 寄存器的作用以及复位
寄存器的作用以及复位
1. 寄存器的作用
1)时序逻辑存储数据。例如,一个计数器,每个周期要加1,那它就要使用寄存器实现。纯组合逻辑是实现不了的。
2)CPU和硬件协调工作,提高设计的灵活度。例如,在休眠时,我们可能会把某个模块的时钟关掉,然后在正常工作时,再将时钟打开。这个就可以通过CPU来实现。
2.基地址/偏移地址
几乎我们设计的每个模块都会有寄存器,而它们的寄存器或多或少能被CPU访问到。但CPU的接口通常只有一组总线去访问这些模块,所以设计上都会把CPU和各个模块挂到总线上。这样CPU作为Master就能够访问到所有的模块了。
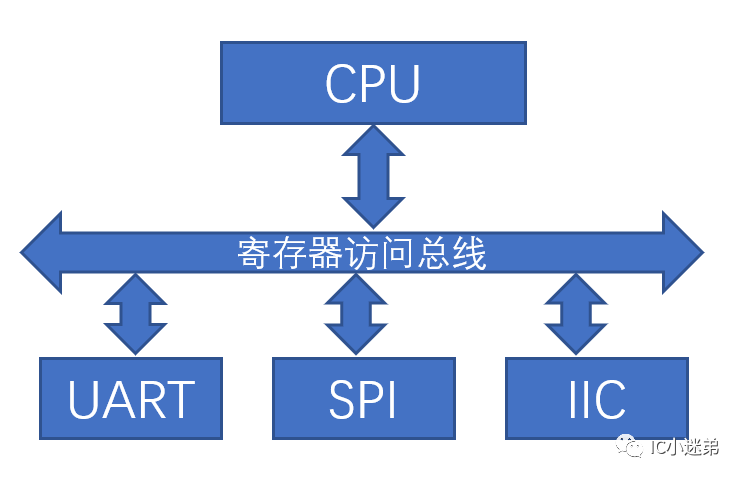
那CPU的地址是怎么映射到一个具体的寄存器上的呢?这就是涉及到基地址和偏移地址的概念。首先,我们在定架构时,会做一张地址映射表格。我们就以下图为例,假设给每个外设接口都分配了32KB的地址空间,32KB占用的是15bit。所以32bit的CPU地址的高17位就是基地址,而低15位便是偏移地址。当CPU发一个0x46018000的地址下来,那么硬件会自动根据它的基地址判断它是去访问I2C的。然后根据偏移地址便可以知道是访问I2C的哪一个寄存器了。

3. 寄存器的复位
- ** 需不需要复位**

如上图,就面积而言,同样的驱动等级下,带复位的寄存器要比不带复位的寄存器大。所以在实际中,为了节省面积,有些寄存器是可以不加复位的。那么,什么样的寄存器不需要复位呢?答案很简单:如果一个寄存器的值是在别的信号的控制下更新,且只有在更新后才会被使用,那么这个寄存器就可以不用复位。例如流水线的数据通路;又例如总线设计中的部分寄存器。我们以AXI总线的地址通道为例,由于addr和size这些控制信号是在valid和ready的控制下更新的。换句话说,在时钟沿下,只要valid和ready同时为高,addr和size就会马上更新;而valid和ready只要有一个不为高时,总线都不会去使用addr和size的值(此时它们的值是don’t care的)。在这个前提下,addr和size是可以不用复位的;但是valid和ready就一定要复位。参考代码如下:

