 从FPGA说起的深度学习:任务并行性
从FPGA说起的深度学习:任务并行性
这是新的系列教程,在本教程中,我们将介绍使用 FPGA 实现深度学习的威廉希尔官方网站 ,深度学习是近年来人工智能领域的热门话题。
在本教程中,旨在加深对深度学习和 FPGA 的理解。
用 C/C++ 编写深度学习推理代码
高级综合 (HLS) 将 C/C++ 代码转换为硬件描述语言
FPGA 运行验证
从这篇文章中,我们将从之前创建的网络模型中提取并行性,并确认处理速度得到了提高。首先,我们检查当前模型的架构,并考虑什么样的并行化是可性的。
并行化方法研究
当前模型架构的框图如下所示。限于篇幅省略了maxpool2d和relu。
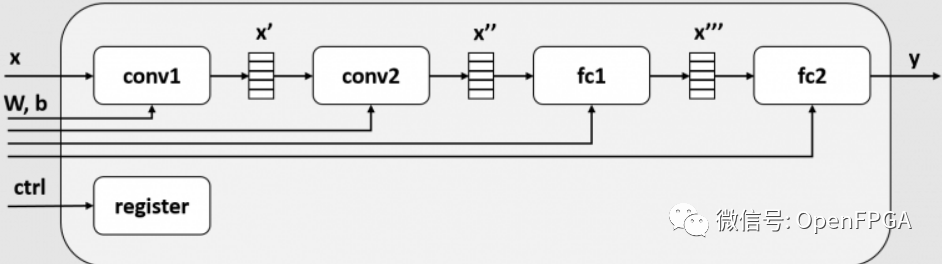
在这个模块中,conv1、conv2、fc1、fc2都是作为不同的模块实现的。FPGA内部的SRAM在每一层之间插入一个缓冲区(x', x'', x''' ),这个缓冲区成为每一层的输入和输出。此后,每一层(conv1、conv2、fc1、fc2)被称为一个任务。
顺序处理(基线)
下图显示了使用该模块对 3 帧图像执行推理处理时的执行时间可视化。
每个任务的执行时间以推理模块的实际运行波形为准,是conv2>conv1>fc1>fc2的关系。在该模块中,conv1、conv2、fc1和fc2作为单独的任务实施,但是这些任务一次只能运行一个(后面会解释原因)。因此,如果将conv1、conv2、fc1、fc2各层的执行时间作为最终的执行时间,则这3帧图像的t0, t1, t2, t3处理时间为3 * (t0 + t1 + t2 + t3)

任务并行度
假设我们可以修复这些任务并发运行。这种情况下的执行时间如下所示,多个任务可以同时处理不同的帧。

提取并行性使多个任务可以同时运行,称为任务并行化。在这个过程中,conv2的执行时间占主导地位,所以3帧的处理时间为t0 + 3 * t1 + t2 + t3。
理想的任务并行度
最后,我们考虑可以理想地执行任务并行化的模式。如上所述,如果只提取任务并行性,最慢的任务就会成为瓶颈,整体处理速度会受到该任务性能的限制。因此,最有效的任务并行是所有任务都具有相同的执行时间。

在这种情况下,处理时间t0 + 3 * t1 + t2 + t3保持不变,但t0 = t1 = t2 = t3调整了每个任务的执行时间,从而提高了性能。在本课程中,实现这种加速的威廉希尔官方网站 被称为循环并行化和数据并行化。这两种并行度提取方法将在下一篇文章中介绍。
任务并行化
在本文中,第一个目标是执行任务并行化。
由于这次创建的模块中有多个任务,貌似已经可以并行处理了,但在实际波形中并不是这样。之所以不能并行化,是因为作为x', x'', x'''任务间接口的buffer()不能被多个任务同时使用。对于任务并行化,任务之间的接口必须可以同时被两个或多个任务读写。
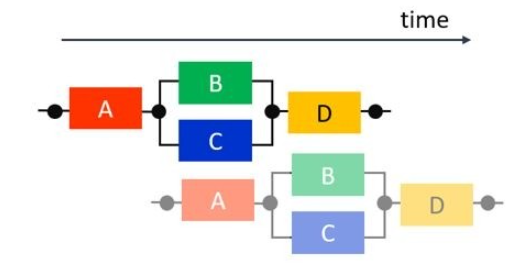
在这个模块x'中,任务级并行化是通过在任务之间使用乒乓缓冲区来实现的。乒乓缓冲区有两个缓冲区,一个用于写入,一个用于读取。带有乒乓缓冲器的框图如下所示:
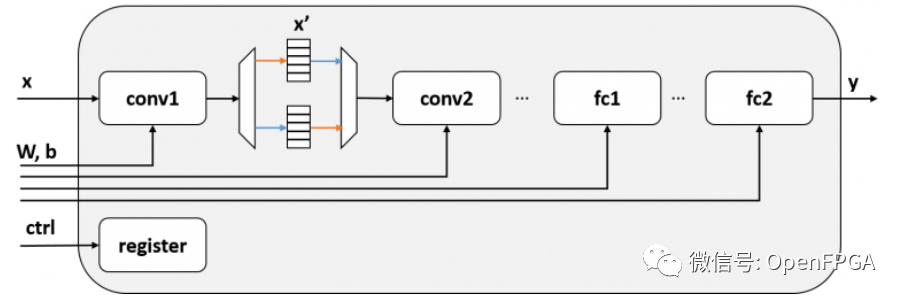 带有乒乓缓冲器的推理模块
带有乒乓缓冲器的推理模块
如果以这种方式配置电路,存储 conv1 输出的缓冲区和 conv2 从中读取输入的缓冲区是分开的,因此 conv1 和 conv2 可以同时运行。虽然图中省略了,但所有层都可以通过双缓冲conv2 <-> fc1,fc1 <-> fc2同时操作。
要在 RTL 中实现这一点,准备两个缓冲区并实现切换机制会很麻烦,但在 Vivado/Vitis HLS 中,只需添加一些 pragma 即可实现这种并行化。
代码更改
对于此任务并行化,我们需要添加以下三种类型的编译指示。
