 低门槛AI部署工具FastDeploy开源!
低门槛AI部署工具FastDeploy开源!
人工智能产业应用发展的越来越快,开发者需要面对的适配部署工作也越来越复杂。层出不穷的算法模型、各种架构的AI硬件、不同场景的部署需求(服务器、服务化、嵌入式、移动端等)、不同操作系统和开发语言,为AI开发者项目落地带来不小的挑战。
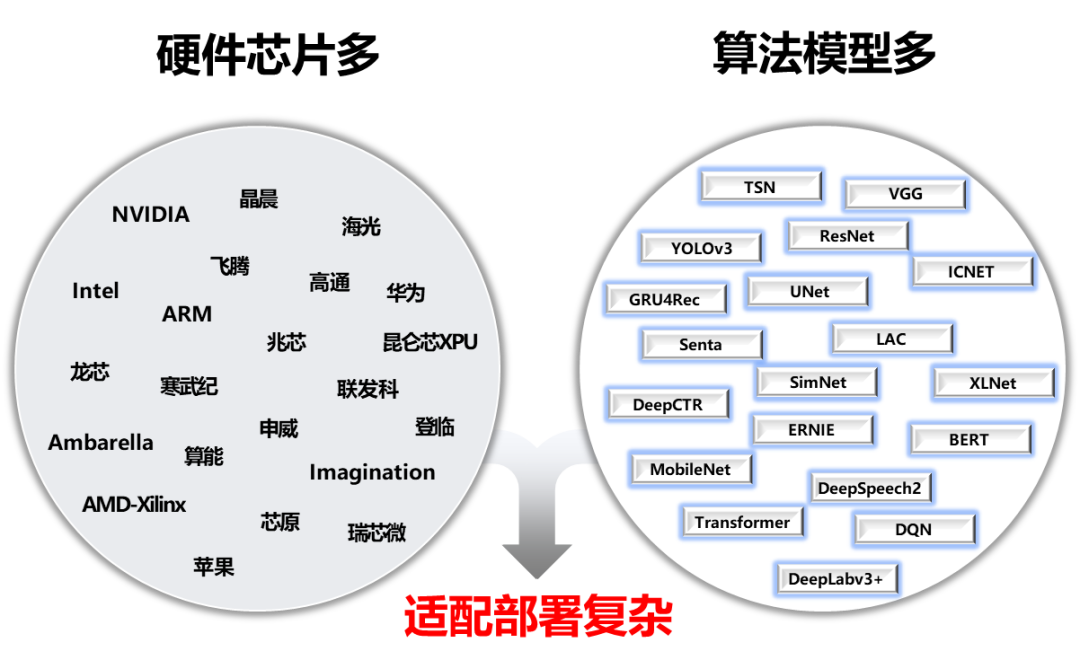
为了解决AI部署落地难题,我们发起了FastDeploy项目。FastDeploy针对产业落地场景中的重要AI模型,将模型API标准化,提供下载即可运行的Demo示例。相比传统推理引擎,做到端到端的推理性能优化。FastDeploy还支持在线(服务化部署)和离线部署形态,满足不同开发者的部署需求。
经过为期一年的高密度打磨,FastDeploy目前具备三类特色能力:
全场景:支持GPU、CPU、Jetson、ARM CPU、瑞芯微NPU、晶晨NPU、恩智浦NPU等多类硬件,支持本地部署、服务化部署、Web端部署、移动端部署等,支持CV、NLP、Speech三大领域,支持图像分类、图像分割、语义分割、物体检测、字符识别(OCR)、人脸检测识别、人像扣图、姿态估计、文本分类、信息抽取、行人跟踪、语音合成等16大主流算法场景。
易用灵活:三行代码完成AI模型的部署,一行API完成模型替换,无缝切换至其他模型部署,提供了150+热门AI模型的部署Demo。
极致高效:相比传统深度学习推理引擎只关注模型的推理时间,FastDeploy则关注模型任务的端到端部署性能。通过高性能前后处理、整合高性能推理引擎、一键自动压缩等威廉希尔官方网站 ,实现了AI模型推理部署的极致性能优化。
项目传送门:https://github.com/PaddlePaddle/FastDeploy
以下将对该3大特性做进一步威廉希尔官方网站 解读,全文大约2100字,预计阅读时长3分钟。
1
3大特性篇
2
3步部署实战篇,抢先看
CPU/GPU部署实战
Jetson部署实战
RK3588部署实战(RV1126、晶晨A311D等NPU类似)
1
3大特性解读
全场景:一套代码云边端多平台多硬件一网打尽,覆盖CV、NLP、Speech
支持PaddleInference、TensorRT、OpenVINO、ONNXRuntime、PaddleLite、RKNN等后端,覆盖常见的NVIDIAGPU、x86CPU、Jetson Nano、Jetson TX2、ARMCPU(移动端、ARM开发板)、Jetson Xavier、瑞芯微NPU(RK3588、RK3568、RV1126、RV1109、RK1808)、晶晨NPU(A311D、S905D)等云边端场景的多类几十款AI硬件部署。同时支持服务化部署、离线CPU/GPU部署、端侧和移动端部署方式。针对不同硬件,统一API保证一套代码在数据中心、边缘部署和端侧部署无缝切换。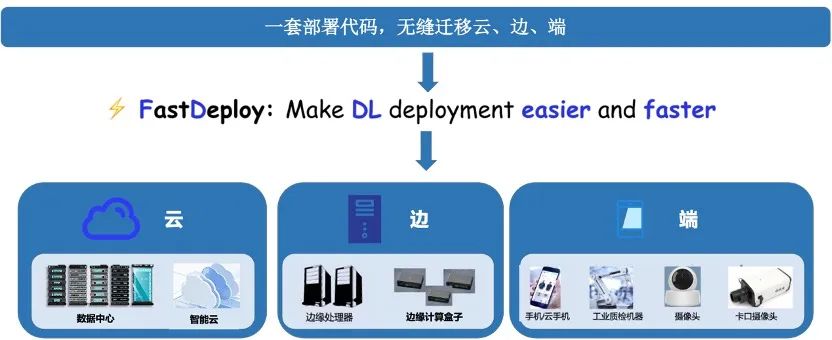 FastDeploy支持CV、NLP、Speech三大AI领域,覆盖16大类算法(图像分类、图像分割、语义分割、物体检测、字符识别(OCR) 、人脸检测、人脸关键点检测、人脸识别、人像扣图、视频扣图、姿态估计、文本分类 信息抽取 文图生成、行人跟踪、语音合成)。支持飞桨PaddleClas、PaddleDetection、PaddleSeg、PaddleOCR、PaddleNLP、PaddleSpeech 6大热门AI套件的主流模型,同时也支持生态(如PyTorch、ONNX等)热门模型的部署。
