 AIGC时代的多模态知识工程思考与展望
AIGC时代的多模态知识工程思考与展望
内容简介:ChatGPT的火爆出圈使得AI生成(AIGC)威廉希尔官方网站 受到了全社会前所未有的广泛关注。此消彼长之下,传统的知识工程遭受了诸多质疑。在多模态智能领域,AIGC的能力不断提升,多模态知识工程工作应该何去何从?是否仍有价值?在本次分享中,讲者将探讨当前AIGC威廉希尔官方网站 耀眼“光芒”背后的“暗面”,思考与展望AIGC时代的多模态知识工程研究。
关于AIGC时代的多模态知识工程思考与展望,我们将从以下六个方面展开介绍:
第一部分,我们回顾一下AIGC威廉希尔官方网站 的发展历程和它带来的划时代影响力;
第二部分,我们对AIGC威廉希尔官方网站 的不足(阿克琉斯之踵)之处进行分析与总结;
第三部分,我们将介绍多模态认知智能的框架和两种实现路径,并进行对比分析;
第四~六部分,我们会展望当前AIGC大模型和MMKG多模态图谱间如何竞与合。
01
AIGC时代:未来已来
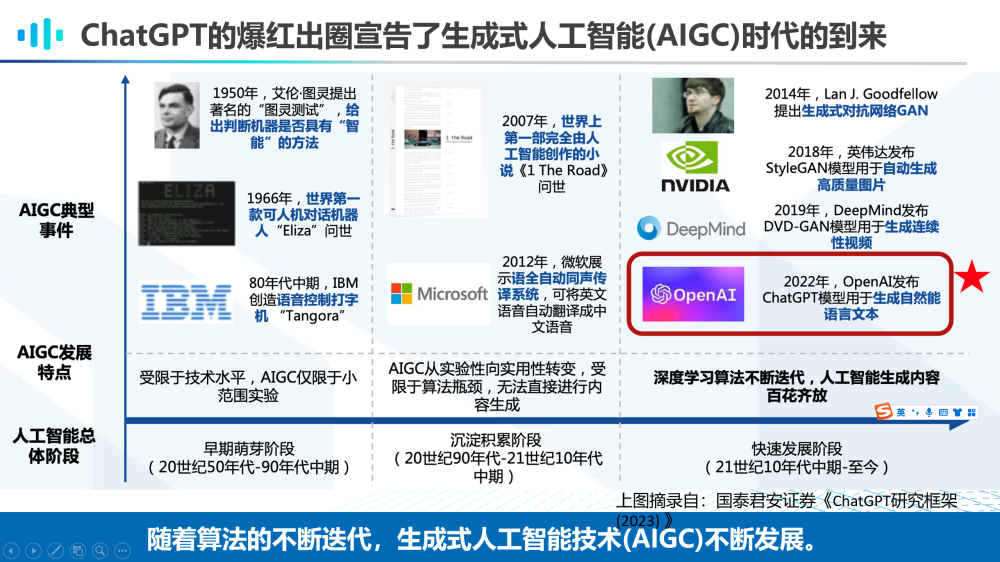
随着人工智能总体阶段的发展,生成式人工智能威廉希尔官方网站 (AIGC)也在不断迭代。从20世纪50年代到90年代中期,是AIGC的早期萌芽阶段,这一时期受限于威廉希尔官方网站 水平,AIGC仅限于小范围实验。这一时期的AIGC典型事件包括:1950年,艾伦·图灵提出的著名的“图灵测试”,给出判断机器是否具有“智能”的方法;1966年,世界上第一款可人机对话机器人“Eliza”的问世;以及在80年代中期IBM公司创造的语音控制打字机“Tangora”的出现。
而从20世纪90年代到21世纪10年代中期,AIGC处于沉淀积累阶段,这一阶段的AIGC威廉希尔官方网站 从实验性向实用性转变,但仍因受限于算法瓶颈,无法直接进行内容生成。这一阶段的AIGC典型事件则包括2007年世界上第一部完全由人工智能创作的小说《1 the road》的问世;以及2012年微软开发的全自动同声传译系统的出现,它能够将英文语音自动翻译成中文语音。
自21世纪10年代中期至今,是AIGC快速发展的阶段,得益于深度学习算法不断迭代,人工智能生成内容百花齐放。2014年,Goodfellow提出的生成对抗网络GAN用于生成图像;2019年,英伟达发布StyleGAN模型可以自动生成高质量图片;2019年DeepMind发布DVD-GAN用于生成连续性视频,直到2022年,OpenAI发布ChatGPT模型生成流畅的自然语言文本。
可以说,ChatGPT的爆红出圈宣告了AIGC时代的到来。
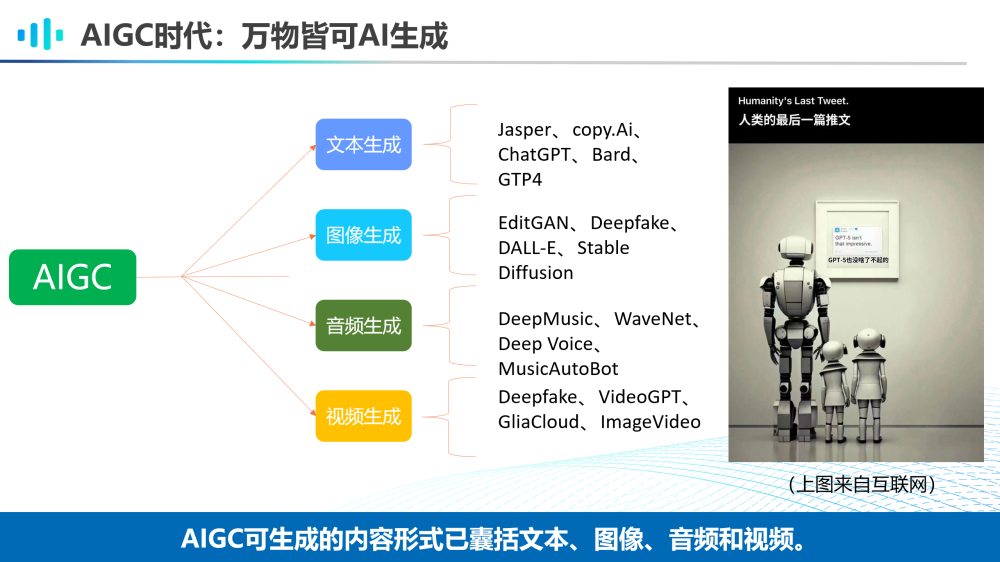
现在的AIGC威廉希尔官方网站 可以生成的内容包括文本、图像、音频和视频等。如今,已经有很多强大的算法被发明出来,如用于图像生成的Stable Diffusion算法。此外,还有很多走在威廉希尔官方网站 前沿的创业公司不断推动AIGC威廉希尔官方网站 的应用落地,如Jasper AI的AI写作软件和midjourney的AI绘画工具的发明都在解放着人类的内容创作生产力。这些共同促进了一个万物皆可AI生成的AIGC时代。
右图是一张来自互联网的趣味图片——机器人一家三口在人类博物馆中观赏人类的最后一篇推文“GPT-5也没啥了不起的”——表达了创作者对当今AIGC威廉希尔官方网站 飞速发展的隐隐担忧。
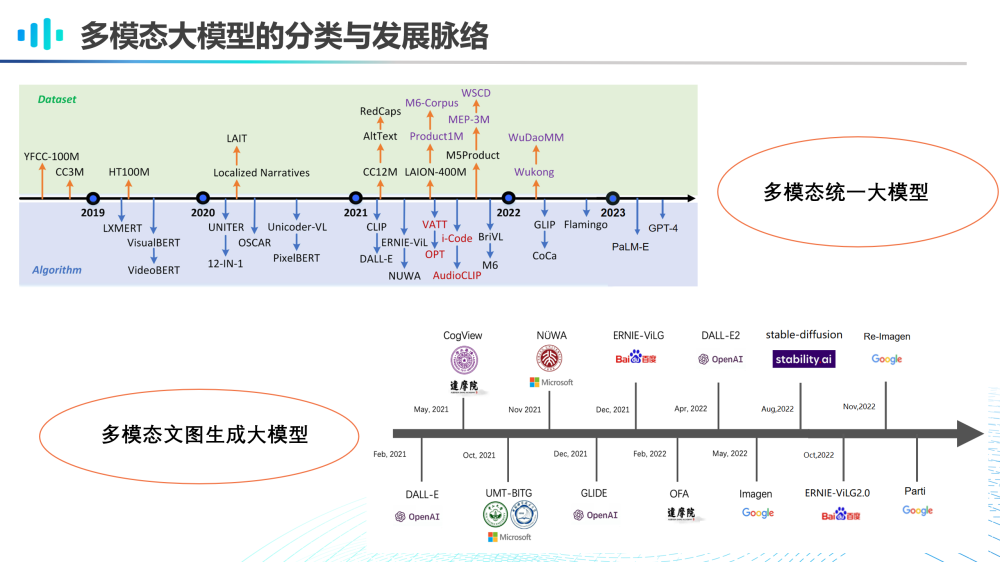
那么,我们首先看一下多模态大模型的分类与发展脉络。如上图所示,多模态大模型发展非常迅速,我们可以将多模态大模型简单分为多模态统一大模型和多模态文图生成大模型,前者用于统一的多模态生成和理解,后者特指具备强大的多模态文到图生成能力的大模型。

