 分布式实时日志分析解决方案ELK部署架构
分布式实时日志分析解决方案ELK部署架构
一、概述
ELK 已经成为目前最流行的集中式日志解决方案,它主要是由 Beats、Logstash、Elasticsearch、Kibana 等组件组成,来共同完成实时日志的收集,存储,展示等一站式的解决方案。本文将会介绍 ELK 常见的架构以及相关问题解决。
Filebeat:Filebeat 是一款轻量级,占用服务资源非常少的数据收集引擎,它是 ELK 家族的新成员,可以代替 Logstash 作为在应用服务器端的日志收集引擎,支持将收集到的数据输出到 Kafka,Redis 等队列。
Logstash:数据收集引擎,相较于 Filebeat 比较重量级,但它集成了大量的插件,支持丰富的数据源收集,对收集的数据可以过滤,分析,格式化日志格式。
Elasticsearch:分布式数据搜索引擎,基于 Apache Lucene 实现,可集群,提供数据的集中式存储,分析,以及强大的数据搜索和聚合功能。
Kibana:数据的可视化平台,通过该 web 平台可以实时的查看 Elasticsearch 中的相关数据,并提供了丰富的图表统计功能。
二、ELK 常见部署架构
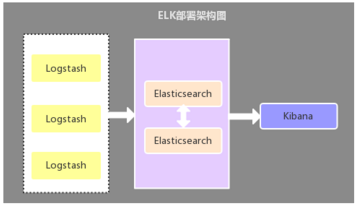
2.1、Logstash 作为日志收集器
这种架构是比较原始的部署架构,在各应用服务器端分别部署一个 Logstash 组件,作为日志收集器,然后将 Logstash 收集到的数据过滤、分析、格式化处理后发送至 Elasticsearch 存储,最后使用 Kibana 进行可视化展示,这种架构不足的是:Logstash 比较耗服务器资源,所以会增加应用服务器端的负载压力。
2.2、Filebeat 作为日志收集器
该架构与第一种架构唯一不同的是:应用端日志收集器换成了 Filebeat,Filebeat 轻量,占用服务器资源少,所以使用 Filebeat 作为应用服务器端的日志收集器,一般 Filebeat 会配合 Logstash 一起使用,这种部署方式也是目前最常用的架构。
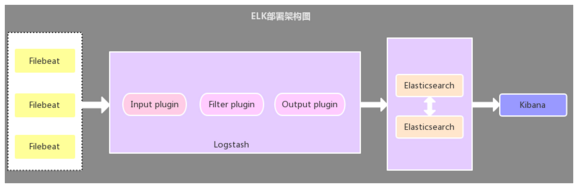
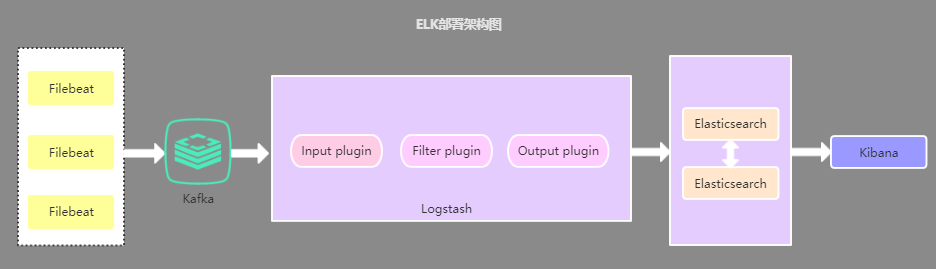
2.3、引入缓存队列的部署架构
该架构在第二种架构的基础上引入了 Kafka 消息队列(还可以是其他消息队列),将 Filebeat 收集到的数据发送至 Kafka,然后在通过 Logstasth 读取 Kafka 中的数据,这种架构主要是解决大数据量下的日志收集方案,使用缓存队列主要是解决数据安全与均衡 Logstash 与 Elasticsearch 负载压力。
2.4、以上三种架构的总结
第一种部署架构由于资源占用问题,现已很少使用,目前使用最多的是第二种部署架构,至于第三种部署架构个人觉得没有必要引入消息队列,除非有其他需求,因为在数据量较大的情况下,Filebeat 使用压力敏感协议向 Logstash 或 Elasticsearch 发送数据。如果 Logstash 正在繁忙地处理数据,它会告知 Filebeat 减慢读取速度。拥塞解决后,Filebeat 将恢复初始速度并继续发送数据。
三、问题及解决方案
问题:如何实现日志的多行合并功能?