FastDeploy支持CV、NLP、Speech三大AI领域,覆盖16大类算法(图像分类、图像分割、语义分割、物体检测、字符识别(OCR) 、人脸检测、人脸关键点检测、人脸识别、人像扣图、视频扣图、姿态估计、文本分类 信息抽取 文图生成、行人跟踪、语音合成)。支持飞桨PaddleClas、PaddleDetection、PaddleSeg、PaddleOCR、PaddleNLP、PaddleSpeech 6大热门AI套件的主流模型,同时也支持生态(如PyTorch、ONNX等)热门模型的部署。
易用灵活,三行代码完成模型部署,一行命令快速体验150+热门模型部署
FastDeploy三行代码可完成AI模型在不同硬件上的部署,极大降低了AI模型部署难度和工作量。一行命令切换TensorRT、OpenVINO、Paddle Inference、Paddle Lite、ONNX Runtime、RKNN等不同推理后端和对应硬件。低门槛的推理引擎后端集成方案,平均一周时间即可完成任意硬件推理引擎的接入使用,解耦前后端架构设计,简单编译测试即可体验FastDeploy支持的AI模型。开发者可以根据模型API实现相应模型部署,也可以选择git clone一键获取150+热门AI模型的部署示例Demo,快速体验不同模型的推理部署。# PP-YOLOE的部署 import fastdeploy as fd import cv2 model = fd.vision.detection.PPYOLOE("model.pdmodel", "model.pdiparams", "infer_cfg.yml") im = cv2.imread("test.jpg") result = model.predict(im) # YOLOv7的部署 import fastdeploy as fd import cv2 model = fd.vision.detection.YOLOv7("model.onnx") im = cv2.imread("test.jpg") result = model.predict(im)
FastDeploy部署不同模型
# PP-YOLOE的部署 import fastdeploy as fd import cv2 option = fd.RuntimeOption() option.use_cpu() option.use_openvino_backend() # 一行命令切换使用 OpenVINO部署 model = fd.vision.detection.PPYOLOE("model.pdmodel", "model.pdiparams", "infer_cfg.yml", runtime_option=option) im = cv2.imread("test.jpg") result = model.predict(im)FastDeploy切换后端和硬件
极致高效:一键压缩提速,预处理加速,端到端性能优化,提升AI算法产业落地
FastDeploy在吸收TensorRT、OpenVINO、Paddle Inference、Paddle Lite、ONNX Runtime、RKNN等高性能推理优势的同时,通过端到端的推理优化解决了传统推理引擎仅关心模型推理速度的问题,提升整体推理速度和性能。集成自动压缩工具,在参数量大大减小的同时(精度几乎无损),推理速度大幅提升。使用CUDA加速优化预处理和后处理模块,将YOLO系列的模型推理加速整体从41ms优化到25ms。端到端的优化策略,彻底解决AI部署落地中的性能难题。更多性能优化,欢迎关注GitHub了解详情。https://github.com/PaddlePaddle/FastDeploy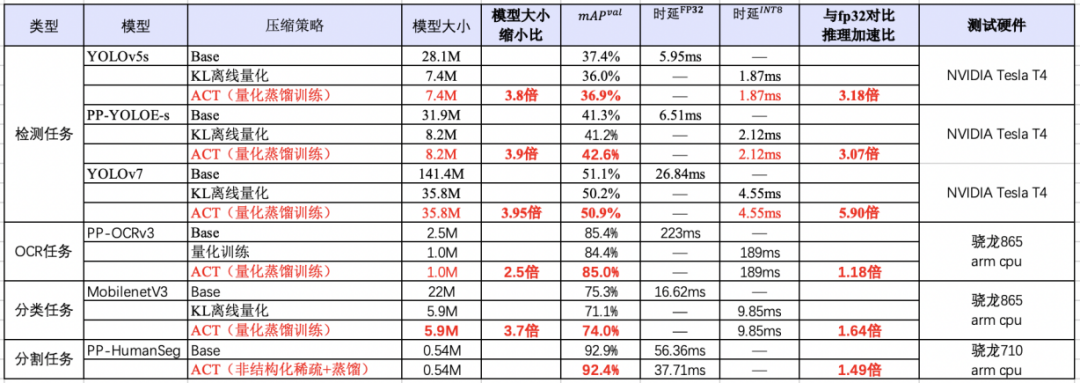
2
3步部署实战篇,抢先看
1
CPU/GPU部署实战(以YOLOv7为例)