不过话说回来,寄存器不加复位的设计风险会比较大,所以建议在设计初期都加上复位,后面要抠面积时,再回来修改。
-
** 同步复位or异步复位**
在电路结构上,同步复位是要比异步复位多一个与门的。如果采用同步复位设计,那么就相当于每个寄存器都会多一个与门,这无疑会撑大面积。所以现在的设计基本上都是采用异步复位,然后在前面加个异步复位同步释放电路。
而由于异步复位同步释放是要在时钟下对复位打两拍,所以在一些源同步设计中,我们要特别注意的一个问题是:时序上是否允许你做同步,例如在SPI slave的设计中,假设我们使用CS进行复位。由于时钟是master发送过来的,每一个数据对应一个时钟。这时就不能用master发送过来的时钟做同步了。
-
** 复位源**
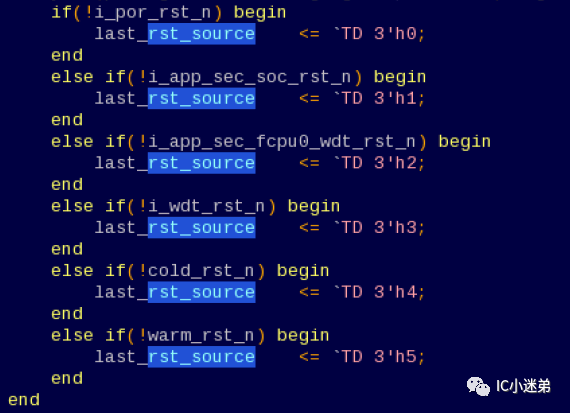
一个复杂的设计中,一个寄存器可能会有很多复位源的。例如,上电复位,软复位,watchdog复位等等。因此,在设计的时候,我们要先根据功能和应用场景将寄存器分到不同的复位域。并画出具体的复位电路图,然后对着电路图来coding。
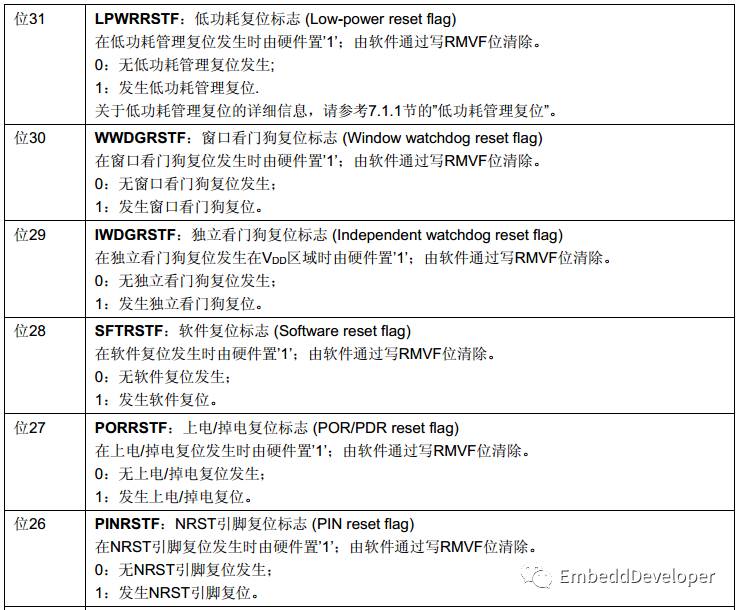
- ** 复位原因记录寄存器**
当复位源很复杂时,建议在设计中加上一个寄存器。用于记录上次复位的原因,方便debug。如下图,不同的复位,该寄存器会被复位成不一样的值。另外,还可以加上一个计数器,用于记录复位的次数等。
4.寄存器的时钟域
这里的时钟域指的是,配置寄存器的时钟域和使用寄存器的时钟域。如果它们是同一个时钟域,那就没什么好顾虑的。但是如果它们属于异步时钟域。那这时候就要对寄存器做静态和动态甚至更细的划分。所谓静态寄存器是指,在使用的过程中,寄存器是不会被改变的;而在改变的过程中一定不能被使用。举个例子,假设某个模块的时钟是通过分频获得的,而分频系数可能在上电初始化后就不会再去修改,而这个模块只会在初始化完成之后才会启动工作。那么这个分频系数寄存器就可以当作是静态的。否则,这个寄存器就是动态的。
在跨时钟域处理的场景中,区分静态和动态寄存器尤为重要。例如,假设一个寄存器是在clka下配置的,却用于clkb下。这时,如果是静态寄存器,那就不需要做跨时钟域处理。因为不管clkb在哪个时刻采样,都只能采到固定值;而动态寄存器可能在采样时发生变化,从而导致亚稳态的出现。当然,也有人为了保险起见,不管是静态和动态寄存器,都统一做跨时钟域处理了。
5.访问权限
寄存器的访问权限类型多种多样,包括但不局限于下图。我们在设计中要考虑的是,哪些寄存器是CPU能否访问的,哪些寄存器是硬件能够访问的。尤其是在安全相关的设计中(例如安全boot),要特别重视这访问权限。因为CPU能读到的东西,随时都会被别人看到。

