 深入分析Linux网络丢包问题!
深入分析Linux网络丢包问题!
今天浩道跟大家分享日常运维工作中,常常遇到的Linux网络丢包,该如何排查。
所谓丢包,是指在网络数据的收发过程中,由于种种原因,数据包还没传输到应用程序中,就被丢弃了。这些被丢弃包的数量,除以总的传输包数,也就是我们常说的丢包率。丢包率是网络性能中最核心的指标之一。丢包通常会带来严重的性能下降,特别是对 TCP 来说,丢包通常意味着网络拥塞和重传,进而还会导致网络延迟增大、吞吐降低。
一、 哪里可能丢包
接下来,我就以最常用的反向代理服务器 Nginx 为例,带你一起看看如何分析网络丢包的问题。执行下面的 hping3 命令,进一步验证 Nginx 是不是可以正常访问。这里我没有使用 ping,是因为 ping 基于 ICMP 协议,而 Nginx 使用的是 TCP 协议。
#-c表示发送10个请求,-S表示使用TCPSYN,-p指定端口为80
hping3-c10-S-p80192.168.0.30
HPING192.168.0.30(eth0192.168.0.30):Sset,40headers+0databytes
len=44ip=192.168.0.30ttl=63DFid=0sport=80flags=SAseq=3win=5120rtt=7.5ms
len=44ip=192.168.0.30ttl=63DFid=0sport=80flags=SAseq=4win=5120rtt=7.4ms
len=44ip=192.168.0.30ttl=63DFid=0sport=80flags=SAseq=5win=5120rtt=3.3ms
len=44ip=192.168.0.30ttl=63DFid=0sport=80flags=SAseq=7win=5120rtt=3.0ms
len=44ip=192.168.0.30ttl=63DFid=0sport=80flags=SAseq=6win=5120rtt=3027.2ms
---192.168.0.30hpingstatistic---
10packetstransmitted,5packetsreceived,50%packetloss
round-tripmin/avg/max=3.0/609.7/3027.2ms
从 hping3 的输出中,我们可以发现,发送了 10 个请求包,却只收到了 5 个回复,50%的包都丢了。再观察每个请求的 RTT 可以发现,RTT 也有非常大的波动变化,小的时候只有 3ms,而大的时候则有 3s。根据这些输出,我们基本能判断,已经发生了丢包现象。可以猜测,3s 的 RTT ,很可能是因为丢包后重传导致的。
那到底是哪里发生了丢包呢?排查之前,我们可以回忆一下 Linux 的网络收发流程,先从理论上分析,哪里有可能会发生丢包。你不妨拿出手边的笔和纸,边回忆边在纸上梳理,思考清楚再继续下面的内容。在这里,为了帮你理解网络丢包的原理,我画了一张图,你可以保存并打印出来使用
从图中你可以看出,可能发生丢包的位置,实际上贯穿了整个网络协议栈。换句话说,全程都有丢包的可能。
- 在两台 VM 连接之间,可能会发生传输失败的错误,比如网络拥塞、线路错误等;
- 在网卡收包后,环形缓冲区可能会因为溢出而丢包;
- 在链路层,可能会因为网络帧校验失败、QoS 等而丢包;
- 在 IP 层,可能会因为路由失败、组包大小超过 MTU 等而丢包;
- 在传输层,可能会因为端口未监听、资源占用超过内核限制等而丢包;
- 在套接字层,可能会因为套接字缓冲区溢出而丢包;
- 在应用层,可能会因为应用程序异常而丢包;
- 此外,如果配置了 iptables 规则,这些网络包也可能因为 iptables 过滤规则而丢包
当然,上面这些问题,还有可能同时发生在通信的两台机器中。不过,由于我们没对 VM2做任何修改,并且 VM2 也只运行了一个最简单的 hping3 命令,这儿不妨假设它是没有问题的。为了简化整个排查过程,我们还可以进一步假设, VM1 的网络和内核配置也没问题。接下来,就可以从协议栈中,逐层排查丢包问题。
二、 链路层
当链路层由于缓冲区溢出等原因导致网卡丢包时,Linux 会在网卡收发数据的统计信息中记录下收发错误的次数。可以通过 ethtool 或者 netstat ,来查看网卡的丢包记录。
netstat-i
KernelInterfacetable
IfaceMTURX-OKRX-ERRRX-DRPRX-OVRTX-OKTX-ERRTX-DRPTX-OVRFlg
eth0100310008000BMRU
lo6553600000000LRU
RX-OK、RX-ERR、RX-DRP、RX-OVR ,分别表示接收时的总包数、总错误数、进入 Ring Buffer 后因其他原因(如内存不足)导致的丢包数以及 Ring Buffer 溢出导致的丢包数。
TX-OK、TX-ERR、TX-DRP、TX-OVR 也代表类似的含义,只不过是指发送时对应的各个指标。
这里我们没有发现任何错误,说明虚拟网卡没有丢包。不过要注意,如果用 tc 等工具配置了 QoS,那么 tc 规则导致的丢包,就不会包含在网卡的统计信息中。所以接下来,我们还要检查一下 eth0 上是否配置了 tc 规则,并查看有没有丢包。添加 -s 选项,以输出统计信息:
tc-sqdiscshowdeveth0
qdiscnetem800d:rootrefcnt2limit1000loss30%
Sent432bytes8pkt(dropped4,overlimits0requeues0)