当前,文图生成大模型已经可以生成逼真、高清以及风格化的意境图像。
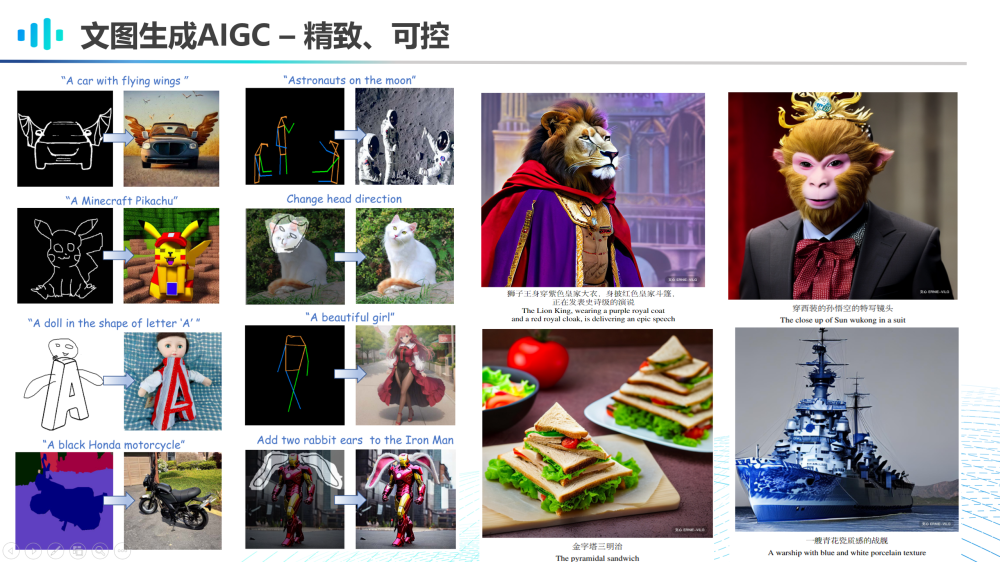
还有一些文图生成大模型,如斯坦福大学提出的ControlNet,其生成能力更加精致、可控。它不仅可以生成各类质地细腻、细节精致的图片,也可以通过简笔画来对图像生成进行操控。
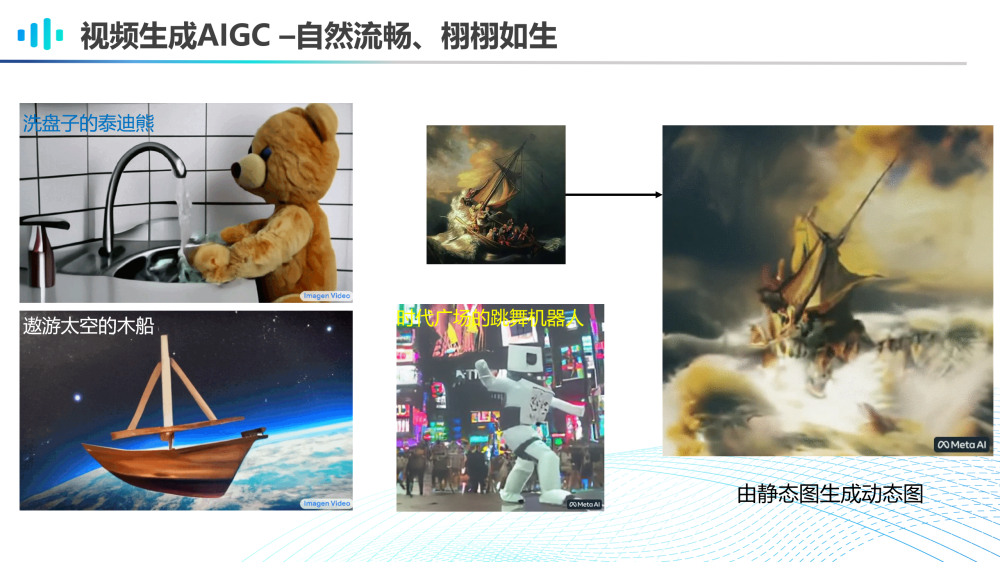
AIGC大模型生成的视频在某种程度上也可谓自然流畅、栩栩如生。

我们还看到Google发布的PaLM-E模型,展现了多模态AIGC大模型驱动的具身智能的情景。这个具备5620亿参数的具身多模态大模型,可以将真实世界的传感器信号与文本输入相结合,建立语言和感知的链接,可以用自然语言操控机器人完成操作规划、视觉问答等任务。

AIGC的惊艳效果不禁让很多人对符号主义(知识工程)的研究产生了疑问。Rich Sutton在著名文章《苦涩的教训》中提出,唯一导致AI进步的因素是更多的数据和更有效的计算。而DeepMind的研究主任Nando de Freitas也宣称,“AI现在完全取决于规模,AI领域更难的挑战已经解决了,游戏结束了!”。我们也看到,在大多数领域,大模型已经(暂时)战胜了精心设计的知识工程。然而,AI的流派之争真的结束了吗?
02
AIGC的阿克琉斯之踵
第二部分,让我们来看一下当前AIGC大模型实际存在的一些问题。

尽管今天的ChatGPT(包括GPT-4)很强大,它的诸多问题仍旧难以忽视:
第一、强语言弱知识的问题,ChatGPT无法理解用户查询中的知识性错误,它具备强大的语言能力,但知识能力仍旧较弱;
第二、实时信息自更新慢,新旧知识难以区分,目前ChatGPT的知识还停留在2021年,而每一次信息更新都需要成本高昂的重新训练;
第三、其逻辑推理能力并不可靠,应该说尚不具备复杂数学逻辑推理与专业逻辑推理能力;
第四、由于缺乏领域知识,它也无法真正为领域类问题提供专业靠谱的答案。

当前的多模态大模型的跨模态生成能力也尚不完善。上图是我们用文图生成大模型Stable Diffusion生成的一些案例。具体来说,当前的文图生成存在组合泛化、属性泄露、方位理解混乱、语义理解错误等问题。因此,尽管我们看到AIGC跨模态生成的视觉效果惊艳,但往往存在较大的模态间信息不对称问题。

此外,当前多模态大模型的多模态理解能力也存在问题。上图是来自BLIP2进行视觉问答任务的错误样例。我们看到:
1)模型由于缺乏事实知识,无法知晓球拍上的“w”图案是品牌“Wilson”的logo,因而错误回答成“nike”;
2)模型由于欠缺逻辑推理能力,不理解图像场景和问题的逻辑关系,因而回答错误;
3)模型由于常识储备不足,对某个具体场景(冲浪)下的意图理解犯了常识性错误。

让我们再来看一下Google的具身多模态大模型PaLM-E,虽然依赖如此大规模的参数实现了初步的机器人操控,但其demo视频中所展示的空间范围、物品种类、规划和操作任务的复杂度等都非常有限。我们可以想象,如果要在真实世界的复杂场景中达到实用级别,PaLM-E的参数规模是否还需要增大百倍、千倍甚至万倍?如果一味用海量参数存储所有知识,那么智慧涌现的代价是否过于昂贵?