系统应用中的日志一般都是以特定格式进行打印的,属于同一条日志的数据可能分多行进行打印,那么在使用 ELK 收集日志的时候就需要将属于同一条日志的多行数据进行合并。
解决方案:使用 Filebeat 或 Logstash 中的 multiline 多行合并插件来实现
在使用 multiline 多行合并插件的时候需要注意,不同的 ELK 部署架构可能 multiline 的使用方式也不同,如果是本文的第一种部署架构,那么 multiline 需要在 Logstash 中配置使用,如果是第二种部署架构,那么 multiline 需要在 Filebeat 中配置使用,无需再在 Logstash 中配置 multiline。
1、multiline 在 Filebeat 中的配置方式:
filebeat.prospectors: - paths: -/home/project/elk/logs/test.log input_type:log multiline: pattern:'^[' negate:true match:after output: logstash: hosts:["localhost:5044"]
pattern:正则表达式
negate:默认为 false,表示匹配 pattern 的行合并到上一行;true 表示不匹配 pattern 的行合并到上一行
match:after 表示合并到上一行的末尾,before 表示合并到上一行的行首
如:
pattern:'[' negate:true match:after
该配置表示将不匹配 pattern 模式的行合并到上一行的末尾
2、multiline 在 Logstash 中的配置方式
input{
beats{
port=>5044
}
}
filter{
multiline{
pattern=>"%{LOGLEVEL}s*]"
negate=>true
what=>"previous"
}
}
output{
elasticsearch{
hosts=>"localhost:9200"
}
}
(1)Logstash 中配置的 what 属性值为 previous,相当于 Filebeat 中的 after,Logstash 中配置的 what 属性值为 next,相当于 Filebeat 中的 before。(2)pattern => "%{LOGLEVEL}s*]" 中的 LOGLEVEL 是 Logstash 预制的正则匹配模式,预制的还有好多常用的正则匹配模式,详细请看:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
问题:如何将 Kibana 中显示日志的时间字段替换为日志信息中的时间?
默认情况下,我们在 Kibana 中查看的时间字段与日志信息中的时间不一致,因为默认的时间字段值是日志收集时的当前时间,所以需要将该字段的时间替换为日志信息中的时间。
解决方案:使用 grok 分词插件与 date 时间格式化插件来实现
在 Logstash 的配置文件的过滤器中配置 grok 分词插件与 date 时间格式化插件,如:
input{
beats{
port=>5044
}
}
filter{
multiline{
pattern=>"%{LOGLEVEL}s*][%{YEAR}%{MONTHNUM}%{MONTHDAY}s+%{TIME}]"
negate=>true
what=>"previous"
}
grok{
match=>["message","(?%{YEAR}%{MONTHNUM}%{MONTHDAY}s+%{TIME})"]
}
date{
match=>["customer_time","yyyyMMddHHss,SSS"]//格式化时间
target=>"@timestamp"//替换默认的时间字段
}
}
output{
elasticsearch{
hosts=>"localhost:9200"
}
}
如,要匹配的日志格式为:“[DEBUG][20170811 1031,359][DefaultBeanDefinitionDocumentReader:106] Loading bean definitions”,解析出该日志的时间字段的方式有:
通过引入写好的表达式文件,如表达式文件为 customer_patterns,内容为:CUSTOMER_TIME %{YEAR}%{MONTHNUM}%{MONTHDAY}s+%{TIME} 注:内容格式为:[自定义表达式名称] [正则表达式] 然后 logstash 中就可以这样引用:
filter{
grok{
patterns_dir=>["./customer-patterms/mypatterns"]//引用表达式文件路径
match=>["message","%{CUSTOMER_TIME:customer_time}"]//使用自定义的grok表达式
}
}
以配置项的方式,规则为:(?< 自定义表达式名称> 正则匹配规则),如:
filter{
grok{
match=>["message","(?%{YEAR}%{MONTHNUM}%{MONTHDAY}s+%{TIME})"]
}
}
问题:如何在 Kibana 中通过选择不同的系统日志模块来查看数据
一般在 Kibana 中显示的日志数据混合了来自不同系统模块的数据,那么如何来选择或者过滤只查看指定的系统模块的日志数据?
