 可商用多语言聊天LLM开源,性能直逼GPT-4
可商用多语言聊天LLM开源,性能直逼GPT-4
SambaNova 与 Together 两家公司合作开源了可商用的 BLOOMChat,一个 1760 亿参数的多语言聊天大语言模型 (LLM)。由 BLOOM (176B) 在助理式的对话数据集上进行指导调整,并支持多种语言的对话、问题回答和生成性答案。
根据介绍,BLOOMChat 是一个新的、开放的、多语言的聊天 LLM。SambaNova 和 Together 使用 SambaNova 独特的可重构数据流架构在 SambaNova DataScale 系统上训练了 BLOOMChat;其建立在 BigScience 组织的 BLOOM 之上,并在 OpenChatKit、Dolly 2.0 和 OASST1 的 OIG 上进行了微调。目前,BLOOM 已经是最大的多语言开放模型,在 46 种语言上进行了训练。
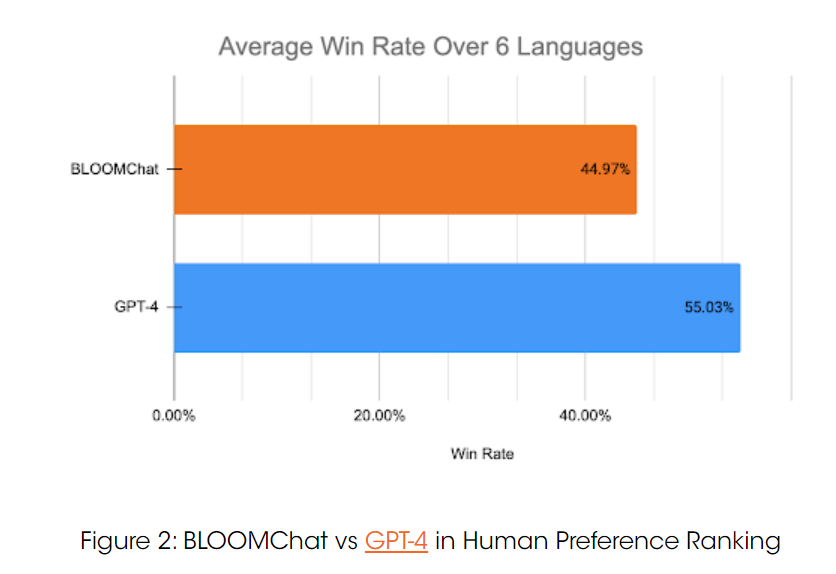
在针对英语、中文、法语、阿拉伯语、西班牙语、印度语这 6 种语言的评测中,GPT-4 的胜率为 54.75%,BLOOMChat 的胜率为 45.25%,稍弱于 GPT-4。但与其它 4 种主流的开源聊天 LLM 相比,BLOOMChat 在 65.92% 的时间内表现更优。且在使用 BLOOMChat 进行跨语言 NLP 任务的初步研究中,BLOOMChat 在 WMT 翻译基准中的表现要优于其他 BLOOM 变体和主流开源聊天模型。
“我们确实想指出,与我们比较的这些模型中,有些并不适合多语言环境。但由于开源社区中没有替代品,所以才有了现在的比较。我们的研究结果表明,使用正确的威廉希尔官方网站 ,可以在开源 LLM 之上构建以实现强大的多语言聊天功能。我们希望我们的研究结果和 BLOOMChat checkpoint 的发布能够为开源社区的持续讨论做出贡献,并激发 LLM 领域的进一步发展。”