至此,我们对多模态大模型做个简单的小结。首先,多模态大模型的本质是“用语言解释视觉,用视觉完善语言”。换句话说,我们要将文本中的语言符号知识,与视觉中的可视化信息建立统计关联。所谓“用语言解释视觉”,就是将语言中蕴含的符号知识体系和逻辑推理能力延伸至对视觉内容的理解;而所谓“用视觉完善语言”,是指丰富的视觉信息可以成为符号知识体系和逻辑推理能力的重要完善和补充。
我们知道,多模态大模型能发挥重大作用的重要前提是:
1)具有海量高质量图文配对数据;
2)文字富含事实知识和常识;
3)其逻辑推理过程可显式化被学习。
而我们所面临的现实情况却是:
1)数据量大但质量差,信息不对称;
2)纯文字中的知识与常识也不完备;
3)其逻辑推理是隐性难以学习的。
正因为这些理想与现实间的差距,导致了前面提到的多模态大模型的种种问题与不足。综上,我们认为,统计大模型始终难以较低成本,全面、准确地掌握人类知识、常识和逻辑推理能力。
03
多模态认知智能
第三部分,我们引出多模态认知智能,其研究旨在解决前一部分提到的问题。

上图是我们提出的一个多模态认知智能的研究框架。总的来说,多模态认知智能主要研究基于多模态数据的知识获取、表示、推理与应用。在多模态知识获取层面,我们从语料中通过抽取、生成、群智等方法获取知识或者从语言模型中萃取知识。在多模态知识表示层面,可以使用多模态图谱、常识图谱、语言模型、大规模知识网络等方法进行知识表示。基于多模态知识表示,可以进一步支撑多模态理解、推理和元认知等能力,从而赋能诸如跨模态搜索、推荐、问答、生成等多模态知识的应用。
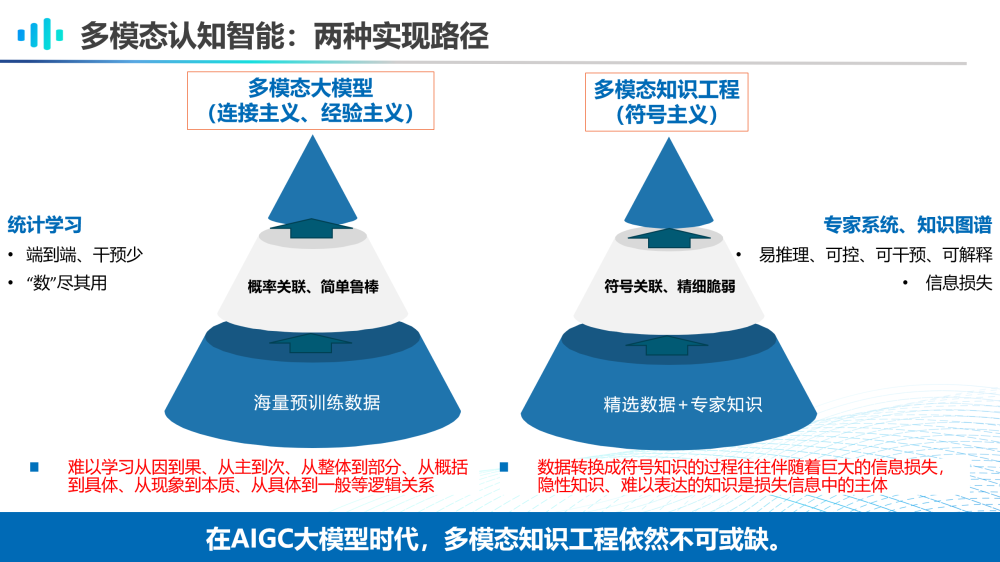
多模态认知智能目前有两种实现路径。一种是多模态大模型,其代表了联结主义和经验主义的思想,从海量预训练数据中学习概率关联,是简单而鲁棒的,它属于统计学习范畴,具备端到端、干预少和“数”尽其用的优势,其劣势在于难以学习到从因到果、从主到次、从整体到部分、从概括到具体、从现象到本质、从具体到一般等逻辑关系。
另一种实现路径是多模态知识工程,其代表了符号主义的思想,从精选数据和专家知识中学习符号关联,是精细而脆弱的,它往往通过专家系统和知识图谱实现,具备易推理、可控、可干预、可解释的优点,但是它的劣势主要在于将数据转换成符号知识的过程往往伴随着巨大的信息损失,而其中隐性知识等难以表达的知识往往是信息损失的主体。
结合多模态大模型和多模态知识工程的优劣势分析,我们认为:在AIGC大模型时代,多模态知识工程依然不可或缺。
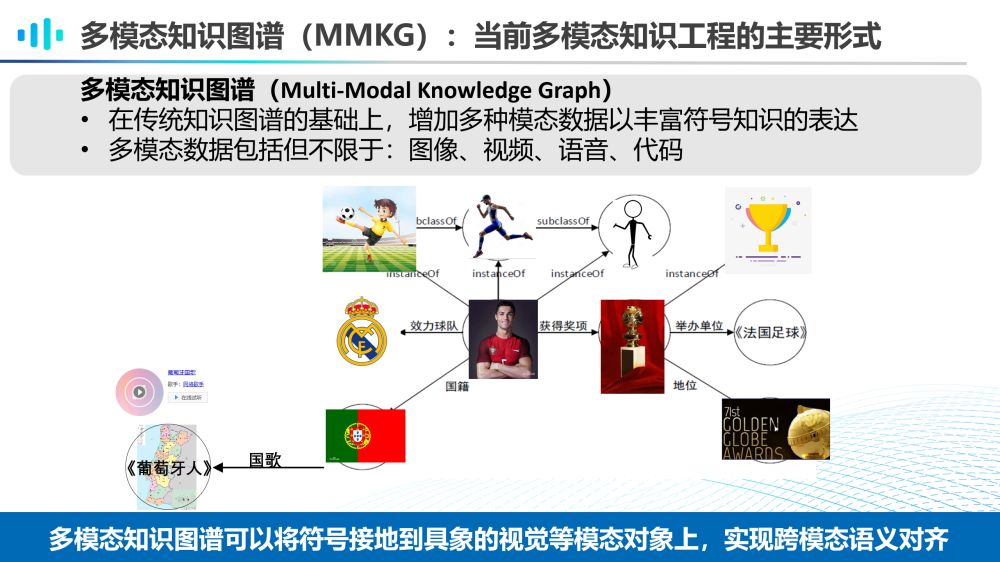
当前,多模态知识工程的主要形式之一是多模态知识图谱(MMKG)。多模态知识图谱是在传统知识图谱的基础上,增加多种模态数据以丰富符号知识表达的方法,其多模态数据包括但不限于图像、视频、语言、代码等。多模态知识图谱可以将符号接地到具象的视觉等模态对象上,实现跨模态语义对齐。
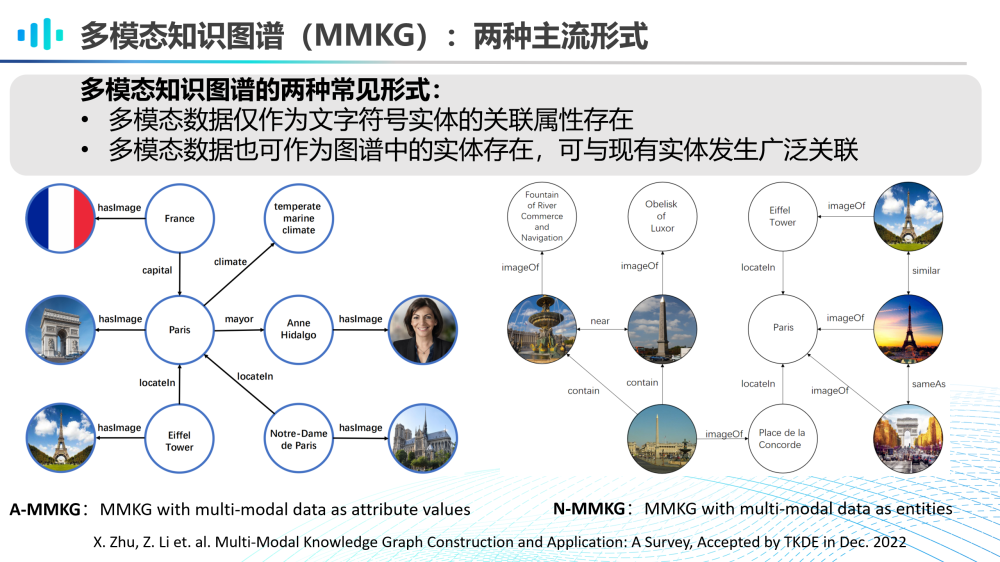
目前多模知识图谱的主流形式有两种。
一种是A-MMKG,其中多模态数据仅作为文字符号实体的关联属性存在;
另一种是N-MMKG,其中多模态数据也可作为图谱中的实体存在,可与现有实体发生广泛关联。

