 基于预训练语言模型设计了一套统一的模型架构
基于预训练语言模型设计了一套统一的模型架构
本文介绍了本小组发表于ICLR 2023的论文UniKGQA,其基于预训练语言模型设计了一套统一的模型架构,同时适用于多跳KBQA检索和推理,在多个KBQA数据集上取得显著提升。

该论文发表于 ICLR-2023 Main Conference:
论文链接:https://arxiv.org/pdf/2212.00959.pdf
开源代码:https://github.com/RUCAIBox/UniKGQA
进NLP群—>加入NLP交流群(备注nips/emnlp/nlpcc进入对应投稿群)
前言
如何结合PLM和KG以完成知识与推理仍然是一大挑战。我们在NAACL-22关于常识知识图谱推理的研究 (SAFE) 中发现,PLM 是执行复杂语义理解的核心。因此,我们深入分析了已有的复杂 GNN 建模外部 KG 知识的方法是否存在冗余。最终,基于发现,我们提出使用纯 MLP 轻量化建模辅助 PLM 推理的 KG 知识,初步探索了 PLM+KG 的使用方法。
进一步,本文研究了在更依赖 KG 的知识库问答任务中如何利用 PLM。已有研究通常割裂地建模检索-推理两阶段,先从大规模知识图谱上检索问题相关的小子图,然后在子图上推理答案节点,这种方法忽略了两阶段间的联系。我们重新审视了两阶段的核心能力,并从数据形式,模型架构,训练策略三个层面进行了统一,提出UniKGQA。同时受 SAFE 启发,我们认为 KG 仅为执行推理的载体,因此 UniKGQA 架构的设计思考为:核心利用 PLM 匹配问题与关系的语义,搭配极简 GNN 在 KG 上传播匹配信息,最终推理答案节点。针对这样的简洁架构,我们同时设计了一套高效的训练方法,使得 UniKGQA 可以将检索的知识迁移到推理阶段,整体性能更高效地收敛到更好的表现。实验证明,在多个标准数据集上相较于已有 SOTA,取得显著提升。
一、研究背景与动机
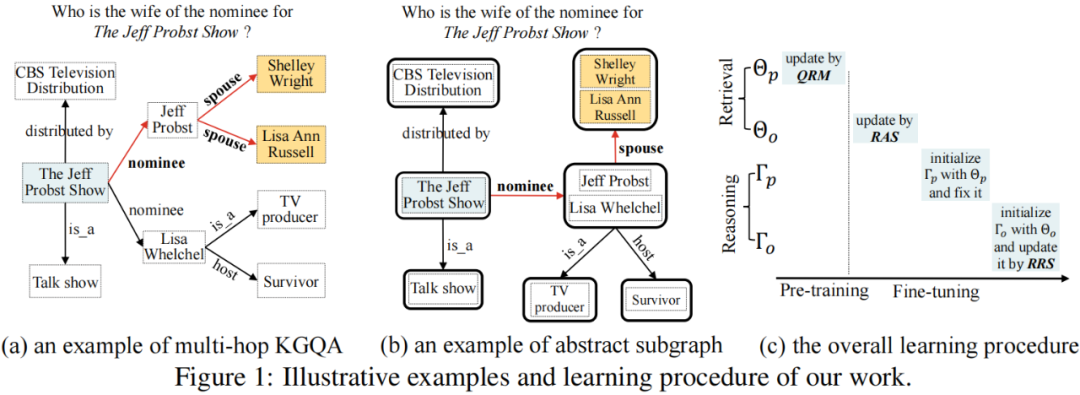
1、多跳知识库问答
给定一个自然语言问题 和一个知识图谱 ,知识图谱问答 (KGQA) 旨在从知识图谱上寻找答案集合,表示为 。我们在图1 (a)中展示了一个例子。给定问题:Who is the wife of the nominee for The Jeff Probst Show?,该任务的目标是从主题实体 The Jeff Probst Show 开始,寻找匹配问题语义的推理路径 nominee --> spouse,最终得到答案实体 Shelley Wright 和 Lisa Ann Russell。已有研究通常假设问题中提到的实体 (例如图1 (a)中的The Jeff Probst Show) 被标记并链接到知识图谱上,即主题实体,表示为 。
