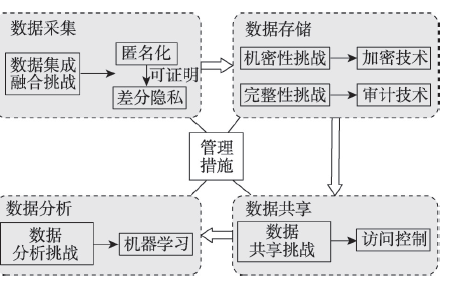
 大数据系统隐私保护关键威廉希尔官方网站
是什么?
大数据系统隐私保护关键威廉希尔官方网站
是什么?
引自:《智能制造信息安全威廉希尔官方网站 》(作者:秦志光, 聂旭云, 秦臻)
伴随着当代社会互联网威廉希尔官方网站 的飞速发展,整个社会也进入了大数据时代。不论人们承认与否,我们的个人数据正在不经意间被动地被企业、个人进行搜集并使用。个人数据的网络化和透明化已经成为不可阻挡的大趋势。这些用户数据对企业来说是珍贵的资源,因为他们可以通过数据挖掘和机器学习从中获得大量有价值的信息。与此同时,用户数据亦是危险的“潘多拉之盒”,数据一旦泄漏,用户的隐私将被侵犯。在智能制造这一环境中,其系统本身不仅能够在实践中不断地充实知识库,而且其还具有自学习功能,并且具有搜集与理解环境信息和自身的信息,并且进行分析判断和规划自身能力的行为,所以在这一环境下,大数据系统的隐私保护工作就显得尤为重要[1]。
「1.大数据系统隐私保护概述」
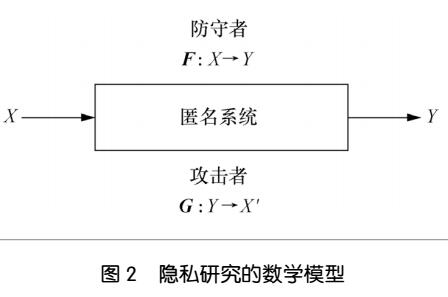
一个隐私保护系统包括各种参与者角色(participation role)、匿名化操作(anonymization operation)与数据状态(data status),它们之间的关系如图1所示。在隐私保护的研究中,有4个数据参与者角色。
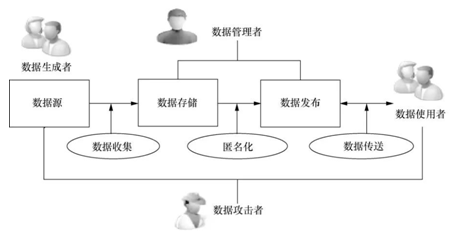
图1一个隐私保护系统中的数据参与角色及其操作
(1)数据生成者(data generator):指那些生成原始数据的个体或组织,例如病人的医疗记录、客户的银行交易业务。他们以某种方式主动提供数据(如发布照片到社交网络平台)或被动提供数据给别人(如在电子商务、电子支付系统中留下个人的信用卡交易记录等)。
(2)数据管理者(data curator):指那些收集、存储、掌握、发布数据的个人或组织。
(3)数据使用者(data user):指为了各种目的对发布的数据集进行访问的用户。
(4)数据攻击者(data attacker):指那些为了善意或恶意的目的从发布的数据集中企图获取更多信息的人。数据攻击者是一种特殊类型的数据使用者。
在大数据系统中隐私保护威廉希尔官方网站 方面,隐私保护的研究领域主要关注基于数据失真的威廉希尔官方网站 、基于数据加密的威廉希尔官方网站 和基于限制发布的威廉希尔官方网站 。
基于数据失真的威廉希尔官方网站 ,主要通过添加噪声等方法,使敏感数据失真但同时保持某些数据或数据属性不变,仍然可以保持某些统计方面的性质。包括随机化,即对原始数据加入随机噪声,然后发布扰动后数据的方法;第二种是阻塞与凝聚,阻塞是指不发布某些特定数据的方法,凝聚是指原始数据记录分组存储统计信息的方法;第三类是差分隐私保护。
基于数据加密的威廉希尔官方网站 ,采用加密威廉希尔官方网站 在数据挖掘过程隐藏敏感数据的方法,包括安全多方计算 SMC,即使两个或多个站点通过某种协议完成计算后,每一方都只知道自己的输入数据和所有数据计算后的最终结果;还包括分布式匿名化,即保证站点数据隐私、收集足够的信息实现利用率尽量大的数据匿名。
