 Meta开发AITemplate,大幅简化多GPU后端部署
Meta开发AITemplate,大幅简化多GPU后端部署
众所周知,GPU 在各种视觉、自然语言和多模态模型推理任务中都占据重要位置。然而,对于高性能 GPU 推理引擎,AI 从业者几乎没有选择权,必须使用一些平台专有的黑盒系统。这意味着如果要切换 GPU 供应商,就必须重新实现一遍部署系统。在生产环境中当涉及复杂的依赖状况时,这种灵活性的缺失使维护迭代成本变得更加高昂。
在 AI 产品落地过程中,经常需要模型快速迭代。尽管一些闭源系统(如 TensorRT)提供了一些定制化功能,但这些定制化功能完全不能满足需求。更进一步来说,这些闭源专有的解决方案,会使 debug 更加困难,对开发敏捷性造成影响。
针对这些业界难题,Meta AI 开发了拥有 NVIDIA GPU 和 AMD GPU 后端的统一推理引擎——AITemplate。
AITemplate 在 CNN、Transformer 和 Diffusion 模型上都能提供接近硬件上限的 TensorCore (NVIDIA GPU) 和 MatrixCore (AMD GPU) 性能。使用 AITemplate 后,在 NVIDIA GPU 上对比 PyTorch Eager 的提速最高能达到 12 倍,在 AMD GPU 上对比 PyTorch Eager 的提速达到 4 倍。
这意味着,当应用于超大规模集群时,AITemplate 能够节约的成本数额将是惊人的。
具体而言,AITemplate 是一个能把 AI 模型转换成高性能 C++ GPU 模板代码的 Python 框架。该框架在设计上专注于性能和简化系统。AITemplate 系统一共分为两层:前段部分进行图优化,后端部分针对目标 GPU 生成 C++ 模板代码。AITemplate 不依赖任何额外的库或 Runtime,如 cuBLAS、cudnn、rocBLAS、MIOpen、TensorRT、MIGraphX 等。任何 AITemplate 编译的模型都是自洽的。
AITemplate 中提供了大量性能提升创新,包括更先进的 GPU Kernel fusion,和一些专门针对 Transformer 的先进优化。这些优化极大提升了 NVIDIA TensorCore 和 AMD MatrixCore 的利用率。
