 英伟达推出A800 GPU,为了能卖给中国客户,对A100“砍了一刀”...
英伟达推出A800 GPU,为了能卖给中国客户,对A100“砍了一刀”...
电子发烧友网报道(文/梁浩斌)当地时间本周一,英伟达官方确认将面向中国客户推出一款型号为A800的GPU,以替代此前受到出口管制的A100 GPU芯片。英伟达表示,A800符合美国政府的出口管制条例,不能通过编程超过限制的性能。
今年8月的最后一天,英伟达发布公告称,公司收到美国政府通知,要求对中国大陆以及中国香港、俄罗斯的客户出口的高端GPU芯片,需要申请出口许可证,其中覆盖到A100和H100等几款GPU,同时未来性能等于或高于A100的产品都会受到该政策影响。随后10月继续加码的出口限制,更是将申请出口许可证的产品类别覆盖到更大的范围,包括用于超级计算机、量子计算等的尖端芯片、威廉希尔官方网站 、设备等。
值得一提的是,A800 GPU是美国半导体公司首次为中国市场推出符合美国贸易政策的先进芯片。在9月份,英伟达曾表示,新的出口管制规则可能会令公司损失数亿美元的收入。而A800作为应对贸易政策而“定制”的产品,可谓进展神速,英伟达透露在今年第三季度已经投产,目前已经有一些国内经销商已经拿到实物,并打出A800 GPU的广告。
A100性能和A800几乎一致,但互连带宽被“砍一刀”
相信大家最关心的是A800跟此前的A100性能有什么差别,A800会不会是特供中国的“低配版”。其实从英伟达已经公开的参数来看,A800单卡算力在参数上几乎是与A100是完全一致的。
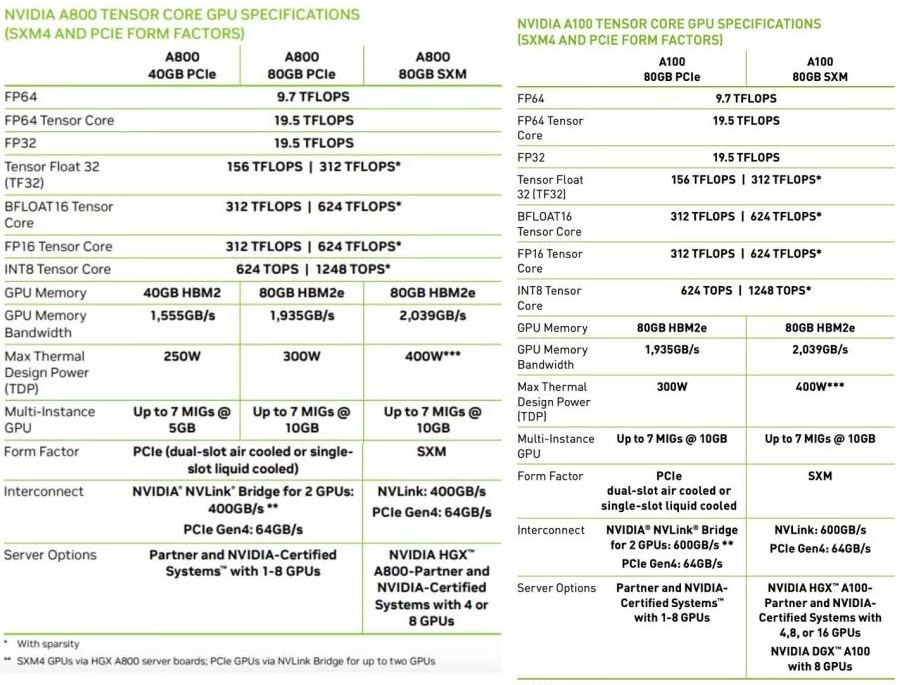
唯一的不同在于NVLink互连桥的带宽缩水33%,从A100上的600GB/s砍至A800的400GB/s,这可能会影响到多卡服务器,比如数据中心、超级计算机的整体性能。
NVLink是英伟达在2014年发布的一种总线和通信协议,采用了点对点结构、串列传输,用于CPU和GPU之间,或是多个GPU之间的连接,相比通过PCIe总线互连的传统方式,NVLink可以大幅提高交互效率。简单来说,NVLink就是能在GPU和GPU、GPU和CPU之间实现高速大带宽直连通信的互连威廉希尔官方网站 。
图源:英伟达
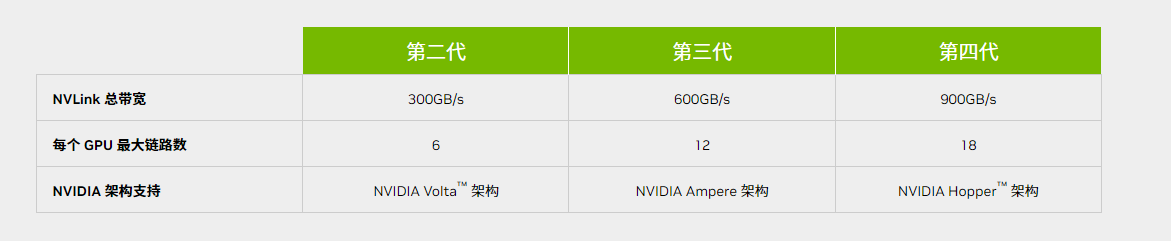
电子发烧友从英伟达官网上了解到,A100所支持的NVLink总带宽达到600GB/s,属于第三代产品。今年3月英伟达在GTC 2022上发布的第四代NVLink-C2C则可以实现高达900GB/s的总带宽,是PCIe 5.0带宽的七倍,并将互连威廉希尔官方网站 扩展至芯片之间的互连,支持定制裸片与 NVIDIA GPU、CPU、DPU、NIC 和 SOC之间实现一致的互连。
而A800上的NVLink总带宽为400GB/s,介于第二代和第三代之间。在AI和HPC等领域中,GPU之间的互连带宽降低,对于动辄数千块GPU组成的计算集群而言显然会造成不小的性能损失。
国内自动驾驶行业首当其冲,谁能替代英伟达?