至此,我们进一步分析AIGC多模态大模型和大规模多模态知识图谱各自的优缺点。
多模态大模型的优点是:
1)关联推理能力强:可以学习掌握大量跨模态知识模式,隐空间的关联推理能力强,具有很强的泛化能力;
2)多任务通吃:一套大模型处理各类跨模态任务;
3)人工成本低:不依赖人工schema设计与数据标注;
4)适配能力强:可通过调优训练或prompt对话等方式来适配新的领域和任务。
而其不足之处在于:
1)可靠程度低:所生成的内容可靠性堪忧,存在误差累积、隐私泄露等问题,无法胜任高精度严肃场景需求;
2)知识推理弱:没有真正掌握数据背后的知识,缺乏知识推理能力,更无因果推理能力;
3)可解释性弱:虽有CoT加持,但可解释性仍然不足;
4)训练成本高:需要消耗大量计算资源和时间来进行训练,需要强大的计算设备和高效的算法。
而与之对应的,多模态知识图谱的优点是:
1)专业可信度高:其结构和关系清晰,易于理解和解释,可为人类决策提供参考,通常为某个具体应用场景构建,可提供更精准和针对性的知识支持;
2)可解释性好:以结构化形式表示知识 ,知识的可访问性、可重用性、可解释性好,对人类友好;
3)可扩展性强:知识图谱的内容可以随着应用场景的需要进行不断扩展和更新,可以不断完善和改进。
而多模态知识图谱的缺点在于:
1)推理能力弱:只能表示已有的知识和关系,对于未知或不确定的领域难以进行有效的知识建模和推理;
2)人工成本高:其构建需要依赖于人工或半自动的方式进行知识抽取和建模,难以实现完全自动化;
3)架构调整难:其基本schema架构通常是静态的,不易根据新的数据或场景进行修改和调整。
由上分析可见:多模态大模型的优点常常是多模态知识图谱的不足,而多模态大模型的不足又往往是多模态知识图谱的优势。因此,我们认为:当前阶段,大模型与知识图谱仍应继续保持竞合关系,互相帮助,互为补充。
04
AIGC for MMKG
第四部分,我们思考与展望一下AIGC大模型如何辅助MMKG的构建与应用。
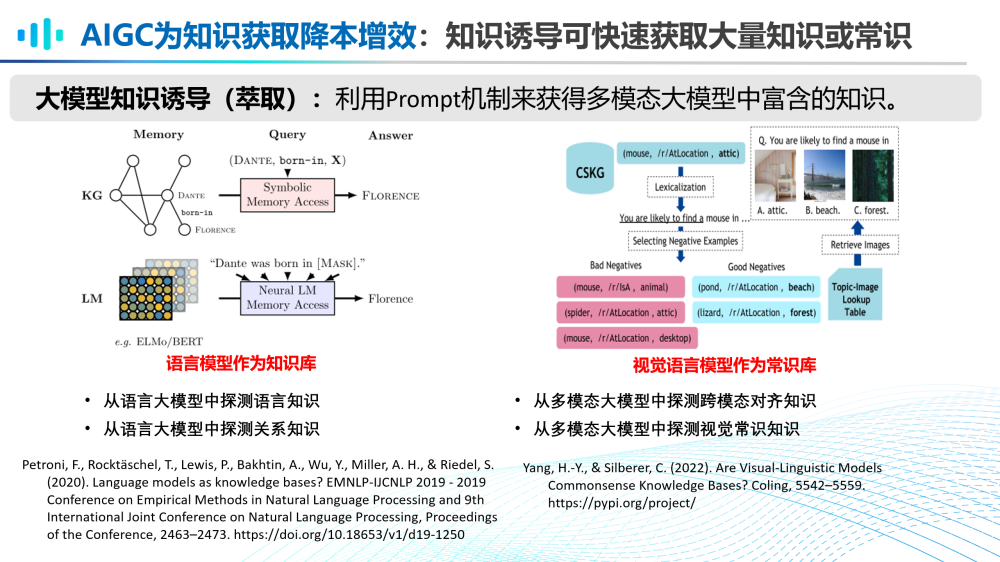
第一,AIGC大模型为知识获取降本增效。
(1)通过知识诱导(萃取),可以快速获取大量知识或常识。例如,我们可以从语言大模型中诱导语言知识和关系知识;我们也可以从多模态大模型中诱导跨模态对齐知识和视觉常识知识。

(2)AIGC大模型的出现使得零样本、少样本、开放知识抽取成为可能。例如,我们可以利用ChatGPT对话大模型的理解和生成能力,从给定文本中抽取三元组知识;我们也可以利用多模态AIGC大模型的跨模态生成和理解能力,从给定图文数据中抽取多模态知识。