#pragmaHLSdataflow #pragmaHLSstable #pragmaHLSinterfaceap_ctrl_chain
在解释每个pragma的作用之前,我先inference_dataflow展示一下新增函数的源代码。与第五篇中的inference_top函数重叠的部分省略。
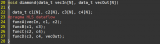
60voidinference_dataflow(constfloatx[kMaxSize],
61constfloatweight0[kMaxSize],constfloatbias0[kMaxSize],
62constfloatweight1[kMaxSize],constfloatbias1[kMaxSize],
63constfloatweight2[kMaxSize],constfloatbias2[kMaxSize],
64constfloatweight3[kMaxSize],constfloatbias3[kMaxSize],
65floaty[kMaxSize]){
66#pragmaHLSdataflow
67#pragmaHLSinterfacem_axiport=xoffset=slavebundle=gmem0
...
76#pragmaHLSinterfacem_axiport=yoffset=slavebundle=gmem9
77#pragmaHLSinterfaces_axiliteport=xbundle=control
...
86#pragmaHLSinterfaces_axiliteport=ybundle=control
87#pragmaHLSinterfaces_axiliteport=returnbundle=control
88#pragmaHLSinterfaceap_ctrl_chainport=returnbundle=control
89
90#pragmaHLSstablevariable=x
91#pragmaHLSstablevariable=weight0
92#pragmaHLSstablevariable=bias0
93#pragmaHLSstablevariable=weight1
94#pragmaHLSstablevariable=bias1
95#pragmaHLSstablevariable=weight2
96#pragmaHLSstablevariable=bias2
97#pragmaHLSstablevariable=weight3
98#pragmaHLSstablevariable=bias3
99#pragmaHLSstablevariable=y
100
101dnnk::inference(x,
102weight0,bias0,
103weight1,bias1,
104weight2,bias2,
105weight3,bias3,
106y);
107}
第66 行添加#pragma HLS dataflow的 pragma使inference_dataflow这些内部函数之间的接口成为乒乓缓冲区并启用任务并行化。第 101 行调用的函数dnnk::inference是下面的函数,它通过第 20 行的#pragma HLS inline编译指示在函数内inference_dataflow内嵌展开。因此,诸如 conv2d, relu的函数符合任务并行化的条件,它们的接口 ( x1, x2, ...) 是一个乒乓缓冲区。
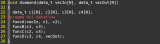
