 基于使用对比学习和条件变分自编码器的新颖框架ADS-Cap
基于使用对比学习和条件变分自编码器的新颖框架ADS-Cap
01
研究动机
在本文中,我们研究了图像描述(Image Captioning)领域一个新兴的问题——图像风格化描述(Stylized Image Captioning)。随着深度学习的发展,自动图像描述吸引了计算机视觉和自然语言处理领域研究者们的广泛关注。现在的图像描述模型可以为图像生成准确的文本表述,但在日常生活中,人们在表达想法的同时通常还会带有自己的情感或者风格,为此研究者们提出了图像风格化描述任务,希望模型在准确描述视觉内容的同时也能在描述中融入指定的语言风格。例如对于图1展示的图片,下面列出了传统的事实性描述和四种风格带有风格的描述,即幽默的、浪漫的、积极的和消极的,其中画红线的部分是体现风格的部分。图像风格化描述也有许多下游应用,例如在聊天机器人中生成更吸引用户的图像描述、以及在社交媒体上通过有吸引力的描述启发用户。
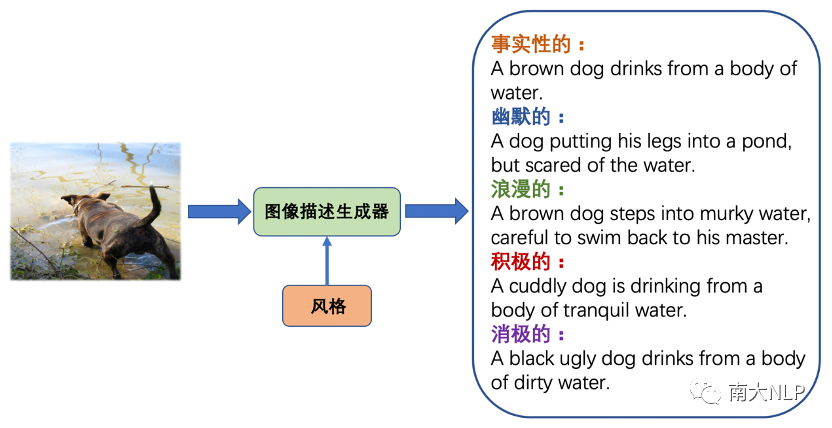 图1图像风格化描述(Stylized Image Captioning)任务
图1图像风格化描述(Stylized Image Captioning)任务
该任务的一个困难在于,收集图片和对应人工标注的风格化描述是代价高昂的,为此我们希望能够仅利用非成对的风格文本语料库,让图像描述模型在这些风格文本上自动学习语言风格知识。因此在训练时,我们提供事实性的图像-描述对数据集以及不包含图片的非成对的风格文本语料库,希望模型通过前者学习如何准确描述图像内容,通过后者学习如何在描述中融入指定语言风格。
在上述设定下,该任务的一个关键问题是:如何高效利用成对的事实性数据和非成对的风格数据。多数以往工作遵循传统的方法论:首先在大规模的成对事实性数据上预训练一个编码器-解码器模型,之后在非成对的风格数据上,以语言模型的方式微调解码器,例如StyleNet[1]和MSCap[2]。然而,我们认为在非成对风格数据上按照语言模型微调会导致模型过于关注语言风格,而忽略了生成描述和图像内容的一致性,因为在微调时解码器完全与视觉输入无关。这最终导致了图像风格化描述模型无法生成切合图像内容的描述。MemCap[3]提出利用场景图作为中间媒介,将成对和非成对数据的训练过程统一为根据场景图生成描述;然而,由于不同模态间的差异,文本和图像抽取的场景图依然是不一致的,这导致模型在测试时仍然无法很好地兼顾描述图像内容的准确性和融入语言风格。
另一个重要问题是,目前的工作基本上忽略了生成风格表达的多样性。如图2所示,对于三张相似场景的图片,基线模型生成了完全相同的风格短语“to meet his lover”,而当为一张图片生成多个风格化描述时,基线模型生成的风格表述也缺乏变化。这样的结果极大偏离了图像风格化描述任务的初衷:我们希望得到生动多样的描述,而不仅仅是几个固定的表达。我们认为造成这一问题的原因是风格语料规模较小,使得传统的编码器-解码器模型难以生成多样的风格模式。