本文关注多跳 KGQA 任务,即答案实体和主题实体在知识图谱上距离多跳。考虑到效率和精度之间的平衡,我们遵循已有工作,通过检索-推理两阶段框架解决此任务。具体而言,给定一个问题 和主题实体 ,检索阶段旨在从超大知识图谱 中检索出一个小的子图 ,而推理阶段则在检索子图 上推理答案实体 。
2、研究动机
虽然两个阶段的目的不同,但是两个阶段都需要评估候选实体与问题的语义关联性 (用于检索阶段remove或推理阶段rerank)。本质上,上述过程可以被视为一个语义匹配问题。由于 KG 中实体与实体间的联系通过关系表示,为了衡量实体的相关性,在构建语义匹配模型时,基于关系的特征(直接的一跳关系或复合的多跳关系路径),都被证明是特别有用的。如图1 (a)所示,给定问题,关键是要在知识图谱中识别出与问题语义匹配的关系及其组成的关系路径 (例如nominee --> spouse),以找到答案实体。
由于两个阶段处理知识图谱时,面临的搜索空间尺度不同 (例如,检索时数百万个实体结点与推理时数千个实体结点),已有方法通常割裂地为两阶段考虑对应的解决方案:前者关注如何使用更高效的方法提升召回性能,而后者关注如和利用更细粒度的匹配信号增强推理。这种思路仅将检索到的三元组从检索阶段传递到推理阶段,而忽略了整个流程中其他有用的语义匹配信号,整体性能为次优解。由于多跳知识图谱问答是一项非常具有挑战性的任务,我们需要充分利用两个阶段习得的各种能力。
因此,本文探讨能否设计一个统一的模型架构来为两个阶段提供更好的性能?如果这样,我们可以紧密关联两阶段并增强习得能力的共享,从而提升整体性能。
二、UniKGQA:适用于检索和推理的统一架构
然而,实现统一的多跳 KGQA 模型架构面临两个主要挑战: (1) 如何应对两个阶段的搜索空间尺度差异很大的问题? (2) 如何在两个阶段之间有效地共享或传递习得的能力? 考虑到这些挑战,我们从数据形式,模型架构,训练策略三方面进行探索,最终对两阶段的模型架构进行了统一。
1、数据形式
在 KG 中,存在大量的一对多现象,例如,头实体为中国,关系为城市,那么存在多个尾实体,每个尾实体又会存在各自的一对多现象,使得图的规模随跳数成指数级增长。实际上,在检索阶段,我们仅需要通过关系或关系路径召回一批相关的实体,而不需要细粒度关注实体本身的信息。结合以上思考,我们针对检索阶段提出了Abstract Subgraph(抽象子图) 的概念,核心是将同一个头实体和关系派生出的尾实体聚合在一起,得到对应的抽象结点,如图1 (b)即为图1 (a)的抽象子图表示,这样可以显著降低原始知识图谱的规模。因此,检索阶段通过关系或关系路径判断抽象节点的相关性,检索完成后,将含有抽象节点的子图进行还原,得到包含原始节点的子图;推理阶段通过关系或关系路径同时考虑具体的节点信息推理最终的答案节点。这样,我们就可以减缓两个阶段面临的搜索空间尺度过大的问题。
