 形状感知零样本语义分割
形状感知零样本语义分割
一、简介
由于大规模视觉语言预训练取得了令人瞩目的进展,最近的识别模型可以以惊人的高准确度对任意对象进行零样本和开放式分类。然而,将这种成功转化为语义分割并不容易,因为这种密集的预测任务不仅需要准确的语义理解,还需要良好的形状描绘,而现有的视觉语言模型是通过图像级别的语言描述进行训练的。为了弥合这一差距,我们在本研究中追求具有形状感知能力的零样本语义分割。受图像分割文献中经典的谱方法的启发,我们提出利用自监督像素级特征构建的拉普拉斯矩阵的特征向量来提升形状感知分割性能。
尽管这种简单而有效的算法完全不使用已知类别的掩模,但我们证明它的表现优于一种最先进的形状感知范式,在训练期间对齐地面实况和预测边缘。我们还深入研究了在不同数据集上使用不同的骨干网络所实现的性能提升,并得出了一些有趣且有结论性的观察:形状感知分割性能的提升与目标掩模的形状紧密性和对应语言嵌入的分布都密切相关。
二、网络架构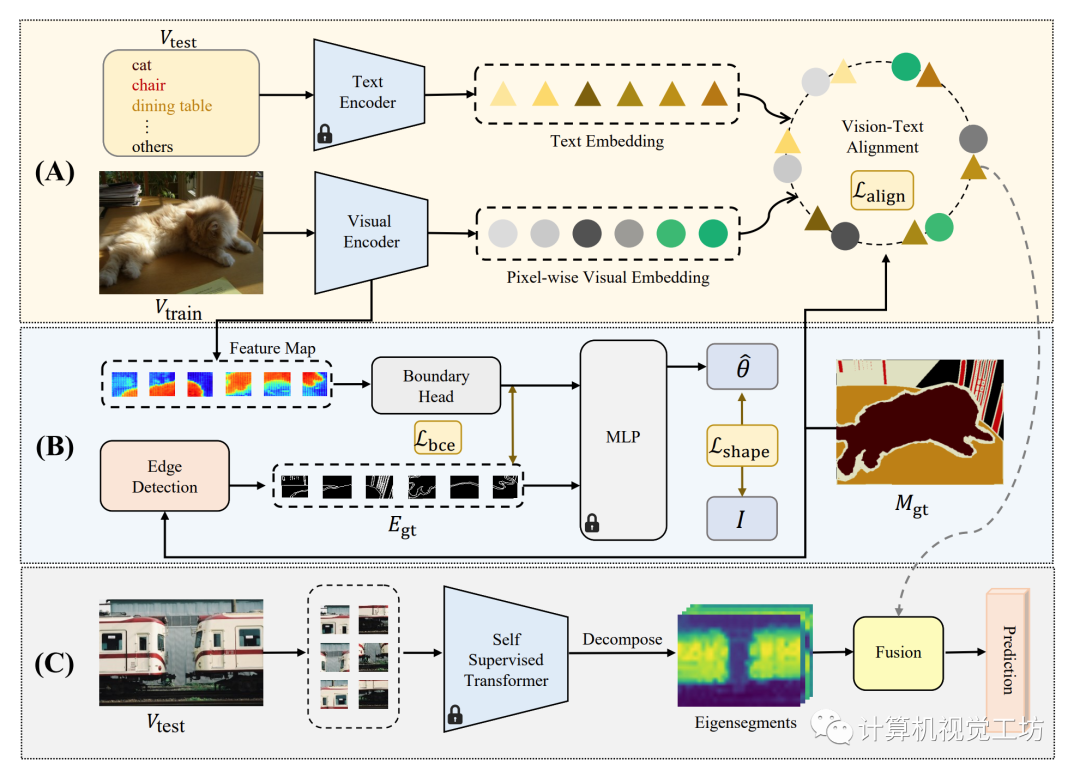
图1 SAZS的总体框架
零样本语义分割的目标是将语义分割任务扩展到训练数据集中未出现的类别。引入额外的先验信息的一种潜在方法是利用预训练的视觉-语言模型,但是大多数这些模型都集中于图像级别的预测,无法转移到密集预测任务。为此,我们提出了一种名为“形状感知零样本语义分割(SAZS)”的新方法。
该方法利用了预训练的CLIP[1]模型中包含的丰富的语言先验信息,在训练期间对齐地面实况和预测边缘。同时,利用自监督像素级特征构建的拉普拉斯矩阵的特征向量来提升形状感知分割性能,并将其与像素级别的预测相结合。 我们的方法的模型框架如图1所示。
输入图像首先通过图像编码器转换为像素级嵌入,然后与预训练的CLIP[1]模型的文本编码器获得的预先计算的文本嵌入对齐(图1中的A部分)。同时,图像编码器中的额外头部用于在补丁中预测边界,并针对分割地面真值中获得的地面真值边缘进行优化(图1中的B部分)。此外,在推断过程中,我们通过谱分析分解图像并将输出的特征向量与类别不可知的分割结果相结合(图1中的C部分)。
我们将训练集表示为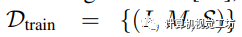 ,测试集表示为
,测试集表示为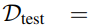
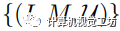 ,其中
,其中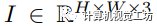 和
和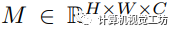 分别表示输入图像和相应的真实语义掩码。S表示 I中的K个潜在标签,而表示测试期间未见过的类别。