(3)AIGC大模型可以显著增强垂域多模态知识获取能力。GPT-4、ChatPDF模型等已经显示了强大的领域知识抽取能力,如基于多模态文档的知识抽取。
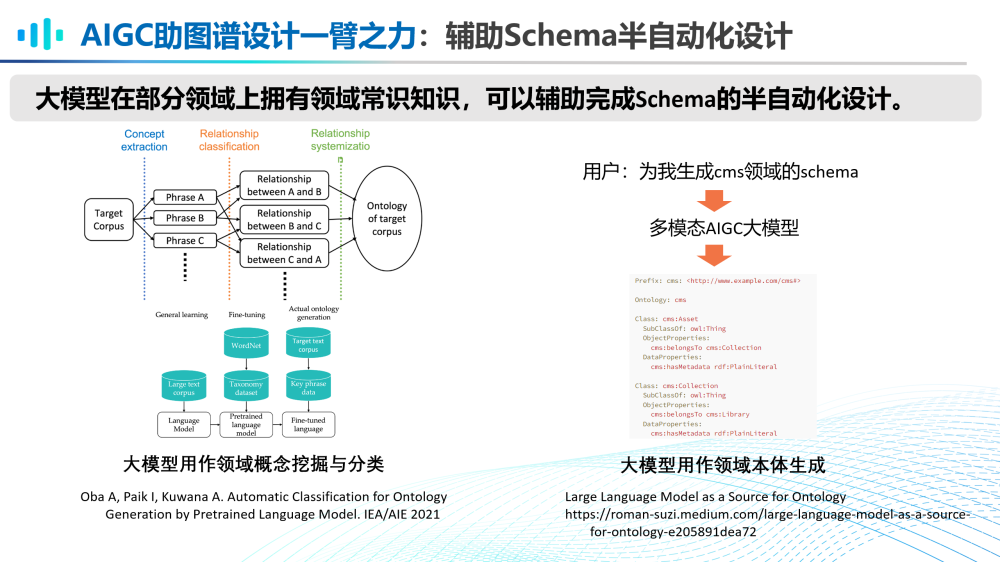
第二,AIGC大模型助图谱设计一臂之力。
大模型在部分领域上拥有领域常识知识,可以辅助完成schema的半自动化设计。在多模态场景中,也有一些尝试,例如可以用多模态AIGC大模型生成cms领域的schema。
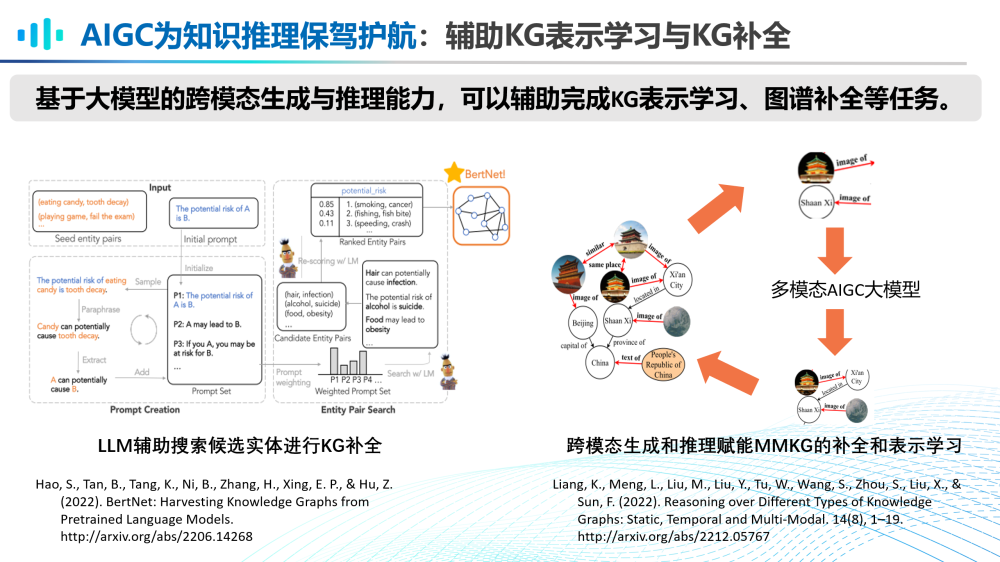
第三,AIGC大模型为知识推理保驾护航。
基于大模型的跨模态生成与推理能力,可以辅助完成KG表示学习、图谱补全等任务。
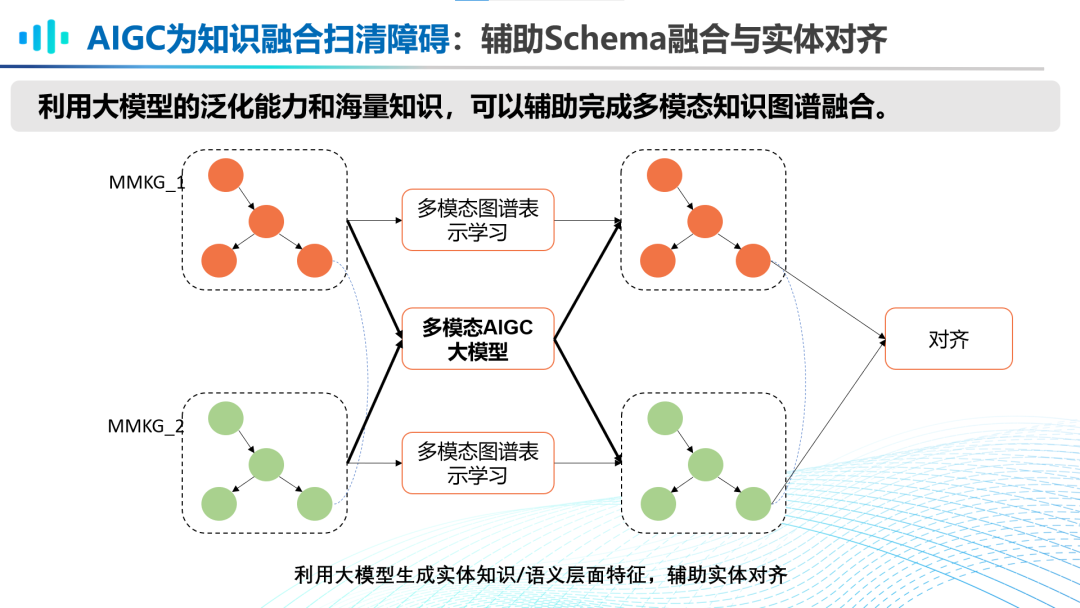
第四,AIGC大模型为知识融合扫清障碍。
利用大模型的泛化能力和海量知识,可以辅助完成多模态知识图谱融合。利于对于两个MMKG的对齐,多模态AIGC大模型在两者之间可以生成实体知识或语义层面的特征,辅助完成实体对齐。
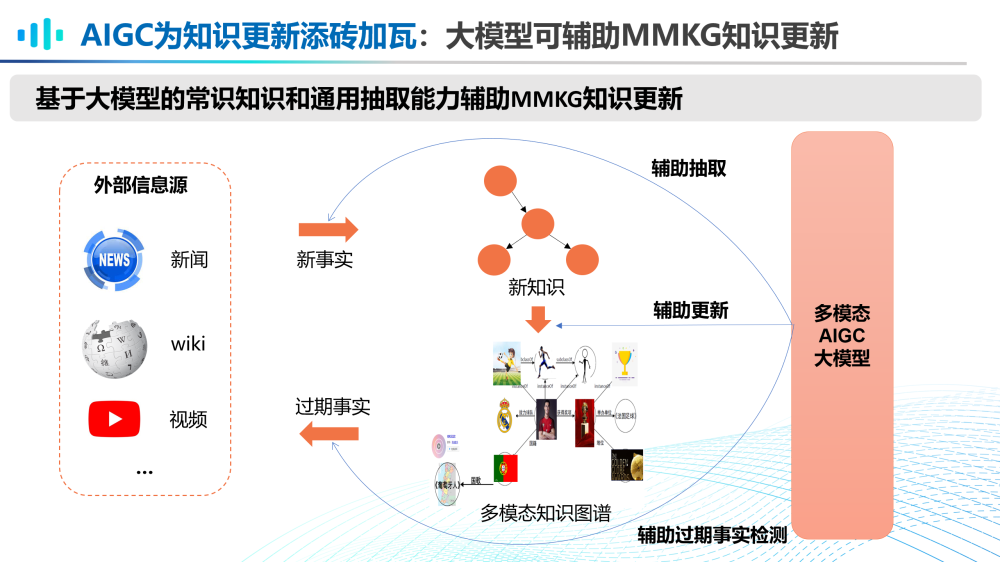
第五,AIGC大模型为知识更新舔砖加瓦。
基于大模型的常识知识和通用抽取能力可以辅助MMKG进行知识更新。可以利用多模态AIGC大模型从新事实中辅助抽取新知识;当新知识抽取完成后,可以借助多模态AIGC大模型辅助更新多模态知识图谱。此外,还可以借助多模态AIGC大模型辅助过期事实检测,从而将过期知识从知识图谱中删除。
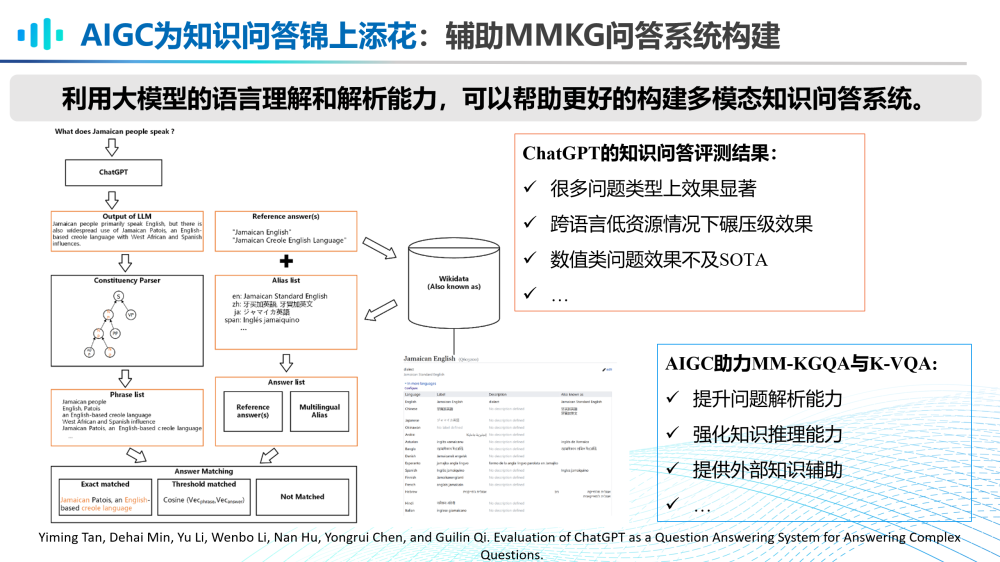
第六,AIGC大模型为知识问答锦上添花。
利用大模型的语言理解能力和解析能力,可以帮助更好的构建多模态知识问答系统。在ChatGPT的知识问答评测结果显示其在很多问题类型上效果显著,且跨语言低资源情况下具有碾压级效果,但是其数值类问题效果不及SOTA。因此,使用AIGC大模型助力MM-KGQA和K-VQA等任务,可以提升问题解析能力,强化知识推理能力,提供外部知识辅助等。
05
MMKG for AIGC
第五部分,我们总结与展望一下MMKG如何助力AIGC大模型的提升与完善。
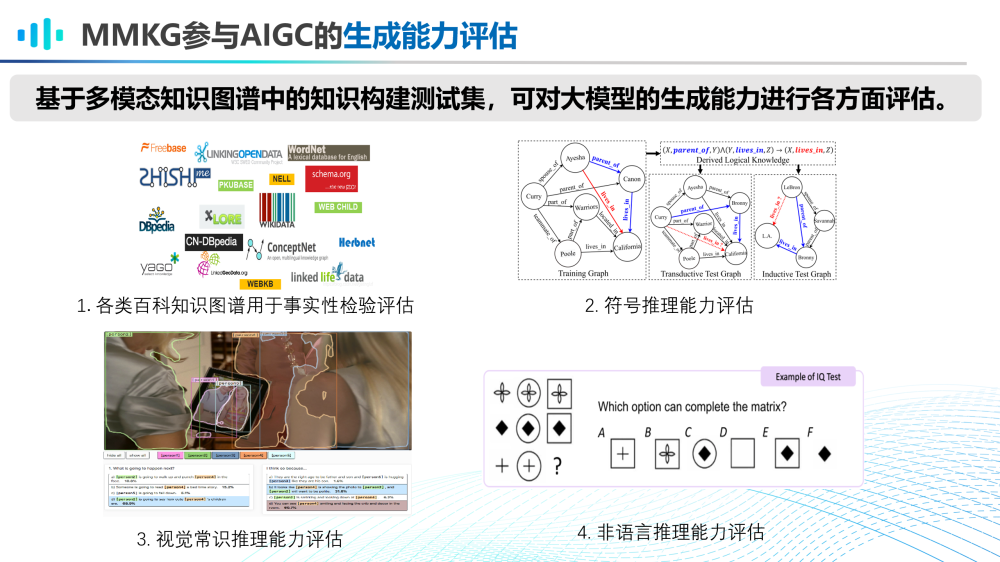
第一,MMKG参与AIGC大模型的生成能力评估。
基于多模态知识图谱中的知识构建测试集,可对大模型的生成能力进行各方面评估。例如利用各类百科知识图谱进行事实性检验评估,也可以利用各类MMKG构建测试集进行符号推理能力评估、视觉常识推理能力评估、非语言推理能力评估等。
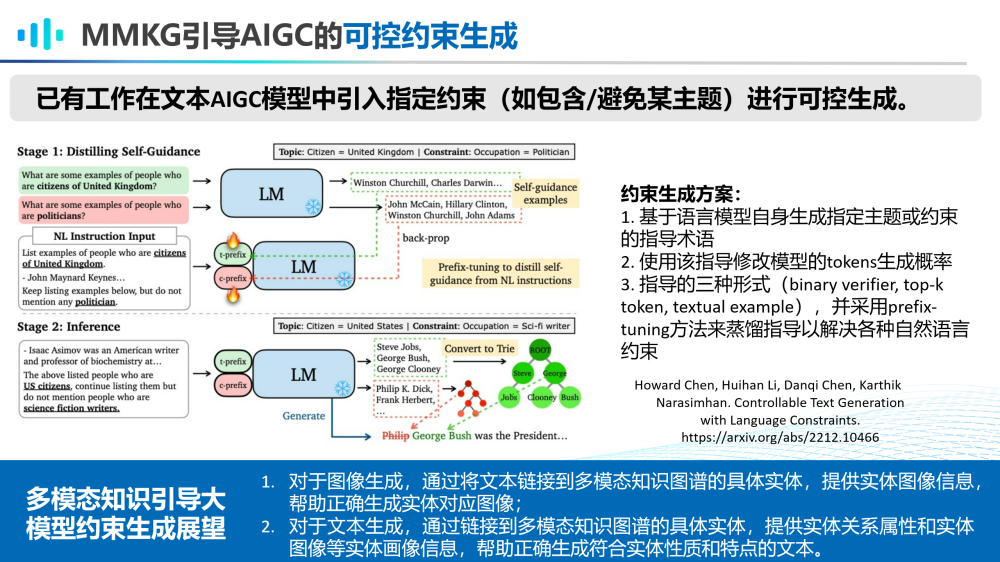
第二,MMKG引导AIGC大模型的可控约束生成。
已有工作在文本AIGC模型中引入指定约束(如包含/避免某主题)进行可控生成。可以展望未来会出现多模态知识引导大模型约束生成的工作。比如对于图像生成,可通过将文本链接到多模态知识图谱的具体实体,提供实体图像信息,帮助正确生成实体对应图像;对于文本生成,通过链接到多模态知识图谱的具体实体,提供实体关系属性和实体图像等实体画像信息,帮助正确生成符合实体性质和特点的文本。
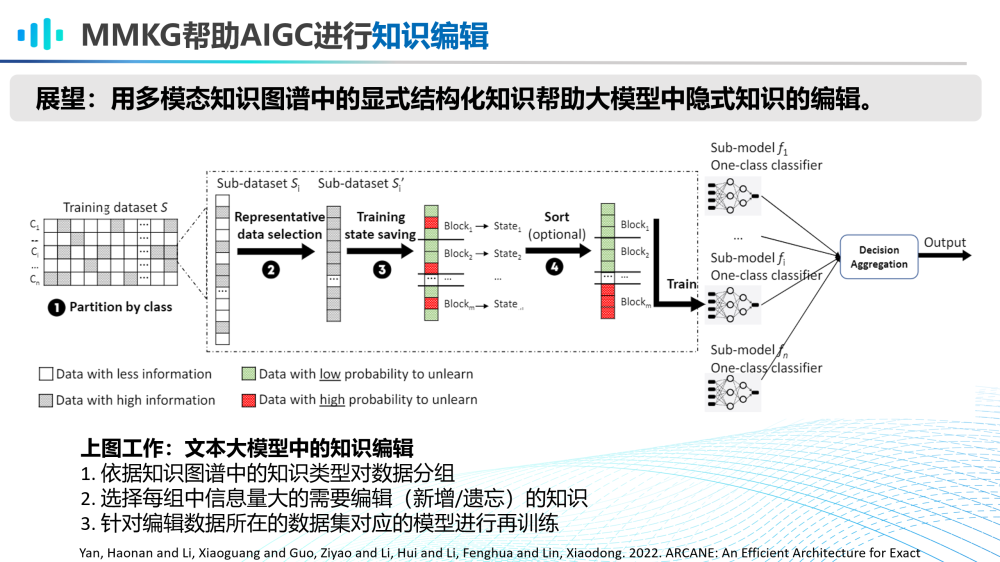
第三,MMKG帮助AIGC大模型进行知识编辑。
目前已有在文本大模型上的知识编辑的相关工作。可以预见,未来也会出现利用多模态知识图谱来对多模态大模型进行知识编辑的研究工作。
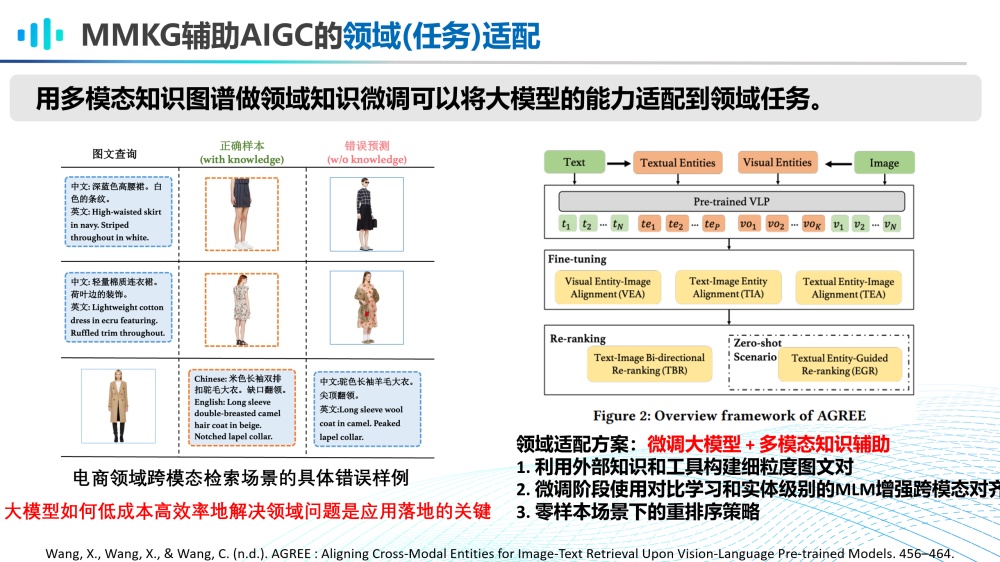
第四,MMKG辅助AIGC大模型的领域(任务)适配。
用多模态知识图谱做领域知识微调可以将大模型的能力适配到领域任务。例如,在电商领域跨模态检索场景,常常存在语义不匹配的问题。这种情况下,大模型如何低成本、高效率地解决该领域的具体问题是其应用落地的关键。我们与阿里合作的这篇工作提出了通过微调大模型,加上多模态知识辅助的方式,实现了大模型的轻量级领域适配。
06
AIGC+MMKG
第六部分,我们展望一下AIGC大模型和MMKG如何进一步合作。
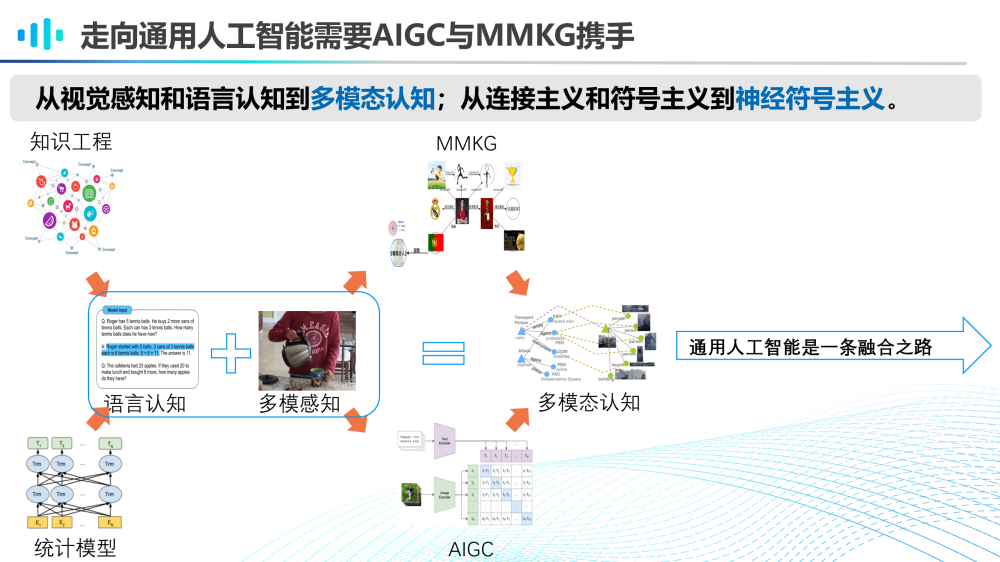
我们认为,走向通用人工智能需要AIGC大模型和MMKG携手并进。在未来,基于知识工程和统计模型的语言认知和多模态感知将会相互结合,并且借助MMKG和AIGC大模型,共同走向多模态认知的发展道路上。从视觉感知和语言认知到多模态认知,从连接主义和符号主义到神经符号主义,通用人工智能必将是一条融合之路。

