 GTC 2023主题直播:NVIDIA Nemo构建定制的语言文本转文本
GTC 2023主题直播:NVIDIA Nemo构建定制的语言文本转文本
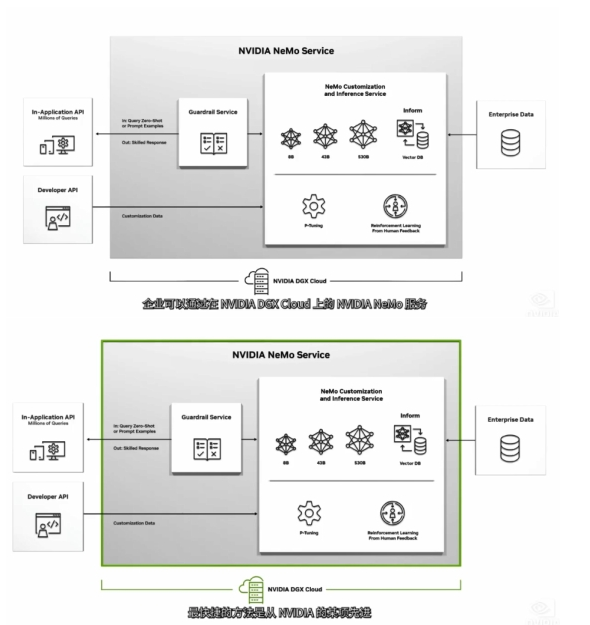
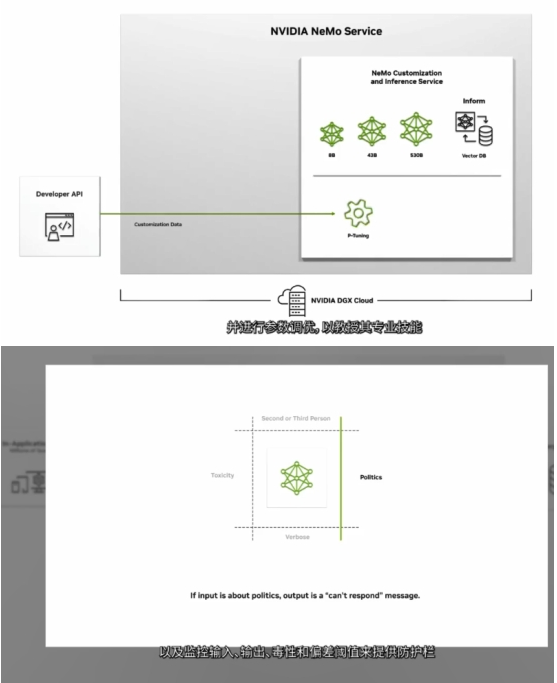
一些专业领域的公司需要使用其专有数据来构建定制模型,NVIDIA 推出NVIDIA Nemo。这是一项云服务,面向需要构建、优化和运营用于 处理特定领域的任务。
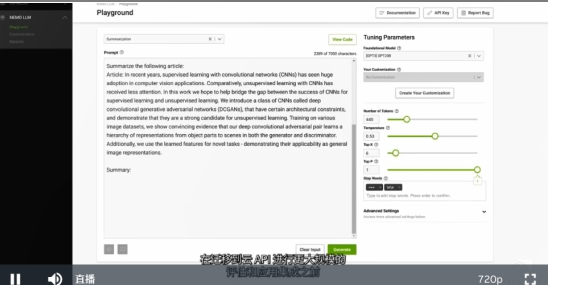
NVIDIA Nemo用于构建定制的语言文本转文本,客户可以引入自己的模型,或从Nemo涵盖了GPT-8、GPT-43到GPT-530等数十亿参数的从创建专有模型到运营,NVIDIA AI专家将全程与您合作。

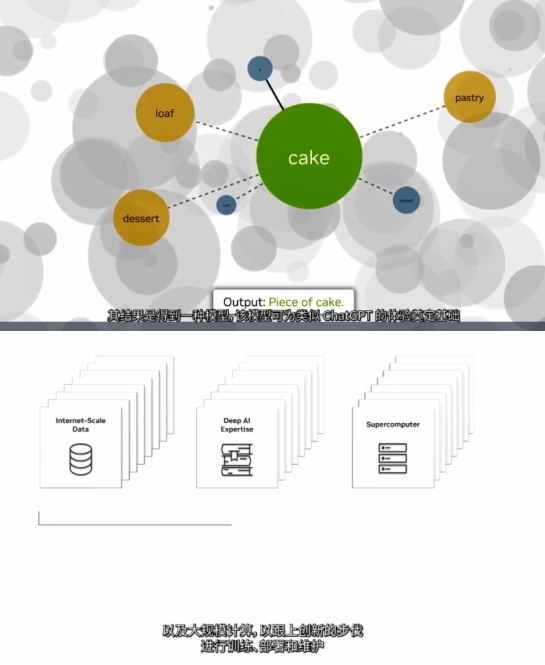
这些关系通过模型嵌入空间中的权进行捕获
GTC 2023主题直播地址:https://t.elecfans.com/live/2302.html
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
NVIDIA
+关注
关注
14文章
4984浏览量
103019 -
AI
+关注
关注
87文章
30817浏览量