解决方案:新增标识不同系统模块的字段或根据不同系统模块建 ES 索引
1、新增标识不同系统模块的字段,然后在 Kibana 中可以根据该字段来过滤查询不同模块的数据 这里以第二种部署架构讲解,在 Filebeat 中的配置内容为:
filebeat.prospectors: - paths: -/home/project/elk/logs/account.log input_type:log multiline: pattern:'^[' negate:true match:after fields://新增log_from字段 log_from:account - paths: -/home/project/elk/logs/customer.log input_type:log multiline: pattern:'^[' negate:true match:after fields: log_from:customer output: logstash: hosts:["localhost:5044"]
通过新增:log_from 字段来标识不同的系统模块日志
2、根据不同的系统模块配置对应的 ES 索引,然后在 Kibana 中创建对应的索引模式匹配,即可在页面通过索引模式下拉框选择不同的系统模块数据。这里以第二种部署架构讲解,分为两步:① 在 Filebeat 中的配置内容为:
filebeat.prospectors: - paths: -/home/project/elk/logs/account.log input_type:log multiline: pattern:'^[' negate:true match:after document_type:account - paths: -/home/project/elk/logs/customer.log input_type:log multiline: pattern:'^[' negate:true match:after document_type:customer output: logstash: hosts:["localhost:5044"]
通过 document_type 来标识不同系统模块
② 修改 Logstash 中 output 的配置内容为:
output{
elasticsearch{
hosts=>"localhost:9200"
index=>"%{type}"
}
}
在 output 中增加 index 属性,%{type} 表示按不同的 document_type 值建 ES 索引
四、总结
本文主要介绍了 ELK 实时日志分析的三种部署架构,以及不同架构所能解决的问题,这三种架构中第二种部署方式是时下最流行也是最常用的部署方式,最后介绍了 ELK 作在日志分析中的一些问题与解决方案,说在最后,ELK 不仅仅可以用来作为分布式日志数据集中式查询和管理,还可以用来作为项目应用以及服务器资源监控等场景,更多内容请看官网。
-
存储
+关注
关注
13文章
4298浏览量
85809 -
服务器
+关注
关注
12文章
9129浏览量
85344 -
数据源
+关注
关注
1文章
63浏览量
9676 -
日志
+关注
关注
0文章
138浏览量
10639 -
收集器
+关注
关注
0文章
30浏览量
3134
原文标题:分布式实时日志分析解决方案 ELK 部署架构
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
InDTU300系列产品如何输出实时日志?
使用分布式I/O进行实时部署系统的设计
开放分布式追踪(OpenTracing)入门与 Jaeger 实现
微服务架构下分布式事务解决方案 —— 阿里GTS
一行代码,保障分布式事务一致性—GTS:微服务架构下分布式事务解决方案
Qorvo分布式Wi-Fi网格解决方案
分布式KVM坐席拼控系统解决方案
HDC威廉希尔官方网站 分论坛:分布式调试、调优能力解决方案
HDC2021威廉希尔官方网站 分论坛:分布式调试、调优能力解决方案
基于Windows平台的分布式实时仿真系统

基于DOCKER容器的ELK日志收集系统分析






 工商网监
工商网监
评论