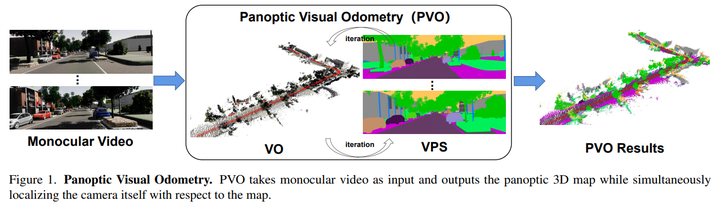
 介绍一种新的全景视觉里程计框架PVO
介绍一种新的全景视觉里程计框架PVO
论文提出了PVO,这是一种新的全景视觉里程计框架,用于实现场景运动、几何和全景分割信息的更全面建模。提出的PVO在统一的视图中对视觉里程计(VO)和视频全景分割(VPS)进行建模,这使得这两项任务互惠互利。具体来说,在图像全景分割的指导下,在VO模块中引入了全景更新模块。
该全景增强VO模块可以通过全景感知动态mask来减轻动态目标在相机姿态估计中的影响。另一方面,VO增强型VPS模块还利用从VO模块获得的相机姿态、深度和光流等几何信息,将当前帧的全景分割结果融合到相邻帧,从而提高了分割精度,这两个模块通过反复迭代优化相互促进。大量实验表明,PVO在视觉里程计和视频全景分割任务中都优于最先进的方法。
领域背景
了解场景的运动、几何和全景分割在计算机视觉和机器人威廉希尔官方网站
中发挥着至关重要的作用,其应用范围从自动驾驶到增强现实,本文朝着解决这个问题迈出了一步,以实现单目视频场景的更全面建模!已经提出了两项任务来解决这个问题,即视觉里程计(VO)和视频全景分割(VPS)。特别地,VO[9,11,38]将单目视频作为输入,并在静态场景假设下估计相机姿态。为了处理场景中的动态对象,一些动态SLAM系统使用实例分割网络进行分割,并明确过滤出某些类别的目标,这些目标可能是动态的,例如行人或车辆。
然而,这种方法忽略了这样一个事实,即潜在的动态目标实际上可能在场景中是静止的,例如停放的车辆。相比之下,VPS专注于在给定一些初始全景分割结果的情况下,跨视频帧跟踪场景中的单个实例。当前的VPS方法没有明确区分目标实例是否在移动,尽管现有的方法广泛地独立地解决了这两个任务,但值得注意的是,场景中的动态目标会使这两项任务都具有挑战性。认识到两个任务之间的这种相关性,一些方法试图同时处理这两个任务,并以多任务的方式训练运动语义网络,如图2所示。然而,这些方法中使用的损失函数可能相互矛盾,从而导致性能下降。
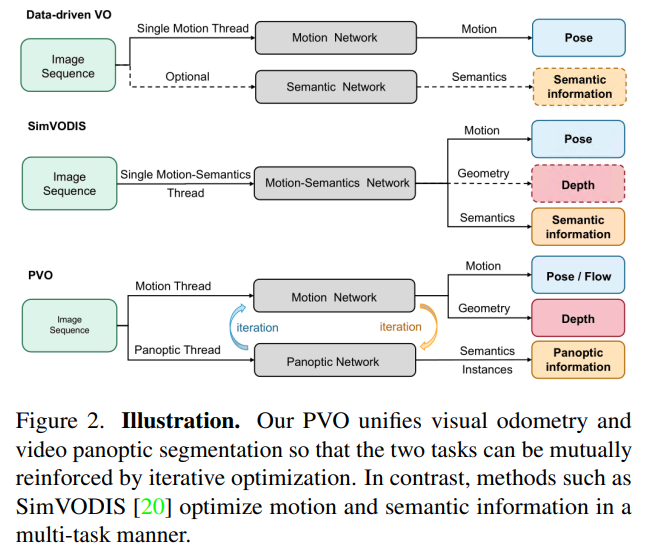
本文提出了一种新的全景视觉里程计(PVO)框架,该框架使用统一的视图将这两项任务紧密耦合,以对场景进行全面建模。VPS可以利用全景分割信息调整VO的权重(每个实例的像素的权重应该相互关联),VO可以将视频全景分割的跟踪和融合从2D转换为3D。受开创性的期望最大化算法的启发,递归迭代优化策略可以使这两项任务互惠互利。
PVO由三个模块组成,一个图像全景分割模块、一个全景增强型VO模块和一个VO增强型VPS模块。全景分割模块获取单个图像并输出图像全景分割结果,然后被馈送到全景增强VO模块中作为初始化。注意,尽管本文选择PanopticFPN,但任何分割模型都可以用于全景分割模块。在全景增强VO模块,提出了一个全景更新模块来过滤动态目标的干扰,从而提高了动态场景中姿态估计的准确性。在VO增强的VPS模块中,引入了一种在线融合机制,根据估计的姿态、深度和光流,将当前帧的多分辨率特征与相邻帧对齐,这种在线融合机制可以有效地解决多目标遮挡的问题。实验表明,递归迭代优化策略提高了VO和VPS的性能。本文的主要贡献概括为四个方面:
