 车道线检测Ultra Fast Deep Lane Detection V2讲解
车道线检测Ultra Fast Deep Lane Detection V2讲解
Ultra Fast Deep Lane Detection V2
【GiantPandaCV 导语】Ultra Fast Deep Lane Detection 是个比较有特点的车道线检测模型,把检测转化成分类来实现。现在出了 V2,有了几个创新点,于是又来研究一下。之前参考 Ultra Fast Deep Lane Detection V1 设计了一个全新的车道线检测网络,把模型压缩了80%,并部署使用了。另外还把 v1 和 yolov4 合并实现了多任务:https://github.com/Huangdebo/YOLOv4-MultiTask
1 介绍
这篇文章提出了一个超快车道线检测,区别于之前基于分割和回归的模型,该模型把车道线检测看车是分类问题,而且使用了全连接层,加强了模型的全局感知能力。另外,本文还设计了一个混合锚点机制,对不同的车道使用不用的锚点,很好地解决了两侧车道检测性能不佳的问题。该模型在兼顾了速度的前提下,还很好地处理了遮挡和暗光等情况,取得了不错的性能。

2 模型设计
2.1 使用锚点来表示车道线
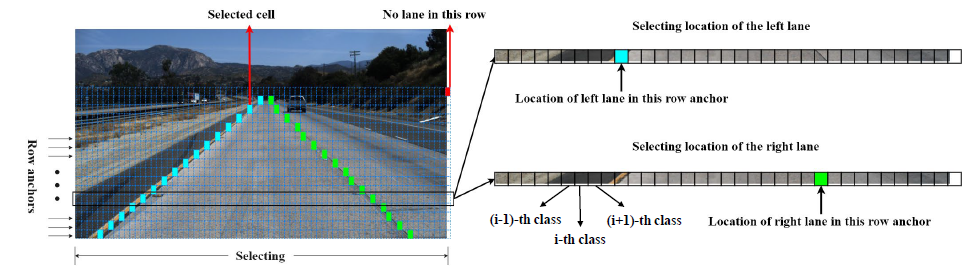
为了表示车道线,首先引入了横向锚点,把车道线看车横向锚点的一组关键点。但当两侧的车道线的水平角度比较小时,便会引起定位问题,也就是一定宽度的车道线会覆盖到多个关键点,导致定位错乱,而且角度越小,问题越严重:
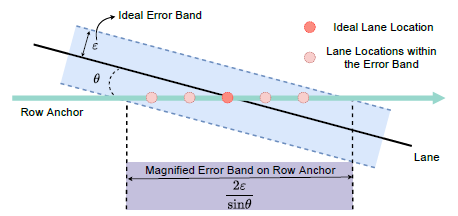
为了解决上述的定位错误问题,文章便提出一种混合锚点机制,中间水平角度大的车道线使用横向锚点来表达,两侧水平角度小的车道线用纵向锚点来表达。每条车道线都用一组归一化坐标来表示
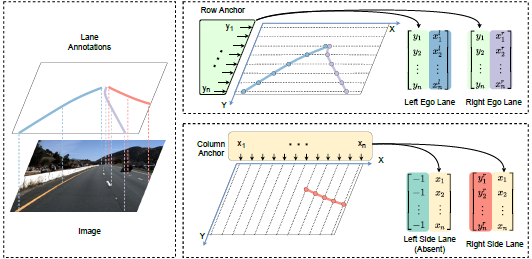
2.2 基于锚点的网络设计
因为每条车道线都用一组归一化坐标来表示,而且是把车道线检测看成分类任务,于是可以通过类别数目来映射出每个车道线关键点的类别:
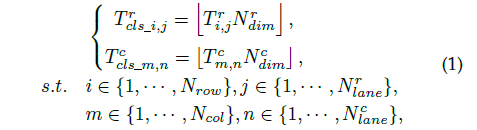
另外,网络还添加了一个分支,用来判别车道线在该处是否存在。该分支的目标就只有两个值:1和0,分别代表存在和不存在:
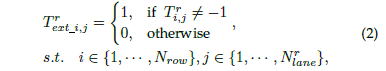
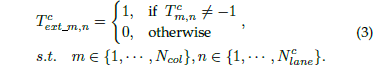
2.3 序列分类的损失函数
既然是分类任务,那自然就会想到使用基本的分类损失函数,相当于把关键点的不同位置看成不同的类别,直接用 CE loss 来表达:
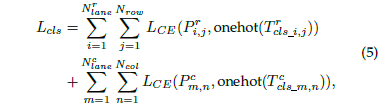
于基本的分类不一样的是,这个位置的类别是有序的,也就是可以把这个位置的预测值看成是各个位置的投票 均值,越靠近 groundtruth 的地方投票值越大,可以缓解预测偏移的问题:
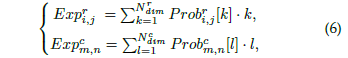
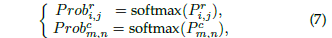 于是,可以这个期望损失可以表达成:
于是,可以这个期望损失可以表达成:
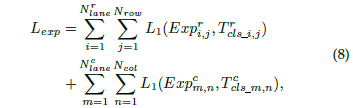