自动驾驶威廉希尔官方网站 开发,是一项需要大量算力进行AI模型训练、计算的密集型工作。作为AI模型训练的核心之一,英伟达的GPU产品一直以来都是自动驾驶玩家的主要选择。英伟达推出的HGX A100平台就是专为AI场景设计的高性能服务器平台,包含比如驱动自动驾驶汽车的模型,以及大型数据集等,官方宣称可以将模型开发效率提高20倍。
对于自动驾驶项目而言,开发效率的提高意味着缩短自动驾驶汽车的上市周期,加速架构的迭代。在行业内,包括特斯拉目前也在大量应用英伟达GPU打造超算平台。去年6月,特斯拉公布了公司内部用于训练Autopilot与自动驾驶深度神经网络的超级计算机,这个集群使用了720个节点的8个A100 GPU(共5760个),实现高达1.8 exaflops的总算力。
国内方面,蔚来在去年年底就宣布采用英伟达A100 GPU以及Mellanox InfiniBand ConnectX-6网卡构建超级计算机集群。
小鹏汽车在今年8月2日宣布与阿里云合作在乌兰察布建成了中国最大的自动驾驶智算中心“扶摇”,采用阿里云智能计算平台,算力可达600PFLOPS。虽然官方没有公布该超算中心所用的硬件,但此前阿里云一直与英伟达有密切合作,今年3月阿里云和英伟达还合作推出了初创加速计划,为初创企业提供算力缓解计算压力。
另一方面小鹏汽车创始人何小鹏在9月份的朋友圈中评论了英伟达A100出口受限的事件,并表示“坏消息是这会对所有自动驾驶云端训练带来挑战,好消息是刚好我们已经把未来几年的需求提前买回来了。” 言下之意小鹏在自动驾驶AI模型训练上所采用的GPU同样来自英伟达。
因此,高端GPU的供应限制,给未来国内自动驾驶行业带来了很大的不确定性,未来算力受限有可能成为抑制自动驾驶威廉希尔官方网站 发展的关键因素。
当然,英伟达也在努力赶在出口的缓冲期尽量向中国完成更多交付。此前英伟达更新的最新消息称,公司已经获得了授权,可以使得A100和H100在2023年9月1日之前通过英伟达在相关的公司履行订单和物流。
在9月份业内又传出英伟达向台积电下了“超级急件”订单,要求台积电提前生产原计划在明年出货的部分产品,交付期从原本的5-6个月缩短至2-3个月,总量约5000片晶圆。从时间上看,这批产品可能在11月前后可以向英伟达交货。
可以预见,在近一年的缓冲期内,在目前没有其他替代产品的情况下,国内厂商会加快采购相关产品,重点可能是相比A100性能提升高达450%的H100 GPU,这至少能保证在未来几年内对算力的需求。
另一方面,英伟达与多家车企的自动驾驶已经进行深度绑定,包括蔚来、小鹏、极氪、轻舟智航等都已经宣布选择英伟达下一代Thor自动驾驶芯片,但如今有了出口管制的先例,继续在终端采用英伟达芯片难免会存在供应风险。
而在车端的自动驾驶芯片上,国内已经有一些替代产品,比如地平线、黑芝麻、寒武纪、华为等都推出了自研自动驾驶芯片,比如华为MDC810平台采用了昇腾610芯片,可以支持最高400 TOPS算力;理想L8 首发的地平线征程5单芯算力也达到了196TOPS,据称下一代征程6算力将超过100TOPS。而随着国内自动驾驶芯片的发展,未来的供应风险,或许也会是国内车企转向本土芯片公司的契机。
目前的状况,对于英伟达以及国内自动驾驶行业来说显然都不是一件好事。但至少在车端自动驾驶芯片上,国内车企往往采用多供应商的策略,扶持国内芯片厂商,并已经有所起色。然而在自动驾驶AI云端训练上,国内供应商要走的路还很长。
今年8月的最后一天,英伟达发布公告称,公司收到美国政府通知,要求对中国大陆以及中国香港、俄罗斯的客户出口的高端GPU芯片,需要申请出口许可证,其中覆盖到A100和H100等几款GPU,同时未来性能等于或高于A100的产品都会受到该政策影响。随后10月继续加码的出口限制,更是将申请出口许可证的产品类别覆盖到更大的范围,包括用于超级计算机、量子计算等的尖端芯片、威廉希尔官方网站 、设备等。
