 简述linux系统UDP丢包问题分析思路(下)
简述linux系统UDP丢包问题分析思路(下)
防火墙
如果系统防火墙丢包,表现的行为一般是所有的 UDP 报文都无法正常接收,当然不排除防火墙只 drop 一部分报文的可能性。
如果遇到丢包比率非常大的情况,请先检查防火墙规则,保证防火墙没有主动 drop UDP 报文。
UDP buffer size 不足
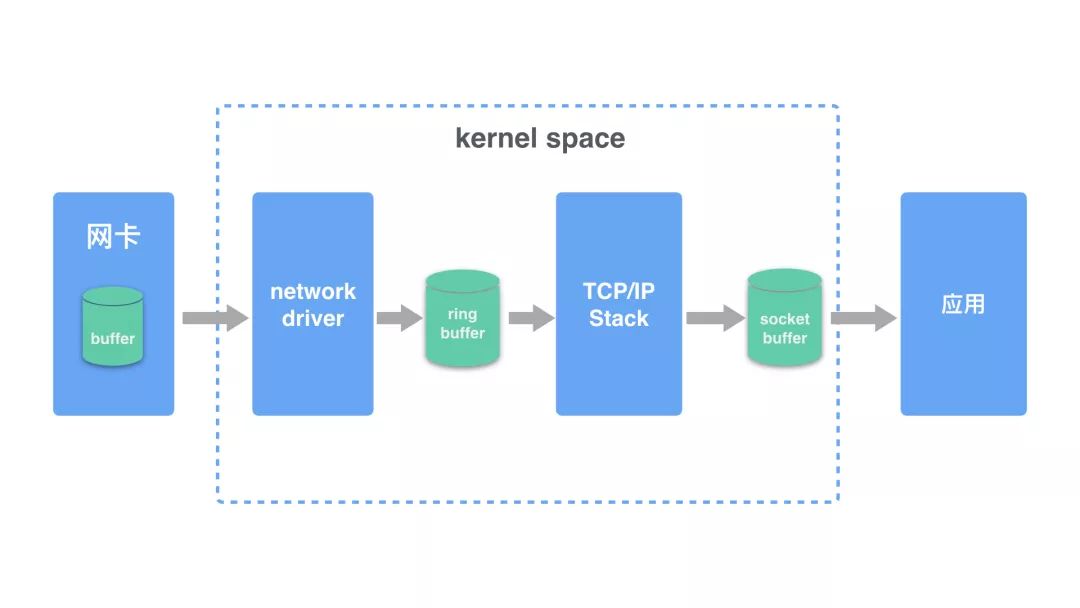
linux 系统在接收报文之后,会把报文保存到缓存区中。因为缓存区的大小是有限的,如果出现 UDP 报文过大(超过缓存区大小或者 MTU 大小)、接收到报文的速率太快,都可能导致 linux 因为缓存满而直接丢包的情况。
在系统层面,linux 设置了 receive buffer 可以配置的最大值,可以在下面的文件中查看,一般是 linux 在启动的时候会根据内存大小设置一个初始值。
- /proc/sys/net/core/rmem_max:允许设置的 receive buffer 最大值
- /proc/sys/net/core/rmem_default:默认使用的 receive buffer 值
- /proc/sys/net/core/wmem_max:允许设置的 send buffer 最大值
- /proc/sys/net/core/wmem_dafault:默认使用的 send buffer 最大值
但是这些初始值并不是为了应对大流量的 UDP 报文,如果应用程序接收和发送 UDP 报文非常多,需要讲这个值调大。可以使用 sysctl 命令让它立即生效:
sysctl -w net.core.rmem_max=26214400 # 设置为 25M也可以修改 /etc/sysctl.conf 中对应的参数在下次启动时让参数保持生效。
如果报文报文过大,可以在发送方对数据进行分割,保证每个报文的大小在 MTU 内。
另外一个可以配置的参数是 netdev_max_backlog,它表示 linux 内核从网卡驱动中读取报文后可以缓存的报文数量,默认是 1000,可以调大这个值,比如设置成 2000:
sudo sysctl -w net.core.netdev_max_backlog=2000系统负载过高
系统 CPU、memory、IO 负载过高都有可能导致网络丢包,比如 CPU 如果负载过高,系统没有时间进行报文的 checksum 计算、复制内存等操作,从而导致网卡或者 socket buffer 出丢包;memory 负载过高,会应用程序处理过慢,无法及时处理报文;IO 负载过高,CPU 都用来响应 IO wait,没有时间处理缓存中的 UDP 报文。
linux 系统本身就是相互关联的系统,任何一个组件出现问题都有可能影响到其他组件的正常运行。对于系统负载过高,要么是应用程序有问题,要么是系统不足。对于前者需要及时发现,debug 和修复;对于后者,也要及时发现并扩容。
应用丢包
上面提到系统的 UDP buffer size,调节的 sysctl 参数只是系统允许的最大值,每个应用程序在创建 socket 时需要设置自己 socket buffer size 的值。
linux 系统会把接受到的报文放到 socket 的 buffer 中,应用程序从 buffer 中不断地读取报文。所以这里有两个和应用有关的因素会影响是否会丢包:socket buffer size 大小以及应用程序读取报文的速度。
对于第一个问题,可以在应用程序初始化 socket 的时候设置 socket receive buffer 的大小,比如下面的代码把 socket buffer 设置为 20MB:
uint64_t receive_buf_size = 20*1024*1024; //20 MBsetsockopt(socket_fd, SOL_SOCKET, SO_RCVBUF, &receive_buf_size, sizeof(receive_buf_size));如果不是自己编写和维护的程序,修改应用代码是件不好甚至不太可能的事情。很多应用程序会提供配置参数来调节这个值,请参考对应的官方文档;如果没有可用的配置参数,只能给程序的开发者提 issue 了。