1.本文提出了一种新的全景视觉里程计(PVO)框架,该框架可以将VO和VPS任务统一起来,对场景进行全面建模;
2.引入全景更新模块,并将其纳入全景增强VO模块,以改进姿态估计;
3.在VOEnhanced VPS模块中提出了一种在线融合机制,有助于改进视频全景分割;
4.大量实验表明,提出的具有递归迭代优化的PVO在视觉里程计和视频全景分割任务中都优于最先进的方法;
1)视频全景分割
视频全景分割旨在生成一致的全景分割,并跟踪视频帧中所有像素的实例。作为一项先驱工作,VPSNet定义了这项新任务,并提出了一种基于实例级跟踪的方法。SiamTrack通过提出pixel-tube匹配损失和对比度损失来扩展VPSNet,以提高实例嵌入的判别能力。VIPDeplab通过引入额外的深度信息,提供了一个深度感知VPS网络。而STEP提出对视频全景分割的每个像素进行分割和跟踪,HybridTracker提出从两个角度跟踪实例:特征空间和空间位置。与现有方法不同,本文引入了一种VO增强的VPS模块,该模块利用VO估计的相机姿态、深度和光流来跟踪和融合从当前帧到相邻帧的信息,并可以处理遮挡。
2)SLAM和视觉里程计
SLAM同时进行定位和地图构建,视觉里程计作为SLAM的前端,专注于姿态估计。现代SLAM系统大致分为两类,基于几何的方法和基于学习的方法。由于基于监督学习的方法具有良好的性能,基于无监督学习的VO方法受到了广泛的关注,但它们的性能不如有监督的方法。一些无监督方法利用多任务学习和深度和光流等辅助任务来提高性能。
最近,TartanVO提出建立一个可推广基于学习的VO,并在具有挑战性的SLAM数据集TartanAir上测试该系统。DROID-SLAM提出使用bundle adjustment层迭代更新相机姿态和像素深度,并展示了卓越的性能。DeFlowSLAM进一步提出了dual-flow表示和自监督方法,以提高SLAM系统在动态场景中的性能。为了应对动态场景的挑战,动态SLAM系统通常利用语义信息作为约束但它们主要作用于stereo、RGBD或LiDAR序列。相反,本文引入了全景更新模块,并在DROID-SLAM上构建了全景增强型VO,可以用于单目视频。这样的组合可以更好地理解场景几何和语义,从而对场景中的动态对象更加鲁棒。与其它多任务端到端模型不同,本文的PVO具有循环迭代优化策略,可以防止任务相互干扰。
本文提出的方法
给定一个单目视频,PVO的目标是同时定位和全景3D映射。图3描述了PVO模型的框架,它由三个主要模块组成:图像全景分割模块、全景增强VO模块和VO增强VPS模块。VO模块旨在估计摄像机的姿态、深度和光流,而VPS模块输出相应的视频全景分割,最后两个模块以反复互动的方式相互促进!