基于抽象子图,我们针对两阶段提出一个评估实体相关性的通用形式,即给定问题 和候选实体的子图 。对于检索阶段, 是抽象子图,包含抽象节点以合并同一关系派生的尾实体。对于推理阶段, 是基于检索阶段的检索子图构建的,还原后没有抽象节点。这种通用的输入格式为开发统一的模型架构提供了基础。接下来,我们将以一般方式描述针对这种统一数据形式设计的模型架构,而不考虑特定的检索或推理阶段。
2、模型架构
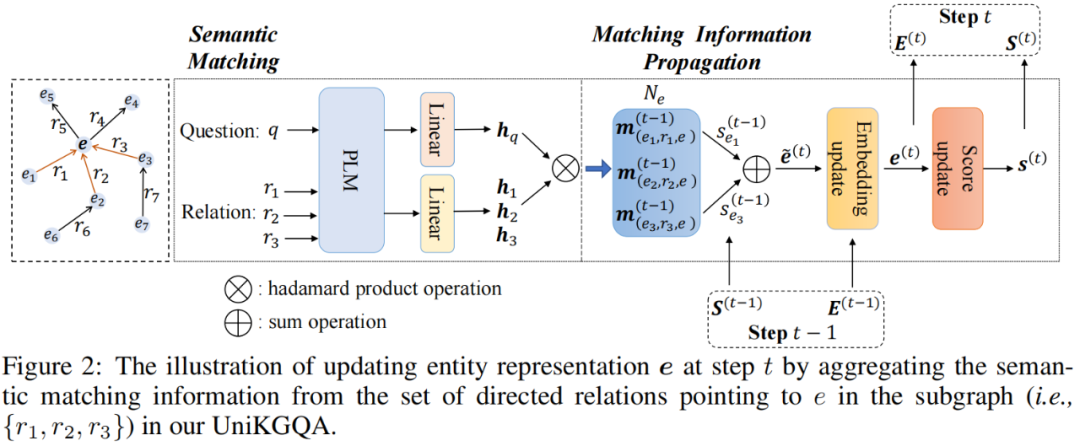
基于上述统一数据形式,我们开发的模型架构包含两个基础模块:(1) 语义匹配 (SM) 模块,利用 PLM 执行问题和关系之间的语义匹配;(2) 匹配信息传播 (MIP) 模块,在知识图谱上传播语义匹配信息。我们在图2中展示了模型架构的概览。
语义匹配 (SM):SM 模块旨在生成问题 与给定子图 中的三元组间的语义匹配特征。具体而言,我们首先利用 PLM 对和的文本进行编码,然后使用 [CLS] 令牌的输出表示作为它们的表示:
基于 和 ,受 NSM 模型的启发,我们通过对应的投影层,在第 步获得问题 和三元组间语义匹配特征的向量间语义匹配特征的向量:
其中,, 是第 步投影层的参数, 和 分别是 PLM 和特征向量的隐藏层维度, 是 sigmoid 激活函数,而 是 hadamard 积。
匹配信息传播 (MIP):基于语义匹配特征,MIP 模块首先将它们聚合起来以更新实体表示,然后利用它来获取实体匹配得分。为了初始化匹配得分,对于给定问题 和子图 中的每个实体 ,我们将 和 之间的匹配分数设置为:如果 是主题实体,则 ,否则 。在第 步,我们利用上一步计算出的头实体的匹配分数作为权重,聚合相邻三元组的匹配特征,以获得尾实体的表示:
其中, 是第 步中实体 的表示, 是可学习的矩阵。在第一步中,由于没有匹配分数,我们按照NSM模型的方法,直接将其一跳关系的表示聚合为实体表示:,其中 是可学习的矩阵。基于所有实体 的表示,我们使用 softmax 函数更新它们的实体匹配分数:
其中, 是一个可学习的向量。
经过 步迭代,我们可以获得最终的实体匹配得分 ,它是子图 中所有实体的概率分布。这些匹配分数可以用来衡量实体作为给定问题 答案的可能性,并将在检索和推理阶段中使用。
训练策略
我们在多跳知识图谱问答的推理和检索阶段都使用了前述的模型架构,分别为推理模型和检索模型。由于这两个模型采用相同的架构,我们引入 和 来分别表示用于检索和推理的模型参数。如前所述,我们的架构包含两组参数,即基础 PLM 以及用于匹配和传播的其他参数。因此, 和 可以分解为 和 ,其中下标 和 分别表示我们架构中的 PLM 参数和其他参数。为了学习这些参数,我们基于统一架构设计了预训练 (即问题-关系匹配)和微调 (即面向检索和推理的学习)策略。下面,我们描述模型训练方法。
