 百万并发场景中倒排索引与位图计算的实践
百万并发场景中倒排索引与位图计算的实践
背景
Promise 时效控单系统作为时效域的控制系统,在用户下单前、下单后等多个节点均提供服务,是用户下单黄金链路上的重要节点;控单系统主要逻辑是针对用户请求从规则库中找出符合条件的最优规则,并将该规则的时效控制结果返回客户端,比如因为临时疫情等原因针对仓、配、商家、客户四级地址等不同维度进行精细粒度的时效控制。 该系统也是 Promise 侧并发量最大的系统,双 11 高峰集群流量 TPS 在百万级别,对系统的性能要求非常高,SLA 要求在 5ms 以内,因此对海量请求在规则库 (几十万) 中如何快速正确匹配规则是该系统的威廉希尔官方网站 挑战点。
朴素的解决方案
按照朴素的思想,在工程建设上,通过异步方式将规则库逐行缓存到 Redis,Key 为规则条件,Value 为规则对应结果;当用户请求过来时,对请求 Request (a,b,c,d..) 中的参数做全组合,根据全组合出的 Key 尝试找出所有可能命中的规则,再从中筛选出最优的规则。如下图所示
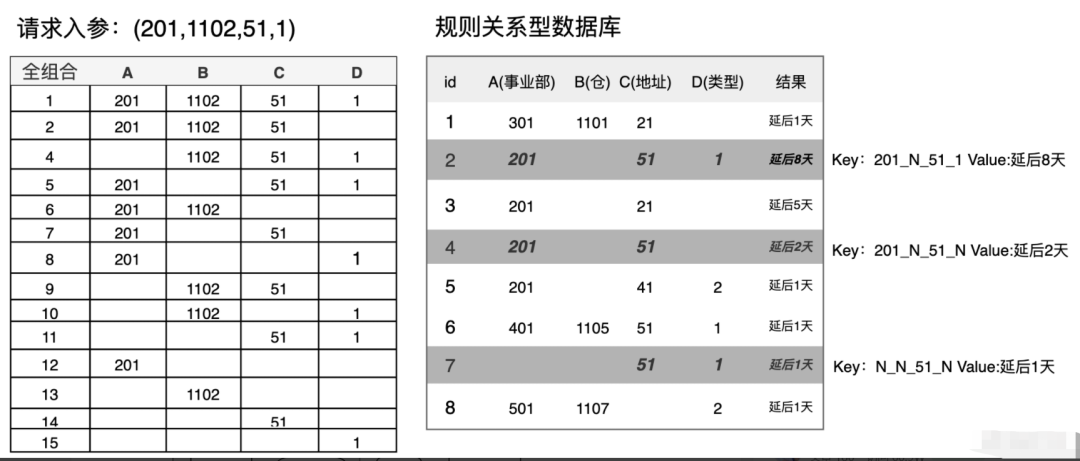
该方案面临的问题是全组合的时间复杂度是 2**n,n≈12;算法的时间复杂度高且算法稳定性差,最差情况一次请求需要 4096 次计算和读取操作。当然在工程上我们可以使用本地缓存做一些优化,但是无法解决最根本的性能问题。架构简图如下所示:
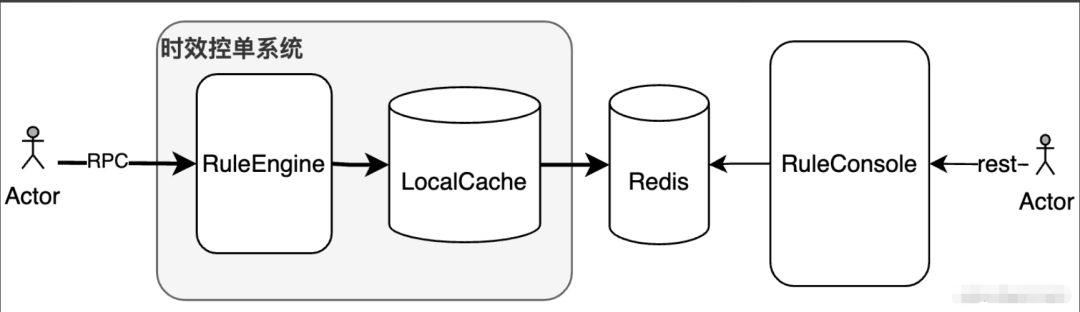
新的解决方案
上面方案是从行的角度看待匹配定位的,能够命中的行的每一列必然也是符合条件的,这里面存在某种隐约的内在联系。能否反过来思考这个问题,为此我们尝试进行新的方案,当然架构简图依然如上图所示,核心优化的是命中算法。 新的方案整体采用列的倒排索引和倒排索引位运算的方式,使得计算复杂度由原来的 2n 降至 n**,且算法稳定性有非常好的保证。