 浅析时序数据库的流计算支持
浅析时序数据库的流计算支持
01
时序数据及其特点
时序数据(Time Series Data)是基于相对稳定频率持续产生的一系列指标监测数据,比如一年内的道琼斯指数、一天内不同时间点的测量气温等。时序数据有以下几个特点:
●历史数据的不变性
● 数据的有效性
● 数据的时效性
● 结构化的数据
● 数据的大量性
02
时序数据库基本架构
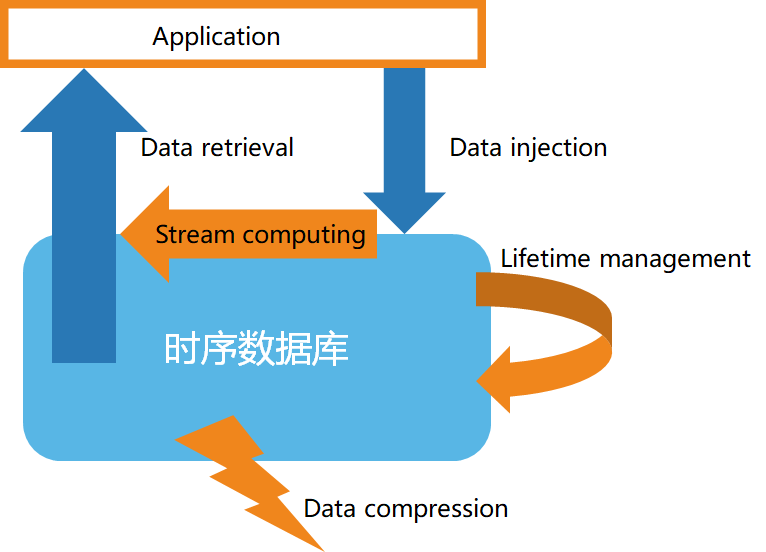
针对时序数据的特点,时序数据库一般具有以下特性:
● 高速的数据入库
● 数据的生命周期管理
● 数据的流处理
● 高效的数据查询
● 定制的数据压缩
03
流计算介绍
流计算主要是指针对实时获取来自不同数据源的海量数据,经过实时分析处理,从而获得有价值的信息。常见的业务场景包括实时事件的快速反应,市场变化的实时告警,实时数据的交互分析等。流计算一般包括如下几方面的功能:
1)过滤和转换 (filter & map)
2)聚合以及窗口函数 (reduce,aggregation/window)
3)多数据流合并以及模式匹配 (joining & pattern detection)
4)从流到块处理
04
时序数据库对流计算的支持
案例一:使用定制化的流计算 API,如下面例子所示:
from(bucket: "mydb")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "mymeasurement")
|> map(fn: (r) => ({ r with value: r.value * 2 }))
|> filter(fn: (r) => r.value > 100)
|> aggregateWindow(every: 1m, fn: sum, createEmpty: false)
|> group(columns: ["location"])
|>join(tables:{stream1:{bucket:"mydb",measurement:"stream1",start:-1h},stream2:{bucket:"mydb",measurement:"stream2",start:-1h}},on:["location"])
|>alert(name:"value_above_threshold",message:"Valueisabovethreshold",crit:(r)=>r.value>100)
|>to(bucket:"mydb",measurement:"output",tagColumns:["location"])
案例二:使用类 SQL 指令,创建流计算以及定义流计算规则,如下:
CREATE STREAM current_stream TRIGGER AT_ONCE INTO current_stream_output_stb AS SELECT _wstartasstart, _wendasend, max(current)asmax_current FROMmeters WHERE voltage <= 220 INTEVAL (5S) SLIDING (1s);
审核编辑:刘清
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
SQL
+关注
关注
1文章
764浏览量
44127 -
数据库
+关注
关注
7文章
3799浏览量
64379 -
API接口
+关注
关注
1文章
84浏览量
10438
原文标题:时序数据库的流计算支持
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
时间序列数据的存储和计算 - 开源时序数据库解析
摘要: Prometheus 开源时序数据库解析的系列文章在之前已经完成了几篇,对比分析了Hbase系的OpenTSDB、Cassandra系的KairosDB、BlueFlood及Heroic
发表于 01-25 14:53
关于时序数据库的内容
简介: 这是一篇无法一口气读完的、文字过万[正文字数14390]的长文,这是一个无法中途不上厕所就看完的、关于时序数据库的视频[时长111分钟]分享的文字整理..大家好,很开心能够和大家一起交流时序数据库
发表于 07-12 08:00
TableStore时序数据存储 - 架构篇
Schema设计以及索引设计方案。最后还会有计算篇,会提供几个时序数据流计算和时序分析的方案设计。 什么是时序数据
发表于 08-08 16:17
•588次阅读
工业互联网时代,我们为什么需要一个时序数据库?
、管理、查询、处理上述二元函数数据的数据库,则可以称之为时序数据库。时序数据库主要以解决下面几个问题:时序数据的写入:如何
工业互联网时代,我们为什么需要时序数据库之二:适合的就是最好的
。至此,我们得出的结论就一个:选择到底用什么数据库来支持时序数据,还是需要对时序数据的需求进行透彻的分析,然后根据时序数据的特点,来选择适合
时序数据库的前世今生
时序数据库忽然火了起来。Facebook开源了beringei时序数据库,基于PostgreSQL打造的时序数据库TimeScaleDB也开源了。时序数据库作为物联网方向一个非常重
工业互联网时代:我们为什么需要时序数据库之二
作为资深“杠精”,当然需要先知道要“杠”的到底是什么?就时序数据库而言,就是要“杠”两个东西:1、“杠”数据;2、“杠”数据库。
华为时序数据库为智慧健康养老行业贡献应用之道
随着 IoT 威廉希尔官方网站
的快速发展,物联网设备产生的数据呈爆炸式增长。这些数据通常随时间产生,称之为时序数据。这样的一种专门用于管理时序数据的数据库
华为PB级时序数据库Gauss DB,助力海量数据处理
,时序数据作为大数据、机器学习、实时预测的基础数据,作用更加显著。因此,对时序数据的研究与应用应当更为深入。 近 5 年来,时序数据库发
华为自研分布式时序数据库集群:初始GaussDB(for Influx)
要处理的指标数据达到TB级,一年的数据同样达到PB级,并且数据需要永久存储。传统的关系型数据库很难支撑这么大的数据量和写入压力,Hadoop

CeresDB 1.0正式发布,Rust高性能云原生时序数据库
在经典的时序数据库中,Tag 列(InfluxDB 称之为 Tag,Prometheus 称之为 Label)通常会对其生成倒排索引,但在实际使用中,Tag 的基数在不同的场景中是不一样的 ———— 在某些场景下
涂鸦推出NekoDB时序数据库,助力全球客户实现低成本部署
随着IoT威廉希尔官方网站
逐渐成熟,众多设备产出的数据呈现指数级增长。企业亟需用行之有效的方式管理海量时序数据。由此,各类时序数据库开始成为市场宠儿。与市场需求相悖的是,时序数据库水平参差不齐。纵
时序数据库是什么?时序数据库的特点
时序数据库是一种在处理时间序列数据方面具有高效和专门化能力的数据库。它主要用于存储和处理时间序列数据,比如传感器数据、监控





 工商网监
工商网监
评论