 速度面积互换设计原则简析
速度面积互换设计原则简析
速度和面积一直都是FPGA设计中非常重要的两个指标。所谓速度,是指整个工程稳定运行所能够达到的最高时钟频率,它不仅和FPGA内部各个寄存器的建立时间余量、保持时间余量有关,也和FPGA与外部芯片接口信号的时序余量有关;
当然,由于FPGA的时钟频率通常很容易遇到瓶颈,所以有时我们更趋向于在特定时钟频率下,用单位时间内的数据吞吐量指标作为速度的衡量指标。所谓面积,就是一个FPGA工程运行所消耗的资源的多少。在FPGA资源相对单一匮乏的年代,工程师们可以简单的将逻辑资源等效为门数进行衡量;
而今天随着FPGA内嵌越来越多的存储器、乘法器、时钟单元、高速走线或高速收发器等资源,FPGA资源所涵盖的项目也越来越多。无论如何,设计者对这两个参数的关注将会贯穿整个设计的始终。
速度和面积始终是一对矛盾的统一体。速度的提高往往需要以面积的扩增为代价,而节省面积也往往会造成速度的牺牲。因此,如何在满足时序要求(速度)的前提下最大程度的节省逻辑资源(面积)是摆在每个设计者面前的一个难题。
如图3.12所示,假定当我们使用1倍的逻辑块处理数据,其时钟频率100Mhz,可以达到100Mbps的吞吐量。
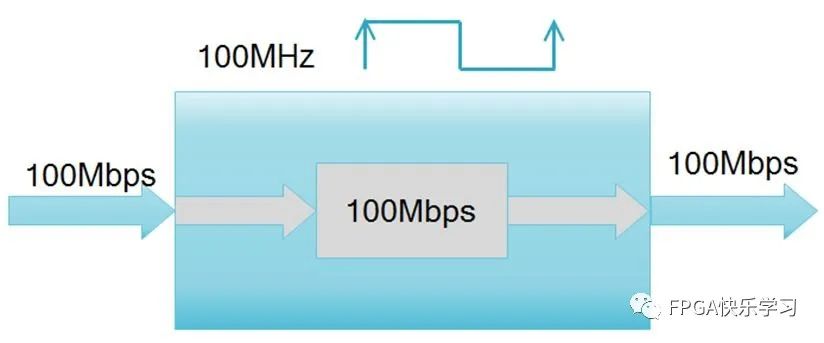
图3.12 1倍资源的数据吞吐量示意图
而当我们的需求有所改变,希望数据吞吐量达到300Mbps。你可能觉得,这不挺简单,如图3.13所示,直接让时钟频率调整到300MHz不就可以了。但凡有一定实践经验的工程师都要抗议了,一般的FPGA器件,除非你的逻辑功能非常简单,否则要跑到300MHz谈何容易。