268968 -
GPT
+关注
关注
0文章
354浏览量
15359 -
gtc
+关注
关注
0文章
73浏览量
4425
发布评论请先 登录
相关推荐
如何使用自然语言处理分析文本数据
使用自然语言处理(NLP)分析文本数据是一个复杂但系统的过程,涉及多个步骤和威廉希尔官方网站
。以下是一个基本的流程,帮助你理解如何使用NLP来分析文本数据: 1. 数据收集 收集文本数据 :从各种
NVIDIA助力企业创建定制AI应用
NVIDIA 近日宣布与众多威廉希尔官方网站
领导者一同使用最新NVIDIA NIM Agent Blueprint以及NVIDIA NeMo和NVIDIA
图纸模板中的文本变量
“ 文本变量和系统自带的内置变量,可以帮助工程师灵活、高效地配置标题栏中的信息,而不用担心模板中的文字对象被意外修改。 ” 文本变量的语法 文本变量以 ${VARIABLENAME} 的方式
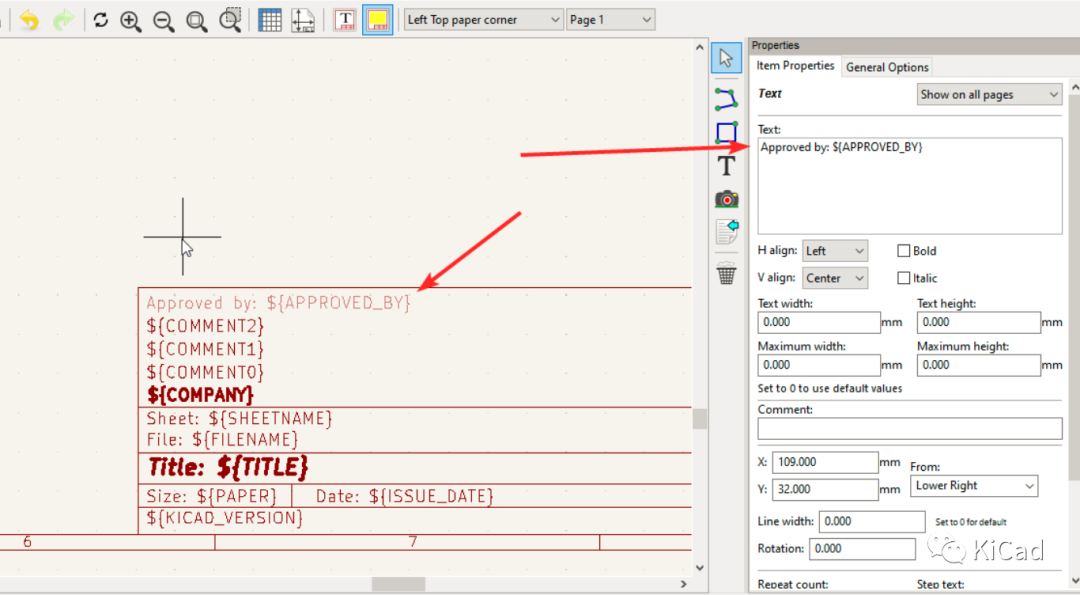
如何在文本字段中使用上标、下标及变量
在KiCad的任何文本字段中,都可以通过以下的方式实现上标、下标、上划线以及显示变量及字段值的描述: 文本变量“文本变量”可以在 原理图设置->工程->文本变量 中设置。下图中设置了一

【AWTK使用经验】如何在AWTK显示阿拉伯文本