 图2:传统编码器-解码器框架难以建模多样化的风格表达
图2:传统编码器-解码器框架难以建模多样化的风格表达
为了解决上面提到的两方面问题,我们提出了全新的ADS-Cap框架:通过对比学习对齐图像文本两种模态,使模型能够将成对数据和非成对数据统一为条件生成的模式,使得模型能够在准确描述图像内容的同时融入指定语言风格;通过条件变分自编码器架构,引导隐空间记忆多种多样的风格表达,有效增强生成时的多样性。
02
贡献
1.我们提出了一个新颖的使用对比学习和条件变分自编码器的图像风格化描述框架ADS-Cap。
2.当使用非成对风格文本语料库训练时,对比学习模块有效地提升了生成描述与图像内容的一致性。
3.条件变分自编码器框架通过在隐空间中记忆风格表达并在测试时采样,显著提升了图像风格化描述生成的多样性。
4.在两个benchmark图像风格化描述数据集上的实验结果表明,我们的方法在准确性和多样性上达到SOTA。
03
解决方案
整体模型架构如下图3所示,主要由一个条件变分自编码器框架和一个对比学习模块组成。蓝色部分代表模型的输入和输出,黄色部分代表模型的可学习参数,红色部分是我们模型编码风格表达的隐空间。
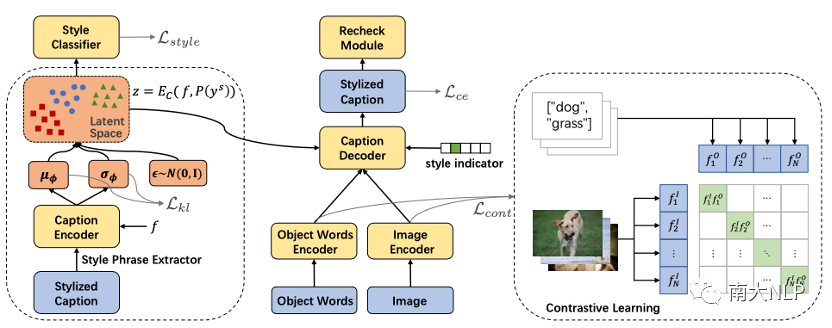 图3:ADS-Cap框架示意图
图3:ADS-Cap框架示意图
3.1对比学习
我们首先通过一个目标对象词词表(来自VG数据集),从非成对数据的描述中抽取目标对象词,这样我们就能够将成对数据和非成对数据的训练统一为条件生成的模式:对于成对的事实性数据,我们根据图像特征生成事实性的描述;对于非成对的风格数据,我们根据目标对象词生成风格化的描述。然而,在测试时,我们需要根据图像特征生成风格化的描述,如下图4黄色箭头所示。为此我们的解决方案是,使用对比学习将图像特征和目标对象词特征编码到同一个共享的多模态特征空间,从而对于解码器来说,根据图像生成和根据目标对象词生成将不再有差异。
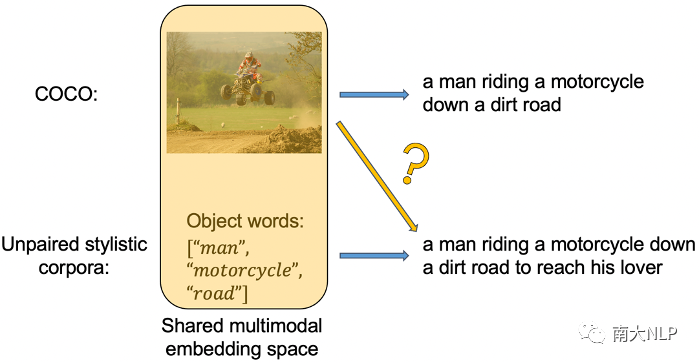 图4:使用非成对风格文本语料库带来的问题
图4:使用非成对风格文本语料库带来的问题
具体而言,对比学习损失最大化一个batch内匹配样本间的余弦相似度,同时最小化不匹配样本间的余弦相似度[4],从而对齐图像和目标对象词两种模态的特征到同一个共享的多模态特征空间中。
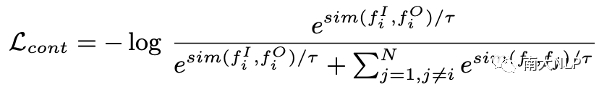
3.2条件变分自编码器框架
为了提高生成描述的多样性,我们使用条件变分自编码器(CVAE)代替了传统的编码器-解码器架构,主要是因为CVAE在许多生成任务上多样性表现较好,而且对于图像风格化描述任务来说,可以利用隐空间自动记忆多种多样的风格表达,从而在测试时在隐空间不同区域采样就可以生成带有不同风格短语的描述。如图5所示,CVAE的编码器将样本的风格表达编码到隐变量,解码器通过该隐变量辅助尝试还原输入样本。之后,CVAE的训练原理也就是KL散度损失和重建损失使得各种各样的风格表达能够均匀地分布在隐空间中。