项目团队使用定性和定量措施来评估了 BLOOMChat 的多语言聊天能力以及跨语言任务能力。共做了 3 种不同场景的实验测评,评测了英语、中文、阿拉伯语、法语、西班牙语和印度语。
实验一:人类偏好排序
旨在将 BLOOMChat 模型在多种语言中的聊天能力与现有的开源模型以及选定的封闭源模型进行比较。使用了 “OpenAssistant Conversations”附录 E 中的 22 个英文问题作为基准。首先让一些人类志愿者将这 22 个英文问题手动翻译成他们各自的母语;然后让另一组不同的志愿者,在匿名的前提下评价每个模型所给出的回答。
将 BLOOMChat 与 OpenAssistant-30B、LLaMA-Adapter-V2-65B 和 BLOOMZ (176B) 三种开源模型进行了比较:
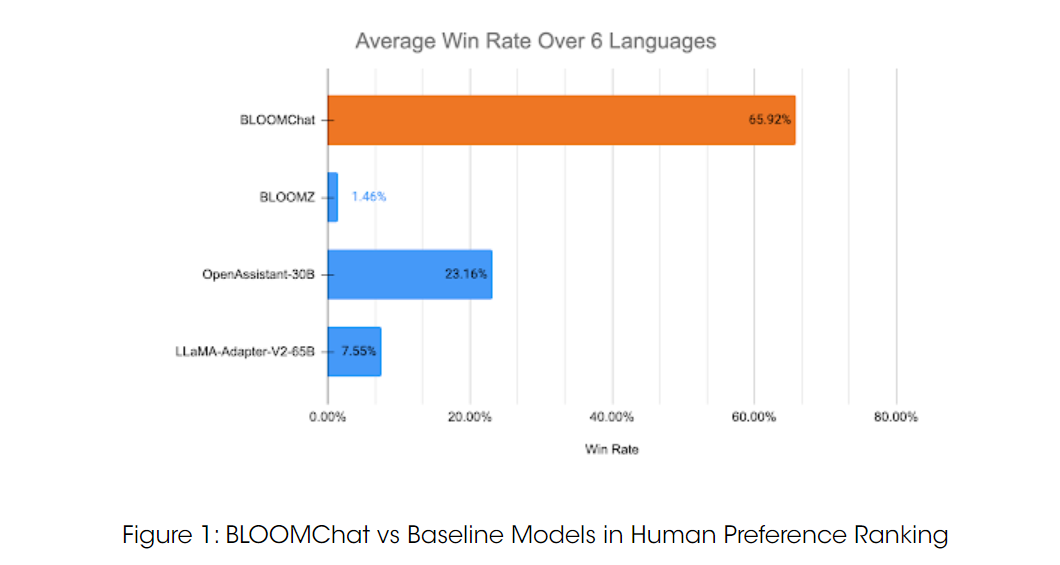
51 名志愿者在所有模型和 6 种语言中共提交了 1158 次比较。如上图所示,BLOOMChat (65.92%) 明显优于其它几个开源模型。
与GPT-4 相比:
实验二:模型质量评估
此实验旨在验证 BLOOMChat 生成的多种语言文本的质量。
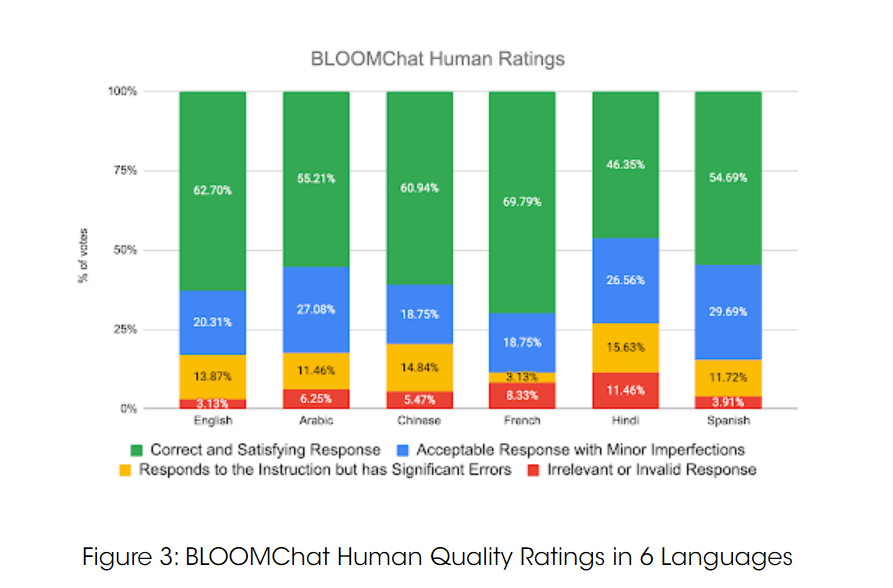
81.8% 的回答被归类为 “正确” 或 “可接受但有轻微缺陷”。尽管只在英语数据集上进行了微调,但 BLOOMChat 在每种语言中都获得了超过 70% 的 “正确” 或 “可接受” 评级。
实验三:WMT 翻译任务
为了初步了解模型解决跨语言 NLP 任务的能力,评估了模型在 WMT 翻译任务上的翻译能力。
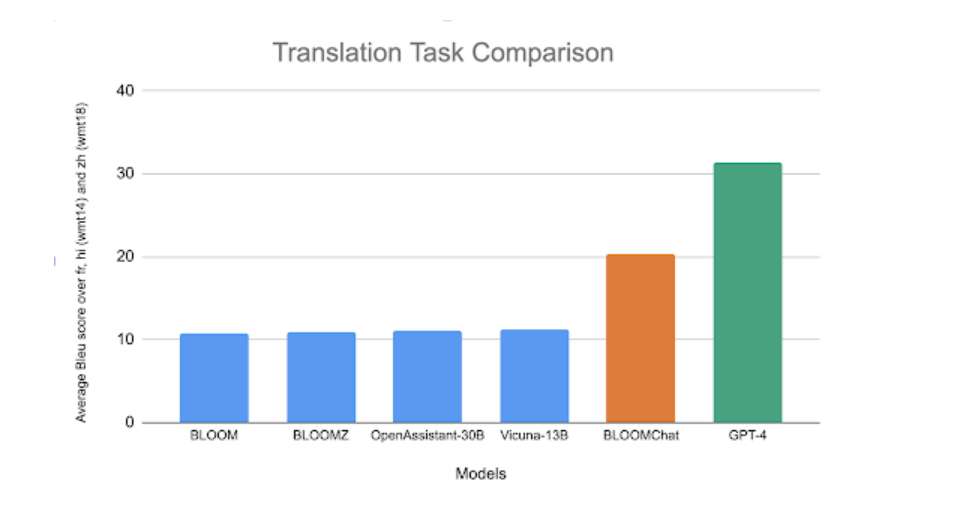
