 用于自动驾驶的时空融合激光雷达地点识别算法SeqOT
用于自动驾驶的时空融合激光雷达地点识别算法SeqOT
论文作者:Junyi Ma, Xieyuanli Chen, Jingyi Xu, Guangming Xiong∗
论文来源:IEEE Transactions on Industrial Electronics
1、摘要
在本文中,作者在其原有工作OverlapTransformer (OT)的基础上,提出了一种用于自动驾驶的时空融合激光雷达地点识别算法SeqOT。SeqOT以多帧激光雷达数据作为输入,使用端到端的方式直接为序列化数据提取全局描述子,用以快速的地点识别检索。SeqOT采用多尺度Transformer结构对单帧高阶特征与多帧高阶特征进行增强和融合,并使用池化结构对多帧子描述子进行降维,显著提升地点识别描述子特异性和实时性。此外,SeqOT具有yaw角旋转不变和激光序列顺序不变的结构,进一步提高自动驾驶车辆多角度地点识别的准确率。试验结果表明,SeqOT在长、短时间跨度数据集上均具有很好的识别性能,且其运行速度快于激光雷达帧率,适用于实时运行的自动驾驶车辆。
2、主要工作与贡献
本文的主要贡献是一个端到端的地点识别神经网络,它利用连续的range image实现可靠的长期地点识别。受益于所提出的yaw角旋转不变结构,SeqOT对视点变化和多帧激光雷达数据的输入顺序具有较强的鲁棒性,因此即使在自动驾驶车辆以相反方向行驶时也能实现可靠的地点识别。SeqOT利用多尺度Transformer模块来融合序列化激光雷达数据的时空信息,通过增强单帧内部特征的关联与多帧间特征的关联,增强地点描述子特异性,进而提升地点识别精度。
3、算法流程
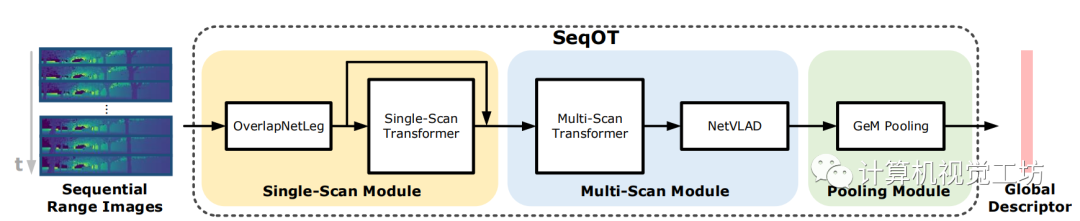
图1 SeqOT算法结构