AIGC和MMKG的第一种融合方式是注入知识以增强预训练大模型。目前知识增强的预训练语言模型已有多种路径实现。在多模态知识增强预训练的方向上,也有工作将场景图知识融入视觉语言预训练模型的预训练过程中以增强跨模态语言理解能力。未来还有很多方式方法来将MMKG中的知识以更多方式融入到大模型当中。
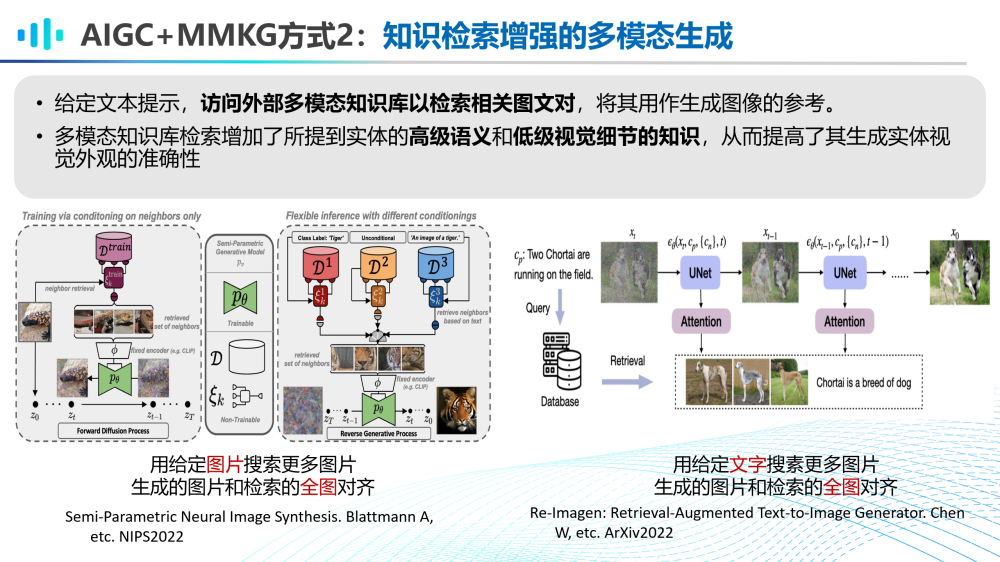
AIGC和MMKG的第二种融合方式是基于知识检索增强的多模态生成。例如,给定文本提示,访问外部多模态知识库以检索相关图文对,将其用作生成图像的参考。
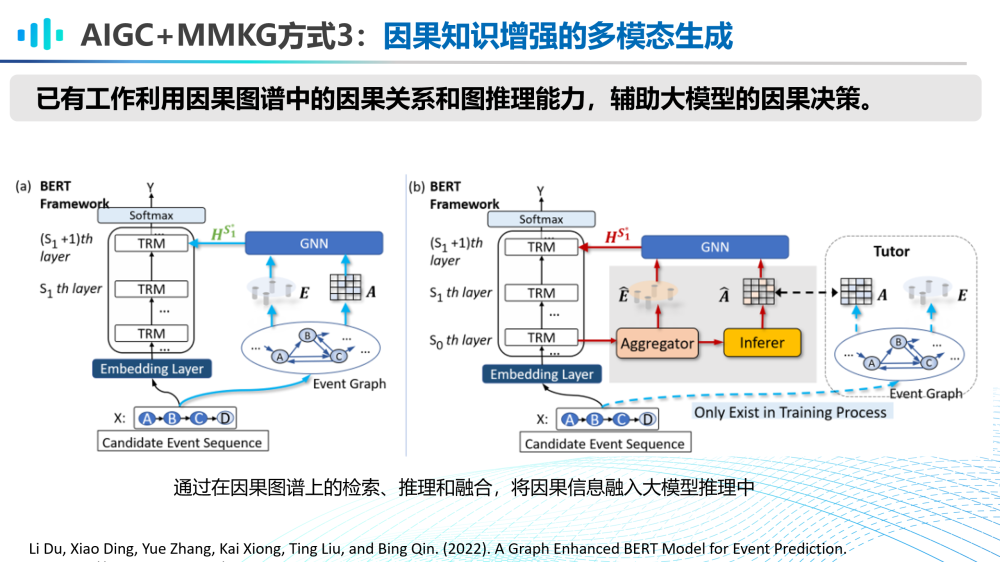
AIGC和MMKG的第三种融合方式是因果知识增强的多模态生成。已有工作利用因果图谱中的因果关系和图推理能力,辅助大模型的因果决策,通过在因果图谱上的检索、推理和融合将因果信息融入大模型推理中。可以展望,未来因果知识也可被用在对多模态大模型的理解与生成能力优化上。
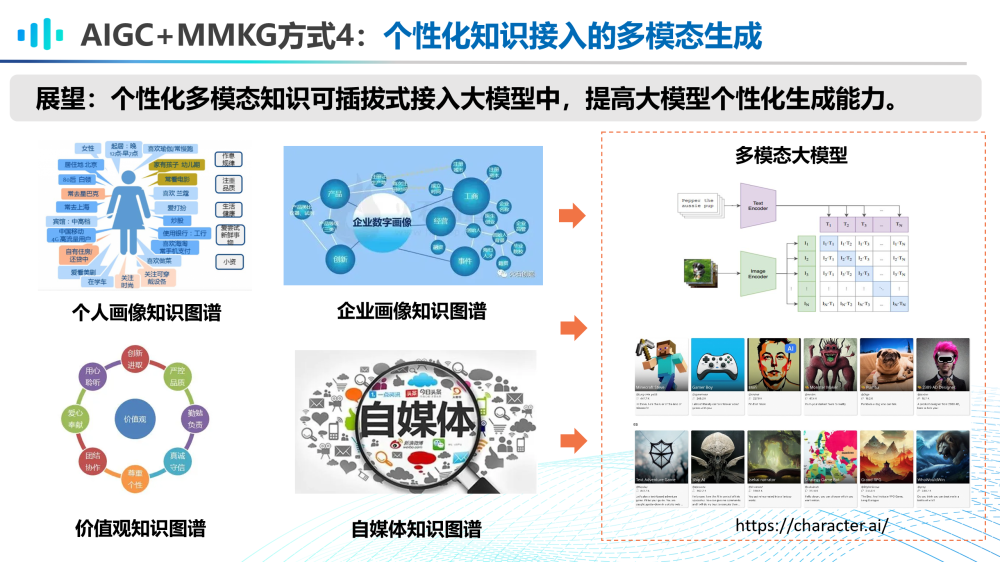
AIGC和MMKG的第四种融合方式是个性化知识接入的多模态生成。在未来,或许每个个体或企业都会拥有AI私有化助手,那么如何管理个性化多模态知识,诸如个人画像知识图谱、企业画像知识图谱、价值观知识图谱、自媒体知识图谱等,将这些知识以一种可插拔式的方式接入AIGC大模型中,提高大模型的个性化生成能力将是非常值得探索的方向。