笔者用得比较多的是Xilinx中低端的Artix-7和Kintex-7系列的FPGA器件,通常也不太敢随便使用超过200MHz的时钟频率。时钟频率不仅受限于器件本身的工艺,也和设计逻辑的复杂性密切相关。所以一般而言,通过直接提高时钟频率来提升系统数据吞吐量的方法只在原时钟频率较低的情况下可行,但原本时钟频率就偏高的情况下是不可行的。
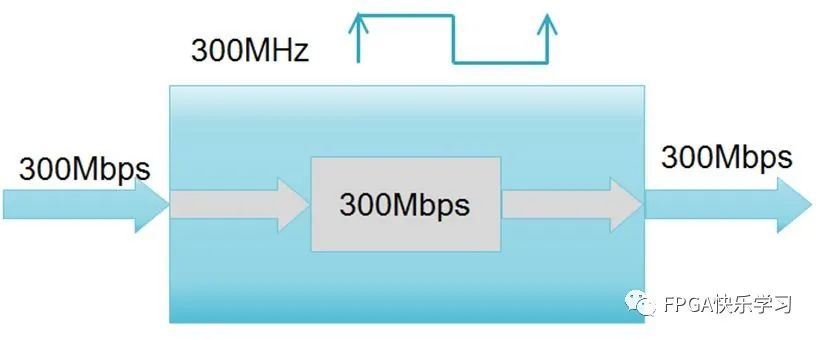
图3.13 3倍时钟频率的数据吞吐量示意图
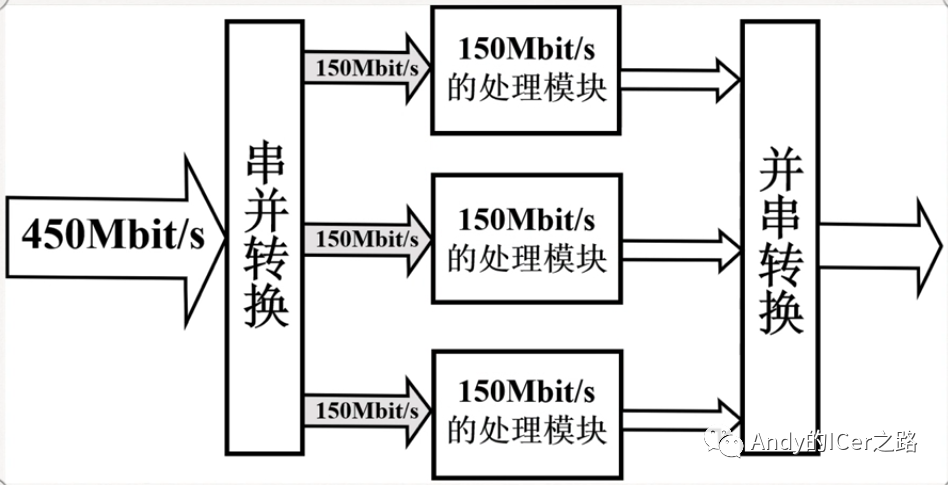
当系统时钟频率已经接近上限,或由于某些其它因素无法随意提升的情况下,更一般的做法,如图3.13所示,就是使用3倍的逻辑资源,即3倍的逻辑块,这就是简单的以面积换速度(牺牲面积,换取速度)的思想,反之,就是速度换面积(牺牲速度,换取面积)的思想。
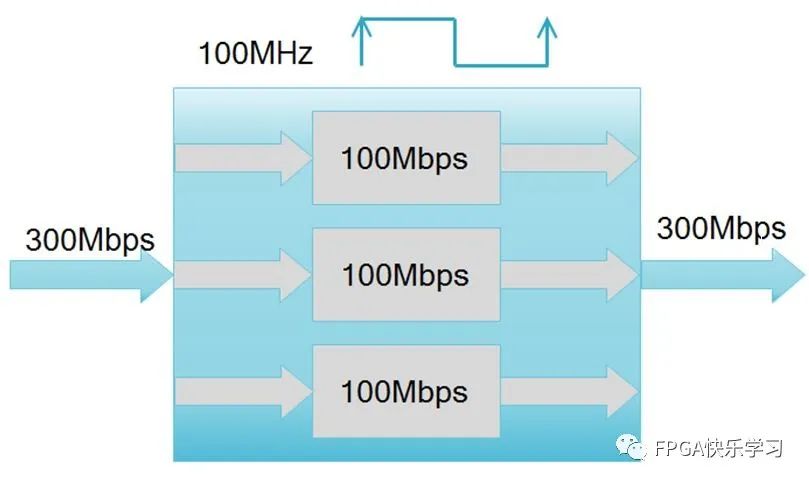
图3.13 3倍资源的数据吞吐量示意图
速度和面积互换原则也可以应用在一般逻辑的性能优化上。比如在FPGA开发工具中,通常也会提供一些预设好的综合优化策略,设计者可以在速度或面积等方面采取不同的综合偏好,这样就把整个代码的优化工作交由工具来实现。当然,综合工具只能在现有代码基础上做一些小范围的修修改改,达到优化的目的,一些大的性能优化还是需要靠设计者自己的代码实现。
以Xilinx的Vivado开发工具为例,如图3.14所示,在Setting -> Synthesis页面的Options ->Strategy选项中,默认采取的综合策略是一个速度和面积比较平衡的Vivado SynthesisDefaults策略。这里我们可以尝试一下将默认策略修改为Flow_PerfOptimized_high,然后看看编译后的资源和时序性能发生了什么样的变化。
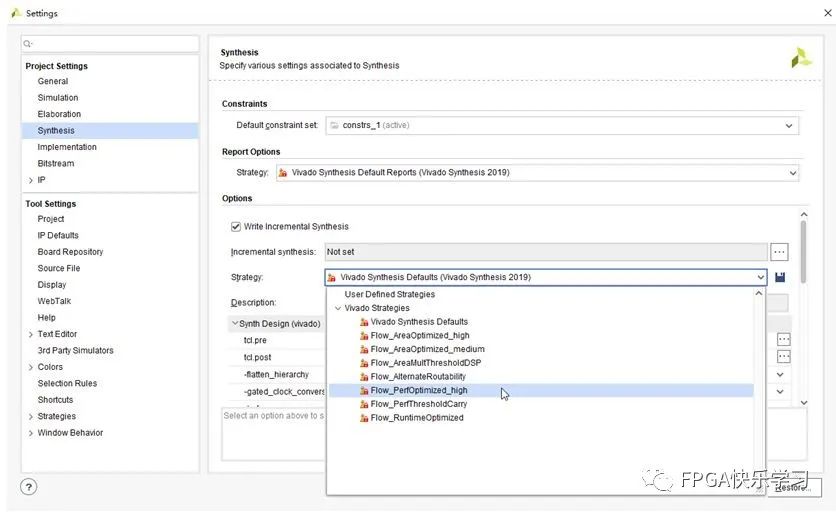
图3.14 Vivado综合优化选项
