 C语言灵魂拷问: ++i为何比i++执行效率高!
C语言灵魂拷问: ++i为何比i++执行效率高!
背景
相信很多人遇到过这样的问题:printf("%d,%d",i++,++i);
也纠结过这个问题,到底答案是什么。却没有一个参考的资料。唯一知道的是,几乎所有C语言教材都这么讲:i++就是先使用i的值再使i自身加一,而++i则是先使i自身加一,然后再使用i的值。出于对真理的追求。今天我们彻底弄明白此问题。譬如这样的话:
int a,b;
int i=10,j=10;
a=i++;
b=++j;
我们可以很清楚的知道a和b的值分别将是10和11。这点毫无疑问,因为无论在任何平台任何编译器上运行都是这个结果!然而对于这样的程序:
int a,b;
int i=10,j=10;
a=(i++)+(i++)+(i++);
b=(++j)+(++j)+(++j);
各位试想答案将是多少?我们可以放到编译器上运行看一下结果如下:
先看看windows下常用的VC6结果:
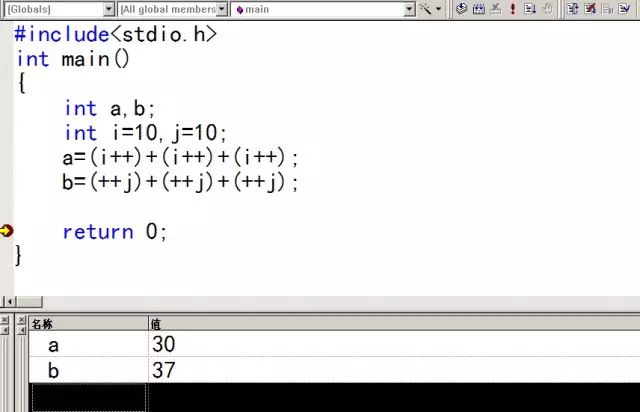
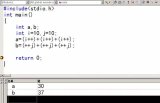
恩看到了,是30和37!嗯,但..这个结果好像有点怪。
那再看看Linux下gcc的结果:
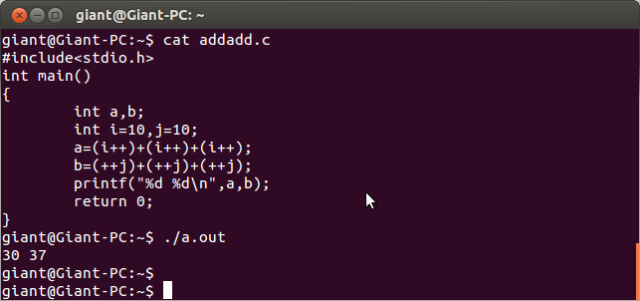
哦,竟然也是30 37 。
那我们再看看古老一点的TurboC的结果:
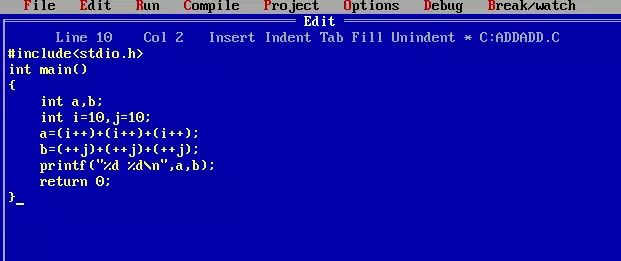