问题-关系匹配的预训练 (QRM): 对于预训练,我们主要关注学习基础 PLMs (即 和 ) 的参数。在实现中,我们让两个模型共享相同的 PLM 参数,即 。语义匹配模块的基本功能是对一个问题和一个单独的关系进行相关性建模 (式2)。因此,我们设计了一个基于问题-关系匹配的对比预训练任务。具体来说,我们采用对比学习目标来对齐相关问题-关系对的表示,同时将其他不相关的对分开。为了收集相关问题-关系对,对于一个由问题 、主题实体 和答案实体 组成的例子,我们从整个知识图谱中提取 和 之间的所有最短路径,并将这些路径中的所有关系视为与 相关的关系,表示为 。这样,我们就可以获得许多弱监督样例。在预训练期间,对于每个问题 ,我们随机采样一个相关的关系 ,并利用对比学习损失进行预训练:
其中,是一个温度超参数,是一个随机采样的负关系,是余弦相似度,、是由SM模块(式1)中的 PLM 编码的问题和关系。这样,通过预训练 PLM 参数,问题-关系匹配能力将得到增强。请注意,在预训练之后,PLM 参数将被固定。
在抽象子图上微调检索 (RAS):在预训练之后,我们在检索任务上学习参数 。回忆一下,我们将子图转化为一种抽象子图的形式,其中包含抽象节点,用于合并来自同一关系派生的尾实体。由于我们的 MIP 模块可以生成子图中节点的匹配分数 (式4),其中下标 表示节点来自抽象子图。此外,我们利用标注的答案来获取标签向量,表示为 。如果抽象节点中包含答案实体,则在 中将抽象节点设置为1。接下来,我们最小化学习匹配得分向量和标签向量之间的KL散度,如下式所示:
通过RAS损失微调后,可以有效地学习检索模型。我们通过它们的匹配得分选择排名前 个节点,利用它们来检索给定问题 的子图。请注意,仅选择与主题实体距离合理的节点进入子图,这可以确保推理阶段使用的子图 相对较小但与问题相关。
在检索子图上微调推理 (RRS):在微调检索模型后,我们继续微调推理模型,学习参数 。通过微调后的检索模型,我们可以获得每个问题 的较小子图 。在推理阶段,我们专注于执行准确的推理,以找到答案实体。因此,我们还原抽象节点中的原始节点及其原始关系。由于检索和推理阶段高度依赖,我们首先使用检索模型的参数来初始化推理模型的参数: 。然后,根据式4,我们采用类似的方法使用KL损失函数来使学习到的匹配得分 (表示为 ) 拟合标签向量 (表示为 ):
其中,下标 表示节点来自检索子图。通过RRS损失的微调后,我们可以利用学习的推理模型选择排名前个实体。
如图1 (c)所示,整体的训练过程由以下三个步骤组成:(1) 与 共享参数,(2) 使用问题-关系匹配预训练 ,(2) 使用抽象子图微调 以进行检索,(3) 使用子图微调 以进行推理,其中 使用 进行初始化。