目前,AITemplate 支持 NVIDIA A100 和 MI-200 系列 GPU,两种 GPU 都被广泛应用在科技公司、研究实验室和云计算提供商的数据中心。
团队对 AITemplate 进行了一系列测试。下图的测试展示了 AITemplate 和 PyTorch Eager 在 NVIDIA A100 上的主流模型中的加速比。
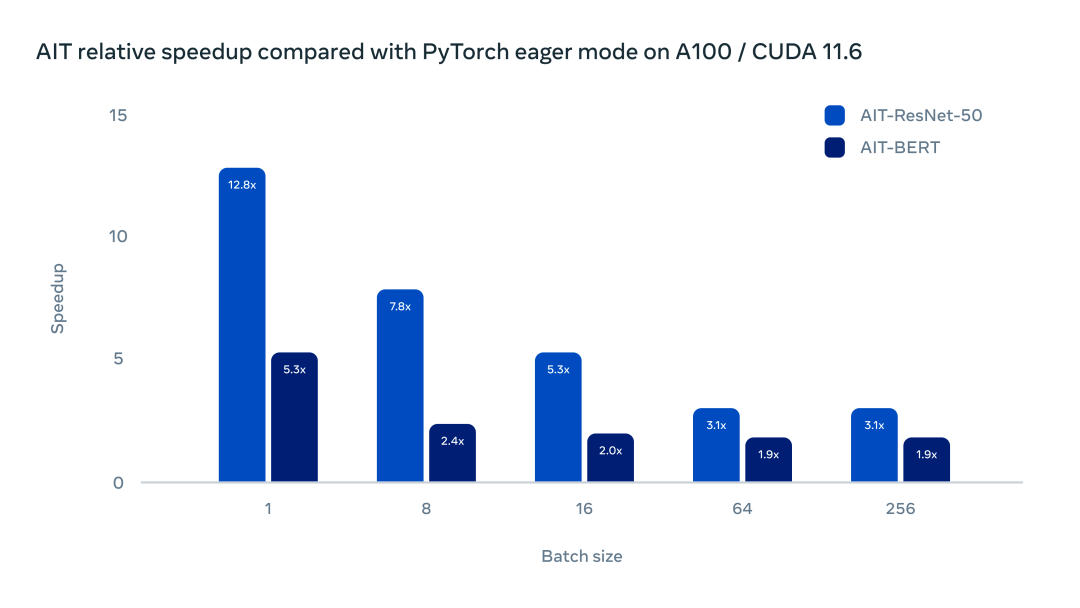
在带有 Cuda 11.6 的 Nvidia A100 上运行 BERT 和 ResNet-50,AITemplate 在 ResNet-50 中提供了 3 到 12 倍的加速,在 BERT 上提供了 2 到 5 倍的加速。
经测试,AITemplate 在 AMD MI250 GPU 上较 PyTorch Eager 也有较大的加速比。
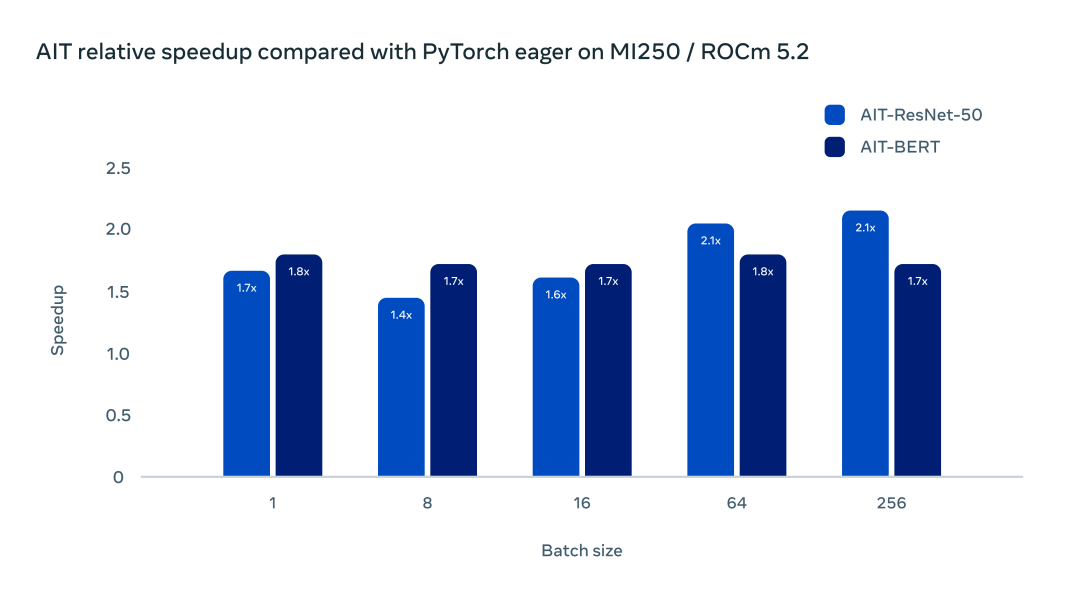
使用 ROCm 5.2 和 MI250 加速器,ResNet-50 和 BERT 的加速在 1.5-2 倍范围内。
AITemplate 的统一 GPU 后端支持,让深度学习开发者在最小开销的情况下,拥有了更多的硬件提供商选择。下图直观展示了 AITemplate 在 NVIDIA A100 GPU 和 AMD MI250 GPU 上的加速对比:
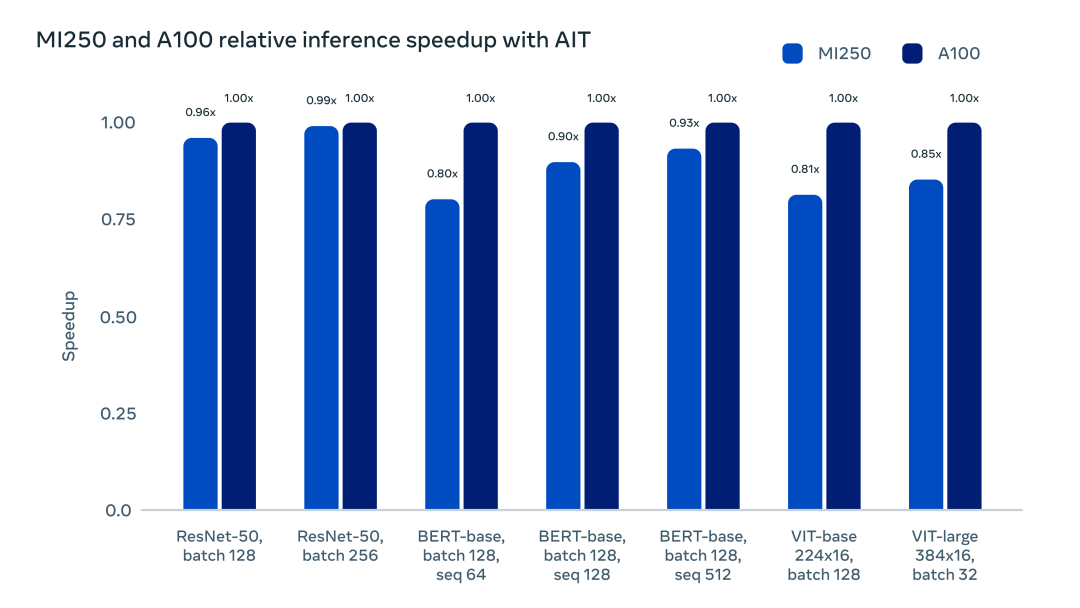
此外,AITemaplte 的部署较其他方案也更为简洁。由于 AI 模型被编译成了自洽的二进制文件并且不存在任何第三方库的依赖,任何被编译的二进制文件都能在相同硬件、CUDA 11/ ROCm 5 或者更新的软件环境中运行,也不用担心任何后向兼容问题。AITemplate 提供了开箱即用的模型样例,如 Vision Transformer、BERT、Stable Diffusion、ResNet 和 MaskRCNN,使得部署 PyTorch 模型更加简单。
AITemplate 的优化
AITemplate 提供了目前最先进的 GPU Kernel 融合威廉希尔官方网站 :支持纵向、水平和内存融合为一体的多维融合威廉希尔官方网站 。纵向融合将同一条链上的操作进行融合;水平融合将并行无依赖的操作进行融合;内存融合把所有内存移动操作和计算密集算子进行融合。