值得一提的是,A800 GPU是美国半导体公司首次为中国市场推出符合美国贸易政策的先进芯片。在9月份,英伟达曾表示,新的出口管制规则可能会令公司损失数亿美元的收入。而A800作为应对贸易政策而“定制”的产品,可谓进展神速,英伟达透露在今年第三季度已经投产,目前已经有一些国内经销商已经拿到实物,并打出A800 GPU的广告。
A100性能和A800几乎一致,但互连带宽被“砍一刀”
相信大家最关心的是A800跟此前的A100性能有什么差别,A800会不会是特供中国的“低配版”。其实从英伟达已经公开的参数来看,A800单卡算力在参数上几乎是与A100是完全一致的。
唯一的不同在于NVLink互连桥的带宽缩水33%,从A100上的600GB/s砍至A800的400GB/s,这可能会影响到多卡服务器,比如数据中心、超级计算机的整体性能。
NVLink是英伟达在2014年发布的一种总线和通信协议,采用了点对点结构、串列传输,用于CPU和GPU之间,或是多个GPU之间的连接,相比通过PCIe总线互连的传统方式,NVLink可以大幅提高交互效率。简单来说,NVLink就是能在GPU和GPU、GPU和CPU之间实现高速大带宽直连通信的互连威廉希尔官方网站 。
图源:英伟达
电子发烧友从英伟达官网上了解到,A100所支持的NVLink总带宽达到600GB/s,属于第三代产品。今年3月英伟达在GTC 2022上发布的第四代NVLink-C2C则可以实现高达900GB/s的总带宽,是PCIe 5.0带宽的七倍,并将互连威廉希尔官方网站 扩展至芯片之间的互连,支持定制裸片与 NVIDIA GPU、CPU、DPU、NIC 和 SOC之间实现一致的互连。
而A800上的NVLink总带宽为400GB/s,介于第二代和第三代之间。在AI和HPC等领域中,GPU之间的互连带宽降低,对于动辄数千块GPU组成的计算集群而言显然会造成不小的性能损失。
国内自动驾驶行业首当其冲,谁能替代英伟达?
自动驾驶威廉希尔官方网站 开发,是一项需要大量算力进行AI模型训练、计算的密集型工作。作为AI模型训练的核心之一,英伟达的GPU产品一直以来都是自动驾驶玩家的主要选择。英伟达推出的HGX A100平台就是专为AI场景设计的高性能服务器平台,包含比如驱动自动驾驶汽车的模型,以及大型数据集等,官方宣称可以将模型开发效率提高20倍。
对于自动驾驶项目而言,开发效率的提高意味着缩短自动驾驶汽车的上市周期,加速架构的迭代。在行业内,包括特斯拉目前也在大量应用英伟达GPU打造超算平台。去年6月,特斯拉公布了公司内部用于训练Autopilot与自动驾驶深度神经网络的超级计算机,这个集群使用了720个节点的8个A100 GPU(共5760个),实现高达1.8 exaflops的总算力。
国内方面,蔚来在去年年底就宣布采用英伟达A100 GPU以及Mellanox InfiniBand ConnectX-6网卡构建超级计算机集群。
小鹏汽车在今年8月2日宣布与阿里云合作在乌兰察布建成了中国最大的自动驾驶智算中心“扶摇”,采用阿里云智能计算平台,算力可达600PFLOPS。虽然官方没有公布该超算中心所用的硬件,但此前阿里云一直与英伟达有密切合作,今年3月阿里云和英伟达还合作推出了初创加速计划,为初创企业提供算力缓解计算压力。
另一方面小鹏汽车创始人何小鹏在9月份的朋友圈中评论了英伟达A100出口受限的事件,并表示“坏消息是这会对所有自动驾驶云端训练带来挑战,好消息是刚好我们已经把未来几年的需求提前买回来了。” 言下之意小鹏在自动驾驶AI模型训练上所采用的GPU同样来自英伟达。
因此,高端GPU的供应限制,给未来国内自动驾驶行业带来了很大的不确定性,未来算力受限有可能成为抑制自动驾驶威廉希尔官方网站 发展的关键因素。
当然,英伟达也在努力赶在出口的缓冲期尽量向中国完成更多交付。此前英伟达更新的最新消息称,公司已经获得了授权,可以使得A100和H100在2023年9月1日之前通过英伟达在相关的公司履行订单和物流。
