 关于ByteHouse你想知道的一切分享
关于ByteHouse你想知道的一切分享
ByteHouse 的前世今生
字节跳动最早是在 2017 年底开始使用 ClickHouse 的,用于支撑增长分析的业务场景。对于字节跳动而言,增长分析的重要性不言而喻。这是一项十分考验运营团队能力的工作,如何衡量不同运营方法的有效性,应该对哪些数据指标进行考量,如何对指标的波动进行更深层次的原因分析,这些需要重点关注。这其中涉及大量数据分析,对于数据分析平台的实时性也有着非常高的要求。在比对、试用过多款 OLAP 分析产品后,字节跳动最终选择了 ClickHouse,并且整体方案的可行性在实际业务应用中得到了很好的验证。
在取得了不错的业务效果之后,采用 ClickHouse 的方案快速推广,从支持增长分析的单一场景,很快扩展到 BI 分析、AB 测试、模型预估等多个场景。同时,研发团队也持续不断打磨和改进 ClickHouse 能力,比如增强数据接入功能、提升 SQL-based 指标计算的执行效率,包括 UDF 增强、SQL 语法增强等,很快使 ClickHouse 成为字节内部最主流的分析平台。
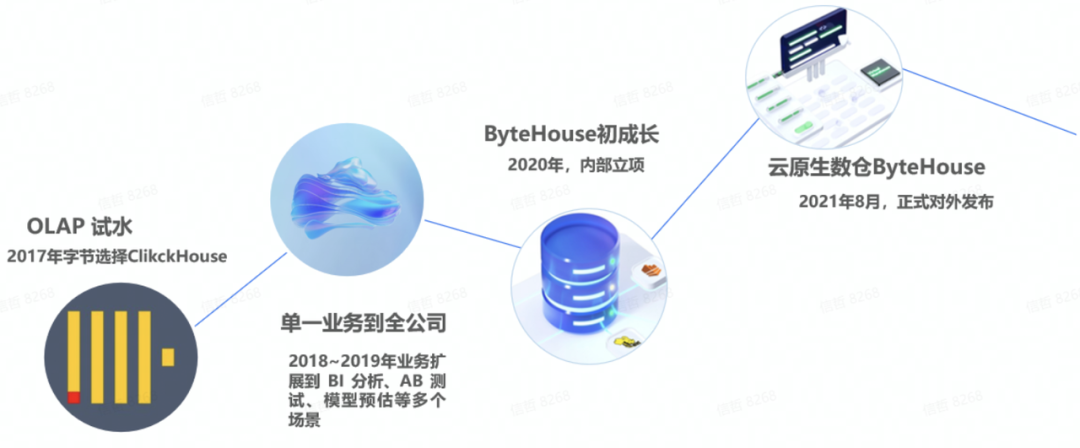
在产品的不断打磨中,2020 年字节跳动火山引擎正式立项,把基于 ClickHouse 做了很多增强和自研的 ByteHouse 作为 ToB 的核心产品之一加快产品化步伐,以期让更多的用户在分析领域获得更快、更好的业务体验。在 2021 年 8 月份,ByteHouse 正式对外发布并提供服务。
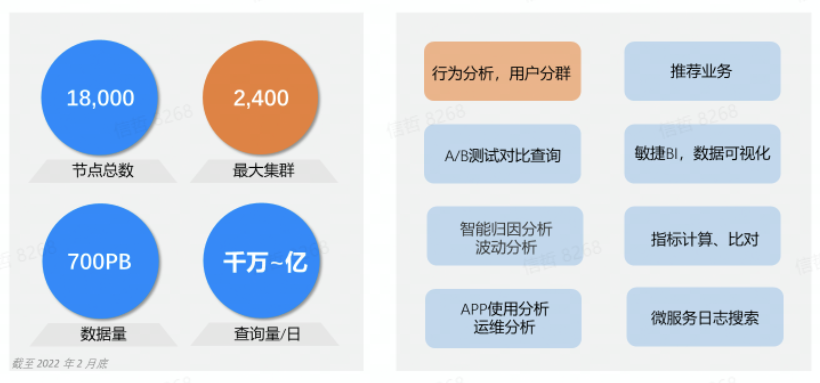
至 2022 年 6 月底,字节跳动内部的 ByteHouse 节点总数已经超过18000个,管理总数据量超过 700PB,每天上亿次的分析查询跑在ByteHouse上,有离线的、有实时的。其中支撑抖音、头条的行为分析平台其集群规模已经达到2400个节点。截止当前,字节内部 80% 的分析型应用都跑在ByteHouse平台上。
字节跳动最初为什么选择 ClickHouse
字节跳动曾做过各类分析型产品做过调研,如 Kylin、Druid、SparkSQL 等。那究竟为什么最后字节跳动选择了 ClickHouse,并进一步投入力量研发出 ByteHouse 使之成为字节跳动内部核心的数据分析平台呢?这里以两个具体的字节跳动业务案例来展开一些细节:
推荐系统实时指标
公司内部 A/B 实验平台已经提供了 T+1 的离线实验指标,而推荐系统需要更快地观察算法模型、或者某个功能的上线效果,因此需要一份能够实时反馈的数据作为补充,而且还要求:
○ 能同时查询聚合指标和明细数据;
○ 能支持多达几百列的维度和指标,且场景灵活变化,会不断增加;
○ 可以高效地按 ID 过滤数据;
○ 需要支持一些机器学习和统计相关的指标计算(比如 AUC)。
选型开始时,最需要解决的是“快”,所以选择了 Kylin 作为主要分析引擎,其优点是能够提供毫秒级别的查询延时。但是 Kylin 存在维度爆炸导致预计算时间越来越长,数据可用时间没有保证的问题。此外,新业务上线会产生新的指标和维度,Kylin 无法支持维度和指标在线更新。
后期改用 SparkSQL ,同样存在不少问题,如查询分析的延迟太长、资源使用率高、稳定性不够好频发OOM,以及无法支持跨更长时间周期的数据做分析等。
综合考量,最后选择了 ClickHouse:
○ 能更快地观察算法模型,没有预计算所导致的高数据时延;
○ 既适合聚合查询,在配合跳数索引后,也能充分支持明细查询;
○ BitSet 的过滤 Bloom Filter 是比较好的解决方案。
