 分享一种基于深度图像梯度的线特征提取算法download
分享一种基于深度图像梯度的线特征提取算法download
0. 笔者个人体会
在低纹理区域,传统的基于特征点的SfM/SLAM/三维重建算法很容易失败。因此很多算法会尝试去提取线特征来提高点特征的鲁棒性,典型操作就是LSD。
但在一些带噪声的低光照环境下,LSD很容易失效。而且线特征检测的难点在于,由于遮挡,线端点的精确定位很难获得。
它使用深度学习来处理图像并丢弃不必要的细节,然后使用手工方法来检测线段。
因此,DeepLSD不仅对光照和噪声具有更强鲁棒性,同时保留了经典方法的准确性。整篇文章的推导和实验非常详实,重要的是算法已经开源!
2. 摘要
线段在我们的人造世界中无处不在,并且越来越多地用于视觉任务中。由于它们提供的空间范围和结构信息,它们是特征点的补充。
基于图像梯度的传统线检测器非常快速和准确,但是在噪声图像和挑战性条件下缺乏鲁棒性。他们有经验的同行更具可重复性,可以处理具有挑战性的图像,但代价是精确度较低,偏向线框线。
我们建议将传统方法和学习方法结合起来,以获得两个世界的最佳效果:一个准确而鲁棒的线检测器,可以在没有真值线的情况下在野外训练。
我们的新型线段检测器DeepLSD使用深度网络处理图像,以生成线吸引力场,然后将其转换为替代图像梯度幅度和角度,再馈入任何现有的手工线检测器。
此外,我们提出了一个新的优化工具,以完善基于吸引力场和消失点的线段。
这种改进大大提高了当前深度探测器的精度。我们展示了我们的方法在低级线检测度量上的性能,以及在使用多挑战数据集的几个下游任务上的性能。
3. 算法解读
作者将深度网络的鲁棒性与手工制作的线特征检测器的准确性结合起来。具体来说,有如下四步:
(1) 通过引导LSD生成真实线距离和角度场(DF/AF)。
(2) 训练深度网络以预测线吸引场DF/AF,然后将其转换为替代图像梯度。
(3) 利用手工LSD提取线段。
(4) 基于吸引场DF/AF进行细化。
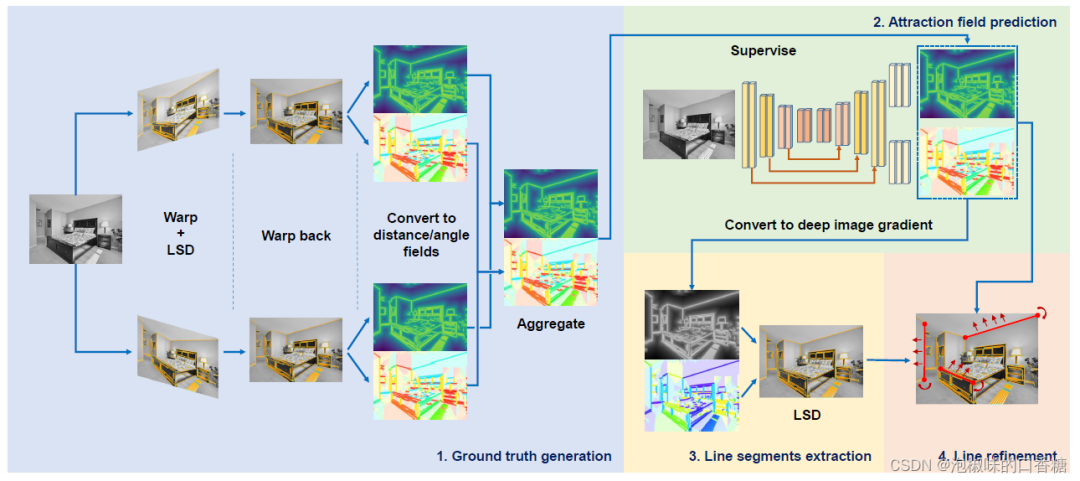
图1 方法概述
作者所做主要贡献如下:
(1) 提出了一种自举当前检测器的方法来在任意图像上创建真实线吸引场。
(2) 引入了一个优化过程,可以同时优化线段和消失点。这种优化可以作为一种独立的细化来提高任何现有的深度线检测器的精度。
(3) 在多个需要线特征的下游任务中,通过结合深度学习方法的鲁棒性和手工方法在单个pipeline中的精度,创造了新的记录。
3.1 线吸引场