总体而言,BLOOMChat 在翻译任务中的表现明显优于其他 BLOOM 变体和开源聊天模型,但和 GPT-4 还有一定差距。
此外,BLOOMChat 团队也坦承了一些该模型的局限性:
BLOOMChat 有时可能会生成听起来合理但事实不正确或与主题无关的回复信息。
BLOOMChat 可能在单个回复中无意间切换语言,影响输出的连贯性和可理解性。
BLOOMChat 可能会产生重复的短语或句子,导致回复内容缺乏吸引力和有效信息。
BLOOMChat 在生成代码或解决复杂数学问题方面的性能可能会受到限制。
BLOOMChat 可能无意中生成含有不适当或有害内容的回复。
审核编辑 :李倩
-
开源
+关注
关注
3文章
3333浏览量
42477 -
语言模型
+关注
关注
0文章
522浏览量
10271 -
数据集
+关注
关注
4文章
1208浏览量
24692 -
LLM
+关注
关注
0文章
286浏览量
327
原文标题:可商用多语言聊天LLM开源,性能直逼GPT-4
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Llama 3 与 GPT-4 比较
ChatGPT 的多语言支持特点
llm模型和chatGPT的区别
OpenAI推出新模型CriticGPT,用GPT-4自我纠错
OpenAI API Key获取:开发人员申请GPT-4 API Key教程
开发者如何调用OpenAI的GPT-4o API以及价格详情指南
阿里云正式发布通义千问2.5,中文性能全面赶超GPT-4 Turbo
阿里云发布通义千问2.5大模型,多项能力超越GPT-4
微软Copilot全面更新为OpenAI的GPT-4 Turbo模型
大语言模型(LLMs)如何处理多语言输入问题

新火种AI|秒杀GPT-4,狙杀GPT-5,横空出世的Claude 3振奋人心!






 工商网监
工商网监
评论