分别表示输入图像和相应的真实语义掩码。S表示 I中的K个潜在标签,而表示测试期间未见过的类别。
在我们的设置中,这两个集合严格互斥(即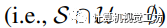 )。 在针对的
)。 在针对的 进行推断之前,模型使用来自S的真实标签在
进行推断之前,模型使用来自S的真实标签在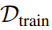 上进行训练。 这意味着在训练过程中从未看到测试集中的类别,使得任务在零样本设置下进行。一旦模型训练得当,它应该能够泛化到未见过的类别,并在开放世界中实现高效的目标密集预测。
上进行训练。 这意味着在训练过程中从未看到测试集中的类别,使得任务在零样本设置下进行。一旦模型训练得当,它应该能够泛化到未见过的类别,并在开放世界中实现高效的目标密集预测。
像素级别的视觉-语言对齐
我们采用扩张残差网络(DRN[2])和密集预测Transformer(DPT[3])来将图像编码为像素级嵌入向量。同时,我们采用预训练的CLIP文本编码器将来自S中K个类别的名称映射到CLIP特征空间作为文本特征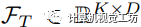 。其中,视觉特征
。其中,视觉特征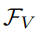 和文本特征具有相同的维度D。
和文本特征具有相同的维度D。
为了实现视觉-语言对齐,此前的工作[5]通过最小化像素和对应语义类别之间的距离,同时最大化像素和其他类别之间的距离来实现。在像素级视觉和语言特征被嵌入同一特征空间的假设下,我们利用余弦相似度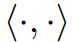 作为特征之间的量化距离度量,并提出对齐损失,它是所有像素上已见类别的交叉熵损失的总和:
作为特征之间的量化距离度量,并提出对齐损失,它是所有像素上已见类别的交叉熵损失的总和: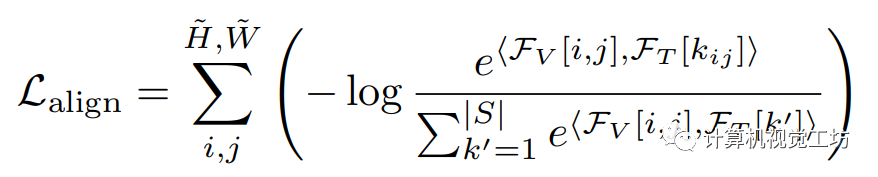 其中,
其中,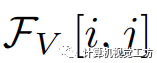 表示在位置
表示在位置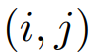 上的像素视觉特征,
上的像素视觉特征,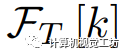 表示第k个文本特征,
表示第k个文本特征,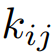 表示像素 的类别的索引。
表示像素 的类别的索引。
形状约束
由于CLIP是在图像级别任务上训练的,仅仅利用CLIP特征空间中的先验信息可能对密集预测任务不足够。为了解决这个问题,我们引入边界检测作为一个约束任务。受到之前工作[6]的启发,我们通过优化真实边缘和特征图中的边缘之间的仿射变换,使其趋近于单位矩阵。
