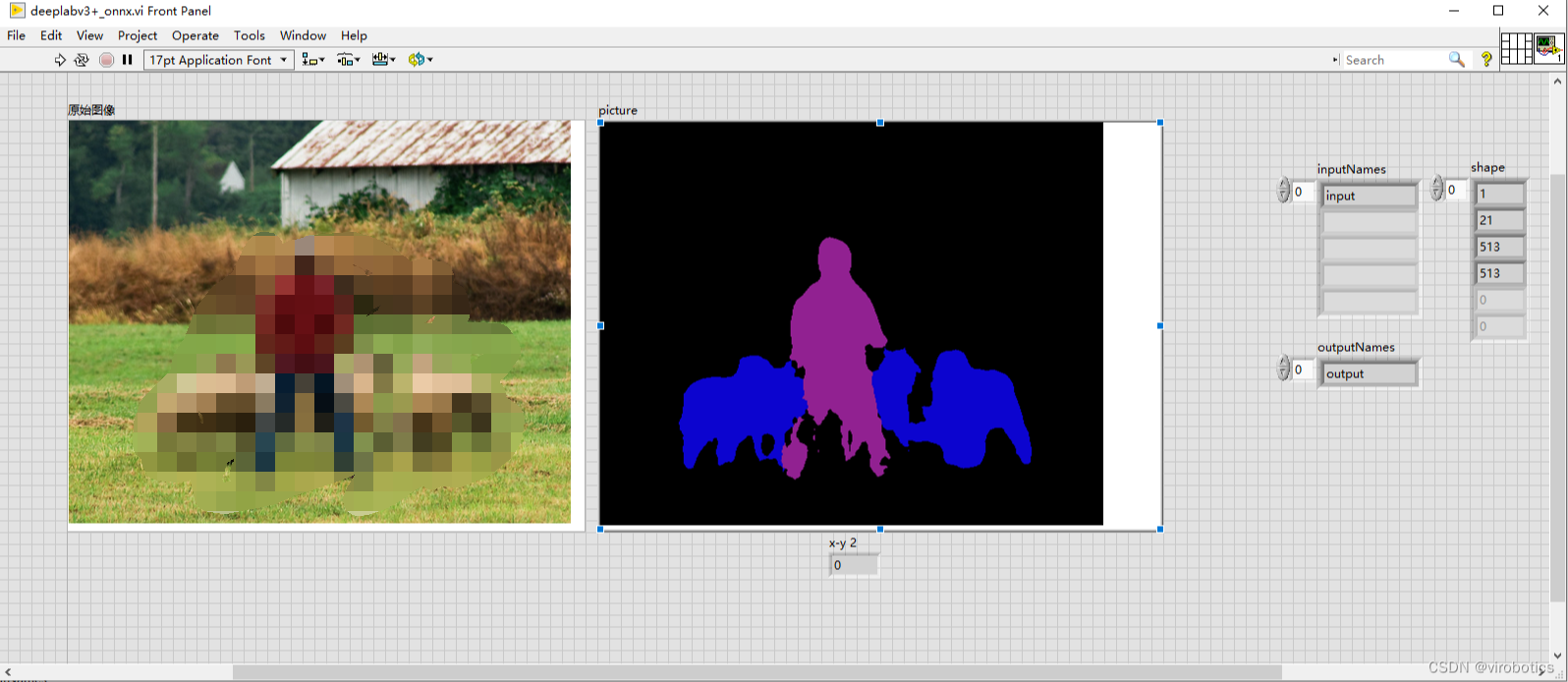
3、LabVIEW Pascal VOC2012上的分割结果(deeplabv3+_onnx.vi)
4、LabVIEW 调用基于 Cityscapes 训练的deeplabv3+实现图像语义分割 (deeplabv3+_onnx_cityscape.vi)
如下图所示即为程序源码,我们对比deeplabv3+_onnx.vi,发现其实只需要把模型和待检测的图片更换,图片尺寸比例也做一个修改即可
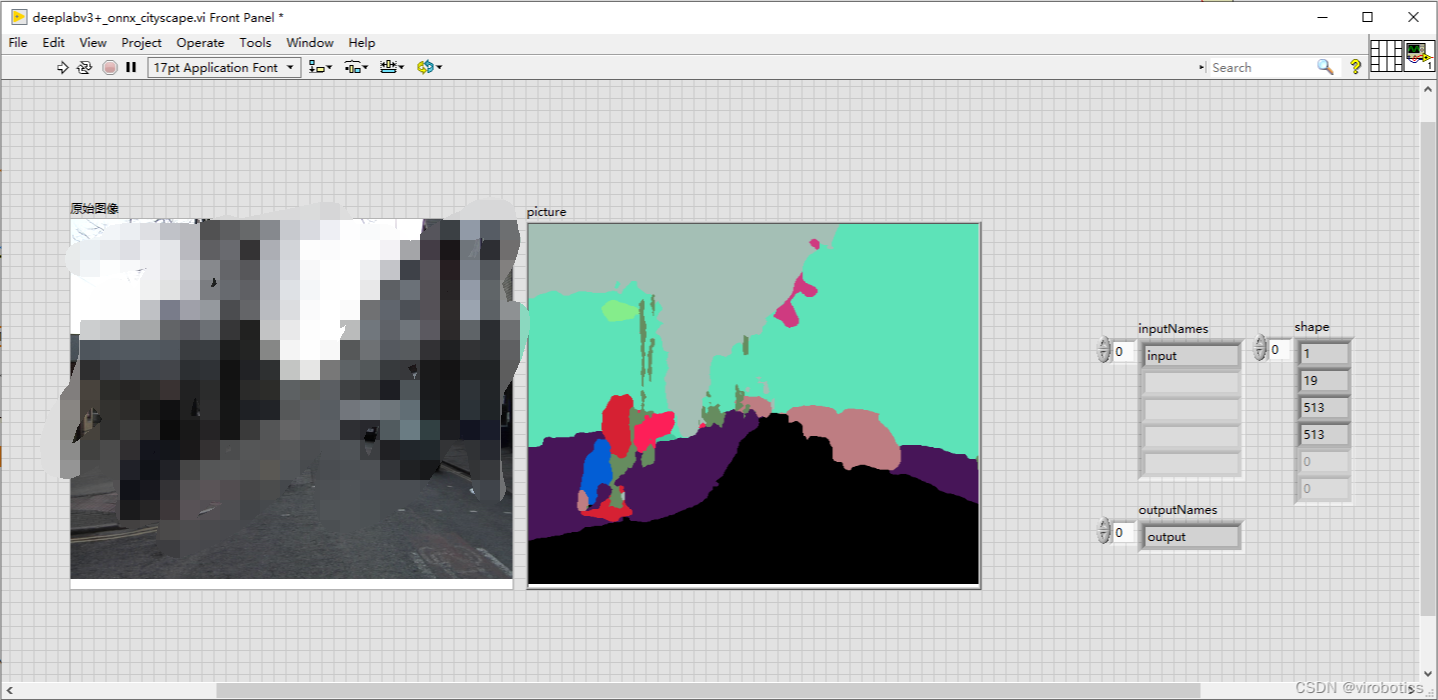
5、LabVIEW 城市景观的分割结果(deeplabv3+_onnx_cityscape.vi)
如您想要探讨更多关于LabVIEW与人工智能威廉希尔官方网站 ,欢迎加入我们的威廉希尔官方网站 交流群:705637299
三、项目源码及模型下载
欢迎关注微信公众号: VIRobotics ,回复关键字:deepLabv3+ 语义分割源码 获取本次分享内容的完整项目源码及模型。
附加说明
操作系统:Windows10
python:3.6及以上
LabVIEW:2018及以上 64位版本
视觉工具包:techforce_lib_opencv_cpu-1.0.0.73.vip
