 NVIDIA Triton 系列文章(8):用户端其他特性
NVIDIA Triton 系列文章(8):用户端其他特性
前面文章用 Triton 开源项目提供的 image_client.py 用户端作示范,在这个范例代码里调用大部分 Triton 用户端函数,并使用多种参数来配置执行的功能,本文内容就是简单剖析 image_client.py 的代码,为读者提供撰写 Triton 用户端的流程。
指定通信协议
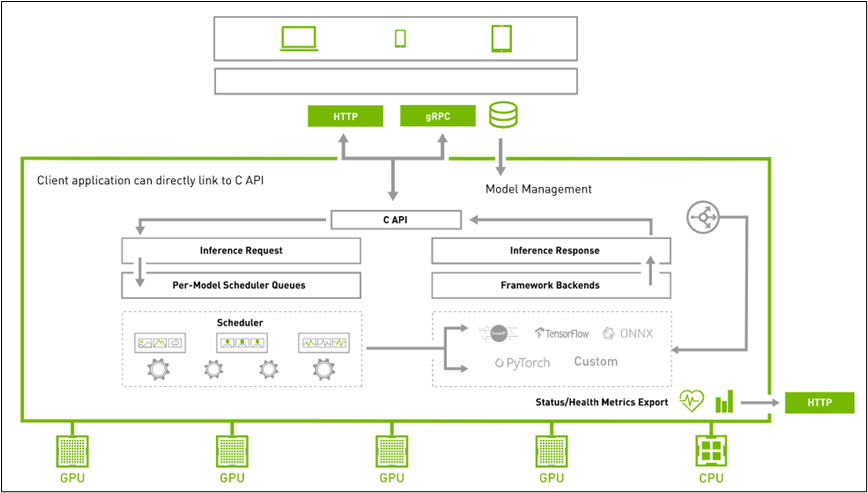
为了满足大部分网路环境的用户端请求,Triton 在服务器与用户端之间提供 HTTP 与 gRPC 两种通信协议,如下架构图所示:
当我们启动 Triton 服务器之后,最后状态会停留在如下截屏的地方:

显示的信息表示,系统提供 8001 端口给 gRPC 协议使用、提供 8000 端口给 HTTP 协议使用。此时服务器处于接收用户端请求的状态,因此“指定通信协议”是执行 Triton 用户端的第一个工作。
这个范例支持两种通信协议,一开始先导入tritonclient.http与tritonclient.grpc两个模块,如下:
import tritonclient.grpc as grpcclient
import tritonclient.http as httpclient代码使用“-i”或“--protocal”其中一种参数指定“HTTP”或“gRPC”协议类型,如果不指定就使用“HTTP”预设值。再根据协议种类调用 httpcclient.InferenceServerClient() 或 grpcclient.InferenceServerClient() 函数创建 triton_client 对象,如下所示:
try:
if FLAGS.protocol.lower() == "grpc":
# Create gRPC client for communicating with the server
triton_client = grpcclient.InferenceServerClient(
url=FLAGS.url, verbose=FLAGS.verbose)
else:
# Specify large enough concurrency to handle the
# the number of requests.
concurrency = 20 if FLAGS.async_set else 1
triton_client = httpclient.InferenceServerClient(
url=FLAGS.url, verbose=FLAGS.verbose, concurrency=concurrency)最后启用 triton_client.infer() 函数对 Triton 服务器发出推理要求,当然得将所需要的参数提供给这个函数,如下所示:
responses.append(
triton_client.infer(FLAGS.model_name,
inputs,
request_id=str(sent_count),
model_version=FLAGS.model_version,
outputs=outputs))不过 image_client.py 代码中并未设定 gRPC 所需要的 8001 端口,因此使用这个通讯协议时,需要用“-u”参数设定“IP:端口”,例如下面指令:
$ python3 image_client.py -m inception_graphdef -s INCEPTION VGG ${HOME}/images/mug.jpg -i GRPC -u <服务器IP>:8001在 examples 范例目录下还有20 个基于 gRPC 协议的范例以及 10 个基于 HTTP 协议的范例,则是在代码内直接指定个别通信协议与端口号的范例,读者可以根据需求去修改特定的范例代码。
调用异步模式(async mode)与数据流(streaming)
大部分读者比较熟悉的并行计算模式,就是在同一个时钟脉冲(clock puls)让不同计算核执行相同的工作,也就是所谓的 SIMD(单指令多数据)并行计算,通常适用于数据量大而且持续的密集型计算任务。
对 Triton 推理服务器而言,并不能确认所收到的推理要求是否为密集型的计算。事实上很大比例的推理要求是属于零碎型计算,这种状况下调用“异步模式”会让系统更加有效率,因为它允许不同计算核(线程)在同一个时钟脉冲段里执行不同指令,这样能大大提高执行弹性进而优化计算性能。
当 Triton 服务器端启动之后,就能接收来自用户端的“异步模式”请求,不过在 HTTP 协议与 gRPC 协议的处理方式不太一样。
在代码中用 httpclient.InferenceServerClient() 函数创建 HTTP 的 triton_client 对象时,需要给定“concurrnecy(并发数量)”参数,而创建 gRPC 的用户端时就不需要这个参数。
调用异步模式有时会需要搭配数据流(stream)的处理器(handle),因此在实际推理的函数就有 triton_client.async_infer() 与 triton_client.async_stream_infer() 两种,使用 gRPC 协议创建的 triton_client,在调用无 stream 模式的 async_infer() 函数进行推理时,需要提供 partial(completion_callback, user_data) 参数。
由于异步处理与数据流处理有比较多底层线程管理的细节,初学者只需要范例目录下的代码,包括 image_client.py 与两个 simple_xxxx_async_infer_client.py 的代码就可以,细节部分还是等未来更熟悉系统之后再进行深入。
使用共享内存(share memory)
如果发起推理请求的 Triton 用户端与 Triton 服务器在同一台机器时,就可以使用共享内存的功能,这包含一般系统内存与 CUDA 显存两种,这项功能可以非常高效地降低数据传输的开销,对提升推理性能有明显的效果。
在 image_client.py 范例中并未提供这项功能,在 Python 范例下有 6 个带有“shm”文件名的代码,就是支持共享内存调用的范例,其中 simple_http_shm_client.py 与 simple_grpc_shm_client.py 为不同通信协议提供了使用共享系统内存的代码,下面以 simple_grpc_shm_client.py 内容为例,简单说明一下主要执行步骤:
# 1.为两个输入张量创建数据:第1个初始化为一整数、第2个初始化为所有整数
input0_data = np.arange(start=0, stop=16, dtype=np.int32)
input1_data = np.ones(shape=16, dtype=np.int32)
input_byte_size = input0_data.size * input0_data.itemsize
output_byte_size = input_byte_size
# 2. 为输出创建共享内存区域,并存储共享内存管理器
shm_op_handle = shm.create_shared_memory_region("output_data",
"/output_simple",
output_byte_size * 2)
# 3.使用Triton Server注册输出的共享内存区域
triton_client.register_system_shared_memory("output_data", "/output_simple",
output_byte_size * 2)
# 4. 将输入数据值放入共享内存
shm_ip_handle = shm.create_shared_memory_region("input_data",
"/input_simple",
input_byte_size * 2)
# 5. 将输入数据值放入共享内存
shm.set_shared_memory_region(shm_ip_handle, [input0_data])
shm.set_shared_memory_region(shm_ip_handle, [input1_data],
offset=input_byte_size)
# 6. 使用Triton Server注册输入的共享内存区域
triton_client.register_system_shared_memory("input_data", "/input_simple",
input_byte_size * 2)
# 7. 设置参数以使用共享内存中的数据
inputs = []
inputs.append(grpcclient.InferInput('INPUT0', [1, 16], "INT32"))
inputs[-1].set_shared_memory("input_data", input_byte_size)
inputs.append(grpcclient.InferInput('INPUT1', [1, 16], "INT32"))
inputs[-1].set_shared_memory("input_data",
input_byte_size,
offset=input_byte_size)
outputs = []
outputs.append(grpcclient.InferRequestedOutput('OUTPUT0'))
outputs[-1].set_shared_memory("output_data", output_byte_size)
outputs.append(grpcclient.InferRequestedOutput('OUTPUT1'))
outputs[-1].set_shared_memory("output_data",
output_byte_size,
offset=output_byte_size)
results = triton_client.infer(model_name=model_name,
inputs=inputs,
outputs=outputs)
# 8. 从共享内存读取结果
output0=results.get_output("OUTPUT0")至于范例中有两个 simple_xxxx_cudashm_client.py 这是针对 CUDA 显存共享的返利代码,主要逻辑与上面的代码相似,主要将上面“shm.”开头的函数改成“cudashm.”开头的函数,当然处理流程也更加复杂一些,需要有足够 CUDA 编程基础才有能力驾驭,因此初学者只要大致了解流程就行。
以上就是 Triton 用户端会用到的基本功能,不过缺乏足够的说明文件,因此其他功能函数的内容必须自行在开源文件内寻找,像 C++ 版本的功能得在 src/c++/library 目录下的 common.h、grpc_client.h 与 http_client.h 里找到细节,Python 版本的函数分别在 src/python/library/triton_client 下的 grpc、http、utils 下的 __init__.py 代码内,获取功能与函数定义的细节。
推荐阅读
NVIDIA Jetson Nano 2GB 系列文章(1):开箱介绍

