 数据中心手动操作关闭复制并开始使用
数据中心手动操作关闭复制并开始使用
在数据中心A中,ArangoDB集群A照常运行,不修改其代码库和API,并提供其正常负载。同样,在数据中心B中,部署了第二个ArangoDB集群B,但最初处于空闲状态。
在这两个数据中心中,我们都部署了Kafka消息代理,这是一个标准的高性能容错排队系统,能够在其消息队列中缓冲大量数据。在卡夫卡中,单个队列被称为“主题”。这些主题可以从其他数据中心使用。卡夫卡有一定的保证,因此在网络问题、个别中断等情况下,不会丢失任何消息,远程数据中心始终保持一致状态。
此外,在每个数据中心中,都有几个名为“ArangoDBSyncMaster”的程序实例。在每个数据中心,同步主机选择一个负责人,负责人与另一个数据中心的同步主机对话,以组织复制。“组织”在这里意味着它计划了必须在两个数据中心中执行的单个任务,以使复制得以进行。从本质上讲,我们必须复制元信息,如数据库、集合和用户的存在,以及切分集合中的实际数据。
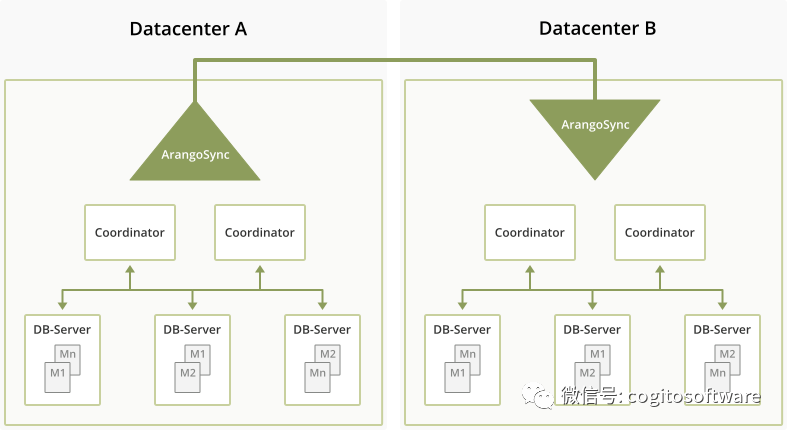
在每个数据中心,领先的SyncMaster领导一小群SyncWorker,他们执行实际的复制任务。例如,对于集合的每个碎片,数据中心a中有一个“发送碎片”任务,数据中心B中有一项“接收碎片”任务。所有这些碎片都由SyncMaster分配给某个SyncWorker。
这些任务负责初始增量同步阶段(运行我们在ArangoDB中已有的现有分片同步协议),以及稍后的更新阶段,在更新阶段中,对分片的所有更新都复制到其他数据中心(在数据中心A中使用WAL-tailing)。
数据流如下:它从ArangoDB集群的某个数据库服务器开始,到达数据中心A中的一个SyncWorker,然后进入数据中心A的Kafka。从那里,它将被数据中心B的SyncWorkers消耗,后者将其写入数据中心B中的协调器。显然,有一些控制消息朝相反的方向流动。这些控制消息将由数据中心A从数据中心B中的Kafka服务器中提取。
这对管理员来说都意味着,在初始部署后,只需告诉数据中心B中的SyncMaster它应该开始遵循数据中心A中的群集A,就可以用一个命令设置异步复制。从那时起,一切都是完全自动的,所有数据库、集合、用户和权限都会自动复制到另一个数据中心。显然,有监控和配置设施,但本质上就是这样。
局限性
这是实现多数据中心意识的第一步,因此自然会有局限性。首先,复制是异步的,因此它总是落后于数据中心a中的实际事件。通常情况下,由于良好的连接性和小于跨数据中心链路容量的写入速率,这种延迟非常小。然而,应该注意,在突然停止复制并手动切换到集群B的情况下,一些最近编写的更新可能会丢失。
整个设置是手动配置的,在两个数据中心之间工作。在此阶段不允许写入副本群集。然而,副本群集可以同时作为另一个数据中心的源,并且源群集可以具有多个副本。也就是说,您可以形成数据中心树。
最后,到目前为止,关闭复制并开始使用复制副本是一种手动操作,需要管理员做出决定和采取行动。
-
服务器
+关注
关注
12文章
9144浏览量
85387 -
数据中心
+关注
关注
16文章
4774浏览量
72112 -
数据库
+关注
关注
7文章
3799浏览量
64376
原文标题:ArangoDB Enterprise—数据中心到数据中心的复制(下)
文章出处:【微信号:哲想软件,微信公众号:哲想软件】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
数据中心子系统的组成
数据中心的健康检查(电气篇)
走向绿色数据中心的7种手段
数据中心的建设也看重风水
数据中心光互联解决方案
未来数据中心与光模块发展假设
数据中心太耗电怎么办
数据中心是什么
PUE指标能准确衡量数据中心能效吗?
什么是数据中心
数据中心网络进行监控和管理如何操作
数据中心到数据中心的复制流程





 工商网监
工商网监
评论