LabVIEW开放神经网络交互工具包【ONNX】:virobotics_lib_onnx_cpu-1.0.0.13.vip
总结
以上就是今天要给大家分享的内容。如果有问题可以在评论区里讨论。
审核编辑 黄宇
-
LabVIEW
+关注
关注
1971文章
3654浏览量
323491 -
人工智能
+关注
关注
1791文章
47244浏览量
238378 -
图像分割
+关注
关注
4文章
182浏览量
17999
发布评论请先 登录
相关推荐

van-自然和医学图像的深度语义分割:网络结构
van-自然和医学图像的深度语义分割:网络结构
聚焦语义分割任务,如何用卷积神经网络处理语义图像分割?
DeepLab进行语义分割的研究分析
分析总结基于深度神经网络的图像语义分割方法

一种改进DeepLabv3+网络的肠道息肉分割方法

基于深度学习的遥感影像典型要素提取方法
基于图像语义分割的毛笔笔触实时生成威廉希尔官方网站
使用OpenVINO™ 部署PaddleSeg模型库中的DeepLabV3+模型

轻松学Pytorch之Deeplabv3推理
图像分割与语义分割中的CNN模型综述
图像语义分割的实用性是什么
常见人体姿态评估显示方式的两种方式





 工商网监
工商网监
评论