实际上,Microsoft 365 Copilot就可以看作是知识库与大模型良好协作的一款划时代产品。借助Microsoft Graph(可以看做是一种知识库)与AIGC大模型的协作融合,助力Word、PowerPoint、Excel的生产力大提升。
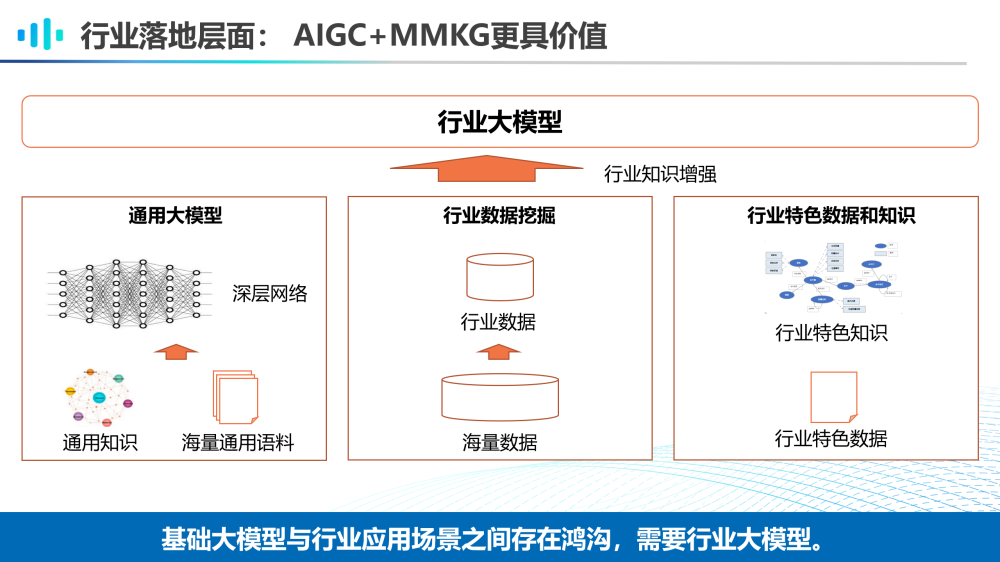
此外,在行业落地层面,AIGC大模型和MMKG的融合更具价值。由于利用海量通用语料和通用知识训练的通用大模型与william hill官网 场景之间依然存在鸿沟,因此需要进行行业数据挖掘和行业特色知识获取来进一步训练更加实用的行业大模型。