基于限制发布的威廉希尔官方网站 ,有选择地发布原始数据、不发布或者发布精度较低的敏感数据,实现隐私保护。当前这类威廉希尔官方网站 的研究集中于“数据匿名化”,保证对敏感数据及隐私的披露风险在可容忍范围内。包括K-anonymity、L-diversity、T-closeness等[2]。
最早被广泛认同的隐私保护模型是k-匿名,由Samarati和Sweeney在2002年提出,作者正是马萨诸塞州医疗数据隐私泄露事件的攻击者。为应对去匿名化攻击,k-匿名要求发布的数据中每一条记录都要与其他至少k-1条记录不可区分(称为一个等价类)。当攻击者获得k-匿名处理后的数据时,将至少得到k个不同人的记录,进而无法做出准确的判断。参数k表示隐私保护的强度,k值越大,隐私保护的强度越强,但丢失的信息更多,数据的可用性越低。
然而,美国康奈尔大学的Machanavajjhala等人在2006年发现了k-匿名的缺陷,即没有对敏感属性做任何约束,攻击者可以利用背景知识攻击、再识别攻击和一致性攻击等方法来确认敏感数据与个人的关系,导致隐私泄露。例如,攻击者获得的k-匿名化的数据,如果被攻击者所在的等价类中都是艾滋病病人,那么攻击者很容易做出被攻击者肯定患有艾滋病的判断(上述就是一致性攻击的原理)。为了防止一致性攻击,新的隐私保护模型l-diversity改进了k-匿名,保证任意一个等价类中的敏感属性都至少有l个不同的值。t-Closeness在l-diversity 的基础上,要求所有等价类中敏感属性的分布尽量接近该属性的全局分布。(a, k)-匿名原则,则在k-匿名的基础上,进一步保证每一个等价类中与任意一个敏感属性值相关记录的百分比不高于a。
上述隐私保护模型依然有缺陷,需要不断地被改进,但同时又有新的攻击方法出现,使得基于k-匿名的传统隐私保护模型陷入这样一个无休止的循环中。差分隐私(differential privacy, DP)是微软研究院的Dwork在2006年提出的一种新的隐私保护模型。该方法能够解决传统隐私保护模型的两大缺陷:
(1)定义了一个相当严格的攻击模型,不关心攻击者拥有多少背景知识,即使攻击者已掌握除某一条记录之外的所有记录信息(即最大背景知识假设),该记录的隐私也无法被披露;
(2)对隐私保护水平给出了严谨的定义和量化评估方法。正是由于差分隐私的诸多优势,使其一出现便迅速取代传统隐私保护模型,成为当前隐私研究的热点,并引起了理论计算机科学、数据库、数据挖掘和机器学习等多个领域的关注。
「2.隐私保护常用算法简介」
1)K-匿名(K-Anonymity)算法
在大数据的时代,很多机构需要面向公众或研究者发布其收集的数据,例如医疗数据,地区政务数据等。这些数据中往往包含了个人用户或企业用户的隐私数据,这要求发布机构在发布前对数据进行脱敏处理。K匿名算法是比较通用的一种数据脱敏方法。例如下面两张表,一张是用户的会员注册信息表,一张是对外发布的医疗信息表。每一行代表用户的一条记录,每一列表示一个属性。每一个记录与一个特定的用户/个体关联,这些属性可以分为4类。
表1 会员注册信息表
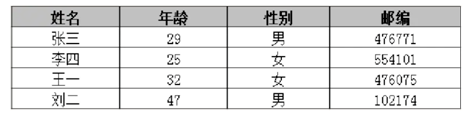
表2 医疗信息表
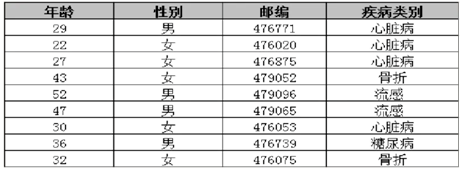
(1)显示标识符(ID):记录的唯一标识。