SeqOT由单帧编码模块、多帧编码模块,以及池化模块组合而成。如图1所示,首先将多帧三维激光点云通过球面投影转换为多帧二维range image,然后将各帧range image输入到单帧编码模块中,分别进行空间维度的压缩和通道维度的扩张,再利用单帧Transformer模块进行特征图的特异性增强,然后将特异性增强后的结果与增强前的结果进行通道维度上的拼接。以上操作均对序列化激光信息中的单帧数据分别进行操作。接下来,将单帧编码模块输出的特征输入到多帧编码模块中,在将相邻帧特征进行拼接后,输入到多帧Transformer模块进行多帧信息的高阶特征融合与增强,然后将融合后的结果输入到NetVLAD结构中生成一系列维度为1x256的子描述子向量。池化模块将此输入激光序列中的全部子描述子进行池化压缩,为输入激光序列生成最终的1x256全局描述子向量。
球面投影与yaw角旋转等变性
SeqOT使用序列化range image作为输入,并充分利用其yaw角旋转等变性。一个三维激光点(x, y, z),通过如下公式就可以投影至一个二维的图像像素(u, v),这就是球面投影生成range image的过程。range image上的每个像素点都代表激光点的距离信息。
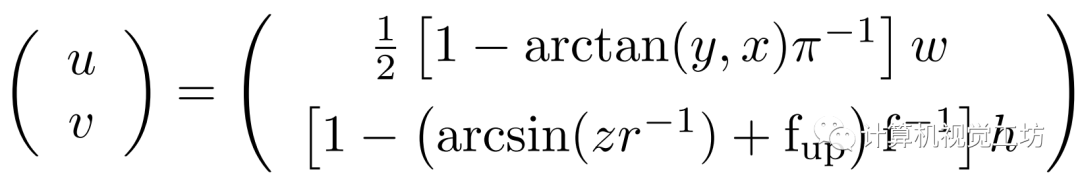
range image本身具备yaw角旋转等变性,即一帧激光点云相对于z轴的旋转等价于本帧range image的平移。图2展示了yaw角旋转等变的简单示例。
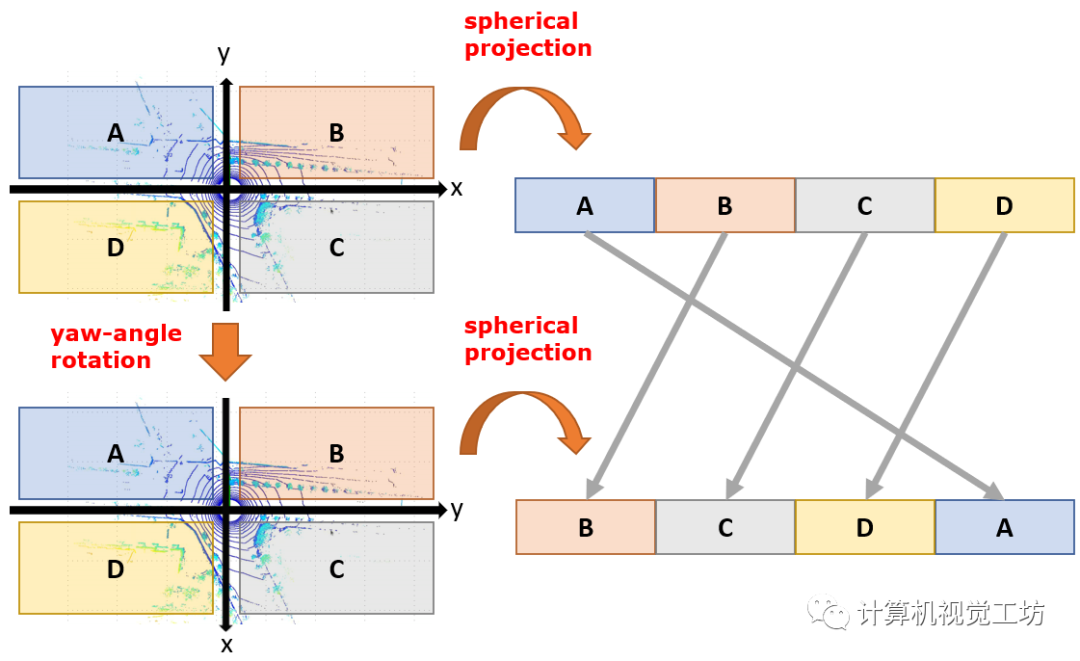
图2 yaw角旋转等变性示例
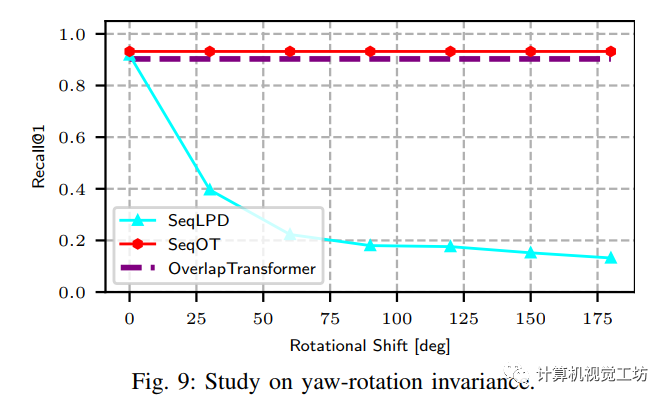
得益于三维点云绕z轴的旋转等价于range image的平移,SeqOT后续的结构能够输出一系列yaw角旋转等变的中间特征图,进而最终将yaw角旋转等变性转化为yaw角旋转不变性,输出不受视点变化影响的全局描述子,从而保证多角度地点识别的可行性。
单帧编码模块
单帧编码模块对输入序列激光帧的每一帧单独进行高阶特征提取。基于此前的工作[1],单帧编码模块使用了与OverlapTransformer相似的OverlapNetLeg对range image进行高度方向的压缩与通道维度的扩张。而后的单帧Transformer模块对OverlapNetLeg的输出进行特异性增强,即增强单帧激光内部不同特征之间的关联。增强后的特征与增强前的特征进行拼接,得到yaw角旋转等变的中间特征,输入到后续的多帧编码模块。