其中列的倒排索引是对每列的值和所分布的行 ID (即 Posting List) 建立 KV 关系,倒排索引位运算是对符合条件的列倒排索引进行列间的位运算,即通过联合查询以便快速找到符合条件的规则行。
算法详细设计
1. 预计算生成列的倒排索引和位图
通过对每列的值进行分组合并生成 Posting List,建立列值和 Posting List 的 KV 关系。以下图为例,列 A 可生成的倒排索引为:301={1},201={2,3,4,5} 等,需要说明的一点,空值也是一种候选项,也需要生成 KV 关系,如 nil={7}。
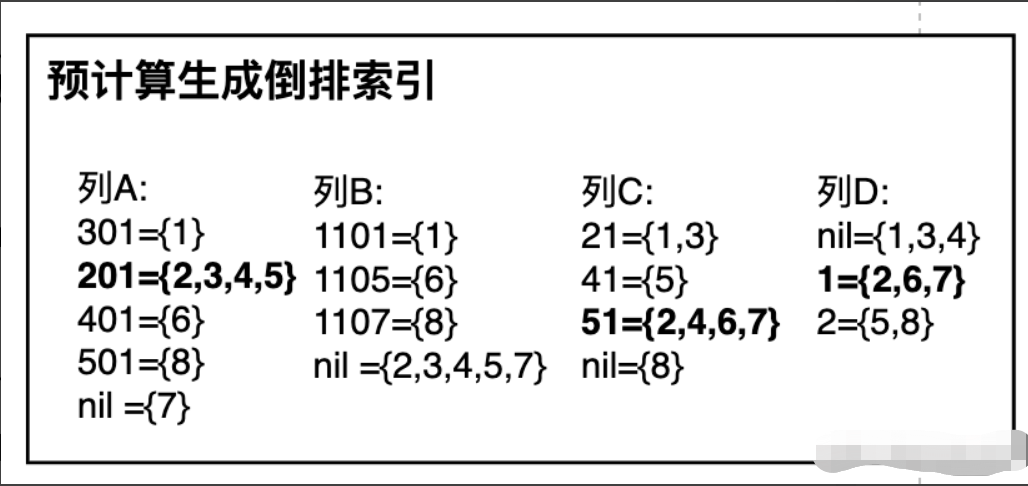
2. 生成列的倒排索引对应位图
将步骤 1 的倒排索引转成成位图,方便后续的位图计算,转换规则为行 ID 对应位图的下标位(步骤 1、2 可以合并操作)。

3. 根据用户请求查找列位图,通过位图计算生成候选规则集
将用户请求中的入参作为 Key,查找符合条件的位图,对每一列进行列内和空值做 || 运算,最后列间位图做 & 运算,得到的结果是候选规则集,如下图所示:
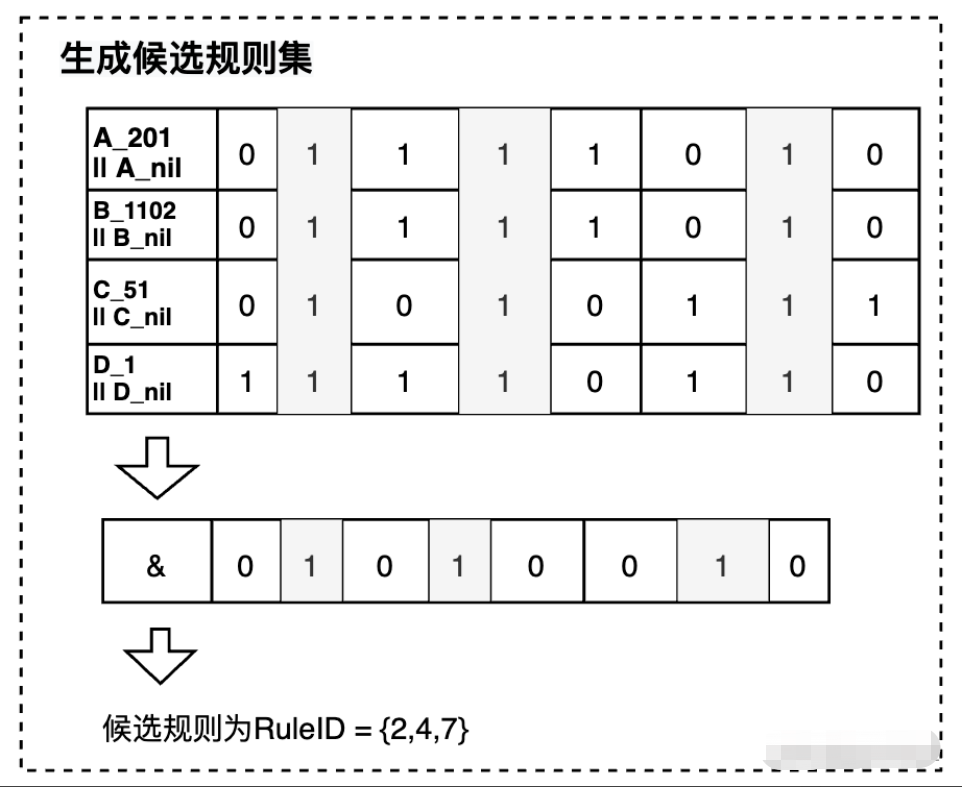
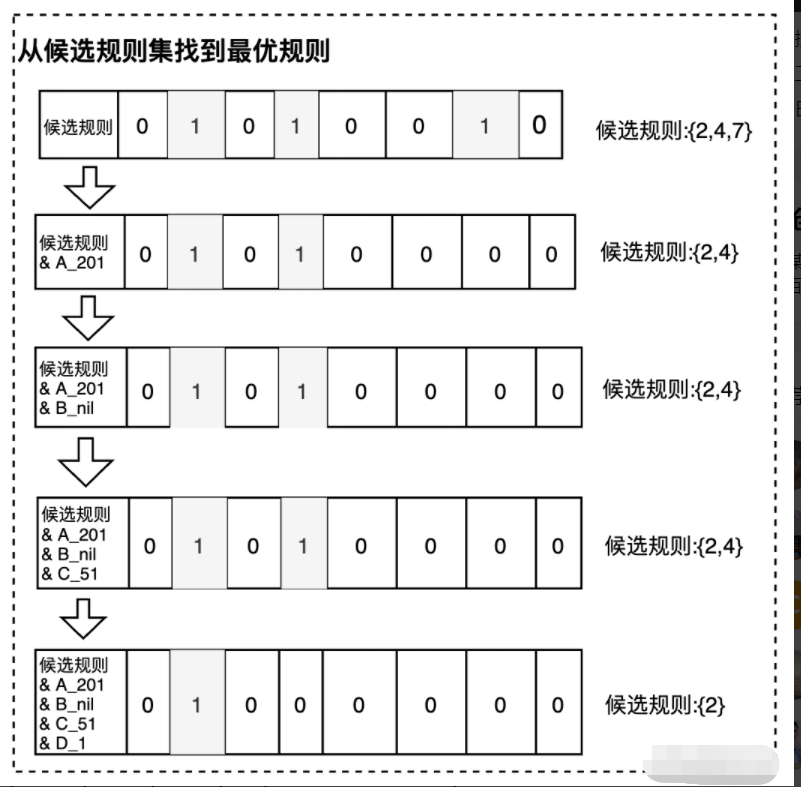
4. 从候选规则库中,根据业务优先级排序,查找最优的规则
以候选规则为基点,按照业务优先级排序,进行逐级位运算 &,当遍历完或位运算为 0 时,找到最后不为空的即为最优规则,该过程是从候选规则库逐渐缩小最优范围的过程。需要说明某列当用户请求位图不存在时,需要使用对应的空位图进行参与,以 B 列为例,入参 B_1102 不存在,需要使用 B_nil 参与 &。
复杂度分析