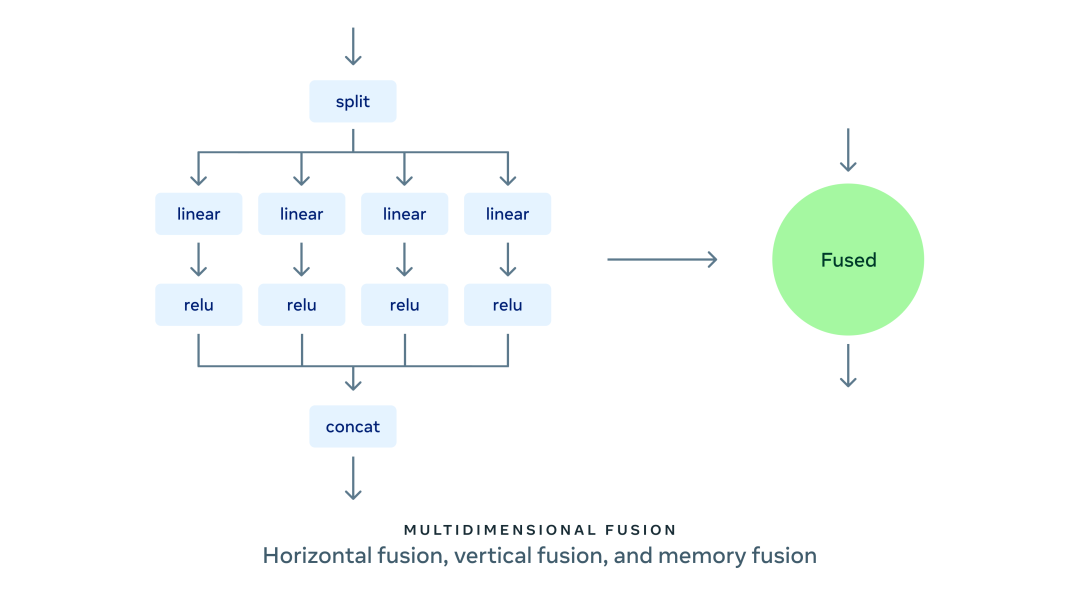
在水平融合中,AITemplate 目前可以把不同输入形状的矩阵乘法 (GEMM)、矩阵乘法和激活函数,以及 LayerNorm、LayerNorm 和激活函数进行融合。
在纵向融合中,AITemplate 支持超过传统标准的 Elementwise 融合,包括:
通过 CUTLASS 和 Composable Kernel 支持了矩阵和 Elementwise 算子融合;
为 Transformer 的 Multi-head Attention 提供了矩阵乘法和内存布局转置融合;
通过张量访问器对内存操作,如 split、slice、concatenate 等进行融合来消除内存搬运。
在标准的 Transformer Multi head attention 模块,目前 AITemplate 在 CUDA 平台使用了 Flash Attention,在 AMD 平台上使用了 Composable Kernel 提供的通用背靠背矩阵乘法融合。两种解决方案都能大幅减小内存带宽需求,在长序列问题中,提升更为明显。如下图所示:
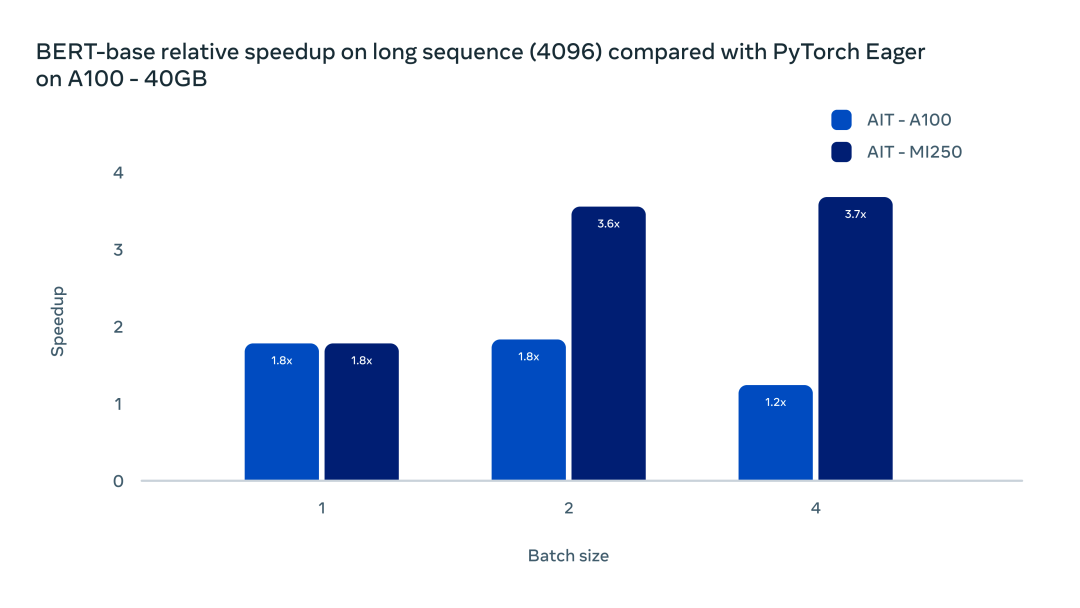
AITemplate 与 Composable Kernel 的广义背靠背融合显着提高了长序列 Transformer 的推理效率。在 batch size 为 1 时,使用 AITemplate 的两张 GPU 均比原生框架加速了 80%。
开发 AITemplate
AITemplate 有两层模版系统:第一层在 Python 中使用 Jinja2 模板,第二层在 GPU TensorCore/MatrixCore 中使用 C++ 模板(NVIDIA GPU 上使用 CUTLASS,AMD GPU 上使用 Composable Kernel)。AITemplate 在 Python 中找到性能最优的 GPU 模板参数,再通过 Jinja2 渲染出最终的 C++ 代码。