讨论
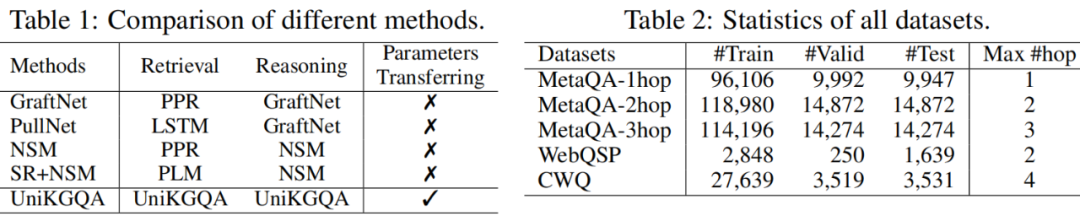
据我们所知,我们是KGQA领域首次提出使用统一模型在检索和推理阶段共享推理能力。在表格1中,我们总结了我们的方法和几种流行的多跳知识库问答方法(包括 GraphfNet、PullNet、NSM 和 SR+NSM 之间的区别。我们可以看到,现有方法通常针对检索和推理阶段采用不同的模型,而我们的方法更为统一。统一带来的一个主要优点是,两个阶段之间的信息可以有效地共享和复用,即,我们使用学习的检索模型来初始化推理模型。
三、实验结果
1、主实验
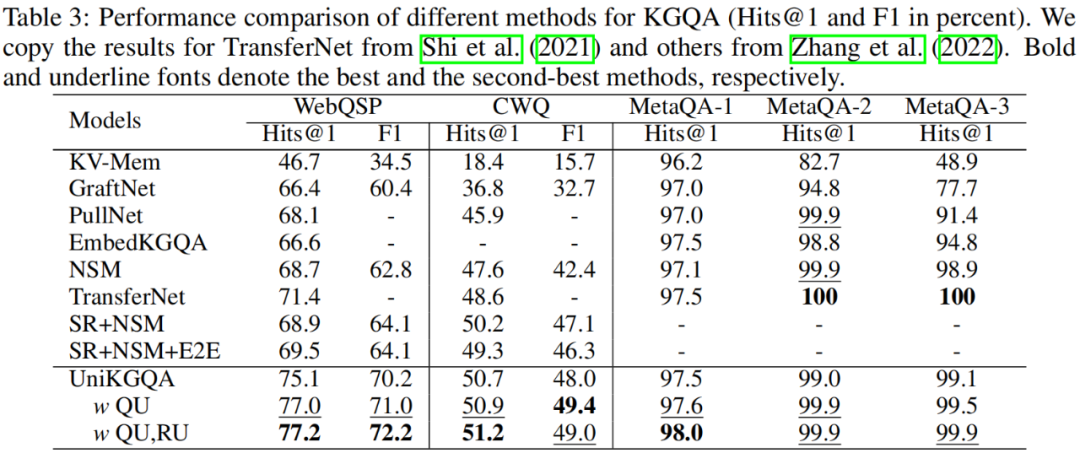
我们在3个公开的文档检索数据集上进行实验,分别是 WebQuestionsSP (WebQSP)、Complex WebQuestions 1.1 (CWQ)、和 MetaQA 数据集。实验结果如下表所示,通过对比可以清晰地看出我们的方法的优势。例如,在难度较大的数据集 WebQSP 和 CWQ 上,我们的方法远远优于现有的最先进基线(例如,WebQSP 的 Hits@1 提高了8.1%,CWQ 的 Hits@1 提高了2.0%)。
在我们的方法中,为了提高效率,我们固定了基于 PLM 的编码器的参数。实际上,更新其参数可以进一步提高模型性能。这样的方法使研究人员在实际应用中可以权衡效率和精度。因此,我们提出了两种 UniKGQA 的变体来研究它:(1) 仅在编码问题时更新 PLM 编码器的参数,(2) 同时在编码问题和关系时更新 PLM 编码器的参数。事实上,这两种变体都可以提高我们的 UniKGQA 的性能。只在编码问题时更新 PLM 编码器可以获得与同时更新两者相当甚至更好的性能。可能的原因是在编码问题和关系时更新 PLM 编码器可能会导致过度拟合下游任务。因此,仅在编码问题时更新PLM 编码器是更有价值的,因为它可以在相对较少的额外计算成本下实现更好的性能。
2、深入分析
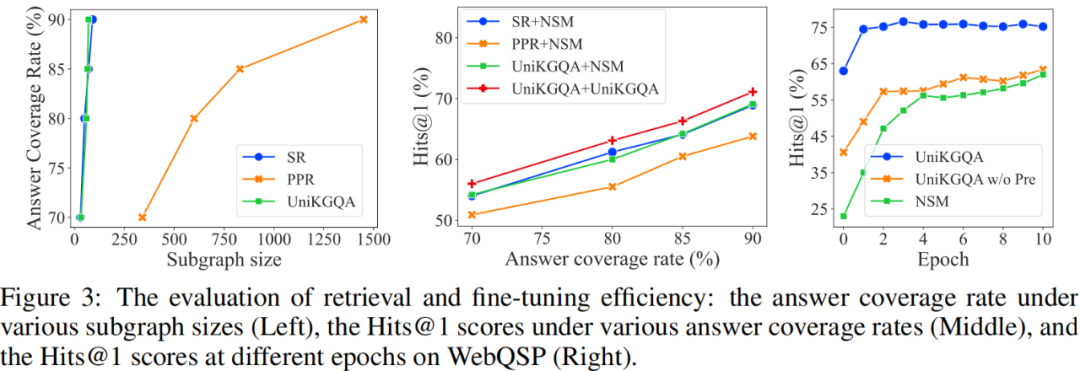
检索性能:我们从三个方面评估检索性能:子图大小、答案覆盖率和最终 QA 性能。可以看到,在检索出相同大小的子图的情况下,UniKGQA 和 SR 的答案覆盖率显著高于 PPR 的。这证明了训练可学习的检索模型的有效性和必要性。此外,尽管 UniKGQA 和 SR 的曲线非常相似,但我们的 UniKGQA 比 SR+NSM 可以实现更好的最终 QA 性能。原因是 UniKGQA 可以基于统一体系结构将相关信息从检索阶段传递到推理阶段,学习更有效的推理模型。这一发现可以通过将我们的 UniKGQA 与 UniKGQA+NSM 进行比较来进一步验证。