结果成了30 39 , 喔~还真有点怪。
当然,就C语言代码来看,i++ 和 ++i 都只有一行,看起来似乎二者的执行效率一样?其实不是的,在学习C语言时,教材和老师一般都会强调 i++ 和 ++i 的区别,例如下面这段C语言代码:
inti,j,k;
i = 0;
j = i++;
i = 0;
k = ++i;
这段C语言代码执行后,j 和 k 的值并不相等:j 等于 0,k 等于 1。既然执行结果有差异,那么执行效率很有可能也是有差异的,事实的确如此。查看上述C语言代码对应的汇编代码,如下:
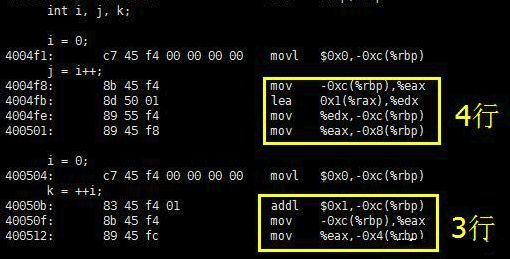
编译器版本为gcc 4.8.4
可见,j=i++; 计算机需要 4 条指令来解释,比执行 k=++i; 多出了一条指令。多出的一条指令为:在对 i 执行自加操作之前,先保存 i 的当前值留作稍后使用(赋值为j)。
这是怎么回事呢?不同的编译器结果还不一样呢?
而且这样看来,似乎 ++i 的执行效率比 i++ 高一些?
为何不同的编译器结果不一样
要说起这其中的原因,我们要先明白两个知识点。即“副作用”与“顺序点”。这里我们引用《C Primer Plus》的说法:
“现在我们再讨论一些C的术语。副作用(side effect)是对数据对象或文件的修改。
例如,语句:states = 50;
一个顺序点(sequence point)是程序执行中的一点;在该点处,所有的副作用都在进入下一步之前被计算。在C中,语句里的分号标志了一个顺序点。它意味着在一个语句中赋值运算符、增量预算符及减量运算符所做的全部改变必须在程序进入下一个语句前发生。任何一个完整的表达式的结束也是一个顺序点。
什么是完整的表达式呢?一个完整的表达式(full expression)是这样一个表达式—-它不是一个更大的表达式的子表达式。完整的表达式的例子包括一个表达式语句里的表达式和在一个while循环里作为判断条件的表达式。
顺序点帮助阐明后缀增量动动作何时发生。例如,考虑下面的代码:
while(guests++<10)
printf(“%d
”,guests);
有时C的初学者会设想在本程序中“先使用该值,然后增加它的值”的意思是在使用printf()语句后再增加guests的值。然而,因为guests++<10是while循环的判断条件,所以它是一个完整的表达式,这个表达式的结束就是一个顺序点。因此,C保证副作用(增加guests的值)在程序进入printf()前发生。同时使用后缀形式保证了guests在与10比较后才增加。现在考虑这个语句:
Y=(4+ x++)+(6+ x++);
表达式4+x++不是一个完整的表达式,所以C不能保证在计算子表达式4+x++后立即增加x。这里,完整表达式是整个赋值语句,并且分号标记了顺序点,所以C能保证的是在程序进入后续语句前x将增加两次。C 没有指明x是在每个子表达式被计算后增加还是在整个表达式被计算后增加,这就是我们要避免使用这类语句的原因。这是《C Primer Plus》的说法,相信您应该有一定答案了。没错,那就是对于i=10;(++i)+(++i)+(++i);这样的语句。C语言标准并没有作规定。有的编译器计算出来是39,因为会使i的值自增三次变为13,然后使用增加三次之后也就是13的3个值相加为39。而有的编译器计算结果则为37,如VisaulC++6.0则会先计算前两个i的值为12,第三个i的值变成了加三次以后的值为13,因此结果是12+12+13=37。如果有心的话,您可以分别在VC6和TC上分别测试;(++i)+(++i)+(++i) +(++i)的值来洞悉不同编译器的处理规则。
那么,回到最初的printf的问题,明白求值的顺序之后,再来看printf的求值问题,printf的参数都是从左到右依次压入栈内,所以计算起来求值运算的时候则是由右至左(栈的特点:即先进后出),那么至此,想必您已经完全想明白了这类问题的全部了!
所以讲到这里,想必大家就清楚缘由了,不同编译器的处理过程是不同的。所以并没有唯一的标准答案!现在大家明白了吗?
为何++i比i++执行效率高一些呢?
那为了写出效率更高的C语言程序,以后是不是应该尽量使用 ++i,而不是 i++ 了呢?例如下面这样的C语言代码:
for(i=0; i<10; i++);
for(i=0; i<10; ++i);
是不是上面那行C语言代码的执行效率低于下面的呢?只能说理论如此,实际上,现代C语言编译器已经足够聪明,它会根据上下文编译C语言代码。
应该明白,i++ 和 ++i 的效率差异主要来自于处理 i++ 时,需要先保存 i 的当前值留作稍后使用。如果之后没有人使用 i 的当前值,也就是说没有C语言代码读取 i++ 的值,编译器实在没有必要保存 i 的当前值了,因此就会将这一步优化掉。
为了便于分析,我们编写下面这样的C语言代码:
int i = 0;
i++;
++i;
与上面的例子相比,区别在于在执行 i++ 时,没有人关心 i 的当前值了。查看这段C语言代码对应的汇编代码:

显然,i++ 和 ++i 对应的指令是一模一样的,不再有执行效率上的差异。
C语言中的 i++ 和 ++i 是有区别的,这就有可能带来效率上的差异。如果有代码关心 i++ 执行时的 i 当前值,程序在对 i 进行自加操作时,将不得不先保存 i 的当前值,而 ++i 就无需保存当前值,这就会带来效率上的差异。如果没人关心 i++ 的当前值,那么现代大多数C语言编译器将会将这一差异优化掉,此时 i++ 和 ++i 不再有效率上的差异。
审核编辑 :李倩
-
C语言
+关注
关注
180文章
7604浏览量
136858 -
编译器
+关注
关注
1文章
1634浏览量
49134
原文标题:C语言灵魂拷问: ++i为何比i++执行效率高!
文章出处:【微信号:混说Linux,微信公众号:混说Linux】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
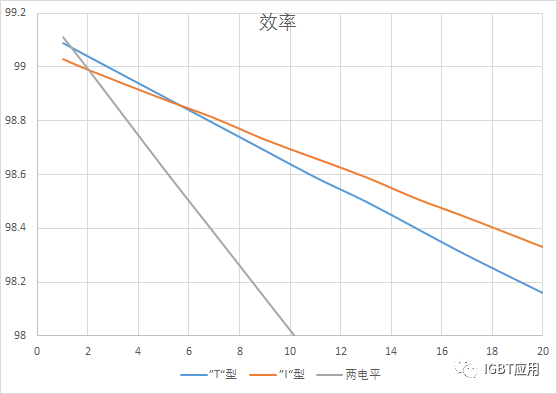
“T”型NPC的效率怎么会比“I”型NPC的效率高呢?





 工商网监
工商网监
评论