通过上面的例子我们可以看到,在时间复杂度方面查找候选规则集时,进行一轮 || 运算,一轮 & 运算;在查找最优规则时进行一轮 & 运算,所以整体复杂度是 3n≈n。 在空间复杂度方面,相比原来的行式存储,倒排索引的存储方式,每列都需要存储行 ID,相当于多了 *(n-1)Posting List 存储空间,当然这是粗略计算,因为实际上行 ID 的存储最终转换为位图存储,在空间上有非常大的压缩空间。
工程问题 - 压缩位图
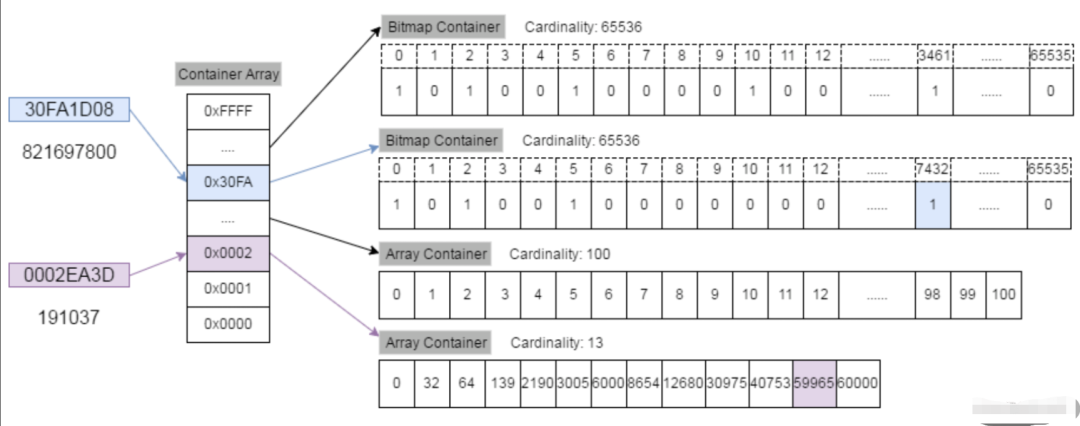
如果倒排索引位图非常稀疏,系统会存在非常大的空间浪费。我们举一个极端 case,若千万规则库中命中的行 ID 是第 1000 万位,按照传统方式 BitSet 进行存储,需要消耗 1.2MB 空间,在内存中占用存在严重浪费,有没有压缩优化方案,在 RoaringBitMap 压缩位图方案中我们找到,相同场景在压缩位图方式下仅占 144bytes;即使在 1000 万的位图空间,我们随机存储 1 万个值,两者比也是在 31K vs 2MB,近 100 倍的差距,总的来说 RoaringBitMap 压缩率非常大。 RoaringBitMap 本质上是将大块的 bitmap 拆分成各个小块,其中每个小块在需要存储数据的时候才会存在,所以当进行交集或并集运算的时候,RoaringBitMap 只需要去计算存在的块而不需要像 bitmap 那样对整个大块进行计算,既做到了压缩的存储又做到计算性能的提升。 以下图 821697800 为例,对应的 16 进制数为 30FA1D08, 其中高 16 位为 30FA,低 16 位为 1D08。先用二分查找从一级索引(即 Container Array)中找到数值为 30FA 的容器,该容器是一个 Bitmap 容器,然后在该容器查找低 16 位的数值 1D08,即十进制下 7432,在 Bitmap 中找到相应的位置,将其置为 1 即可。
适用场景分析
