 一文浅谈软件测试
一文浅谈软件测试
作者 |苏亭 华东师范大学软件工程学院教授
版块 |鉴源论坛 · 观模
01软件测试的“起源”和发展
从狭义的角度说,软件测试是软件开发中的一个流程,即通过把程序实际运行起来并试图找出其中可能存在的错误。软件错误一般被大家通俗地称为“bug”。事实上,“bug”这个词最早起源于Grace Hopper(她是美国海军准将、计算机科学家,也是世界上最早的一批程序员之一)的一个真实故事。1947年9月9日,Grace和同事们在检查哈佛二号电脑(Harvard Mark II)总是出错的原因,大家仔细检查程序仍找不出错误,最后才发现原来是一只飞蛾意外飞入电脑内部的继电器而造成短路,他们把这只飞蛾移除后便成功让电脑正常运作[1](下图就是当时事故的记录和那只飞蛾)。从此以后,“bug”一词就被拿来指称软件错误,“debug”一词被拿来指称调试查找软件错误。

图1事故记录
后来,随着人们对软件错误的认识逐步加深,软件测试也经历了多个阶段的发展。最初Grace所在的年代,人们只是为了找出软件错误的原因(Debugging Period);后来1957年开始,人们强调需要设计软件测试集来验证/确保软件符合设计时提出的需求规范和软件功能(Demonstration Period);从1979年开始,人们开始主动地去寻找能触发软件错误的测试集(Destruction Period);再后来,软件测试成为了保障软件质量的重要手段,成为软件开发流程中一个必不可少的阶段[2]。比如,下图是经典的软件开发生命周期模型(SDLC)之一的瀑布模型(Waterfall Method),软件测试是其中的重要一环。
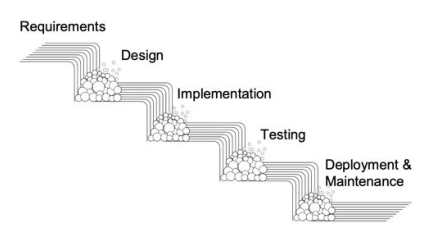
图2瀑布模型
值得注意的是,在经典的软件开发生命周期模型中,如上图的瀑布模型中,软件测试是处于比较“靠右”的阶段。现如今,软件测试越来越强调“左移”测试(Shift-Left Testing,最早由Larry Smith在2001年提出[3]),其主要目的是为了让软件测试尽早地介入到软件需求分析、设计等阶段,能尽早地在这些阶段就能发现软件缺陷(而不是在软件实现结束后才介入测试),以期望进一步降低软件错误的修复成本。下图(引用于[4])形象地给出了这种变化趋势(下方左边的图给出了传统开发生命周期模型中,软件测试所在的位置和比重比较靠右;下方右边的图逐步演化为把测试阶段左移,让软件测试阶段更早地接入到软件开发的早期阶段,如需求、设计和开发)。
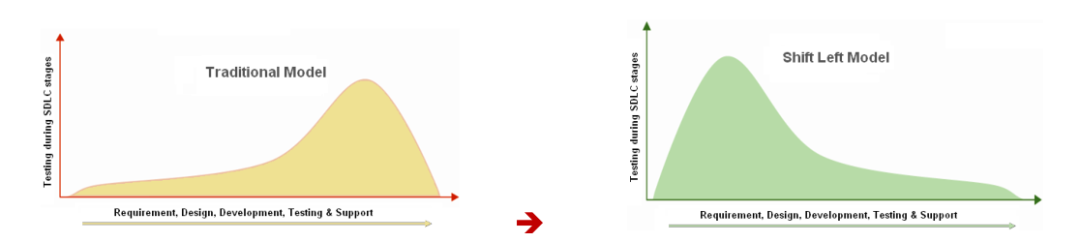
图3软件测试变化趋势
02软件测试能做什么?不能做什么?
软件测试是业界使用最普遍的质量保障手段。因为,软件测试在适应性和可扩展性方面比较强,在特定的领域场景下,如果软件测试方法和威廉希尔官方网站 设计得当,能够有效地找到潜在的软件错误。但是,我们也需要注意,它也有其局限性,即软件测试没法保证找到被测对象程序中所有的软件错误(“Testing shows the presence, not the absence of bugs.” By Edsger W. Dijkstra)。与之相对应的,软件形式化验证威廉希尔官方网站 能够严格地证明某个软件程序没有软件错误的存在(当然,这句话也是在一些特定的假设下才成立)。
03找到软件测试错误需要满足什么条件?关键要素在哪里?
据统计,软件测试占所有软件开发时间 40~50%,占所有研发费用 50%以上。软件测试作为一种有效的软件质量保障手段,其主要缺点在于测试成本很高(主要原因在于,一方面很多情况下测试过程离不开手工参与;在另外一方面,测试讲究“大力出奇迹”,因为需要依靠大量的测试执行去碰运气)。因此,如何实现高效、自动化的软件测试威廉希尔官方网站 成为了业界和学界普遍关心的问题。然而,无论软件测试应用场景是什么,实现软件测试的关键要素有两个:(1)测试输入;(2)测试预言(Test Oracle)。下面以一个具体的代码片段例子(该代码片段选自于[5])来解释下。