(2)准标识符(QI):较高概率识别记录的最小属性集合。
(3)敏感属性(SA):需要保护的信息。
(4)非敏感属性(NSA):为保护用户的数据隐私,通常在发布之前会删除显示标识符,但通过准标识符结合背景知识,也可以获得一次额外敏感信息。所以通常对准标识符进行匿名处理。
K-匿名(K-Anonymity)是Samarati和Sweeney在1998年提出的威廉希尔官方网站 ,该威廉希尔官方网站 可以保证存储在发布数据集中的每条个体记录对于敏感属性不能与其他的K-1个个体相区分,即K-匿名机制要求同一个准标识符至少要有K条记录,因此观察者无法通过准标识符连接记录。
K-匿名的具体使用如下:隐私数据脱敏的第一步通常是对所有标识符列进行移除或是脱敏处理,使得攻击者无法直接标识用户。但是攻击者还是有可能通过多个准标识列的属性值识别到个人。攻击者可能通过(例如知道某个人的邮编,生日,性别等)包含个人信息的开放数据库获得特定个人的准标识列属性值,并与大数据平台数据进行匹配,从而得到特定个人的敏感信息。为了避免这种情况的发生,通常也需要对准标识列进行脱敏处理,如数据泛化等。数据泛化是将准标识列的数据替换为语义一致但更通用的数据。
K-匿名威廉希尔官方网站 就是每个相等集(或称为等价组)中的记录个数为K个,那么当针对大数据的攻击者在进行链接攻击时,对于任意一条记录的攻击同时会关联到相等集中的其他K-1条记录。这种特性使得攻击者无法确定与特定用户相关的记录,从而保护了用户的隐私。
K-匿名的实施,通常是通过概括(generalization)和隐匿(suppression)威廉希尔官方网站 来实现。概括(generalization)指对数据进行更加概括、抽象的描述,使得无法区分具体数值。通过降低发布数据的精度,使得每条记录至少与数据表中其他的K-1条记录具有完全相同的准标识符属性值,从而降低链接攻击所导致的隐私泄露风险。
K-匿名威廉希尔官方网站 能保证以下3点:
(1)攻击者无法知道某特定个人是否在公开的数据中给定一个人。
(2)攻击者无法确认他是否有某项敏感属性。
(3)攻击者无法确认某条数据对应的是哪个人。但从另外一个角落来看,K-匿名威廉希尔官方网站 虽然可以阻止身份信息的公开,但无法防止属性信息的公开,导致其无法抵抗同质攻击,背景知识攻击,补充数据攻击等情况。
k-匿名算法存在着一些攻击方式:
(1)同质化攻击:某个k-匿名组内对应的敏感属性的值也完全相同,这使得攻击者可以轻易获取想要的信息。
(2)背景知识攻击:即使k-匿名组内的敏感属性值并不相同,攻击者也有可能依据其已有的背景知识以高概率获取到其隐私信息。
(3)未排序匹配攻击:当公开的数据记录和原始记录的顺序一样的时候,攻击者可以猜出匿名化的记录是属于谁。例如如果攻击者知道在数据中小明是排在小白前面,那么他就可以确认,小明的购买偏好是电子产品,小白是家用电器。解决方法也很简单,在公开数据之前先打乱原始数据的顺序就可以避免这类的攻击。
(4)补充数据攻击:假如公开的数据有多种类型,如果它们的k-anonymity方法不同,那么攻击者可以通过关联多种数据推测用户信息[3]。
2) l-diversity 算法