多帧编码模块与池化模块
多帧编码模块将连续帧经过单帧编码模块输出的序列化高阶特征进行初步融合,池化模块则对初步融合的特征进行描述子级的聚合,最终为序列化输入计算地点识别描述子。在多帧编码模块中,首先将相邻三帧点云对应的单帧编码模块的输出进行拼接,构成更长的特征编码,输入至多帧Transformer模块,对帧间特征关联进行增强,实现多帧信息的融合。序列化信息融合后的特征输入至NetVLAD结构中,提取一系列子描述子。池化模块最终将序列子描述子进行聚合,生成一维地点识别全局描述子。由于结构中使用了具有顺序不变性质的NetVLAD结构与GeM池化结构,因此最终输出的全局描述子具备yaw角旋转不变性和激光序列顺序不变性,示例如图3所示,相关证明详见论文。
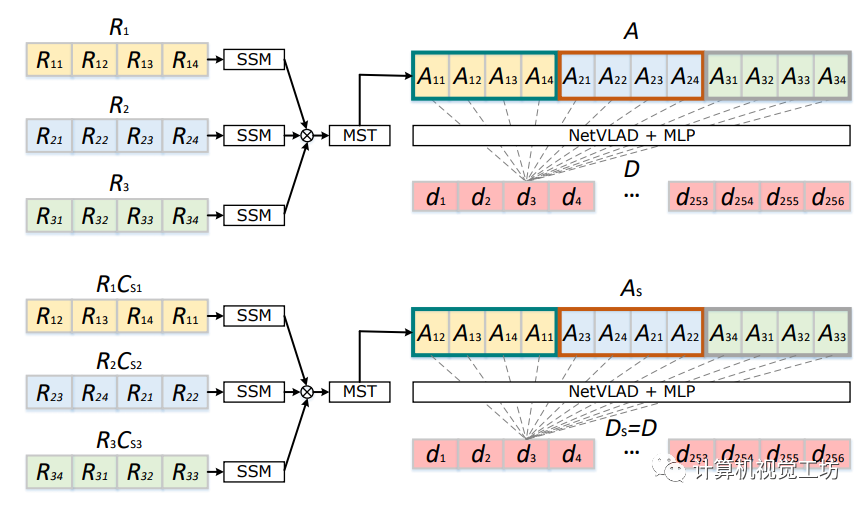
图3 全局描述子yaw角旋转不变性示例
基于overlap的训练
与此前工作[1]类似,SeqOT利用基于overlap划分的数据集进行训练。利用overlap作为label进行训练的理念在OverlapNet论文[2]中有所阐述。训练过程采用对比学习的思路,对于一帧query点云,同时向SeqOT输入本帧点云对应的序列激光帧、以及它的kp个正样本序列和kn个负样本序列。基于overlap的triplet loss函数如下式所示。
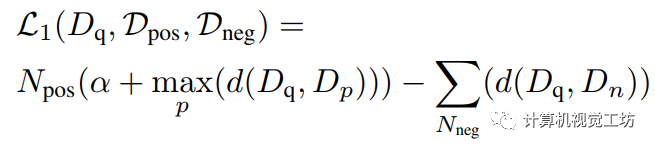
使用overlap而不是点云之间的距离作为衡量正负样本的基准,是因为overlap对于描述激光点云相似度来说是一个更为自然的方式;此外,点云间的overlap对应了后续点云配准的质量,因此基于overlap对是否为同一地点进行判断更有益于后续算法的进行。此外,本工作面向自动驾驶车辆地点识别最常用场景——可重复性行驶环境,为低显存的嵌入式设备提供了更为节省资源的两步训练策略,即第一步:将triplet loss作用于多帧编码模块输出的子描述子,训练池化模块之前的模型,并保存训练使用的子描述子;第二步:利用保存的子描述子作为输入,将triplet loss作用于SeqOT最终输出的全局描述子,训练池化模块。