。本篇文章将简单介绍阿拉伯文本相关整形与排序规则,接着介绍在AWStudio设置阿拉伯语言翻译的步骤。阿拉伯文本整形规则一般GUI显示英文或者中文时,内存中存储的字符

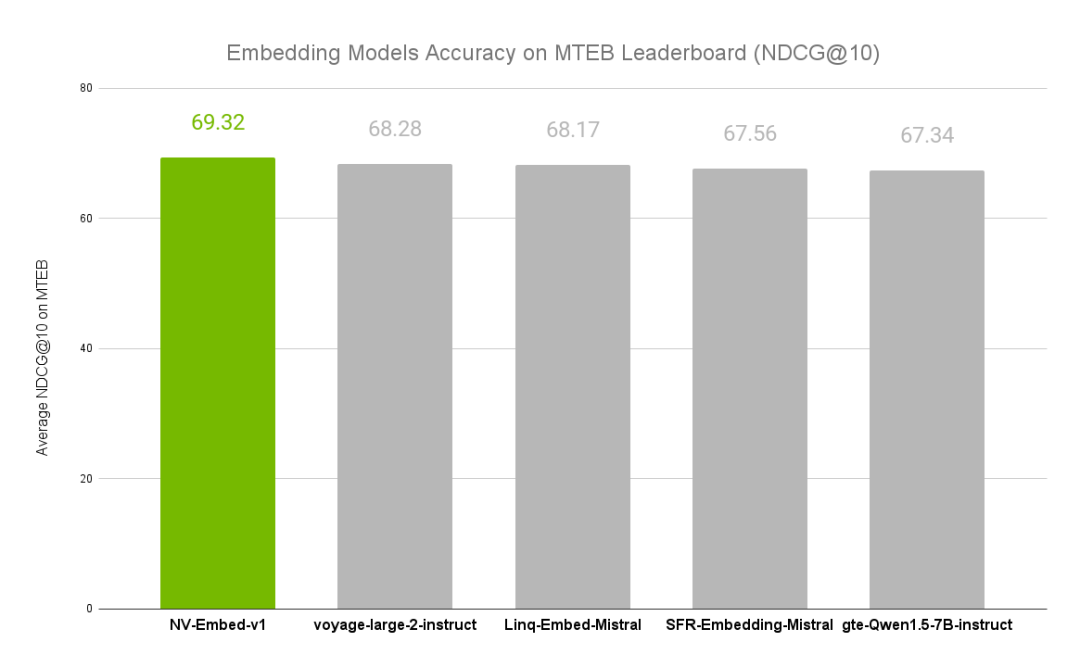
NVIDIA文本嵌入模型NV-Embed的精度基准
NVIDIA 的最新嵌入模型 NV-Embed —— 以 69.32 的分数创下了嵌入准确率的新纪录海量文本嵌入基准测试(MTEB)涵盖 56 项嵌入任务。
Mistral AI与NVIDIA推出全新语言模型Mistral NeMo 12B
Mistral AI 和 NVIDIA 于近日共同发布了一款全新的领先语言模型Mistral NeMo 12B。开发者可以轻松定制和部署该模型,令其适用于支持聊天机器人、多
nlp自然语言处理模型怎么做
的进展。本文将详细介绍NLP模型的构建过程,包括数据预处理、模型选择、训练与优化等方面。 数据预处理 数据预处理是NLP模型构建的第一步,其目的是将原始文本数据转换为模型能够处理的格式。数据预处理主要包括以下几个步骤: 1.1
卷积神经网络在文本分类领域的应用
在自然语言处理(NLP)领域,文本分类一直是一个重要的研究方向。随着深度学习威廉希尔官方网站
的飞速发展,卷积神经网络(Convolutional Neural Network,简称CNN)在图像识别领域取得了

【大语言模型:原理与工程实践】大语言模型的基础威廉希尔官方网站
