 NLP类别不均衡问题之loss合集
NLP类别不均衡问题之loss合集
NLP 任务中,数据类别不均衡问题应该是一个极常见又头疼的的问题了。最近在工作中也是碰到这个问题,花了些时间梳理并实践了下类别不均衡问题的解决方式,主要实践了下“魔改”loss(focal loss, GHM loss, dice loss 等),整理了下。所有的 Loss 实践代码在这里:
https://github.com/shuxinyin/NLP-Loss-Pytorch
数据不均衡问题也可以说是一个长尾问题,但长尾那部分数据往往是重要且不能被忽略的,它不仅仅是分类标签下样本数量的不平衡,实质上也是 难易样本的不平衡 。
解决不均衡问题一般从两方面入手:
- 数据层面:重采样,使得参与迭代计算的数据是均衡的;
- 模型层面:重加权,修改模型的 loss,在 loss 计算上,加大对少样本的 loss 奖励。
数据层面的重采样
关于数据层面的重采样,方式都是通过采样,重新构造数据分布,使得数据平衡。一般常用的有三种:1)欠采样;2)过采样;3)SMOTE。
- 欠采样:指某类别下数据较多,则只采取部分数据,直接抛弃一些数据,这种方式太简单粗暴,拟合出来的模型的偏差大,泛化性能较差;
- 过采样:这种方式与欠采样相反,某类别下数据较少,进行重复采样,达到数据平衡。因为这些少的数据反复迭代计算,会使得模型产生过拟合的现象。
- SMOTE:一种近邻插值,可以降低过拟合风险,但它是适用于回归预测场景下,而 NLP 任务一般是离散的情况。
这几种方法单独使用会或多或少造成数据的浪费或重,一般会与 ensemble 方式结合使用,sample 多份数据,训练出多个模型,最后综合。
但以上几种方式在工程实践中往往是少用的,一是因为数真实据珍贵,二也是 ensemble 的方式部署中资源消耗大,没法接受。因此,就集中看下重加权 loss 改进的部分。
模型层面的重加权
重加权主要指的是在 loss 计算阶段,通过设计 loss,调整类别的权值对 loss 的贡献。比较经典的 loss 改进应该是 Focal Loss, GHM Loss, Dice Loss。
2.1 Focal Loss
Focal Loss 是一种解决不平衡问题的经典 loss,基本思想就是把注意力集中于那些预测不准的样本上。
何为预测不准的样本?比如正样本的预测值小于 0.5 的,或者负样本的预测值大于 0.5 的样本。再简单点,就是当正样本预测值>0.5 时,在计算该样本的 loss 时,给它一个小的权值,反之,正样本预测值<0.5 时,给它一个大的权值。同理,对负样本时也是如此。
以二分类为例,一般采用交叉熵作为模型损失。
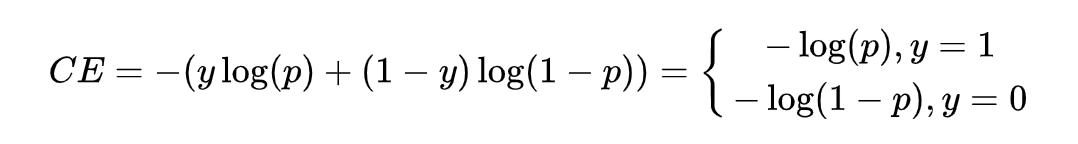
其中 是真实标签, 是预测值,在此基础又出来了一个权重交叉熵,即用一个超参去缓解上述这种影响,也就是下式。
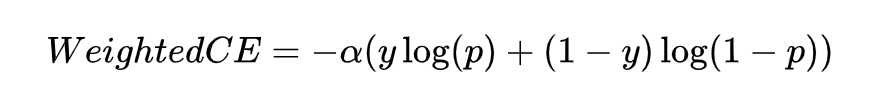
接下来,看下 Focal Loss 是怎么做到集中关注预测不准的样本?