backlog0b0prequeues0
可以看到, eth0 上配置了一个网络interwetten与威廉的赔率体系 排队规则(qdisc netem),并且配置了丢包率为 30%(loss 30%)。再看后面的统计信息,发送了 8 个包,但是丢了 4个。看来应该就是这里导致 Nginx 回复的响应包被 netem 模块给丢了。
既然发现了问题,解决方法也很简单,直接删掉 netem 模块就可以了。执行下面的命令,删除 tc 中的 netem 模块:
tcqdiscdeldeveth0rootnetemloss30%
删除后,重新执行之前的 hping3 命令,看看现在还有没有问题:
hping3-c10-S-p80192.168.0.30
HPING192.168.0.30(eth0192.168.0.30):Sset,40headers+0databytes
len=44ip=192.168.0.30ttl=63DFid=0sport=80flags=SAseq=0win=5120rtt=7.9ms
len=44ip=192.168.0.30ttl=63DFid=0sport=80flags=SAseq=2win=5120rtt=1003.8ms
len=44ip=192.168.0.30ttl=63DFid=0sport=80flags=SAseq=5win=5120rtt=7.6ms
len=44ip=192.168.0.30ttl=63DFid=0sport=80flags=SAseq=6win=5120rtt=7.4ms
len=44ip=192.168.0.30ttl=63DFid=0sport=80flags=SAseq=9win=5120rtt=3.0ms
---192.168.0.30hpingstatistic---
10packetstransmitted,5packetsreceived,50%packetloss
round-tripmin/avg/max=3.0/205.9/1003.8ms
不幸的是,从 hping3 的输出中可以看到还是 50% 的丢包,RTT 的波动也仍旧很大,从 3ms 到 1s。显然,问题还是没解决,丢包还在继续发生。不过,既然链路层已经排查完了,我们就继续向上层分析,看看网络层和传输层有没有问题。
三、 网络层和传输层
在网络层和传输层中,引发丢包的因素非常多。不过,其实想确认是否丢包,是非常简单的事,因为 Linux 已经为我们提供了各个协议的收发汇总情况。执行 netstat -s 命令,可以看到协议的收发汇总,以及错误信息:
netstat-s
#输出
Ip:
Forwarding:1//开启转发
31totalpacketsreceived//总收包数
0forwarded//转发包数
0incomingpacketsdiscarded//接收丢包数
25incomingpacketsdelivered//接收的数据包数
15requestssentout//发出的数据包数
Icmp:
0ICMPmessagesreceived//收到的ICMP包数
0inputICMPmessagefailed//收到ICMP失败数
ICMPinputhistogram:
0ICMPmessagessent//ICMP发送数
0ICMPmessagesfailed//ICMP失败数
ICMPoutputhistogram:
Tcp:
0activeconnectionopenings//主动连接数
0passiveconnectionopenings//被动连接数
11failedconnectionattempts//失败连接尝试数
0connectionresetsreceived//接收的连接重置数
0connectionsestablished//建立连接数
25segmentsreceived//已接收报文数
21segmentssentout//已发送报文数
4segmentsretransmitted//重传报文数
0badsegmentsreceived//错误报文数
0resetssent//发出的连接重置数
Udp:
0packetsreceived
...
TcpExt:
11resetsreceivedforembryonicSYN_RECVsockets//半连接重置数
0packetheaderspredicted
TCPTimeouts:7//超时数
TCPSynRetrans:4//SYN重传数
...
etstat 汇总了 IP、ICMP、TCP、UDP 等各种协议的收发统计信息。不过,我们的目的是排查丢包问题,所以这里主要观察的是错误数、丢包数以及重传数。可以看到,只有 TCP 协议发生了丢包和重传,分别是:
- 11 次连接失败重试(11 failed connection attempts)
- 4 次重传(4 segments retransmitted)
- 11 次半连接重置(11 resets received for embryonic SYN_RECV sockets)
- 4 次 SYN 重传(TCPSynRetrans)
- 7 次超时(TCPTimeouts)
这个结果告诉我们,TCP 协议有多次超时和失败重试,并且主要错误是半连接重置。换句话说,主要的失败,都是三次握手失败。不过,虽然在这儿看到了这么多失败,但具体失败的根源还是无法确定。所以,我们还需要继续顺着协议栈来分析。接下来的几层又该如何分析呢?