很明显,增加应用的 receive buffer 会减少丢包的可能性,但同时会导致应用使用更多的内存,所以需要谨慎使用。
另外一个因素是应用读取 buffer 中报文的速度,对于应用程序来说,处理报文应该采取异步的方式
包丢在什么地方
想要详细了解 linux 系统在执行哪个函数时丢包的话,可以使用 dropwatch 工具,它监听系统丢包信息,并打印出丢包发生的函数地址:
# dropwatch -l kasInitalizing kallsyms dbstartEnabling monitoring...Kernel monitoring activated.Issue Ctrl-C to stop monitoring
1 drops at tcp_v4_do_rcv+cd (0xffffffff81799bad)10 drops at tcp_v4_rcv+80 (0xffffffff8179a620)1 drops at sk_stream_kill_queues+57 (0xffffffff81729ca7)4 drops at unix_release_sock+20e (0xffffffff817dc94e)1 drops at igmp_rcv+e1 (0xffffffff817b4c41)1 drops at igmp_rcv+e1 (0xffffffff817b4c41)通过这些信息,找到对应的内核代码处,就能知道内核在哪个步骤中把报文丢弃,以及大致的丢包原因。
此外,还可以使用 linux perf 工具监听 kfree_skb(把网络报文丢弃时会调用该函数) 事件的发生:
sudo perf record -g -a -e skb:kfree_skbsudo perf script关于 perf 命令的使用和解读,网上有很多文章可以参考。
总结
- UDP 本身就是无连接不可靠的协议,适用于报文偶尔丢失也不影响程序状态的场景,比如视频、音频、游戏、监控等。对报文可靠性要求比较高的应用不要使用 UDP,推荐直接使用 TCP。当然,也可以在应用层做重试、去重保证可靠性
- 如果发现服务器丢包,首先通过监控查看系统负载是否过高,先想办法把负载降低再看丢包问题是否消失
- 如果系统负载过高,UDP 丢包是没有有效解决方案的。如果是应用异常导致 CPU、memory、IO 过高,请及时定位异常应用并修复;如果是资源不够,监控应该能及时发现并快速扩容
- 对于系统大量接收或者发送 UDP 报文的,可以通过调节系统和程序的 socket buffer size 来降低丢包的概率
- 应用程序在处理 UDP 报文时,要采用异步方式,在两次接收报文之间不要有太多的处理逻辑
参考资料
- Pivotal: Network troubleshooting guide
- What are udp “packet receive errors” and “packets to unknown port received”
- Lost multicast packets troubleshooting guide
- splunk Answers: UDP Drops on Linux
作者:吴伟
原文:
https://cizixs.com/2018/01/13/linux-udp-packet-drop-debug/
-
cpu
+关注
关注
68文章
10855浏览量
211611 -
TCP
+关注
关注
8文章
1353浏览量
79059 -
UDP
+关注
关注
0文章
325浏览量
33933 -
网络驱动
+关注
关注
0文章
7浏览量
7409
发布评论请先 登录
相关推荐
udp数据丢包的原因?

Linux应用的延时和丢包模拟
深入分析Linux网络丢包问题

简述linux系统UDP丢包问题分析思路(上)
如何解决MPSoC万兆以太网应用中UDP接收丢包问题

Linux下模拟网络时延和丢包神器介绍
网络丢包问题分析





 工商网监
工商网监
评论