在代码生成后,就能使用 GPU C++ 编译器(NVIDIA 平台上的 NVCC 和 AMD 平台上的 HIPCC)编译出最终的二进制代码。AITemplate 提供了一套类似于 PyTorch 的前端,方便用户直接将模型转换到 AITemplate 而不是通过多层 IR 转换。
总体来看,AITemplate 对当前一代及下一代 NVIDIA GPU 和 AMD GPU 提供了 SOTA 性能并大幅简化了系统复杂度。
Meta 表示,这只是创建高性能多平台推理引擎旅程的开始:「我们正在积极扩展 AITemplate 的完全动态输入支持。我们也有计划推广 AITemplate 到其他平台,例如 Apple 的 M 系列 GPU,以及来自其他供应商的 CPU 等等。」
此外,AITemplate 团队也正在开发自动 PyTorch 模型转换系统,使其成为开箱即用的 PyTorch 部署方案。「AITemplate 对支持 ONNX 和 Open-XLA 也持开放态度。我们希望能构建一个更为绿色高效的 AI 推理系统,能拥有更高的性能,更强的灵活性和更多的后端选择。」团队表示。
审核编辑:郭婷
-
gpu
+关注
关注
28文章
4733浏览量
128911 -
AI
+关注
关注
87文章
30805浏览量
268942
原文标题:推理速度数倍提升,大幅简化多GPU后端部署:Meta发布全新推理引擎AITemplate
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Meta发布新AI模型Meta Motivo,旨在提升元宇宙体验
Arm推出GitHub平台AI工具,简化开发者AI应用开发部署流程
亚马逊云科技上线Meta Llama 3.2模型
Meta发布多模态LLAMA 3.2人工智能模型
Meta不会在欧盟提供新的多模态AI模型
NVIDIA全面加快Meta Llama 3的推理速度
高通与Meta合作优化Meta Llama 3,实现终端侧运行
Meta第二代自研AI芯片出世,性能提升三倍以上

FPGA在深度学习应用中或将取代GPU
模拟后端是什么意思
Meta将于今年在数据中心部署新款定制AI芯片
Meta计划今年部署自研定制芯片,以加速AI研发
扎克伯格的Meta斥资数十亿美元购买35万块Nvidia H100 GPU






 工商网监
工商网监
评论