基于上述原因,行业落地往往需要多层次的模型,并有效与知识库和外部工具进行配合,才能真正解决好行业问题。通用多模态预训练生成大模型、行业领域预训练模型、任务小模型以及行业知识库、外部工具将构成一个模型共同体,协作解决行业复杂问题。
07
总 结

最后总结一下本次分享的主要观点。首先,AIGC威廉希尔官方网站 的发展必将加速迈向通用人工智能的步伐。但是仅凭AIGC威廉希尔官方网站 无法真正实现通用人工智能。在多模态领域,MMKG的构建与应用仍具重要价值。我们认为,AIGC和MMKG应该相互借力,我们分别从AIGC用于MMKG、MMKG用于AIGC、MMKG和AIGC如何融合三方面给出了二者竞合方式的探索和展望。未来,符号知识和统计模型的竞合方式有待进一步深入探索。
审核编辑 :李倩
-
AI
+关注
关注
87文章
30830浏览量
268984 -
深度学习
+关注
关注
73文章
5503浏览量
121139 -
ChatGPT
+关注
关注
29文章
1560浏览量
7624
原文标题:AIGC时代的多模态知识工程思考与展望
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
多文化场景下的多模态情感识别
AI下一个风口来临 AIGC产业生态迎来发展快车道
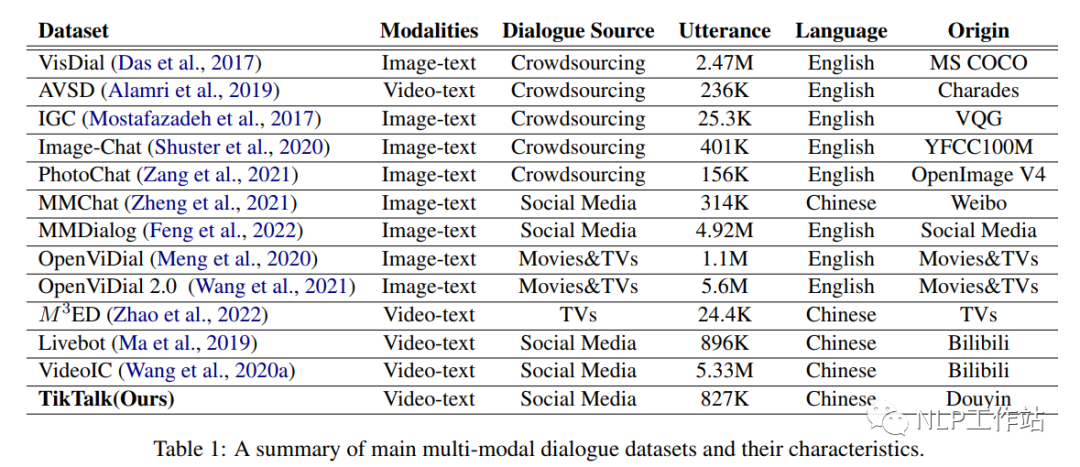
中文多模态对话数据集
AIGC最新综述:从GAN到ChatGPT的AI生成历史
ChatGPT/AIGC研究框架原理和应用实践
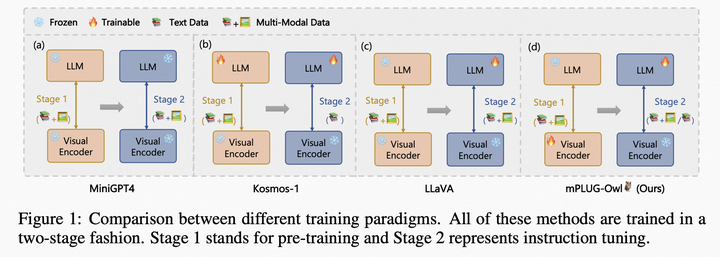
如何利用LLM做多模态任务?
威廉希尔官方网站 与市场:为具身智能突破威廉希尔官方网站 瓶颈:AIGC
展望时代增量 “AIGC浪潮与算力变革”媒体沙龙在京召开

创芯派 | 专访青丘片场:AIGC威廉希尔官方网站 驱动下的创意视频革新之路

VisCPM:迈向多语言多模态大模型时代

DreamLLM:多功能多模态大型语言模型,你的DreamLLM~

华为战略研究院院长周红:面向智能时代的思考和展望






 工商网监
工商网监
评论