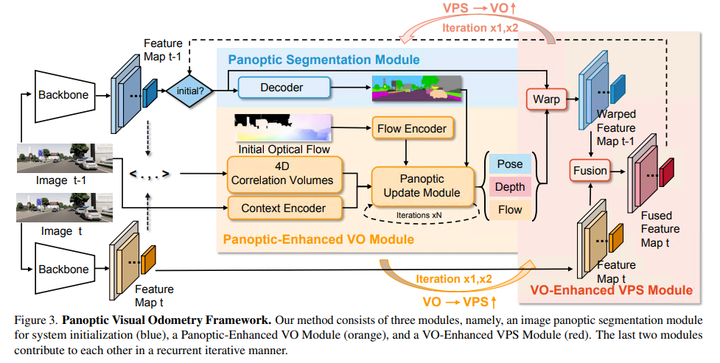
1)图像全景分割
图像全景分割以单个图像为输入,输出图像的全景分割结果,将语义分割和实例分割相结合,对图像的实例进行综合建模。输出结果用于初始化视频全景分割,然后输入全景增强VO模块。在本文的实验中,如果没有特别指出,使用广泛使用的图像全景分割网络PanopticFPN。PanopticFPN建立在具有权重θ_e的ResNetf_{θ_e}的主干上,并提取图像的多尺度特征I_t:

它使用具有权重θ_d的解码器g_{θ_d}输出全景分割结果,该解码器由语义分割和实例分割组成,每个像素p的全景分割结果为:
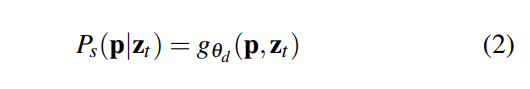
被馈送到解码器中的多尺度特征随着时间的推移而更新。一开始,编码器生成的多尺度特征被直接输入解码器(图3蓝色部分)。在随后的时间步长中,这些多尺度特征在被馈送到解码器之前用在线特征融合模块进行更新。
2)全景增强 VO 模块
在视觉里程计中,动态场景无处不在,过滤掉动态目标的干扰至关重要。DROID-SLAM的前端以单目视频{{I_t}}^N_{t=0}为输入,并优化相机姿态{G_t}^N_{t=0}∈SE(3)和反深度d_t∈R^{H×W}+,通过迭代优化光流delta r{ij}∈R^{HW2}。它不考虑大多数背景是静态的,前景目标可能是动态的,并且每个目标的像素权重应该是相关的。全景增强VO模块(见图4)是通过结合全景分割的信息,帮助获得更好的置信度估计(见图7),因此,全景增强VO可以获得更精确的相机姿势。接下来,将简要回顾DROID-SLAM的类似部分(特征提取和相关性),并重点介绍全景更新模块的复杂设计。
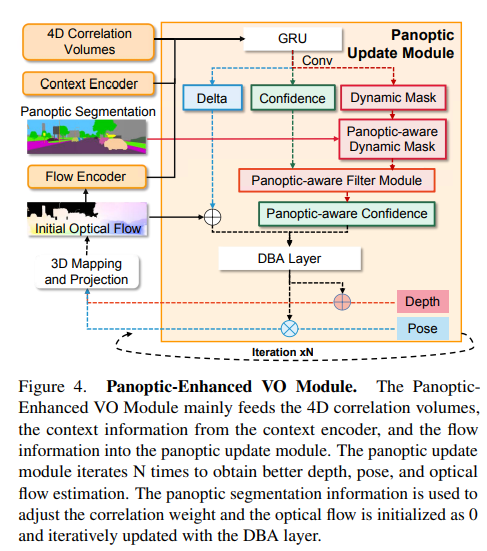

特征提取:与DROID-SLAM类似,全景增强VO模块借用了RAFT的关键组件来提取特征。本文使用两个独立的网络(一个特征编码器和一个上下文编码器) 提取每个图像的多尺度特征,其中利用特征编码器的特征构建成对图像的4D相关volumes,并将上下文编码器的特征注入全景更新模块。特征编码器的结构类似于全景分割网络的主干,并且它们可以使用共享编码器。
相关金字塔和查找表:与DROIDSLAM类似,本文采用帧图(V,E)来指示帧之间的共同可见性。例如,边(i,j)∈E表示保持重叠区域的两个图像I_i和I_j,并且可以通过这两个图像的特征向量之间的点积来构建4D相关volumes:
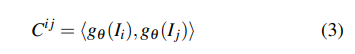