同时,团队也持续投入研发力量,不断自研增强产品能力,比如通过异步构建索引使得整体写入吞吐量能力提升 20%。通过对 Kafka 多消费线程的改造和增强,实现并行消费,使得写入性能得到线性提升。此外,自研 HaKafka 引擎,提升了系统的 HA 高可用能力,即使出现节点故障也不用担心数据有完整性问题。
广告投放实时分析
通常运营人员需要查看广告投放的实时效果,由于业务的特点,当天产生的数据往往会涉及到对历史数据的刷新,威廉希尔官方网站 上最初是基于 Druid 实现,但有些问题一直难以解决。例如,实时数据会涉及到历史3个月的时间分区,Druid 会产生很多 segment,历史数据重刷后需要额外时间去做合并的操作,无法保证数据的实时消费;另外,业务数据的维度非常多,数据粒度非常细,所以 Druid 的预聚合的意义不大,业务更多的需求是直接来消费明细数据。
最后团队也选择了 ClickHouse 威廉希尔官方网站 路线,并持续做了改进和增强,如:
○ 对 Buffer Engine 做了改进,解决了社区版本在 Buffer Engine 和 ReplicatedMergeTree 同时使用下查询一致性的问题。
○ 自研事务机制,确保每次插入数据的原子性,增强数据消费的稳定性,解决了社区版本由于缺少事务支持,在异常场景下,往往会出现丢失或者重复消费的情况。具体实现上是将 Offset 和 Parts 数据绑定在一起,每次消费时,会默认创建一个事务,由事务负责把 Part 数据和 Offset 一同写入磁盘中,如果出现失败,事务会一起回滚 Offset 和写入的 Part 然后重新消费。
ByteHouse 具备哪些特点
随着 ByteHouse 在字节跳动内部支撑的分析业务越来越多,ByteHouse 也成为了字节跳动内部分析平台构建的事实标准。ByteHouse 在字节广泛的应用中,不断从业务角度出发不断打磨产品,并从实际应用角度思考什么样的数据分析产品才是更好用的。我们认为,一个优秀的数据分析产品应该具备以下特点:
能支撑更全面的分析场景
数据库行业流传着“没有银弹”的说法,大家认为没有一个分析类产品能够满足所有场景。这固然是很有道理的,但是也不必走向另外一个极端,所有场景都要“一事一库”。如果有一个通用性的数据分析产品,能够支撑 80% 以上的常见场景,这能为企业减少大量的时间和精力,并且能更有信心的应对营业务带来的数据分析挑战。
ClickHouse 的一个问题就是适用的场景相对较窄,对于宽表模型的查询和分析效率非常高,但涉及到多表关联的分析场景却表现不佳,甚至不支持此类业务场景。因而,ClickHouse的这种高性能的表现更多的是基于“本能”层面。ByteHouse 团队以打造一款综合且性能强大的分析平台为目标,对ClickHouse 做了全方位的增强,推出了全自研的查询优化器,从而让性能表现从“本能”层面跃迁到“智能”层面,从而更好的应对各类分析场景。
对于一款关系型数据库产品来说,优化器就是大脑,通过优化器对查询语句进行改写优化,基于代价寻找最优执行路径、生成执行计划,并且结合资源动态负载情况,让整体性能的输出更加稳健、也更加智能。从效果来看,在部分场景下,优化器使得性能提升达 10 倍以上;此外,在 TPC-DS 标准测试测试场景中,启用优化器的收益也十分显著,能够完成全部 99 个测试场景,而且性能也提升数倍不等。
而应对传统数仓负载中的复杂查询场景,仅仅有查询优化器的增强还不够,ByteHouse 为此还做了大量的工作。如 Runtime Filter,能够智能过滤掉分析中不相干数据,减少中间过程数据的网络传输,提升整体分析效率,在星型和雪花型业务分析场景中有很好的效果。另外通过优化网络威廉希尔官方网站 ,比如连接复用、RDMA、传输压缩等威廉希尔官方网站 ,也极大提升了整体分析性能。此外还包括其他一系列的能力增强,比如细粒度资源管控、数据交换的优化等,能够让 ByteHouse 在复杂分析场景中游刃有余。