在交叉熵 loss 基础上,当正样本预测值 大于 0.5 时,需要给它的 loss 一个小的权重值 ,使其对总 loss 影响小,反之正样本预测值 小于 0.5,给它的 loss 一个大的权重值。为满足以上要求,则 增大时, 应减小,故刚好 可满足上述要求。
应此加上注意参数 ,得到 Focal Loss 的二分类情况:
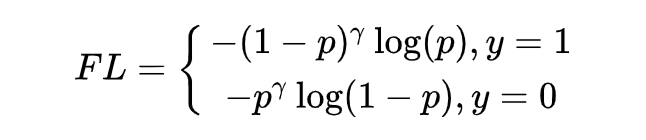
加上调节系数 ,Focal Loss 推广到多分类的情况:
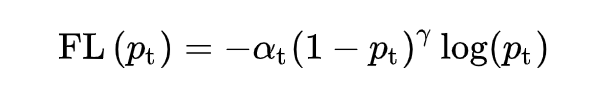
其中 为第 t 类预测值,,试验中效果最佳时,。
代码的实现也是比较简洁的。
def __init__(self, num_class, alpha=None, gamma=2, reduction='mean'):
super(MultiFocalLoss, self).__init__()
self.gamma = gamma
......
def forward(self, logit, target):
alpha = self.alpha.to(logit.device)
prob = F.softmax(logit, dim=1)
ori_shp = target.shape
target = target.view(-1, 1)
prob = prob.gather(1, target).view(-1) + self.smooth # avoid nan
logpt = torch.log(prob)
alpha_weight = alpha[target.squeeze().long()]
loss = -alpha_weight * torch.pow(torch.sub(1.0, prob), self.gamma) * logpt
if self.reduction == 'mean':
loss = loss.mean()
return loss
2.2 GHM Loss
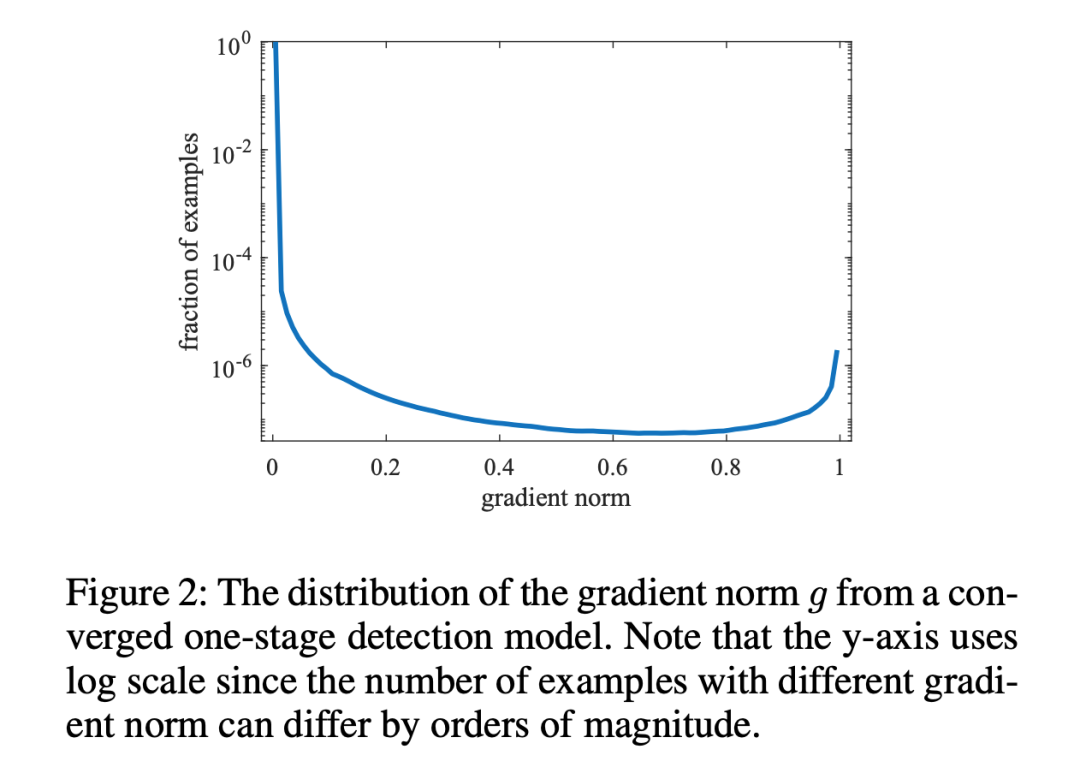
上面的 Focal Loss 注重了对 hard example 的学习,但不是所有的 hard example 都值得关注,有一些 hard example 很可能是离群点,这种离群点当然是不应该让模型关注的。
GHM (gradient harmonizing mechanism) 是一种梯度调和机制,GHM Loss 的改进思想有两点:1)就是在使模型继续保持对 hard example 关注的基础上,使模型不去关注这些离群样本;2)另外 Focal Loss 中, 的值分别由实验经验得出,而一般情况下超参 是互相影响的,应当共同进行实验得到。
Focal Loss 中通过调节置信度 ,当正样本中模型的预测值 较小时,则乘上(1-p),给一个大的 loss 值使得模型关注这种样本。 **于是 GHM Loss 在此基础上,规定了一个置信度范围 ** **,具体一点,就是当正样本中模型的预测值为 **** 较小时,要看这个 ** ** 多小,若是 ** ,这种样本可能就是离群点,就不注意它了。
于是 GHM Loss 首先规定了一个梯度模长 :
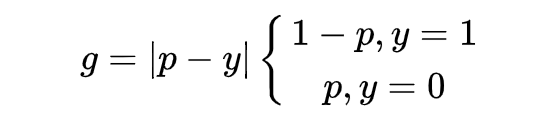
其中, 是模型预测概率值, 是 ground-truth 的标签值,这里以二分类为例,取值为 0 或 1。可发现,** 表示检测的难易程度, 越大则检测难度越大。**
GHM Loss 的思想是,不要关注那些容易学的样本,也不要关注那些离群点特别难分的样本。所以问题就转为我们需要寻找一个变量去衡量这个样本是不是这两种, 这个变量需满足当 值大时,它要小,从而进行抑制,当 值小时,它也要小,进行抑制。 于是文中就引入了梯度密度:
表明了样本 1~N 中,梯度模长分布在 范围内的样本个数, 代表了 区间的长度,因此梯度密度 GD(g) 的物理含义是:单位梯度模长 部分的样本个数。
在此基础上,还需要一个前提,那就是处于 值小与大的样本(也就是易分样本与难分样本)的数量远多于中间值样本,此时 GD 才可以满足上述变量的要求。
此时,对于每个样本,把交叉熵 CE×该样本梯度密度的倒数,就得到 GHM Loss。
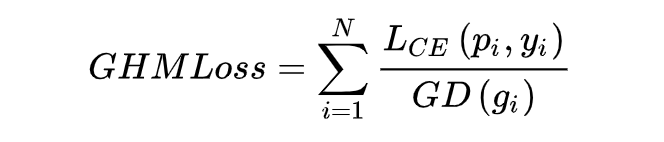
这里附上逻辑的代码,完整的可以上文章首尾仓库查看。
class GHM_Loss(nn.Module):
def __init__(self, bins, alpha):
super(GHM_Loss, self).__init__()
self._bins = bins
self._alpha = alpha
self._last_bin_count = None
def _g2bin(self, g):
# split to n bins
return torch.floor(g * (self._bins - 0.0001)).long()
def forward(self, x, target):
# compute value g
g = torch.abs(self._custom_loss_grad(x, target)).detach()
bin_idx = self._g2bin(g)
bin_count = torch.zeros((self._bins))
for i in range(self._bins):
# 计算落入bins的梯度模长数量
bin_count[i] = (bin_idx == i).sum().item()
N = (x.size(0) * x.size(1))
if self._last_bin_count is None:
self._last_bin_count = bin_count
else:
bin_count = self._alpha * self._last_bin_count + (1 - self._alpha) * bin_count
self._last_bin_count = bin_count
nonempty_bins = (bin_count > 0).sum().item()
gd = bin_count * nonempty_bins
gd = torch.clamp(gd, min=0.0001)
beta = N / gd # 计算好样本的gd值
# 借由binary_cross_entropy_with_logits,gd值当作参数传入
return F.binary_cross_entropy_with_logits(x, target, weight=beta[bin_idx])
2.3 Dice Loss & DSC Loss
Dice Loss 是来自文章 V-Net 提出的,DSC Loss 是香侬科技的 Dice Loss for Data-imbalanced NLP Tasks。
按照上面的逻辑,看一下 Dice Loss 是怎么演变过来的。Dice Loss 主要来自于 dice coefficient,dice coefficient 是一种用于评估两个样本的相似性的度量函数。
定义是这样的:取值范围在 0 到 1 之间,值越大表示越相似。若令 X 是所有模型预测为正的样本的集合,Y 为所有实际上为正类的样本集合,dice coefficient 可重写为:
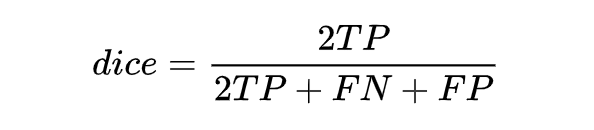
同时,结合 F1 的指标计算公式推一下,可得:
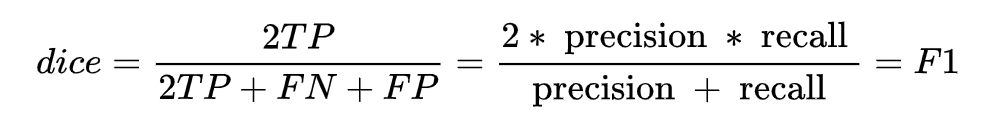