回顾上面的设计方案我们可以看到,这种方式仅适用于 PostingList 简单如行 ID 的形式,如果是复杂对象就不适合用位图来存储。另外仅适用于等值查询,不适用于 like、in 的范围查询,为什么有这种局限性?因为这种方式依赖于搜索条件的空间,在方案中我们将值的条件作为搜索的 Key,值的条件空间希望尽可能是一个有限的、方便穷举的、小的空间。而范围查询导致这个空间变成难以穷举、近乎无限扩张的、所以不适用。
其他优化方式
除了使用位运算的方式对倒排索引加速,考虑到 Posting List 的有序性,还有其他的方式比如使用跳表、Hash 表等方式,以 ES 中采用的跳表为例,进行 & 运算实际就是在查找两个有序 Posting List 公共部分,以相互二分查找的形式,将时间复杂度控制在 log (n) 的级别。 具体参见《工业界如何利用跳表、哈希表、位图进行倒排索引加速?》:https://time.geekbang.org/column/article/221292?utm_source=related_read&utm_medium=article&utm_term=related_read
审核编辑 :李倩
-
索引
+关注
关注
0文章
59浏览量
10468 -
Redis
+关注
关注
0文章
374浏览量
10872 -
位图
+关注
关注
0文章
6浏览量
2275
原文标题:百万并发场景中倒排索引与位图计算的实践
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
边缘计算架构设计最佳实践
云计算平台的最佳实践
本源量子荣获2024金融科技场景应用大赛“探索实践奖”

探索工业计算机的多元应用场景

MATLAB中的矩阵索引
TRIZ在逆变器设计中的实践应用
高并发物联网云平台是什么
ClickHouse内幕(3)基于索引的查询优化





 工商网监
工商网监
评论