以一个图像采集和显示的实例工程(note10_prj001)进行比对。如图3.15所示,使用默认策略的综合消耗了5798个LUT。如图3.16所示,使用高性能优化策略的综合则消耗了5878个LUT,多消耗了80个LUT。
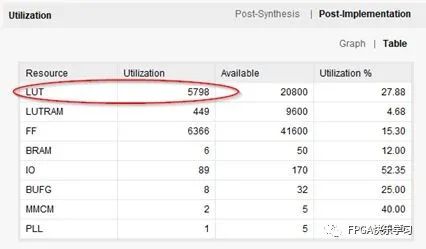
图3.15 默认综合策略的资源报告
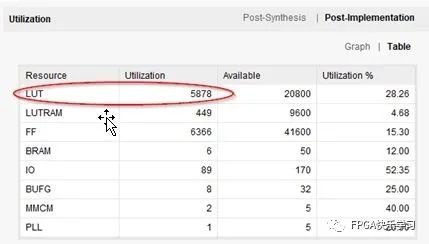
图3.16 高性能优化策略的资源报告
再来看时序性能,我们挑选驱动负载最大的两个时钟做比对。如图3.17和图3.18所示,可以看到,时钟负载最大的clk_out2的建立时间余量(WNS)和保持时间余量(THS)都略微有所提升;但时钟负载次之的clk_out3的两个余量参数反而都略微下降了。

图3.17 默认总和策略的时钟报告

图3.18 高性能优化策略的时钟报告
由此看来,关于速度和面积互换的思想,综合工具虽然提供了一些整体的代码性能优化手段,但是它对整体性能的提升充其量不过是个“小打小闹”的级别,最主要的优化其实还是要靠写代码的设计者。
审核编辑:刘清
-
FPGA设计
+关注
关注
9文章
428浏览量
26513 -
存储器
+关注
关注
38文章
7484浏览量
163776 -
时钟
+关注
关注
10文章
1733浏览量
131461 -
乘法器
+关注
关注
8文章
205浏览量
37046 -
代码
+关注
关注
30文章
4780浏览量
68540
原文标题:经典设计思想:速度面积互换原则
文章出处:【微信号:FPGA快乐学习,微信公众号:FPGA快乐学习】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐







 工商网监
工商网监
评论