在9月份业内又传出英伟达向台积电下了“超级急件”订单,要求台积电提前生产原计划在明年出货的部分产品,交付期从原本的5-6个月缩短至2-3个月,总量约5000片晶圆。从时间上看,这批产品可能在11月前后可以向英伟达交货。
可以预见,在近一年的缓冲期内,在目前没有其他替代产品的情况下,国内厂商会加快采购相关产品,重点可能是相比A100性能提升高达450%的H100 GPU,这至少能保证在未来几年内对算力的需求。
另一方面,英伟达与多家车企的自动驾驶已经进行深度绑定,包括蔚来、小鹏、极氪、轻舟智航等都已经宣布选择英伟达下一代Thor自动驾驶芯片,但如今有了出口管制的先例,继续在终端采用英伟达芯片难免会存在供应风险。
而在车端的自动驾驶芯片上,国内已经有一些替代产品,比如地平线、黑芝麻、寒武纪、华为等都推出了自研自动驾驶芯片,比如华为MDC810平台采用了昇腾610芯片,可以支持最高400 TOPS算力;理想L8 首发的地平线征程5单芯算力也达到了196TOPS,据称下一代征程6算力将超过100TOPS。而随着国内自动驾驶芯片的发展,未来的供应风险,或许也会是国内车企转向本土芯片公司的契机。
目前的状况,对于英伟达以及国内自动驾驶行业来说显然都不是一件好事。但至少在车端自动驾驶芯片上,国内车企往往采用多供应商的策略,扶持国内芯片厂商,并已经有所起色。然而在自动驾驶AI云端训练上,国内供应商要走的路还很长。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
gpu
+关注
关注
28文章
4718浏览量
128828 -
英伟达
+关注
关注
22文章
3759浏览量
90940 -
A800
+关注
关注
0文章
14浏览量
251
发布评论请先 登录
相关推荐
英伟达或取消B100转用B200A代替
今年3月份,英伟达在美国加利福尼亚州圣何塞会议中心召开的GTC 2024大会上推出了Blackwell架构GPU。原定于今年底出货的B100
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
2024年3月19日,[英伟达]CEO[黄仁勋]在GTC大会上公布了新一代AI芯片架构BLACKWELL,并推出基于该架构的超级芯片GB200,将助推数据处理、工程模拟、电子设计自动化
发表于 05-13 17:16
英伟达宣布推出新一代GPU Blackwell,SK海力士已量产HBM3E
在英伟达GTC 2024大会上,英伟达CEO黄仁勋宣布推出新一代GPU Blackwell,第

英伟达缩短AI GPU交付周期,持续推进算力产业链发展
与此同时,随着人工智能的迅猛发展及其广泛应用,对像H100和A100这类专为数据中心设计的高性能GPU的需求也大幅增长。而包括Yotta在内的多家公司因此纷纷加大向英伟
猛兽财经:2024年继续看好英伟达的两个理由
2023年可以说是英伟达成立近30年以来最好的一年。由于大语言模型带动的训练和推理算力需求的增加,导致市场对英伟达AI芯片(H100、

NVIDIA特供中国的芯片,AI性能大降10%售价依然高
目前NVIDIA最昂贵的A100、H100芯片无法对中国市场出售,此前为中国市场定制的A800、H800
2024年,GPU能降价吗?
首当其冲的就是A100GPU。OpenAI使用的是3,617台HGXA100服务器,包含近3万块英伟达GPU。国内云计算相关专家认为,做好A

英伟达和华为/海思主流GPU型号性能参考
一句话总结,H100 vs. A100:3 倍性能,2 倍价格 值得注意的是,HCCS vs. NVLINK的GPU 间带宽。 对于 8 卡
发表于 12-29 11:43
•5709次阅读

英伟达vs.华为/海思:GPU性能一览
NVIDIA NVLink采用全网状拓扑,如下所示,(双向)GPU-to-GPU 最大带宽可达到400GB/s (需要注意的是,下方展示的是8*A100模块时的600GB/s速率,8*A800也是类似的全网状拓扑);






 工商网监
工商网监
评论