遵循平均池化层以获得金字塔相关性,本文使用DROID-SLAM中定义的相同查找运算符来使用双线性插值对金字塔相关volumes值进行索引,这些相关特征被串联,从而产生最终的特征向量。Panoptic增强型VO模块继承了DROID-SLAM的前端VO模块,利用全景分割信息来调整VO的权重。将通过将初始光流馈送到流编码器而获得的flow信息和从两帧建立的4D相关volumes以及上下文编码器获取的特征作为中间变量馈送到GRU,然后三个卷积层输出动态掩码M_{d_{ij}},相关置信度map w_{ij}和稠密光流delta r_{ij}。给定初始化的全景分割,可以将动态掩码调整为全景感知动态掩码,为了便于理解,保持符号不变。置信度和全景感知动态掩码通过全景感知滤波器模块以获得全景感知置信度:
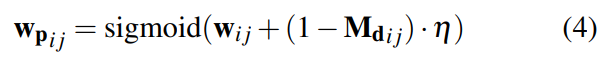
深度和动态的残差掩码被添加到当前深度和动态掩码,分别为:
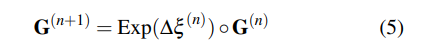
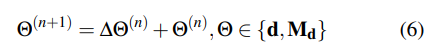
Correspondence:首先在每次迭代中使用当前的姿态和深度估计来搜索对应关系。参考DROID-SLAM,对于帧i中的每个像素坐标pi,帧图中每个边(i,j)∈E的稠密对应域pij可以计算如下:
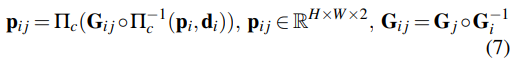
DBA层:使用DROID-SLAM中定义的密集束调整层(DBA)来map stream revisions,以更新当前估计的逐像素深度和姿态,成本函数可以定义如下:
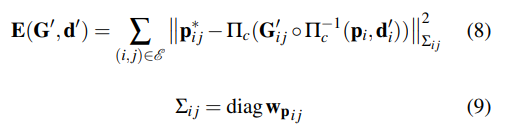
3)VO增强型VPS模块
视频全景分割旨在获得每帧的全景分割结果,并保持帧间分割的一致性。为了提高分割精度和跟踪精度,FuseTrack等一些方法试图利用光流信息对特征进行融合,并根据特征的相似性进行跟踪。这些方法仅来自可能遇到遮挡或剧烈运动的2D视角。我们生活在一个3D世界中,可以使用额外的深度信息来更好地建模场景。本文的VO增强型VPS模块正是基于这一理解,能够更好地解决上述问题。
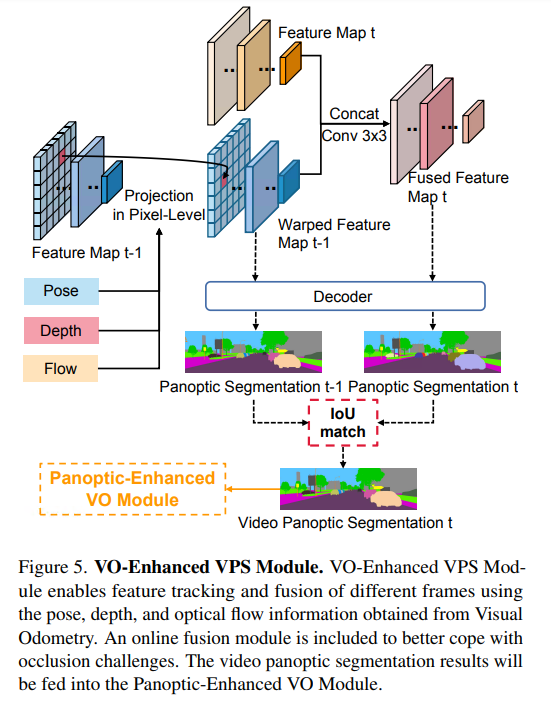
图5显示了VO增强型VPS模块,该模块通过使用从视觉里程计获得的深度、姿态和光流信息,将前一帧t−1的特征wrap到当前帧t,从而获得wrap的特征。在线融合模块将融合当前帧t的特征和wrap的特征,以获得融合的特征。为了保持视频分割的一致性,首先将wrap的特征t−1(包含几何运动信息)和融合的特征图t输入解码器,分别获得全景分割t−1和t,然后使用简单的IoU匹配模块来获得一致的全景分割,该结果将被输入Panoptic增强型VO模块。
4)递归迭代优化
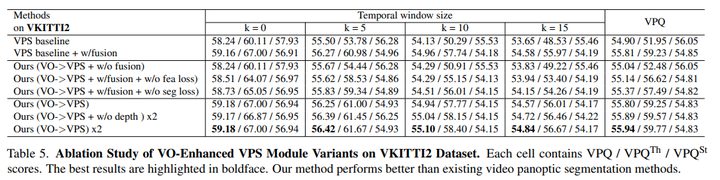