具体来说,如图1所示,我们提取视觉编码器的中间特征,并将其划分成块。首先采用Sobel算子获得边缘对应的真实标签。之后将特征块输入边界头进行特征提取。我们利用训练好的形状网络(图 1中的MLP)计算第i个特征块的变换矩阵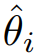 ,该矩阵用于将处理后的特征块与边缘的真实注释之间进行仿射变换。我们使用形状损失来优化仿射变换矩阵与单位矩阵之间的差异:
,该矩阵用于将处理后的特征块与边缘的真实注释之间进行仿射变换。我们使用形状损失来优化仿射变换矩阵与单位矩阵之间的差异: 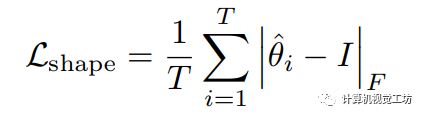 其中T表示特征块数量,表示Frobenius范数。
其中T表示特征块数量,表示Frobenius范数。
此外,我们还计算了整张特征图的预测边缘掩码与相应的真实标注之间的二元交叉熵损失 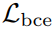 ,以进一步优化边缘检测的性能。经过边缘检测任务的联合训练,视觉编码器能够利用输入图像中的形状先验信息。后面的实验结果表明,由
,以进一步优化边缘检测的性能。经过边缘检测任务的联合训练,视觉编码器能够利用输入图像中的形状先验信息。后面的实验结果表明,由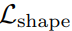 和引入的形状感知带来了显著的性能提升。
和引入的形状感知带来了显著的性能提升。
最终,在训练过程中需要优化的总损失为: 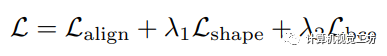 其中,和是损失权重。
其中,和是损失权重。
自监督谱分解
由于此前谱分解工作[7]的启发,我们利用无监督谱分解的方式将输入图像的拉普拉斯矩阵分解为具有边界信息的特征段,并在图1中的融合模块中将这些特征段与神经网络的预测结果融合。 关联矩阵的推导是谱分解的关键。首先提取预训练的自监督Transformer(DINO[4])最后一层的注意力块中的特征。像素,的关联矩阵定义为: 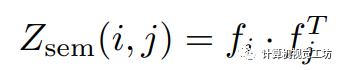 虽然从DINO特征中的关联矩阵富含语义信息,但缺少包括颜色相似性和空间距离在内的低层次近邻信息。
虽然从DINO特征中的关联矩阵富含语义信息,但缺少包括颜色相似性和空间距离在内的低层次近邻信息。
我们首先将输入图像转换为HSV颜色空间: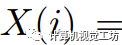
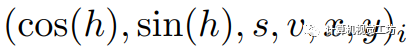 ,其中
,其中 是各自的HSV坐标,