最早通过吸引场表示线段的方法是AFM,为图像的每个像素回归一个2D向量场,来表示直线上最近点的相对位置。
该方法允许将离散量(线段)表示为适合深度学习的平滑2通道图像。然而,这种表示方法并不是获得精确线段的最佳方法。
如图2所示,比如HAWP那样直接预测端点的位置需要很大的感受野,以便能够从遥远的端点获取信息。
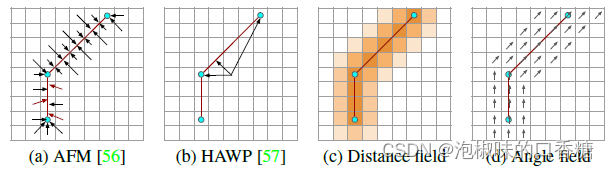
图2 吸引场参数化。(a)对二维向量进行参数化可能会对小向量模产生噪声角。(b) 向端点添加偏移量需要长程信息且对噪声端点不具有鲁棒性。作者提出将距离场(c)和线角度场(d)解耦。
而DeepLSD这项工作的巧妙之处在于,作者提出将网络限制在一个较小的感受野,并使用传统的启发式方法来确定端点。
DeepLSD采用和HAWP类似的吸引场,但没有额外的两个指向端点的角度,只保留线距离场(DF)和线角度场(AF)。其中线距离场DF给出当前像素到直线上最近点的距离,线角度场AF返回最近直线的方向:
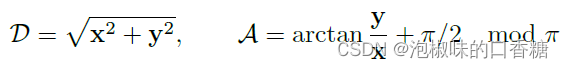
3.2 真值生成
为了学习线吸引场,需要ground truth。AFM和HAWP都是使用线框数据集的真值来监督。但DeepLSD的作者探索了一种新的方法,即通过引导先前的线检测器来获取真值。
具体来说,就是通过单应性自适应生成真值吸引场。给定单幅输入图像I,将其与N个随机单应矩阵Hi进行wrap,在所有wrap后的图像Ii中使用LSD检测直线段,然后将其wrap回到I来得到线集合Li。
下一步是将所有的线聚合在一起,这一部分是个难点。作者的做法是将线条集合Li转换为距离场Di和角度场Ai,并通过取所有图像中每个像素(u, v)的中值来聚合:
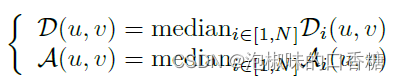
通过取中值,可以去除仅在少数图像中检测到的噪声,结果如图3所示。

图3 伪GT可视化
3.3 学习线吸引场
为了回归距离场和角度场,DeepLSD使用了UNet架构,尺寸为HxW的输入图像经多个卷积层处理,并通过连续3次平均池化操作逐步降采样至8倍。
然后通过另一系列卷积层和双线性插值将特征放大回原始分辨率。得到的深度特征被分成两个分支,一个输出距离场,一个输出角度场。最后距离场通过反归一化得到:
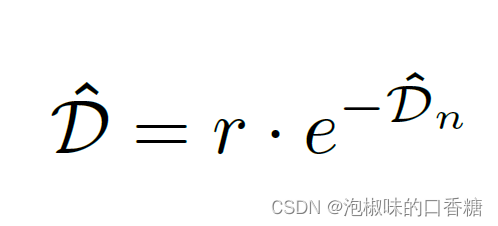