安装FastDeploy部署包,下载部署示例(可选,也可以三行API实现部署代码)
pip install fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html git clone https://github.com/PaddlePaddle/FastDeploy.git cd examples/vision/detection/yolov7/python/
准备模型文件和测试图片
wget https://bj.bcebos.com/paddlehub/fastdeploy/yolov7.onnx wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
CPU/GPU推理模型
# CPU推理 python infer.py --model yolov7.onnx --image 000000014439.jpg --device cpu # GPU推理 python infer.py --model yolov7.onnx --image 000000014439.jpg --device gpu # GPU上使用TensorRT推理 python infer.py --model yolov7.onnx --image 000000014439.jpg --device gpu --use_trt True
推理结果示例:

2
Jetson部署实战(以YOLOv7为例)
安装FastDeploy部署包,配置环境变量
git clone https://github.com/PaddlePaddle/FastDeploy cd FastDeploy mkdir build && cd build cmake .. DBUILD_ON_JETSON=ON DENABLE_VISION=ON DCMAKE_INSTALL_PREFIX=${PWD}/install make j8 make install cd FastDeploy/build/install source fastdeploy_init.sh
准备模型文件和测试图片
wget https://bj.bcebos.com/paddlehub/fastdeploy/yolov7.onnx wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
编译推理模型
cd examples/vision/detection/yolov7/cpp cmake .. DFASTDEPLOY_INSTALL_DIR=${FASTDEPOLY_DIR} mkdir build && cd build make j # 使用TensorRT推理(当模型不支持TensorRT时会自动转成使用CPU推理) ./infer_demo yolov7s.onnx 000000014439.jpg 27s.onnx 000000014439.jpg 2
推理结果示例:

3
RK3588部署实战(以轻量化检测网络PicoDet为例)
安装FastDeploy部署包,下载部署示例(可选,也可以三行API实现部署代码)
# 参考编译文档,完成FastDeploy编译安装 # 参考文档链接:https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/build_and_install/rknpu2.md # 下载部署示例代码 git clone https://github.com/PaddlePaddle/FastDeploy.git cd examples/vision/detection/paddledetection/rknpu2/python
准备模型文件和测试图片