微调效率:我们比较了 UniKGQA 和较强基线模型 NSM 在相同检索的子图上进行微调时,性能随迭代轮数的变化。如图3右侧展示。首先,我们可以看到,在微调之前(即迭代轮数为零时),我们的 UniKGQA 已经达到了与 NSM 最佳结果相当的性能。这表明推理模型已经成功利用了检索模型习得的知识,可以进行一定的推理。迭代两轮之后,我们的 UniKGQA 已经达到接近收敛的性能。表明我们的模型可以实现高效的微调。
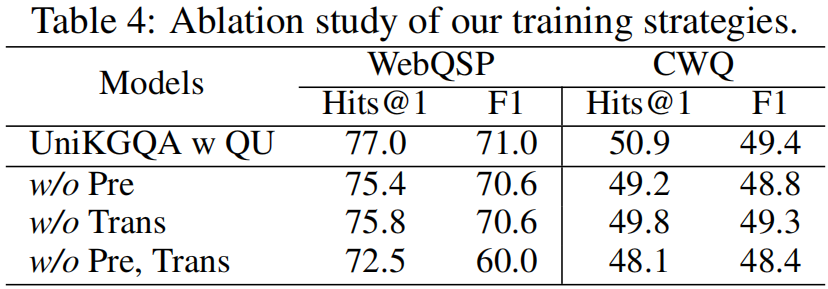
消融实验:我们提出两个重要的训练策略以提高性能:(1) 使用问题-关系匹配进行预训练,(2) 使用检索模型的参数初始化推理模型。我们通过消融实验验证它们的有效性。我们提出了三种变体:(1) 去除预训练过程, (2) 去除使用检索模型参数初始化,(3) 同时去除预训练和初始化过程。我们在表格4中展示了消融研究的结果。可以看到,所有这些变体的性能都低于完整的 UniKGQA,这表明这两个训练策略对最终性能都很重要。此外,这种观察还验证了我们的 UniKGQA 确实能够转移和重用习得的知识以提高最终性能。
四、总结
在这项工作中,我们提出了一种多跳知识图谱问答任务新的模型架构。作为主要威廉希尔官方网站 贡献,UniKGQA 引入了基于 PLMs 的统一模型架构,可同时适用于检索阶段与推理阶段。为了应对两个阶段的不同搜索空间规模,我们提出了检索阶段专用的抽象子图的概念,它可以显著减少需要搜索的节点数量。此外,我们针对统一模型架构,设计了一套高效的训练策略,包含预训练(即问题-关系匹配)和微调(即面向检索和推理的学习)。得益于统一的模型架构,UniKGQA 可以有效增强两个阶段之间习得能力的共享和转移。我们在三个基准数据集上进行了广泛的实验,实验结果表明,我们提出的统一模型优于竞争方法,尤其是在更具挑战性的数据集(WebQSP 和 CWQ)上表现更好。
审核编辑 :李倩
-
PLM
+关注
关注
2文章
121浏览量
20865 -
语言模型
+关注
关注
0文章
523浏览量
10273 -
数据集
+关注
关注
4文章
1208浏览量
24694 -
知识图谱
+关注
关注
2文章
132浏览量
7704
原文标题:四、总结
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一文详解知识增强的语言预训练模型
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》
【大语言模型:原理与工程实践】大语言模型的预训练

Multilingual多语言预训练语言模型的套路
一种基于乱序语言模型的预训练模型-PERT
利用视觉语言模型对检测器进行预训练
一套开源的大型语言模型(LLM)—— StableLM






 工商网监
工商网监
评论