14staticvoidinference(constfloat*x, 15constfloat*weight0,constfloat*bias0, 16constfloat*weight1,constfloat*bias1, 17constfloat*weight2,constfloat*bias2, 18constfloat*weight3,constfloat*bias3, 19float*y){ 20#pragmaHLSinline ... 34 35//1stlayer 36conv2d(x,weight0,bias0,kWidths[0],kHeights[0],kChannels[0],kChannels[1],3,x1); 37relu(x1,kWidths[0]*kHeights[0]*kChannels[1],x2); 38maxpool2d(x2,kWidths[0],kHeights[0],kChannels[1],2,x3); 39 ... 48 49//4thlayer 50linear(x8,weight3,bias3,kChannels[3],kChannels[4],y); 51}
inference_dataflow从函数的第90行#pragma HLS stable开始,在x, weight0, y输入/输出等函数inference_dataflow的入口/出口处自动完成同步。如果不去掉这个同步,两个进程之间就会产生依赖,比如“上一帧y输出完成->下一帧x输入准备好”,多任务就不行了。另请参阅Vivado HLS 官方文档 ( UG902 ),了解有关稳定阵列部分的详细说明。
最后,inference_dataflow该函数第88行的pragma修改了外部寄存器接口,使得#pragma HLS interface ap_ctrl_chain port=return该函数可以用于同时处理多个帧。inference_dataflow如果没有这个 pragma,即使你实现了 ping-pong 缓冲区,主机端也只会尝试一个一个地执行它们,性能不会提高。
综合结果确认
可以在检查综合时检查任务并行化是否顺利进行。
下面是HLS综合结果报告,Latency -> Summary一栏列出了整个函数的延迟和执行间隔(Interval)。在这里,整体延迟仍然是所有任务处理时间的总和,但执行间隔的值conv2d_232_U0与第二个卷积层的执行周期数相匹配。该模块的吞吐量是第二个卷积层执行间隔的倒数。
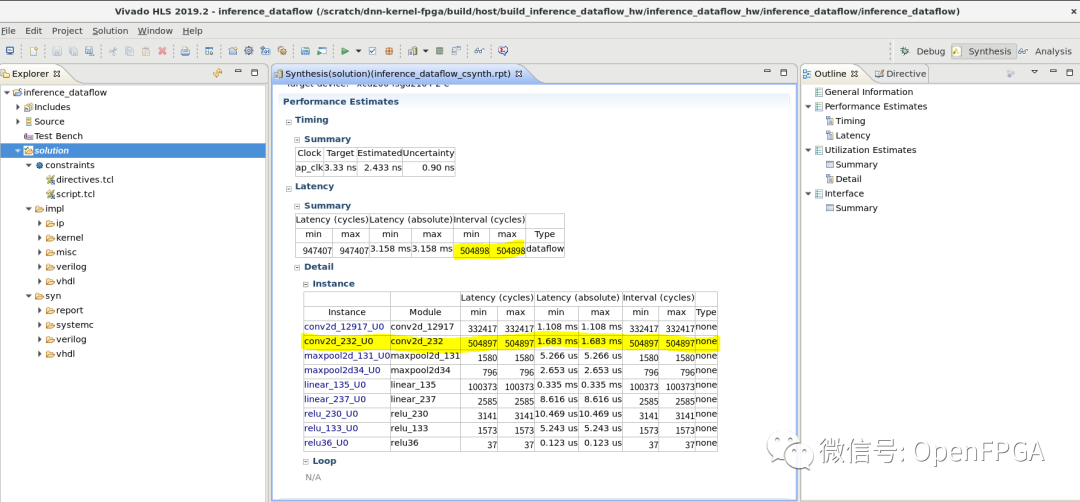
正如本文开头所解释的,conv2d_232_U0处理时间成为此任务并行化后电路中的瓶颈。任务并行化的速度提升率为947407 / 504898 = 1.88倍。
通过这种方式,我们能够确认 HLS 能够正确实现任务并行化。
总结
在本文中,我们通过提取任务并行性来加速处理。本来conv2占用了一半以上的执行时间,所以提速幅度不到2倍,如果设置为N,最大提速为N倍。
在下一篇文章中,我们将通过对卷积层应用数据并行化和循环并行化来解决每一层处理时间的不平衡。
-
FPGA
+关注
关注
1629文章
21735浏览量
603150 -
人工智能
+关注
关注
1791文章
47244浏览量
238360 -
C++
+关注
关注
22文章
2108浏览量
73636 -
模型
+关注
关注
1文章
3238浏览量
48824 -
深度学习
+关注
关注
73文章
5503浏览量
121136
原文标题:从FPGA说起的深度学习(六)-任务并行性
文章出处:【微信号:Open_FPGA,微信公众号:OpenFPGA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于HLS之任务级并行编程
FPGA在人工智能中的应用有哪些?
FPGA做深度学习能走多远?
Python中的并行性和并发性分析
什么是深度学习?使用FPGA进行深度学习的好处?
算法隐含并行性的物理模型
FPGA在深度学习领域的应用
如何在不需要特殊库或类的情况下实现C代码并行性?
从FPGA说起的深度学习
从FPGA说起的深度学习:数据并行性






 工商网监
工商网监
评论