图4 代码片段
上面这个程序是为了统计一个数组arr中元素0的个数。仔细看就会发现,这里隐藏着一个软件错误:for循环中的迭代起始条件(int i=1)是错误的,应该是(int i=0)。这就是一个具体的软件错误(英文中称为Software Fault)。
针对这样一段软件代码,一个可能的测试用例(Test Case)可以是:{arr=[2,7,0],expected_output=1}(这里arr=[2,7,0]称为测试输入,expected_output=1称为预期输出或测试预言)。软件测试中,判断一个测试输入是否找到了一个软件错误,最简单的办法就是判断测试输入在执行后的实际输出是否符合预期输出。显然,这个测试用例是无法找到该软件错误的,因为实际输出就是等于1,与预期输出是一样的。相反,一个能找到该错误的测试用例可以是:{arr=[0,2,7],expected_output=1}。因为这个测试用例的执行后的实际输出是0,与预期输出是不相等的。
这里,我们可以理解下为什么后一个测试用例能找到这个软件错误,而前一个测试用例却不能找到错误。因为软件测试找到一个软件错误必须满足的四个条件:
(1)Reachability:测试输入受限必须到达Software Fault所在的代码位置(如,这里的int i=1);
(2)Infection:这个测试输入必须使得软件程序的状态出错(如,这里i的值在第一次循环迭代的时候被错误地赋值为了1);
(3)Propagation:这个错误的程序状态必须导致程序的最后输出结果错误,或者最终的程序状态错误(如,这里Count这个返回值为0,其实是错误的);
(4)Reveal:测试预言必须能否观察到程序的最后输出或者最终的程序状态是错误的(如,这里通过对比Count的值和预期输出值1是能判定程序出错了)。
根据上面的这四个条件,我们很容易发现,前一个测试用例只满足了(1)和(2),没有满足(3)和(4);而后一个测试用例满足了上述四个条件。因此,通过上面一个例子,可以看到,为了实现高效的软件测试,最需要解决的是生成有效的测试输入、以及写出(甚至是自动生成)有效的测试预言。这也构成了设计开发自动化软件测试方法和威廉希尔官方网站 的主要挑战。
参考资料:
[1] Grace Hopper - Wikipedia. https://en.wikipedia.org/wiki/Grace_Hopper.
[2] History of software testing. https://davidmoremad.medium.com/history-of-software-testing-cfa461c4ae0a.
[3] Shift-Left Testing By Larry Smith. https://www.drdobbs.com/shift-left-testing/184404768.
[4] Shift Left Testing: What, Why & How To Shift Left. https://www.bmc.com/blogs/what-is-shift-left-shift-left-testing-explained.
[5] "Introduction to Software Testing", Paul Ammann and Jeff Offutt.
审核编辑黄宇
-
测试
+关注
关注
8文章
5283浏览量
126610 -
软件
+关注
关注
69文章
4929浏览量
87415
发布评论请先 登录
相关推荐
如何利用emulation提升软件测试效率
软件测试六大问 全面而深入的软件测试行业解疑
软件接口自动化测试,使用软件工具+工装治具测试

如何使用EMC测试软件执行辐射抗扰度测试?(三)软件检查及手动模式
如何使用EMC测试软件执行辐射抗扰度测试?(二)测试、校准方法及调制
如何使用EMC测试软件执行辐射抗扰度测试?(一)测试方法





 工商网监
工商网监
评论