NVIDIA Jetson Nano 2GB 系列文章(2):安装系统
NVIDIA Jetson Nano 2GB 系列文章(3):网络设置及添加 SWAPFile 虚拟内存
NVIDIA Jetson Nano 2GB 系列文章(4):体验并行计算性能
NVIDIA Jetson Nano 2GB 系列文章(5):体验视觉功能库
NVIDIA Jetson Nano 2GB 系列文章(6):安装与调用摄像头
NVIDIA Jetson Nano 2GB 系列文章(8):执行常见机器视觉应用
NVIDIA Jetson Nano 2GB 系列文章(9):调节 CSI 图像质量
NVIDIA Jetson Nano 2GB 系列文章(10):颜色空间动态调节技巧
NVIDIA Jetson Nano 2GB 系列文章(11):你应该了解的 OpenCV
NVIDIA Jetson Nano 2GB 系列文章(12):人脸定位
NVIDIA Jetson Nano 2GB 系列文章(13):身份识别
NVIDIA Jetson Nano 2GB 系列文章(14):Hello AI World
NVIDIA Jetson Nano 2GB 系列文章(15):Hello AI World 环境安装
NVIDIA Jetson Nano 2GB 系列文章(16):10行代码威力
NVIDIA Jetson Nano 2GB 系列文章(17):更换模型得到不同效果
NVIDIA Jetson Nano 2GB 系列文章(18):Utils 的 videoSource 工具
NVIDIA Jetson Nano 2GB 系列文章(19):Utils 的 videoOutput 工具
NVIDIA Jetson Nano 2GB 系列文章(20):“Hello AI World” 扩充参数解析功能
NVIDIA Jetson Nano 2GB 系列文章(21):身份识别

NVIDIA Jetson Nano 2GB 系列文章(22):“Hello AI World” 图像分类代码
NVIDIA Jetson Nano 2GB 系列文章(23):“Hello AI World 的物件识别应用
NVIDIAJetson Nano 2GB 系列文章(24): “Hello AI World” 的物件识别应用
NVIDIAJetson Nano 2GB 系列文章(25): “Hello AI World” 图像分类的模型训练
NVIDIAJetson Nano 2GB 系列文章(26): “Hello AI World” 物件检测的模型训练
NVIDIAJetson Nano 2GB 系列文章(27): DeepStream 简介与启用
NVIDIAJetson Nano 2GB 系列文章(28): DeepStream 初体验
NVIDIAJetson Nano 2GB 系列文章(29): DeepStream 目标追踪功能
NVIDIAJetson Nano 2GB 系列文章(30): DeepStream 摄像头“实时性能”
NVIDIAJetson Nano 2GB 系列文章(31): DeepStream 多模型组合检测-1
NVIDIAJetson Nano 2GB 系列文章(32): 架构说明与deepstream-test范例
NVIDIAJetsonNano 2GB 系列文章(33): DeepStream 车牌识别与私密信息遮盖
NVIDIA Jetson Nano 2GB 系列文章(34): DeepStream 安装Python开发环境
NVIDIAJetson Nano 2GB 系列文章(35): Python版test1实战说明
NVIDIAJetson Nano 2GB 系列文章(36): 加入USB输入与RTSP输出
NVIDIAJetson Nano 2GB 系列文章(37): 多网路模型合成功能
NVIDIAJetson Nano 2GB 系列文章(38): nvdsanalytics视频分析插件
NVIDIAJetson Nano 2GB 系列文章(39): 结合IoT信息传输
NVIDIAJetson Nano 2GB 系列文章(40): Jetbot系统介绍
NVIDIAJetson Nano 2GB 系列文章(41): 软件环境安装
NVIDIAJetson Nano 2GB 系列文章(42): 无线WIFI的安装与调试
NVIDIAJetson Nano 2GB 系列文章(43): CSI摄像头安装与测试
NVIDIAJetson Nano 2GB 系列文章(44): Jetson的40针引脚
NVIDIAJetson Nano 2GB 系列文章(46): 机电控制设备的安装
NVIDIAJetson Nano 2GB 系列文章(47): 组装过程的注意细节
NVIDIAJetson Nano 2GB 系列文章(48): 用键盘与摇杆控制行动
NVIDIAJetson Nano 2GB 系列文章(49): 智能避撞之现场演示
NVIDIAJetson Nano 2GB 系列文章(50): 智能避障之模型训练
NVIDIAJetson Nano 2GB 系列文章(51): 图像分类法实现找路功能
NVIDIAJetson Nano 2GB 系列文章(52): 图像分类法实现找路功能
NVIDIAJetson Nano 2GB 系列文章(53): 简化模型训练流程的TAO工具套件
NVIDIA Jetson Nano 2GB 系列文章(54):NGC的内容简介与注册密钥
NVIDIA Jetson Nano 2GB 系列文章(55):安装TAO模型训练工具
NVIDIA Jetson Nano 2GB 系列文章(56):启动器CLI指令集与配置文件
NVIDIA Jetson Nano 2GB 系列文章(57):视觉类脚本的环境配置与映射
NVIDIA Jetson Nano 2GB 系列文章(58):视觉类的数据格式
NVIDIA Jetson Nano 2GB 系列文章(59):视觉类的数据增强
NVIDIA Jetson Nano 2GB 系列文章(60):图像分类的模型训练与修剪
NVIDIA Jetson Nano 2GB 系列文章(61):物件检测的模型训练与优化
NVIDIA Jetson Nano 2GB 系列文章(62):物件检测的模型训练与优化-2
NVIDIA Jetson Nano 2GB 系列文章(63):物件检测的模型训练与优化-3
NVIDIA Jetson Nano 2GB 系列文章(64):将模型部署到Jetson设备
NVIDIA Jetson Nano 2GB 系列文章(65):执行部署的 TensorRT 加速引擎
NVIDIA Jetson 系列文章(1):硬件开箱