是各自的HSV坐标,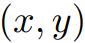 是像素i的空间坐标。然后,像素关联矩阵被定义为:
是像素i的空间坐标。然后,像素关联矩阵被定义为: 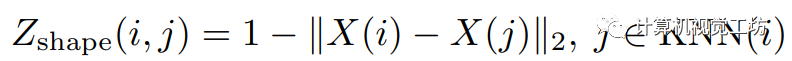 这里的
这里的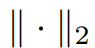 表示二范数。整体的关联矩阵定义为这两者的加权和:
表示二范数。整体的关联矩阵定义为这两者的加权和: 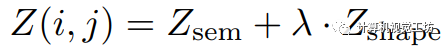
推理过程
在进行推理时,我们首先使用预训练的CLIP文本编码器对类别的进行编码,并获得包含C个类别的文本特征 ,其中每个类别都用一个D维嵌入表示。然后我们利用训练好的视觉编码器获取视觉特征图
,其中每个类别都用一个D维嵌入表示。然后我们利用训练好的视觉编码器获取视觉特征图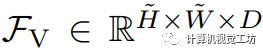 。最终的逻辑回归值
。最终的逻辑回归值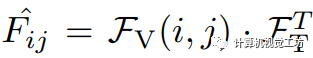 是视觉特征和文本特征之间余弦相似性的计算结果。同时,我们使用预训练的DINO以无监督的方式提取语义特征,并计算出前K个谱特征区段
是视觉特征和文本特征之间余弦相似性的计算结果。同时,我们使用预训练的DINO以无监督的方式提取语义特征,并计算出前K个谱特征区段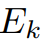 (我们的实现中
(我们的实现中 )。 最终的预测结果是由融合模块生成的,该模块根据和
)。 最终的预测结果是由融合模块生成的,该模块根据和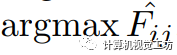 之间的最大IoU(表示为
之间的最大IoU(表示为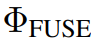 )从预测集中进行选择:
)从预测集中进行选择: 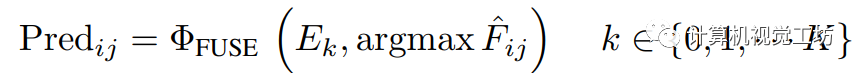
三、实验结果
我们分别在语义分割数据集PASCAL-5i[8]和COCO-20i[9]上进行了定量和定性实验,分别如下图所示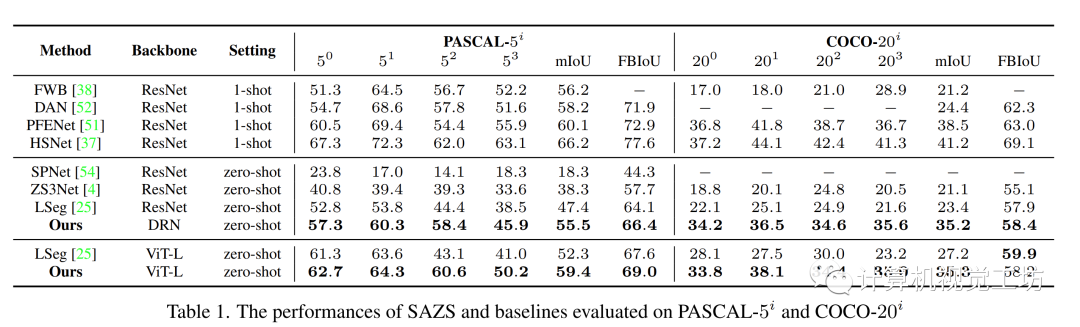
表1:SAZS在PASCAL-5i和COCO-20i上的定量结果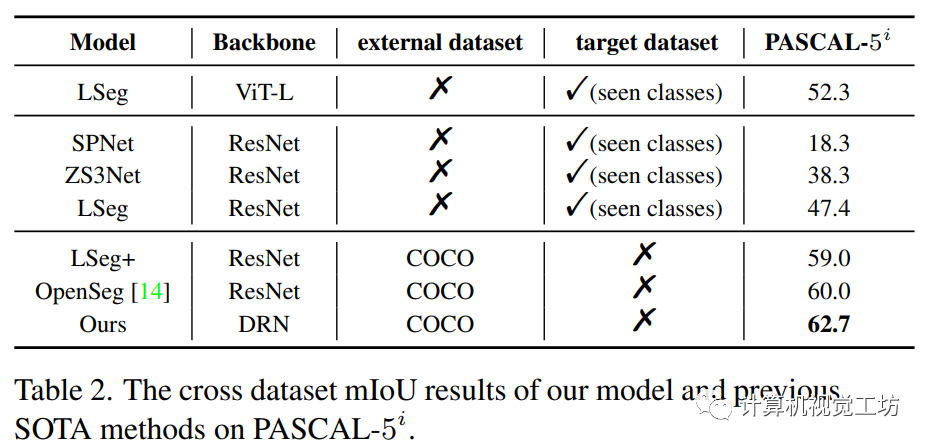
表2:SAZS跨数据零样本分割的定量结果(在PASCAL-5i上测试)
SAZS在PASCAL-5i和COCO-20i上的定性结果分别如下图所示。第一列和最后一列是不同类别的输入图像和相应的地面真实语义掩码。第二列和第三列分别是 SAZS 没有和有形状感知的预测结果。*表示在训练阶段未曾出现的类别.