其中r是像素中的一个参数,它定义了每条线周围的区域。由于手工方法主要需要线段附近的梯度信息,因此DeepLSD只对距离线段小于r个像素的像素进行监督。
总损失为距离场和角度场的损失之和:
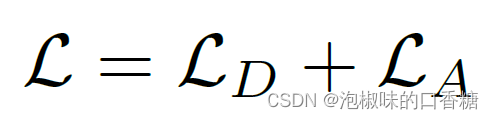
这里就没啥可说的了,LD为归一化距离场之间的L1损失,LA为L2角度损失:
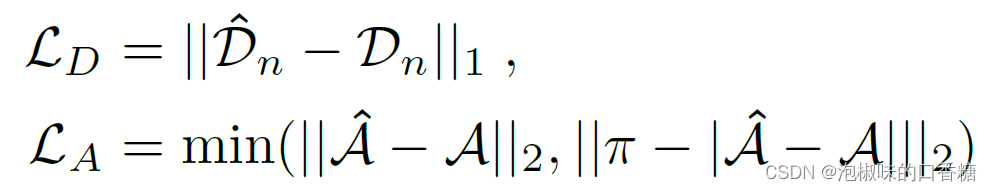
3.4.提取线段
由于LSD是基于图像梯度的,因此需要将距离场和角度场转换为替代图像梯度幅度和角度:
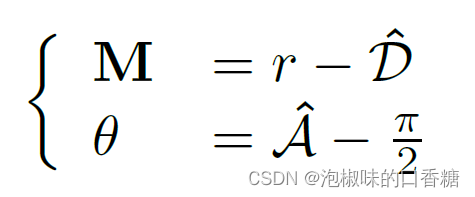
AFM和LSD方法的一个重要区别是梯度方向。对于黑暗与明亮区域分离的边缘,LSD跟踪从暗到亮的梯度方向,而AFM不跟踪。
如图4所示,当几条平行线以暗-亮-暗或亮-暗-亮的模式相邻出现时,这就变得很重要。
为了更好的精度和尺度不变性,DeepLSD检测这些双边缘,并构造角度方向:
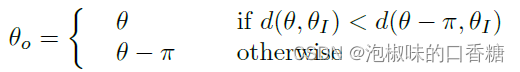
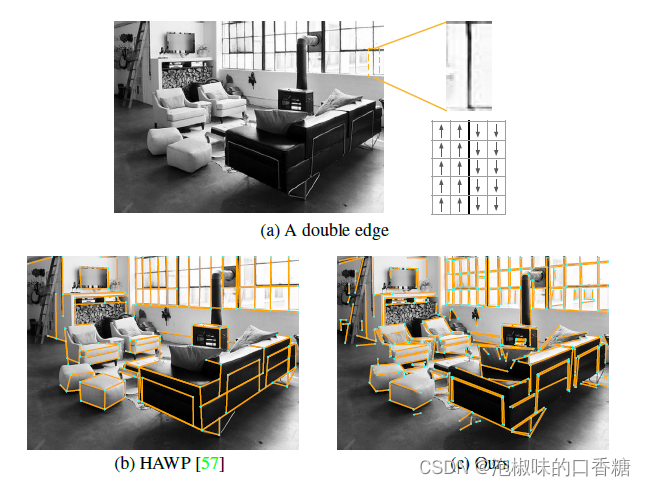
图4 区分双边缘。(a) 亮-暗-亮边缘和定向角度场的示例。(b) HAWP将其视为一条直线。(c) 为了准确,DeepLSD将其检测为两条线。
为了使线特征更加精确,作者还提出了一个优化步骤,即利用第二步预测的DF和AF来细化。需要注意的是,这种优化方法也可以用来增强任何其他深度探测器的线特征。
优化的核心思路是,在3D中平行的线将共享消失点。因此DeepLSD将其作为软约束融入到优化中,有效地降低了自由度。
首先利用多模型拟合算法Progressive-X计算一组与预测线段相关的消失点(VPs)。然后对每条线段独立进行优化,损失函数是三种不同成本的加权无约束最小二乘最小化:
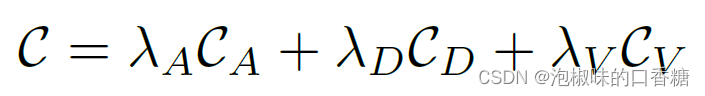
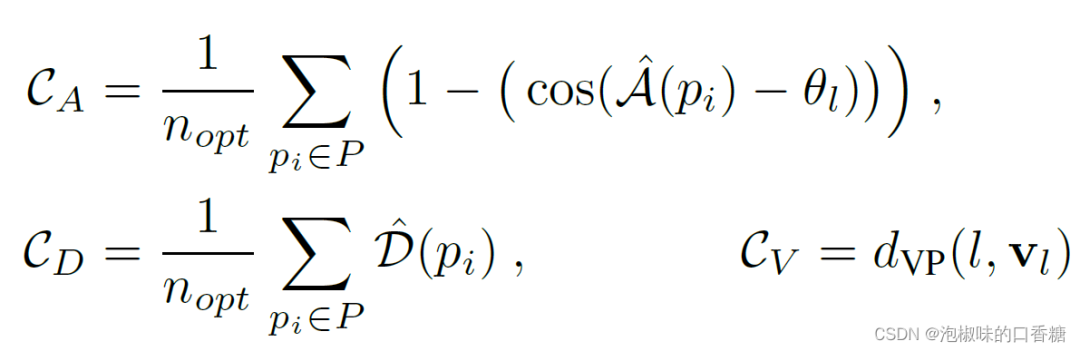
4. 实验
作者训练了DeepLSD的两个版本,一个在室内Wireframe数据集,没有使用GT线,一个室外MegaDepth数据集。
MegaDepth数据集保留150个场景用于训练,17个场景用于验证,每个场景只采集50张图像。
在实验细节上,使用Adam优化器和初始学习率为1e3,学习率调整策略为,当损失函数到达一定数值时学习率/10。
硬件条件为,在NVIDIA RTX 2080 GPU上训练时间12小时。