四、 iptables
首先,除了网络层和传输层的各种协议,iptables 和内核的连接跟踪机制也可能会导致丢包。所以,这也是发生丢包问题时我们必须要排查的一个因素。
先来看看连接跟踪,要确认是不是连接跟踪导致的问题,只需要对比当前的连接跟踪数和最大连接跟踪数即可。
#主机终端中查询内核配置
$sysctlnet.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max=262144
$sysctlnet.netfilter.nf_conntrack_count
net.netfilter.nf_conntrack_count=182
可以看到,连接跟踪数只有 182,而最大连接跟踪数则是 262144。显然,这里的丢包,不可能是连接跟踪导致的。
接着,再来看 iptables。回顾一下 iptables 的原理,它基于 Netfilter 框架,通过一系列的规则,对网络数据包进行过滤(如防火墙)和修改(如 NAT)。这些 iptables 规则,统一管理在一系列的表中,包括 filter、nat、mangle(用于修改分组数据) 和 raw(用于原始数据包)等。而每张表又可以包括一系列的链,用于对 iptables 规则进行分组管理。
对于丢包问题来说,最大的可能就是被 filter 表中的规则给丢弃了。要弄清楚这一点,就需要我们确认,那些目标为 DROP 和 REJECT 等会弃包的规则,有没有被执行到。可以直接查询 DROP 和 REJECT 等规则的统计信息,看看是否为0。如果不是 0 ,再把相关的规则拎出来进行分析。
iptables-tfilter-nvL
#输出
ChainINPUT(policyACCEPT25packets,1000bytes)
pktsbytestargetprotoptinoutsourcedestination
6240DROPall--**0.0.0.0/00.0.0.0/0statisticmoderandomprobability0.29999999981
ChainFORWARD(policyACCEPT0packets,0bytes)
pktsbytestargetprotoptinoutsourcedestination
ChainOUTPUT(policyACCEPT15packets,660bytes)
pktsbytestargetprotoptinoutsourcedestination
6264DROPall--**0.0.0.0/00.0.0.0/0statisticmoderandomprobability0.29999999981
从 iptables 的输出中,你可以看到,两条 DROP 规则的统计数值不是 0,它们分别在INPUT 和 OUTPUT 链中。这两条规则实际上是一样的,指的是使用 statistic 模块,进行随机 30% 的丢包。0.0.0.0/0 表示匹配所有的源 IP 和目的 IP,也就是会对所有包都进行随机 30% 的丢包。看起来,这应该就是导致部分丢包的“罪魁祸首”了。
执行下面的两条 iptables 命令,删除这两条 DROP 规则。
root@nginx:/#iptables-tfilter-DINPUT-mstatistic--moderandom--probability0.30-jDROP
root@nginx:/#iptables-tfilter-DOUTPUT-mstatistic--moderandom--probability0.30-jDROP
再次执行刚才的 hping3 命令,看看现在是否正常
hping3-c10-S-p80192.168.0.30
#输出
HPING192.168.0.30(eth0192.168.0.30):Sset,40headers+0databytes
len=44ip=192.168.0.30ttl=63DFid=0sport=80flags=SAseq=0win=5120rtt=11.9ms
len=44ip=192.168.0.30ttl=63DFid=0sport=80flags=SAseq=1win=5120rtt=7.8ms
...