受EM算法的启发,可以以递归迭代的方式优化所提出的全景增强VO模块和VO增强VPS模块,直到收敛。在实验上,循环通常只需要两次迭代就可以收敛,表5和表6表明,反复迭代优化可以提高VPS和VO模块的性能。
5)实施细则
PVO由PyTorch实现,由三个主要模块组成:图像全景分割、全景增强VO模块和VO增强VPS模块。本文使用三个阶段来训练网络,在KITTI数据集上训练图像全景分割作为初始化。在PanopticFCN之后,训练过程中采用了多尺度缩放策略。在两个GeForce RTX 3090 GPU上以1e-4的初始速率优化网络,其中每个小批量有八个图像,SGD优化器的使用具有1e-4的重量衰减和0.9的动量。
全景增强VO模块的训练遵循DROIDSLAM,只是它额外提供了地面实况全景分割结果。在训练VO增强视频全景分割模块时,使用GT深度、光流和姿态信息作为几何先验来对齐特征,并固定训练的单图像全景分割的主干,然后仅训练融合模块。该网络在一个GeForce RTX 3090 GPU上以1e-5的初始学习率进行了优化,其中每个批次有八个图像。当融合网络基本收敛时,添加了一个分割一致性损失函数来进一步完善VPS模块!
实验结果
1)视觉里程计
本文在三个具有动态场景的数据集上进行实验:Virtual KITTI、KITTI和TUM RGBD动态序列,使用绝对轨迹误差(ATE)进行评估。对于视频全景分割,在cityscape和VIPER数据集上使用视频全景质量(VPQ)度量。本文进一步对Virtual KITTI进行消融研究,以分析本文的框架设计。最后,展示了PVO在视频编辑方面的适用性,如补充材料中的第B节所示。
VKITTI2
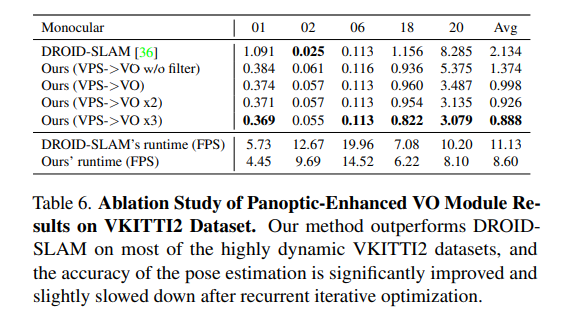
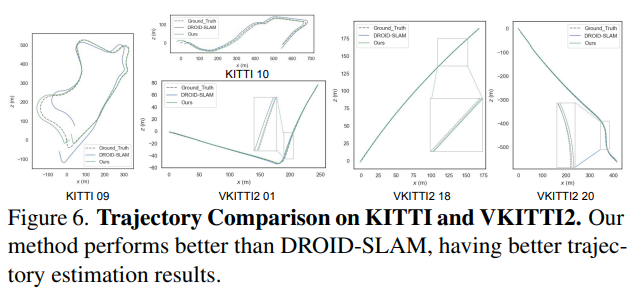
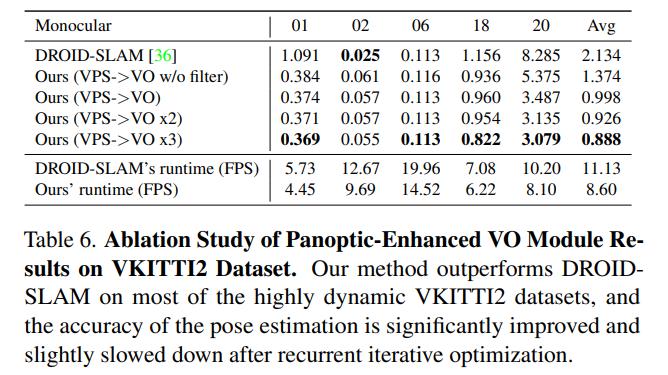
虚拟KITTI数据集[3]由从KITTI跟踪基准克隆的5个序列组成,为每个序列提供RGB、深度、类分割、实例分割、相机姿态、flow和场景flow数据。如表6和图6所示,在大多数序列中,本文的PVO以很大的优势优于DROID SLAM,并在序列02中实现了有竞争力的性能。
KITTI
KITTI是一个捕捉真实世界交通场景的数据集,从农村地区的高速公路到拥有大量静态和动态对象的城市街道。本文将在VKITTI2[3]数据集上训练的PVO模型应用于KITTI序列。如图6所示,PVO的姿态估计误差仅为DROID-SLAM的一半,这证明了PVO具有良好的泛化能力。表1显示了KITTI和VKITTI数据集上的完整SLAM比较结果,其中PVO在大多数情况下都大大优于DROID-SLAM和DynaSLAM,DynaSLAM在VKITTI2 02、06和18序列中属于灾难性系统故障。