另外,对于网络另一个用以判别车道线是否存在的分支,就是一个二分类问题,其损失函数可以表达成:
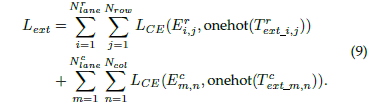
所以整个模型的损失函数便可以组成: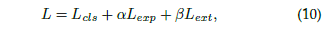
3 消融实验
3.1 混合锚点机制的作用
混合锚点机制中包含了横向锚点策略和纵向锚点策略,针对不同的车道线,使用不同的策略。为了对比混合锚点机制的作用,作者分别单独使用横向锚点策略和纵向锚点策略以及混合锚点来进行对比:
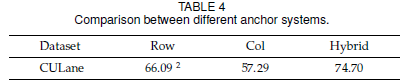
3.2 序列分类的作用
相比于基本的分类任务,文章中所用的序列分类还利用了车道线关键点位置的有序性。为了对比序列分类的作用,作者还使用了传统分类和回归的方式来比对。对于回归方式,则是把网络的分类头换成回归头,并用 smooth L1 los 来训练。实验表明,利用了关键点有序性的序列分类的性能明显优于一般的分类和回归方式:
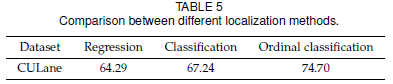
3.3 序列分类损失的消融
序列分类的损失函数包含了两部分,一个是基本的分类损失和一个期望损失。作者也进行了消融实验来对比它们的作用:
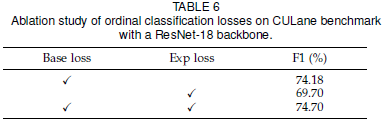
3.4 类别的个数和锚点数量的影响
因为是把车道线的位置检测看成是关键点位置的分类,那久必须要设定一个类别数目,作者通过调整类别数目来做对比实验,发现随着类别数目的增加,模型的性能显示提升然后再下降,说明类别数目并不是越多越好。同样,锚点的数量也需要预先设定,原则上讲,锚点数量越多,对车道线的检测就越精细,但也意味着计算量也更大,所以必须要在模型速度和性能上做一个权衡。
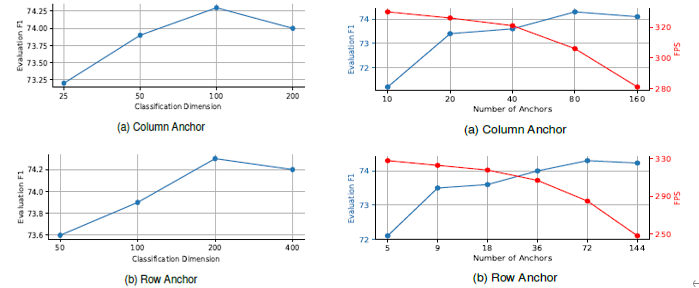
4 结论
使用了混合锚点机制和序列分类损失,缓解了 V1 中两侧车道线检测性能不足的问题,而且还能保持一样的高效率。但锚点的数目和序列分类的数目丢等参数都需要手动设定,可能存在一定的数据相关性。而且网络最后一层使用的是全连接层来提升网络的感知能力,导致参数比较大,对工程部署不太友好,这些都是可优化的点。
审核编辑 :李倩
-
检测
+关注
关注
5文章
4484浏览量
91445 -
模型
+关注
关注
1文章
3229浏览量
48813 -
机制
+关注
关注
0文章
24浏览量
9782
原文标题:车道线检测 Ultra Fast Deep Lane Detection V2 讲解
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【实战】Python+OpenCV车道线检测识别项目:实现L2级别自动驾驶必备(配套课程+平台实践)

浅析SDIO协议V2和V3版本的区别
如何通过SDK功能获取esptouch v2 apk的自定义数据?
SC171开发套件V2 威廉希尔官方网站 资料

深度解读RoCE v2的核心威廉希尔官方网站 原理
CMSIS-RTOS V1与V2的区别是什么?
硬件平台介绍及使用(SC171开发套件V2)
使用ST-link V2的过程中电脑插入读卡器设备后无法正常识别ST-link V2的原因?
荣耀Magic V2 RSR保时捷设计亮相MWC 2024巴塞罗那全球发布会
大模型系列:Flash Attention V2整体运作流程







 工商网监
工商网监
评论