4、实验结果
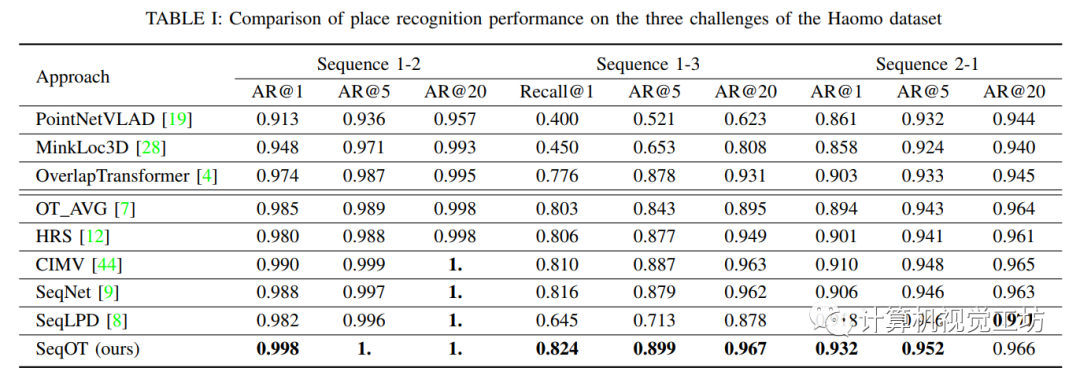
毫末数据集上的地点识别结果
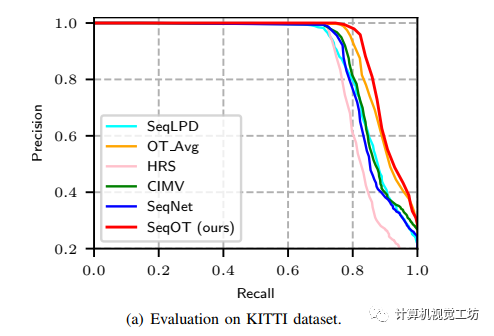
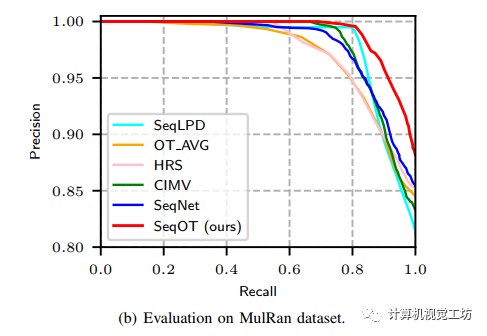
KITTI和MulRan数据集上的泛化性测试结果
输入序列长度的对比试验结果
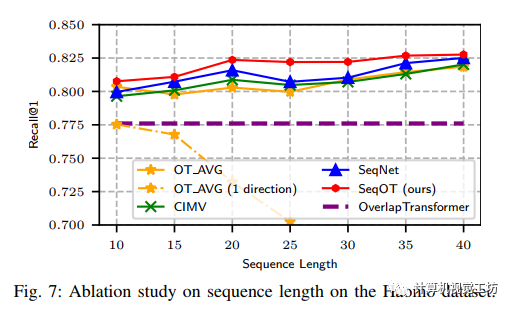
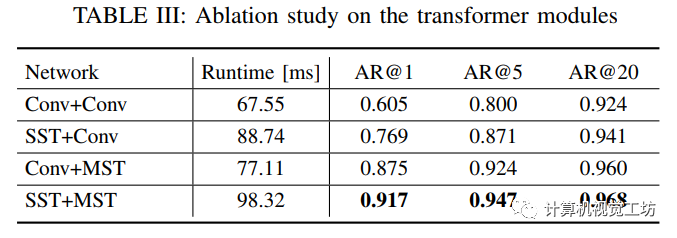
多尺度Transformer的消融试验结果
yaw角旋转不变性验证
审核编辑:郭婷
-
神经网络
+关注
关注
42文章
4771浏览量
100752 -
激光雷达
+关注
关注
968文章
3971浏览量
189895 -
自动驾驶
+关注
关注
784文章
13805浏览量
166429
原文标题:SeqOT: 基于时空融合Transformer的SOTA地点识别算法,代码开源(IEEE Trans2022)
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Mobileye牵手Innoviz合作激光雷达用于其Mobile Drive平台
毫米波雷达与激光雷达比较 毫米波雷达在自动驾驶中的作用
激光雷达在SLAM算法中的应用综述
激光雷达威廉希尔官方网站 的基于深度学习的进步
激光雷达在自动驾驶中的应用
激光雷达与纯视觉方案,哪个才是自动驾驶最优选?
激光雷达滤光片:自动驾驶的“眼睛之选”

自动驾驶汽车如何识别障碍物
百度萝卜快跑第六代无人车携手禾赛AT128激光雷达,共筑自动驾驶新篇章
基于FPGA的激光雷达控制板

阜时科技近期签订商用车自动驾驶全固态激光雷达批量订单
未来已来,多传感器融合感知是自动驾驶破局的关键
激光雷达的应用场景
硅基片上激光雷达的测距原理






 工商网监
工商网监
评论