TUM-RGBD
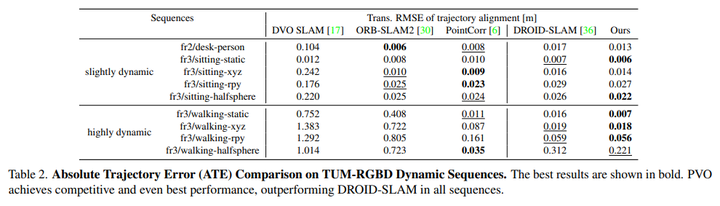
TUM RGBD是一个用手持相机捕捉室内场景的数据集,本文选择TUM RGBD数据集的动态序列来显示本文的方法的有效性。将PVO与DROIDSLAM以及三种最先进的动态RGB-D SLAM系统进行了比较,即DVO-SLAM、ORB-SLAM2和PointCorr。请注意,PVO和DROID-SLAM仅使用单目RGB视频。表2表明PVO在所有场景中都优于DROID-SLAM,与传统的RGB-D SLAM系统相比,本文的方法在大多数场景中也表现得更好。
2)视频全景分割
将PVO与三种基于实例的视频全景分割方法进行了比较,即VPSNetTrack、VPSNetFuseTrack和SiamTrack。在图像全景分割模型UPSNet的基础上,VPSNetTrack还添加了MaskTrack head,以形成视频全景分割模型。基于VPSNet Track的VPSNet FuseTrack额外注入了时间特征聚合和融合,而SiamTrack利用pixel-tubel 匹配损失和对比度损耗对VPSNet Track进行微调,性能略有提高,比较VPSNet FuseTrack主要是因为SiamTrack的代码不可用。
Cityscape:本文在VPS中采用了Cityscape的公共训练/val/test分割,其中每个视频包含30个连续帧,每五帧有相应的GT注释。表3表明,使用PanopticFCN的方法在val数据集上优于最先进的方法,实现了比VPSNet Track高+1.6%VPQ。与VPSNetFuseTrack相比,本文的方法略有改进,可以保持一致的视频分割,如补充材料中的图A4所示。原因是由于内存有限,论文的VO模块只能获得1/8分辨率的光流和深度。
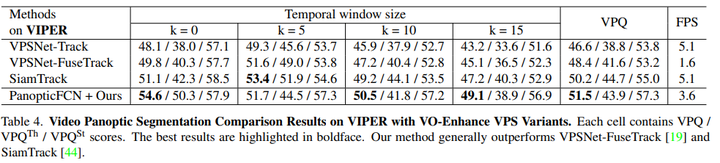
VIPER:VIPER维护了大量高质量的全景视频注释,这是另一个视频全景分割基准。遵循VPS[19],并采用其公共train/val拆分。使用从日常场景中选择的10个视频,每个视频的前60帧用于评估。表4表明,与VPSNet FuseTrack相比,PanopticFCN方法在VIPER数据集上获得了更高的分数(+3.1VPQ)。
3)消融实验
VPS增强型VO模块:在全景增强型VO模块中,使用DROID-SLAM作为基线,(VPS->VO)意味着增加了全景信息先验以增强VO基线,(VPS->VO x2)意味着可以迭代优化VO模块两次。(VPS->VO x3)意味着对VO模块进行3次反复迭代优化,表6和图7显示,在大多数高度动态的VKITTI2数据集上,全景信息可以帮助提高DROID-SLAM的准确性,递归迭代优化可以进一步改善结果。