美国康奈尔大学的Machanavajjhala等人在2006年发现了k-匿名的缺陷,即没有对敏感属性做任何约束,攻击者可以利用背景知识攻击、再识别攻击和一致性攻击等方法来确认敏感数据与个人的关系,导致隐私泄露。例如,攻击者获得的k-匿名化的数据,如果被攻击者所在的等价类中都是艾滋病病人,那么攻击者很容易做出被攻击者肯定患有艾滋病的判断(上述就是一致性攻击的原理)。为了防止一致性攻击,新的隐私保护模型l-diversity改进了k-匿名,保证任意一个等价类中的敏感属性都至少有l个不同的值。t-Closeness在l-diversity 的基础上,要求所有等价类中敏感属性的分布尽量接近该属性的全局分布。(a,k)-匿名原则,则在k-匿名的基础上,进一步保证每一个等价类中与任意一个敏感属性值相关记录的百分比不高于a。如果一个等价类里的敏感属性至少有l个良表示(well-represented)的取值,则称该等价类具有l-diversity。如果一个数据表里的所有等价类都具有l-diversity,则称该表具有l-diversity。
3)t-closeness算法
t-closeness认为,在数据表公开前,观察者有对于客户敏感属性的先验信念(prior belief),数据表公开后观察者获得了后验信念(posterior belief)。这二者之间的差别就是观察者获得的信息(information gain)。t-closeness将信息获得又分为两部分:关于整体的和关于特定个体的。
首先考虑如下思想实验:
记观察者的先验信念为B0,我们先发布一个抹去准标识符信息的数据表,这个表中敏感属性的分布记为Q,根据Q,观察者得到了B1;然后发布含有准标识符信息的数据表,那么观察者可以由准标识符识别特定个体所在等价类,并可以得到该等价类中敏感属性的分布P,根据P,观察者得到了B2。
l-diversity其实就是限制B2与B0之间的区别。然而,我们发布数据是因为数据有价值,这个价值就是数据整体的分布规律,可以用B0与B1之间的差别表示。二者差别越大,表明数据的价值越大,这一部分不应被限制。也即整体的分布Q应该被公开。因为这正是数据的价值所在。而B1与B2之间的差别,就是我们需要保护的隐私信息,应该被尽可能限制。
t-closeness通过限制P与Q的距离来限制B1与B2的区别。其认为如果P=Q,那么应有B1=B2。P、Q越近,B1、B2也应越近。
The t-closeness Principle:如果等价类E中的敏感属性取值分布与整张表中该敏感属性的分布的距离不超过阈值t,则称E满足t-closeness。如果数据表中所有等价类都满足t-closeness,则称该表满足t-closeness。
4)差分隐私算法
差分隐私,英文名为differential privacy,顾名思义,保护的是数据源中一点微小的改动导致的隐私泄露问题。图2为差分隐私处理流程框架。
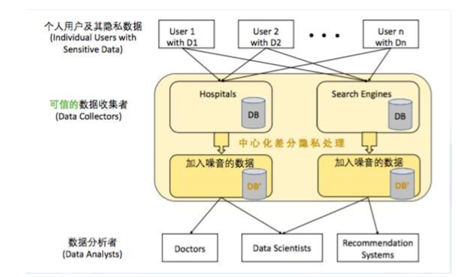
图2 差分隐私处理框架流程
「3.面向聚类的隐私保护方案」
1) 面向大数据分析的隐私保护聚类方法
一种面向大数据分析的隐私保护聚类方法,其特征在于,包括以下步骤:
(1)对数据集中的数据进行归一化处理;
(2)将数据集平均分为k个子集,在每个子集中随机选择一个样本点作为初始中心点;