wget https://bj.bcebos.com/fastdeploy/models/rknn2/picodet_s_416_coco_npu.zip unzip -qo picodet_s_416_coco_npu.zip ## 下载Paddle静态图模型并解压 wget https://bj.bcebos.com/fastdeploy/models/rknn2/picodet_s_416_coco_npu.zip unzip -qo picodet_s_416_coco_npu.zip # 静态图转ONNX模型,注意,这里的save_file请和压缩包名对齐 paddle2onnx --model_dir picodet_s_416_coco_npu --model_filename model.pdmodel --params_filename model.pdiparams --save_file picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx --enable_dev_version True python -m paddle2onnx.optimize --input_model picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx --output_model picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx --input_shape_dict "{'image':[1,3,416,416]}" # ONNX模型转RKNN模型 # 转换模型,模型将生成在picodet_s_320_coco_lcnet_non_postprocess目录下 python tools/rknpu2/export.py --config_path tools/rknpu2/config/RK3588/picodet_s_416_coco_npu.yaml # 下载图片 wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
推理模型
python3 infer.py --model_file ./picodet _3588/picodet_3588.rknn --config_file ./picodet_3588/deploy.yaml --image images/000000014439.jpg 审核编辑 :李倩
-
AI
+关注
关注
87文章
30762浏览量
268905 -
人工智能
+关注
关注
1791文章
47207浏览量
238280 -
深度学习
+关注
关注
73文章
5500浏览量
121117
原文标题:模型部署不再难!低门槛AI部署工具FastDeploy开源!
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
企业AI模型部署攻略
AI模型部署和管理的关系
如何在STM32f4系列开发板上部署STM32Cube.AI,
企业AI模型部署怎么做
Arm推出GitHub平台AI工具,简化开发者AI应用开发部署流程
生成式AI工具作用
Llama 3 与开源AI模型的关系
真格基金宣布捐赠开源AI项目vLLM
NVIDIA RTX AI套件简化AI驱动的应用开发
降价潮背后:大模型落地门槛真的降了吗?

红帽发布RHEL AI开发者预览版,集成IBM Granite模型,简化AI开发流程
简单两步使用OpenVINO™搞定Qwen2的量化与部署任务

简单三步使用OpenVINO™搞定ChatGLM3的本地部署






 工商网监
工商网监
评论