VO增强型VPS模块:为了评估VO是否有助于VPS,首先使用PanopticFPN来获得每个帧的全景分割结果,然后使用来自RAFT的光流信息进行帧间跟踪,这被设置为VPS基线。(VPS基线+w/fusion)意味着额外地将特征与流量估计相融合。(VO->VPS+w/o融合)意味着在基线之上使用额外的深度、姿势和其他信息,(VO->VPS)意味着我们额外融合了该功能。
VO增强型VPS模块中的在线融合:为了验证所提出的特征对齐损失(fea损失)和分割一致性损失(seg损失)的有效性,方法如下:(VO->VPS+w/fusion+w/o fealoss)意味着在没有特征对齐损失的情况下训练在线融合模块,(VO->VPS+w/fusion+w/o-seg loss)意味着在没有Segmentation Consistent loss的情况下训练在线融合模块,表5展示了这两种损失函数的有效性!
一些结论
论文提出了一种新的全景视觉里程计方法,该方法在统一的视图中对VO和VPS进行建模,使这两项任务能够相互促进。全景更新模块可以帮助改进姿态估计,而在线融合模块有助于改进全景分割。大量实验表明,本文的PVO在这两项任务中都优于最先进的方法。局限性主要是PVO建立在DROID-SLAM和全景分割的基础上,这使得网络很重,需要大量内存。尽管PVO可以在动态场景中稳健地执行,但它忽略了当摄像机返回到之前的位置时环路闭合的问题,探索一种低成本、高效的闭环SLAM系统是未来的工作。
审核编辑:刘清
-
摄像机
+关注
关注
3文章
1596浏览量
60019 -
Droid
+关注
关注
0文章
2浏览量
6416 -
SLAM
+关注
关注
23文章
423浏览量
31824 -
vps
+关注
关注
1文章
109浏览量
12026
原文标题:CVPR 2023 | PVO:全景视觉里程计(VO和全景分割双SOTA)!
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
用于任意排列多相机的通用视觉里程计系统
一种面向飞行试验的数据融合框架

基于视觉语言模型的导航框架VLMnav
浅谈扫地机器人用到的那些电子元器件!
投入式水位计是什么?投入式水位计怎么安装


一种完全分布式的点线协同视觉惯性导航系统
全景声解码器

rup是一种什么模型
一种高效的KV缓存压缩框架--GEAR

视觉惯性里程计(VIO)在运动估计中的优势及应用

介绍一种OpenAtom OpenHarmony轻量系统适配方案

知语云全景监测威廉希尔官方网站 :现代安全防护的全面解决方案
基于深度学习的LiDAR SLAM框架(DeepPointMap)






 工商网监
工商网监
评论