访问权限在寄存器描述文档中是必不可缺的。下面给出一个参考格式。

6.Byte mask
CPU访问寄存器的数据总线要么是32bit,要么是64bit。也就是说数据总线会是多byte的。如果没有byte mask,那么CPU在修改某一byte时,要做读改写的操作。所以通常在设计中,我们会给寄存器加上byte mask的属性。例如,寄存器是32bit的,那么可以通过4bit的byte_en来控制写。
7.多路访问源仲裁
一个寄存器有多个访问源的场景很常见。例如,CPU和其它硬件都可以访问;又例如多个CPU可以访问。我们举个例子,假设模块A和模块B都有一个SPI控制器,但是它们共用一组IO,并使用一个寄存器spi_switch来选择是模块A还是模块B的控制器接到IO中。而好死不死spi_switch又正好能够被两个CPU配置。那么,假设CPU0把IO交给了模块A,如果模块A在使用SPI传输的过程中,CPU1把IO切到了模块B,这就出问题了。那么只是在寄存器spi_switch的设计上下功夫,该如何设计才能避免上面的问题呢?答案是有的,但我要卖个关子,你们自己想去吧。
8.保留寄存器
在实际项目中,固件的完成时间往往要落后于RTL设计,你总会遇到tapeout了,固件还在设计的情况。也就是说,我们在设计RTL时,有可能固件的一些功能或架构还不够明确。所以我们在设计时,可视情况,预留多一些寄存器,这些寄存器在RTL设计时还没有明确的功能,因此,我管它们叫做保留寄存器(reserved寄存器),如下图。万一固件哪天需要使用寄存器来做标记,直接使用这些保留寄存器即可。

9.寄存器和RAM之间的选择
项目中使用到memory做缓存是家常便饭。而从实现的角度来看,这些memory可通过寄存器来实现,也可以通过调用RAM来实现。选择寄存器和RAM需要考虑三点:
1)面积。一般小的memory可以使用寄存器搭;而较大的memory使用RAM搭比较换算。两者选择的边界很难分清,需要根据具体工艺来评估。
2)因为寄存器的读取是单拍就出来了,而RAM的读取要等下一拍才出来。所以在做选择时,我们要先看看是否允许数据下一拍出来。
3)RAM的读latency很大,它有可能是项目timing的瓶颈。尤其是RAM比较大,或者RAM的访问源比较多的时候。在评估时,可是打开RAM的library,来查看具体的latency。
10.默认值
设置寄存器的默认值也是一门艺术。这里列几个我暂时还记得的规则:
1) IO驱动的默认值不要给太小。
2) MCU复位自己的软复位寄存器的默认值不能有效。否则,复位状态下,MCU根本就动不起来,更别说去释放软复位了。
3)时钟gate相关寄存器要防止死锁。举个极端的例子,假设MCU的时钟gate是通过MCU自己配置寄存器来控制的。那么这个gate寄存器的默认值就是要开启的。否则复位后,时钟会被gate住,MCU根本就动不起来。
11.寄存器复用
还是为了那该死的面积。举个例子,假设一个系统是半双工的,也就是说同一时间只能读或者只能写。那么读跟写是可以共用一部分寄存器的。
12.寄存器访问接口
比较常见的寄存器接口有三个:
1.APB总线
2.AHB总线
3.用户自定义的总线
具体的设计实例,去知识星球看I2C控制器的代码吧。
13.寄存器文档和代码自动生成
手敲寄存器代码,MAS文档和代码分开维护都是蛋疼的事情。所以很多公司都只会维护一张excel表格,并在excel表格的寄存上生成MAS和代码,甚至是C语言头文件和寄存器RALF文件。这个具体的脚本还在开发中,后面会更新到知识星球
-
寄存器
+关注
关注
31文章
5343浏览量
120363 -
cpu
+关注
关注
68文章
10863浏览量
211763 -
时序逻辑
+关注
关注
0文章
39浏览量
9163
发布评论请先 登录
相关推荐
移位寄存器怎么用_如何使用移位寄存器_移位寄存器的用途
GPIO寄存器

配置STM32寄存器控制GPIO点亮LED





 工商网监
工商网监
评论