(3)设置总隐私预算ε和最大迭代次数tm,计算最小隐私预算εm和迭代次数t=ε/εm,如果t>tm,则采用等差隐私预算分配方法来分配隐私预算序列,如果t≤tm,则采用平均隐私预算分配方法来分配隐私预算序列,得到隐私预算序列εp,其中1≤p≤tm;
(4)对于数据集中的所有样本点,分别计算其到k个中心点的欧氏距离,将样本点分配给最近的中心点,将数据集划分为k个聚类C={C1,C2,…,Ck};
(5)根据隐私预算序列εp中对应的项生成拉普拉斯分布的随机数;
(6)对于每一个聚类Cj,其中1≤j≤k,计算该聚类样本点数目num以及样本点的和向量sum,分别对其添加噪声得到num′和sum′,上述噪声为步骤(5)中拉普拉斯分布的随机数;
(7)更新每一个聚类Cj的中心点为sum′/num′,其中1≤j≤k;
(8)计算误差平方和,如果本次和前次迭代的误差平方和的差的绝对值小于设置阈值或者迭代次数达到上限tm,则结束执行,得到聚类结果,否则转到步骤4继续执行下一次迭代[4]。
2)隐藏算法NeSDO
为了防止微数据敏感性值的泄露,数据隐藏的主要思想是通过修改微数据部分(或全部)数值,尽量避免数据记录中属性值之间出现一对一的映射模式,以降低可能存在的逆推猜测风险,这就要求隐藏策略尽量保留数据个体间的共性,弱化个体记录的个性特征。例如基于限制发布威廉希尔官方网站 的k-匿名隐藏策略,通过限制所发布的每条记录在准标识符属性上与至少k-1条记录的准标识符属性相同,破坏属性值间的一对一映射关系,防止敏感微数据值的泄露;而聚类分析的目标是将数据集分成若干聚簇,同一聚簇内数据对象具有较高的相似性,不同聚簇间的数据对象具有较高的相异性,隐藏中如果仅保留数据记录的共性,则隐藏后数据聚类后所得聚簇划分可能变得模糊,从而导致错误的聚类结果。因此,面向聚类的数据隐藏中,在保持微数据共性的同时,还应保持微数据关于聚类的个性特征。
在基于数据失真的扰动隐藏中,合成数据替换威廉希尔官方网站 采用人工合成数据(通常采用某数据分组的统计信息)对数据表中的个体数据进行置换,由于合成数据并不存在于原数据表中,这种方法往往能获得较好的隐私保护安全性,同时聚类与数据表全局与局部的统计信息也密切相关,选取合适的数据统计信息有利于聚类可用性的维护。考虑分析共性数据记录和个性数据记录特征与其邻域均值的关系,用合适的邻域数据记录均值替换共性数据记录与个性数据记录的各属性取值,实现隐藏操作对数据记录关于聚类的共性特征和个性特征的保持。
-
数据
+关注
关注
8文章
7006浏览量
88955 -
机器学习
+关注
关注
66文章
8408浏览量
132576 -
大数据
+关注
关注
64文章
8884浏览量
137409
发布评论请先 登录
相关推荐
一文汇总大数据四大方面十五大关键威廉希尔官方网站
平衡创新与伦理:AI时代的隐私保护和算法公平
【视频】智能家居系统关键威廉希尔官方网站 分析与应用
智能穿戴产业的五大关键威廉希尔官方网站
明白VPP关键威廉希尔官方网站 有哪些
面向OpenHarmony终端的密码安全关键威廉希尔官方网站
视觉导航关键威廉希尔官方网站 及应用
大数据时代,这十五大关键威廉希尔官方网站 你竟不知道?
贵州省大数据领域威廉希尔官方网站 榜单“大数据安全与隐私保护关键威廉希尔官方网站 ”项目启动
医疗大数据面临的挑战及相应的隐私保护威廉希尔官方网站





 工商网监
工商网监
评论