形状感知分割验证指标IoU与目标掩模的形状紧密性和对应语言嵌入的分布关系如下图所示。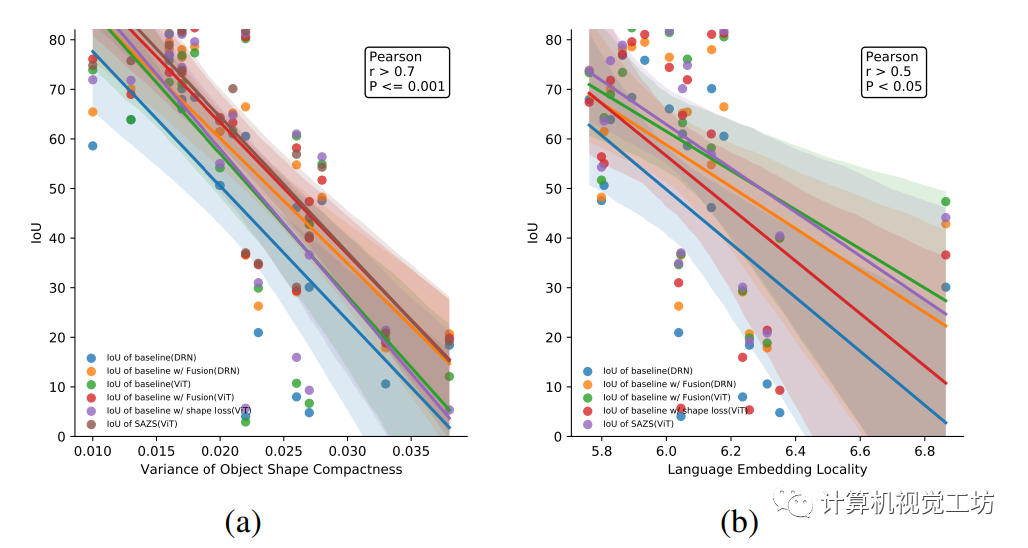
四、总结
本文提出了一种新颖的框架,用于实现形状感知的零样本语义分割(简称SAZS)。该框架利用大规模预训练视觉语言模型的特征空间中包含的丰富先验信息,同时通过在边界检测约束任务上进行联合训练。此外,采用自监督谱分解来获取图像的特征向量,将其与网络预测融合增强模型感知形状的能力。相关性分析进一步凸显了形状紧密度和语言嵌入分布对分割性能的影响。
审核编辑:刘清
-
编码器
+关注
关注
45文章
3639浏览量
134441 -
DRNN
+关注
关注
0文章
2浏览量
6112 -
Clip
+关注
关注
0文章
31浏览量
6665 -
HSV
+关注
关注
0文章
10浏览量
2603
原文标题:CVPR2023 | 形状感知零样本语义分割
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
利用VLM和MLLMs实现SLAM语义增强

语义分割25种损失函数综述和展望

请问模拟开关必须要跟ADC一样放在模拟地与数字地的分割处吗?
图像语义分割的实用性是什么
图像分割和语义分割的区别与联系
图像分割与目标检测的区别是什么
图像分割与语义分割中的CNN模型综述
机器人视觉威廉希尔官方网站 中常见的图像分割方法
未来已来,多传感器融合感知是自动驾驶破局的关键
移动协作机器人的RGB-D感知的端到端处理方案
助力移动机器人下游任务!Mobile-Seed用于联合语义分割和边界检测

深入解析SAMPro3D的三维场景零样本分割威廉希尔官方网站

浅析自动驾驶行业的视觉感知主流框架设计
SegRefiner:通过扩散模型实现高精度图像分割






 工商网监
工商网监
评论