从收益效果上看,在字节内部部分业务场景中,多表关联分析性能提升 26 倍,单表复杂查询也提升 3 倍左右,在标准SSB测试场景中也表现不俗,为支撑更全面的分析场景的目标迈出重要一步。
数据分析能力能随业务快速扩缩,极致弹性
在 node-base 架构下,存算一体的模式不够灵活,难以满足业务对弹性的需求,扩容的代价无论是时间成本和资源成本都很高。应对这些挑战,ByteHouse 团队花费极大精力从底层开始秉承 Cloud-Native 云原生的架构理念进行整体重构,让资源可以伴随业务的需求进行灵活的弹性伸缩,扩容的代价更低更可控。另外,业务上可以通过读写分离做更好的资源管控和分流,从而让整体业务的 SLA 更有保障。下面介绍部分 ByteHouse 架构重构中的关键威廉希尔官方网站 点。
首先是基于分布式 KV 构建元数据管理服务,元数据信息会持久化保存在状态存储池里面,为了降低对元数据库的访问压力,对于访问频度高的元数据会进行缓存。元数据服务自身是无状态的,可以水平扩展。
在高性能层面,除了前面介绍的全自研优化器之外,还通过智能的分布式多级缓存威廉希尔官方网站 来弥补存算分离架构下远程数据访问时额外的网络开销和IO开销带来的性能损失。此外 virtule warehouse 计算资源实现了容器化部署,做到了无状态化,从而可以快速、灵活的进行弹性伸缩,且不影响业务。
在存储层面,实现了存储服务化,对数据存储层进行统一抽象,构造 VFS 虚拟存储系统,能够支持更多的存储语义,包括 HDFS 块存储、对象存储等,既解决了存储在扩展性、读写吞吐瓶颈、一致性等问题,同时能大幅降低存储成本。
强一致性的事务机制、MVCC 多版本并发控制、细粒度锁等威廉希尔官方网站 保障,也能让 ByteHouse 更好地去满足核心分析业务对一致性和并发能力的要求。
此外,在负载管理上,围绕计算、内存、网络带宽这三项核心资源进行持续优化,同时也在不断引入AI等新威廉希尔官方网站 让系统资源的动态调配更加智能和高效;细粒度、多级的资源隔离能力也能更好的匹配业务差异化的需求,让整体系统运行更加稳定可靠。
稳定、高可用
以抖音集团内部建于2017年的行为分析平台为例,仅头条和抖音两款应用每天会产生万亿条级别的事件记录,且至少保存1年,分析的特征维度多达上千,既有聚合查询也有明细查询,其自助式查询分析要求必须达到秒级响应。当前这个平台运行在 2400 个节点的 ByteHouse 集群上。
对社区版 ClickHouse 或者其他大部分分析类产品来说,要达到这个规模是非常困难的,几乎难以实现。ByteHouse 做了哪些能力增强来不断突破规模上限、持续支持业务高速增长呢?这里我们先重点介绍两方面的能力增强:
一、通过自研的 HaMergeTree 替代社区的 ReplicatedMergeTree,降低对 ZooKeeper 的请求次数,减少在 Zookeeper 上存储的数据量,副本直接通过 log 日志来交换信息,不需要再从 Zookeeper 获取,从而极大减轻 Zookeeper 的负载,让其压力与集群内数据量规模脱钩。
二、通过元数据持久化的方案,提升故障恢复能力。社区版本的元数据常驻于内存中,这会导致重启时间非常长,因而当故障发生后,恢复的时间也很长,动辄一到两个小时,这个是业务不能接受的。ByteHouse 的做法是将元数据持久化到 RocksDB,启动时直接从 RocksDB 加载元数据,内存中也仅仅存放必要的 Part 信息,这样就减少元数据对内存的占用,在性能基本无损失的情况下,单机支持的part 不再受内存容量的限制,可以达到 100 万以上;最重要的是极大缩短了集群的故障恢复时间,从1-2 小时直接缩短到 3 分钟,大大提高了系统的高可用能力,为业务提供了坚实保障。