全面剖析大语言模型的核心威廉希尔官方网站
与基础知识。首先,概述自然语言的基本表示,这是理解大语言模型威廉希尔官方网站
的前提。接着,详细介绍自然语言处理预训练的经典结构Transformer,以及其工作原理,
发表于 05-05 12:17
使用NVIDIA Holoscan for Media构建下一代直播媒体应用
NVIDIA Holoscan for Media 现已向所有希望在完全可重复使用的集群上构建下一代直播媒体应用的开发者开放。
NVIDIA宣布推出基于Omniverse Cloud API构建的全新软件框架
NVIDIA 在 GTC 大会上宣布推出基于 Omniverse Cloud API(应用编程接口)构建的全新软件框架。
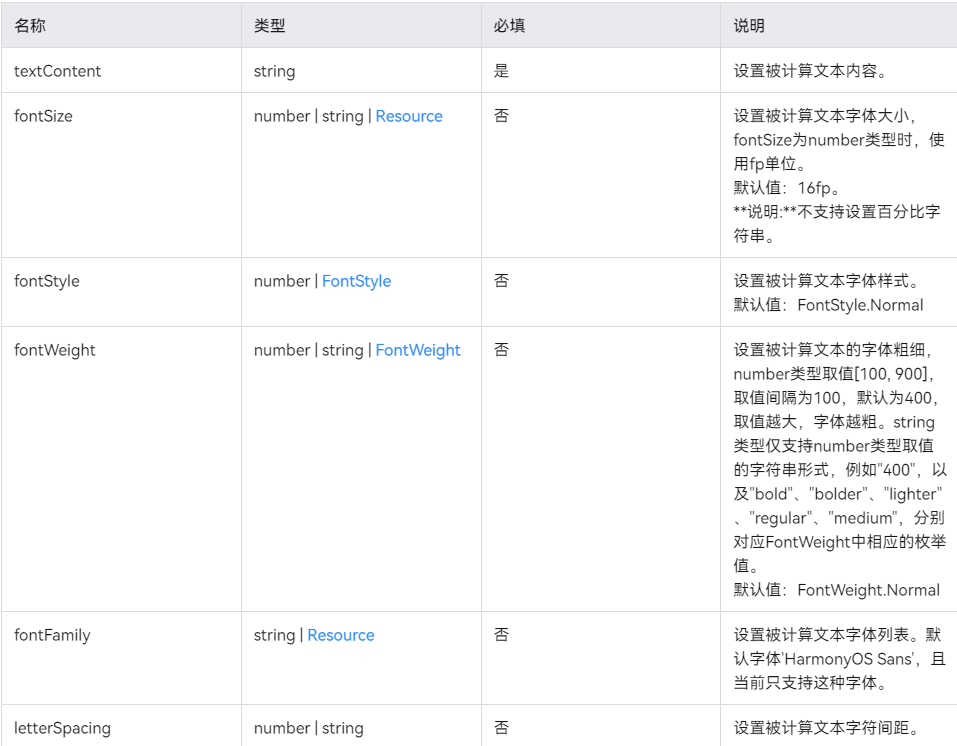
鸿蒙UI界面——@ohos.measure (文本计算)
: MeasureOptions): number 计算指定文本单行布局下的宽度。 系统能力: SystemCapability.ArkUI.ArkUI.Full 参数: 参数名 类型 必填 说明 options
2023年科技圈热词“大语言模型”,与自然语言处理有何关系
电子发烧友网报道(文/李弯弯)大语言模型(LLM)是基于海量文本数据训练的深度学习模型。它不仅能够生成自然语言文本,还能够深入理解文本含义,





 工商网监
工商网监
评论