NVIDIA Jetson 系列文章(2):配置操作系统
NVIDIA Jetson 系列文章(3):安装开发环境
NVIDIA Jetson 系列文章(4):安装DeepStream
NVIDIA Jetson 系列文章(5):使用Docker容器的入门技巧
NVIDIA Jetson 系列文章(6):使用容器版DeepStream
NVIDIA Jetson 系列文章(7):配置DS容器Python开发环境
NVIDIA Jetson 系列文章(8):用DS容器执行Python范例
NVIDIA Jetson 系列文章(9):为容器接入USB摄像头
NVIDIA Jetson 系列文章(10):从头创建Jetson的容器(1)
NVIDIA Jetson 系列文章(11):从头创建Jetson的容器(2)
NVIDIA Jetson 系列文章(12):创建各种YOLO-l4t容器
NVIDIA Triton系列文章(1):应用概论
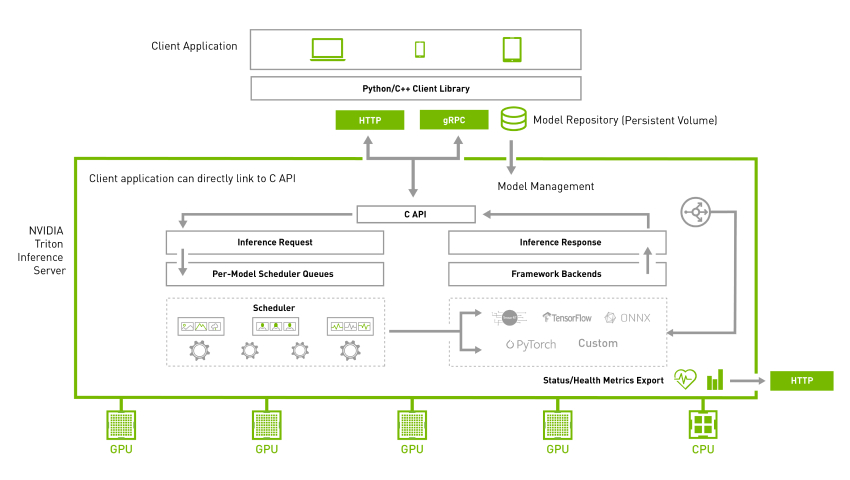
NVIDIA Triton系列文章(2):功能与架构简介
NVIDIA Triton系列文章(3):开发资源说明
NVIDIA Triton系列文章(4):创建模型仓
NVIDIA Triton 系列文章(5):安装服务器软件
NVIDIA Triton 系列文章(6):安装用户端软件
NVIDIA Triton 系列文章(7):image_client 用户端参数
原文标题:NVIDIA Triton 系列文章(8):用户端其他特性
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
22文章
3776浏览量
91084
原文标题:NVIDIA Triton 系列文章(8):用户端其他特性
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Triton编译器如何提升编程效率
Triton编译器的优化技巧
Triton编译器的优势与劣势分析
Triton编译器在机器学习中的应用
Triton编译器支持的编程语言
Triton编译器与其他编译器的比较
Triton编译器功能介绍 Triton编译器使用教程

NVIDIA助力提供多样、灵活的模型选择
适用于35kV及以下新建或改扩建的用户端Acrel-2000Z电力监控
使用NVIDIA Triton推理服务器来加速AI预测
在AMD GPU上如何安装和配置triton?

ACRELADL系列多功能电能表在迪拜大厦EMS中的应用





 工商网监
工商网监
评论