4.1 直线检测性能
作者首先在HPatches数据集和RDNIM数据集上评估直线检测性能,其中HPatches数据集具有不同的光照和视点变化,RDNIM数据集具有挑战性的昼夜变化相关的图像对。
评价指标为重复性、定位误差以及单应估计分数。重复性(Rep)衡量匹配误差在3个像素以下的直线的比例,定位误差(LE)返回50个最准确匹配的平均距离。表1和图5所示是与经典线特征检测器的对比结果。
表1 在HPatches和RDNIM数据集上的直线检测评估
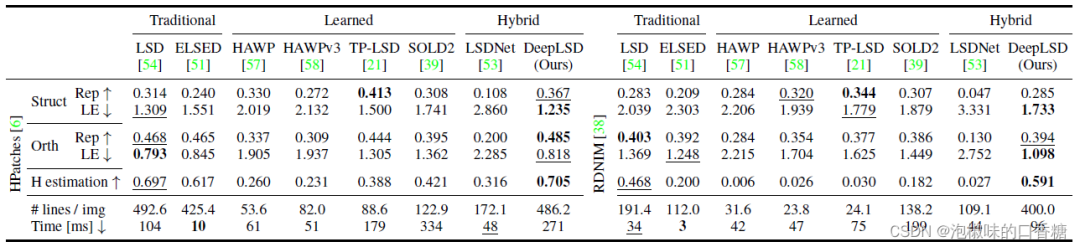

图5 线段检测示例
从结果来看,以TPLSD为首的学习方法具有较好的可重复性,但存在较低的定位误差和不准确的单应矩阵估计。
手工方法和DeepLSD由于不直接对端点进行回归,而是利用非常低的细节逐步增长线段,因此精度更高。
当变化最具挑战性时,DeepLSD比LSD表现出最好的改善,即在昼夜变化强烈的RDNIM上。
可以显著提高定位误差和单应性估计分数。LSDNet由于通过将图像缩放到固定的低分辨率而失去了准确性。
总体而言,DeepLSD在手工方法和学习方法之间提供了最佳的权衡,并且在单应性估计的下游任务中始终排名第一。
4.2 重建及定位
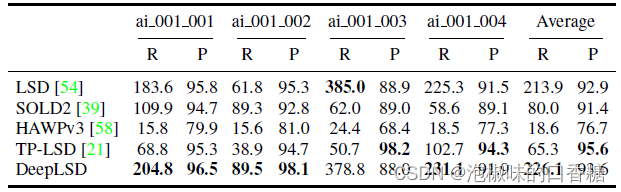
这项工作除了评估自身的线特征生成质量外,还进行了三维重建对比。作者利用Line3D++获取一组已知姿态的图像和相关的2D线段,并输出线条的三维重建。
作者在Hypersim数据集的前4个场景上将DeepLSD与几个基线进行比较。其中召回R为距离网格5 mm以内的所有线段的长度,单位为米,越高意味着许多线条被重建。精度P是距离网格5毫米以内的预测线的百分比,越高表明大部分预测的直线在真实的三维表面上。
结果如表2所示,DeepLSD总体上获得了最好的召回和精度。TP-LSD虽然在召回上排名第一,但是能够恢复的直线很少,其平均精度比DeepLSD小71 %。
值得注意的是,DeepLSD比LSD能够重建更多的直线,且精度更高。
表2 线三维重建对比结果
作者在7Scenes数据集上进行了定位实验,估计位姿精度,其中Stairs场景对于特征点的定位非常具有挑战性。
图6表明,DeepLSD在这个具有挑战性的数据集上获得了最好的性能。
与仅使用点相比,可以突出线特征带来的性能的大幅提升。在室内环境中,线特征提取并定位的性能良好,即使在低纹理场景中也可以匹配。