len=44ip=192.168.0.30ttl=63DFid=0sport=80flags=SAseq=9win=5120rtt=15.0ms
---192.168.0.30hpingstatistic---
10packetstransmitted,10packetsreceived,0%packetloss
round-tripmin/avg/max=3.3/7.9/15.0ms
这次输出你可以看到,现在已经没有丢包了,并且延迟的波动变化也很小。看来,丢包问题应该已经解决了。
不过,到目前为止,我们一直使用的 hping3 工具,只能验证案例 Nginx 的 80 端口处于正常监听状态,却还没有访问 Nginx 的 HTTP 服务。所以,不要匆忙下结论结束这次优化,我们还需要进一步确认,Nginx 能不能正常响应 HTTP 请求。我们继续在终端二中,执行如下的 curl 命令,检查 Nginx 对 HTTP 请求的响应:
$curl--max-time3http://192.168.0.30
curl:(28)Operationtimedoutafter3000millisecondswith0bytesreceived
奇怪,hping3 的结果显示Nginx 的 80 端口是正常状态,为什么还是不能正常响应 HTTP 请求呢?别忘了,我们还有个大杀器——抓包操作。看来有必要抓包看看了。
五、 tcpdump
执行下面的 tcpdump 命令,抓取 80 端口的包
tcpdump-ieth0-nnport80
#输出
tcpdump:verboseoutputsuppressed,use-vor-vvforfullprotocoldecode
listeningoneth0,link-typeEN10MB(Ethernet),capturesize262144bytes
然后,切换到终端二中,再次执行前面的 curl 命令:
curl--max-time3http://192.168.0.30
curl:(28)Operationtimedoutafter3000millisecondswith0bytesreceived
等到 curl 命令结束后,再次切换回终端一,查看 tcpdump 的输出:
1400.589235IP10.255.255.5.39058>172.17.0.2.80:Flags[S],seq332257715,win29200,options[mss1418,sackOK,TSval486800541ecr0,nop,wscale7],length0
1400.589277IP172.17.0.2.80>10.255.255.5.39058:Flags[S.],seq1630206251,ack332257716,win4880,options[mss256,sackOK,TSval2509376001ecr486800541,nop,wscale7],length0
1400.589894IP10.255.255.5.39058>172.17.0.2.80:Flags[.],ack1,win229,options[nop,nop,TSval486800541ecr2509376001],length0
1403.589352IP10.255.255.5.39058>172.17.0.2.80:Flags[F.],seq76,ack1,win229,options[nop,nop,TSval486803541ecr2509376001],length0
1403.589417IP172.17.0.2.80>10.255.255.5.39058:Flags[.],ack1,win40,options[nop,nop,TSval2509379001ecr486800541,nop,nop,sack1{76:77}],length0
从 tcpdump 的输出中,我们就可以看到:
- 前三个包是正常的 TCP 三次握手,这没问题;
- 但第四个包却是在 3 秒以后了,并且还是客户端(VM2)发送过来的 FIN 包,说明客户端的连接关闭了
根据 curl 设置的 3 秒超时选项,你应该能猜到,这是因为 curl 命令超时后退出了。用 Wireshark 的 Flow Graph 来表示,
你可以更清楚地看到上面这个问题:
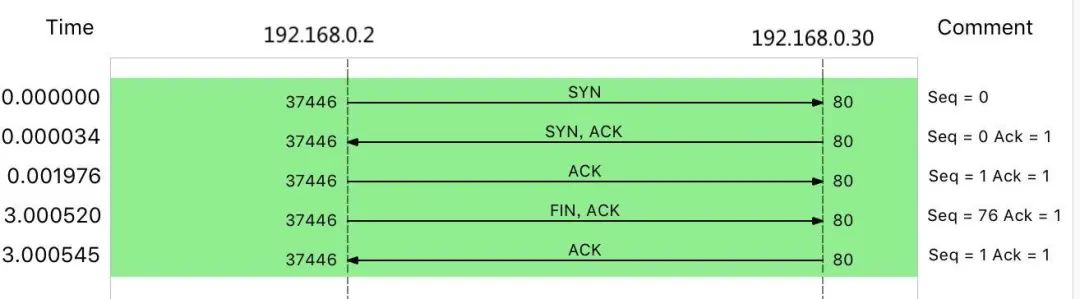
这里比较奇怪的是,我们并没有抓取到 curl 发来的 HTTP GET 请求。那究竟是网卡丢包了,还是客户端就没发过来呢?
可以重新执行 netstat -i 命令,确认一下网卡有没有丢包问题:
netstat-i
KernelInterfacetable
IfaceMTURX-OKRX-ERRRX-DRPRX-OVRTX-OKTX-ERRTX-DRPTX-OVRFlg
eth01001570344094000BMRU
lo6553600000000LRU
从 netstat 的输出中,你可以看到,接收丢包数(RX-DRP)是 344,果然是在网卡接收时丢包了。不过问题也来了,为什么刚才用 hping3 时不丢包,现在换成 GET 就收不到了呢?还是那句话,遇到搞不懂的现象,不妨先去查查工具和方法的原理。我们可以对比一下这两个工具:
- hping3 实际上只发送了 SYN 包;
- curl 在发送 SYN 包后,还会发送 HTTP GET 请求。HTTP GET本质上也是一个 TCP 包,但跟 SYN 包相比,它还携带了 HTTP GET 的数据。
通过这个对比,你应该想到了,这可能是 MTU 配置错误导致的。为什么呢?
其实,仔细观察上面 netstat 的输出界面,第二列正是每个网卡的 MTU 值。eth0 的 MTU只有 100,而以太网的 MTU 默认值是 1500,这个 100 就显得太小了。当然,MTU 问题是很好解决的,把它改成 1500 就可以了。
ifconfigeth0mtu1500
修改完成后,再切换到终端二中,再次执行 curl 命令,确认问题是否真的解决了:
curl--max-time3http://192.168.0.30/
#输出
...
Thankyouforusingnginx.