可以动手推一下,就能得到 dice coefficient 是等同 F1 score 的,**因此本质上 dice loss 是直接优化 F1 指标的。 **
上述表达式是离散的,需要把上述 DSC 表达式转化为连续的版本,需要进行软化处理。对单个样本 x,可以直接定义它的 DSC:
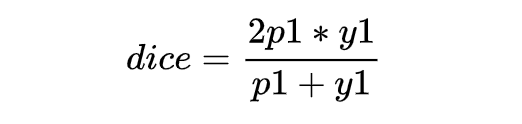
但是当样本为负样本时,y1=0,loss 就为 0 了,需要加一个平滑项。
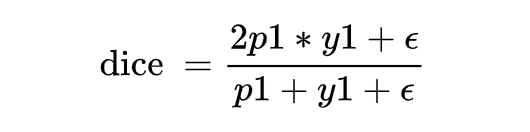
上面有说到 dice coefficient 是一种两个样本的相似性的度量函数,上式中,假设正样本 p 越大,dice 值越大,说明模型预测的越准,则应该 loss 值越小,因此 dice loss 的就变成了下式这也就是最终 dice loss 的样子。
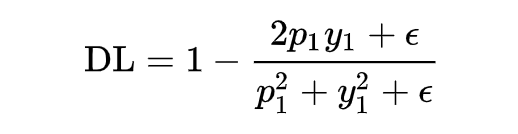
为了能得到 focal loss 同样的功能,让 dice loss 集中关注预测不准的样本,可以与 focal loss 一样加上一个调节系数 ,就得到了香侬提出的适用于 NLP 任务的自调节 DSC-Loss。
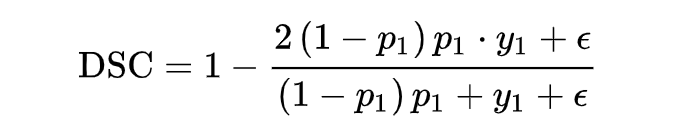
弄明白了原理,看下代码的实现。
class DSCLoss(torch.nn.Module):
def __init__(self, alpha: float = 1.0, smooth: float = 1.0, reduction: str = "mean"):
super().__init__()
self.alpha = alpha
self.smooth = smooth
self.reduction = reduction
def forward(self, logits, targets):
probs = torch.softmax(logits, dim=1)
probs = torch.gather(probs, dim=1, index=targets.unsqueeze(1))
probs_with_factor = ((1 - probs) ** self.alpha) * probs
loss = 1 - (2 * probs_with_factor + self.smooth) / (probs_with_factor + 1 + self.smooth)
if self.reduction == "mean":
return loss.mean()
总结
本文主要讨论了类别不均衡问题的解决办法,可分为数据层面的重采样及模型 loss 方面的改进,如 focal loss, dice loss 等。最后说一下实践下来的经验,由于不同数据集的数据分布特点各有不同,dice loss 以及 GHM loss 会出现些抖动、不稳定的情况。当不想挨个实践的时候,首推 focal loss,dice loss。
-
数据
+关注
关注
8文章
7006浏览量
88955 -
代码
+关注
关注
30文章
4780浏览量
68539 -
nlp
+关注
关注
1文章
488浏览量
22033
发布评论请先 登录
相关推荐
详细介绍数据均衡的方法以及运用的不同场景
Return Loss Headromm
基于差异度的不均衡电信客户数据分类方法
不均衡数据集上基于子域学习的复合分类模型
基于不均衡的加权在线贯序极限学习机
比亚迪在新能源市场不断领先,但不同能源车型发展不均衡问题不可忽视
基于目前TDD网络高负荷及FD不均衡现状分析
一种新的不均衡关联分类算法ACI
数据类别不均衡问题的分类及解决方式

NLP类别不均衡问题之loss大集合
让充电更高效:便携式锂电池均衡维护仪的智能之选






 工商网监
工商网监
评论