保证查询效率前提下,更快、更准确的数据导入
在实时写入场景中,社区版 ClickHouse 还是存在部分能力的缺失,比如数据分布按 shard 的分布策略很难保障均匀分布,会存在数据倾斜的情况,而且不支持由用户指定唯一键的业务需求,也无法保证数据的有序消费, 单线程的消费模式导致吞吐量受限,另外在 HA 高可用上也存在能力缺失。ByteHouse 针对这些不足对 kafka engion 做了全面的增强。
首先是在分布式架构下,通过自研的 HaKafka 引擎为数据的实时注入提供了 HA 高可用保障,保障数据不丢失;支持唯一键;通过 memory table,提升了实时写入的吞吐能力,同时延迟刷盘也大幅降低IOPS,节省 IO 资源。
在此基础上 ByteHouse 再向前一步,演进到云原生架构,能力得到更大的提升,包括支持 exactly-once 消费语义,自动容错,之前 node-base 架构模式的扩容难、代价高的问题也在云原生架构下迎刃而解,能够做到按需的灵活弹性扩容和缩容。
此外,ByteHouse 自研了 UniqueMergeTree 表引擎,很好的平衡了写和读的性能。UniqueMergeTree 表引擎既支持行更新的模式,也支持部分列更新的模式,用户可以根据业务要求开启或关闭。在性能方面,与 ReplacingMergeTree 相比,UniqueMergeTree 的写入性能只有轻微下降,但在查询性能上取得了数量级的提升。进一步对比了 UniqueMergeTree 和普通 MergeTree 的查询性能,发现两者是非常接近的。
ByteHouse 的未来展望
我们将持续围绕让 ByteHouse 更快、更稳、更智能持续做威廉希尔官方网站 迭代,包括更强的优化器,当前在原型测试中有 3 倍的性能提升;通过AI威廉希尔官方网站 的引入让系统更智能更高效,在原型测试中,基于 IMDB 的大规模数据集的性能表现上有20%的提升;此外更加智能的物化视图威廉希尔官方网站 以及 RDMA 威廉希尔官方网站 预期都会在 23 年实现产品化落地。
面向未来,ByteHouse 的愿景是打造数据分析领域的“抖音”平台,能够为用户带来一体化的集成、分析体验,降低用户分析门槛,一站式提供分析所需的各种能力,并能通过安全可信的数据分享、模型分享帮助用户便捷地实现交易和价值变现。
审核编辑 :李倩
-
SQL
+关注
关注
1文章
764浏览量
44127 -
数据分析
+关注
关注
2文章
1449浏览量
34056 -
字节跳动
+关注
关注
0文章
318浏览量
8931
原文标题:关于 ByteHouse 你想知道的一切,看这一篇就够了
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ADC128S102WGRQV想知道输入阻抗具体有多大?
大研智造厂家面对面 关于激光焊锡机、锡球焊设备高频问题QA,你想知道的都在这!

智能读码器Q&amp;A | 常见疑问解答,你想知道的都在这!

关于公路边坡安全监测,你想知道的都在这里!
定华雷达仪表学堂:雷达液位计,还有什么是你想知道的呢?

关于定位系统威廉希尔官方网站 你知道多少?
切分去核机物联网监控管理系统解决方案
TLE9867使用定序器读取模拟输入数据,只想知道在读取ADC1数据时,中断方式和定序器方式有何不同?
求助,关于ADC和触发器的基本问题求解

一帧CANFD报文由多少个位组成?
关于ESS和BMS,您需要了解的一切


高速PCB的铜箔选用指南—外层避坑设计






 工商网监
工商网监
评论