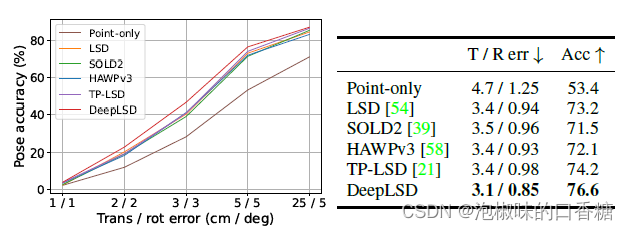
图6 7Scenes数据集楼梯的视觉定位结果
4.3 线优化的影响
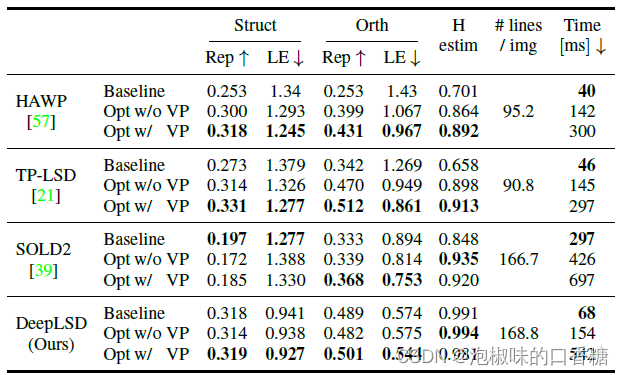
作者还研究了优化步骤的影响。对于每种方法,作者将原始线条与优化后的线条和VP进行比较。
表3展示了线检测器在Wireframe测试集的462张图像上的检测结果。结果显示,优化可以显著改善不精确方法的定位误差和单应性得分,并显著提高评价直线精度的所有指标。
特别是对于HAWP和TP-LSD,两者的定位误差都下降了32 %,单应性得分提高了27 %和39 %。
注意,优化并没有给DeepLSD带来多大提升,这是因为它的原始预测线已经是亚像素精确的,并且优化受到DF和AF分辨率的限制。
表3 Wireframe数据集上的线优化
4.4 消融研究
作者在HPatches数据集上用低级别检测器指标验证了设计选择,将DeepLSD与单边相同模型进行比较。表4展示了各组成部分的重要性。
值得注意的是,在DeepLSD上重新训练HAWP会导致较差的结果,因为与线框线相比,线条的数量更多,而且一般的直线往往有噪声的端点,因此预测到两个端点的角度也是有噪声的。
表4 HPatches数据集上的消融实验
5. 结论
作者提出了一种混合线段检测器,结合了深度学习的鲁棒性和手工检测器的准确性,并使用学习的替代图像梯度作为中间表示。还提出了一种可以应用于现有深度检测器的优化方法,弥补了深度检测器和手工检测器之间的线局部化的差距。
审核编辑:刘清
-
检测器
+关注
关注
1文章
863浏览量
47685 -
SLAM
+关注
关注
23文章
423浏览量
31827 -
AFM
+关注
关注
0文章
59浏览量
20173
原文标题:DeepLSD:基于深度图像梯度的线段检测和细化
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度识别人脸识别在任务中为什么有很强大的建模能力
图像识别威廉希尔官方网站 的原理是什么
卷积神经网络通常包括哪几层
深度学习与nlp的区别在哪
如何设计人脸识别的神经网络
卷积神经网络的基本结构及其功能
基于深度学习的鸟类声音识别系统
基于FPGA的实时边缘检测系统设计,Sobel图像边缘检测,FPGA图像处理
咳嗽检测深度神经网络算法
赛默斐视表面瑕疵检测系统是一种利用机器视觉威廉希尔官方网站
OpenCV4图像分析之BLOB特征分析





 工商网监
工商网监
评论