除此之外,我们在隐变量上增加了一个风格分类器,以隐变量为输入,预测该隐变量对应样本的风格。这样一个辅助损失有两方面好处,一个是可以引导隐空间编码与风格相关的信息;另外这个单层神经网络+softmax的分类器实际上也将整个隐空间按风格划分了,这样在测试时,我们就可以通过拒绝采样得到我们想要风格的隐变量。
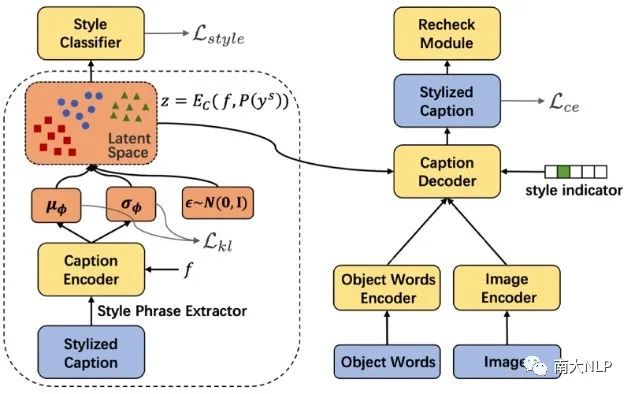 图5:条件变分自编码器框架及风格分类器
图5:条件变分自编码器框架及风格分类器
04
实验
我们在图像风格化描述的两个benchmark数据集FlickrStyle10K[1]和SentiCap[5]上进行实验。前者包含幽默和浪漫两种风格,各7000张图片和对应的风格化描述;后者包含积极和消极两种风格,共2360张图片以及9513个风格化描述。数据集划分以及实验设定上,我们与MSCap[2]和MemCap[3]保持一致。
4.1内容准确性&风格准确性
在性能方面,我们首先比较了之前工作采用的内容准确率和风格准确率。其中内容准确率采用Bleu、CIDEr这类计算和参考句子间n元组重复度的指标,风格准确率则使用生成句子的困惑度ppl、以及一个预训练好的风格判别器给出的风格准确率cls。可以看到如表1所示,我们的方法相比之前工作在几乎所有指标上取得了显著的提升,特别是在FlickrStyle这个风格更复杂的数据集上。这也侧面证实了以往工作忽略了生成描述和图像内容一致性这个问题,而我们的方法能够在融入语言风格的同时保持和图像内容的一致性。
表1:内容准确性和风格准确性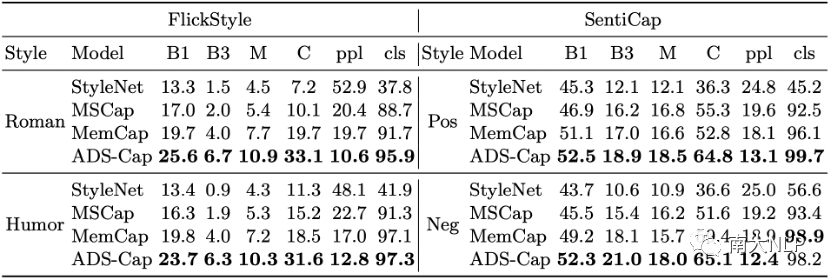
4.2多样性
我们比较将我们的方法与编码器-解码器基线模型在两类多样性上进行了比较。图6展示了两类多样性以及我们方法的效果。
 图6:两类多样性及样例展示
图6:两类多样性及样例展示
第一类是图像间的多样性(Diversity across Images),也就是我们希望同一场景下不同图像生成的风格化描述应该是多样的。为此我们考虑了:1.唯一性,不同的风格短语战全部风格短语的比例;2.均匀性,风格词概率分布的熵(下式)。从下表2结果中可以看到,在七种典型场景下(各种人物以及动物),我们的CVAE模型均显著高于编码器-解码器基线,但距离人类的表现还有不少距离。
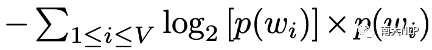
表2:相似场景下风格化描述多样性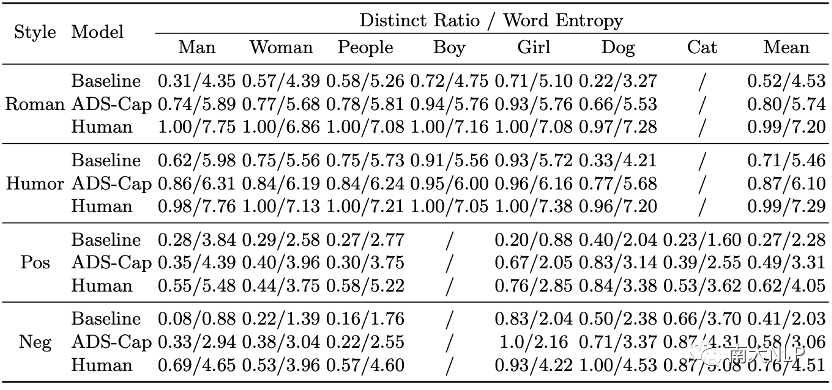
第二类是经典的为一张图像生成多个风格化描述的多样性。为此我们考虑了图像描述领域中量此类多样性的两个指标:Distinct和Div-n,前者计算不同的风格短语的比例,后者计算不同的n元组的比例。从表2中可以看到,我们的方法同样优于基线模型。
表3:为一张图像生成多个风格化描述的多样性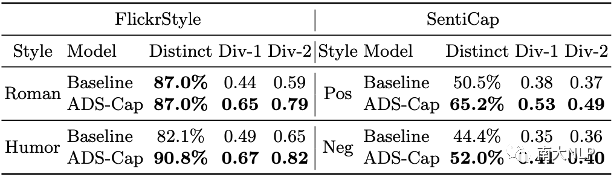
4.3效果分析
为了展示分析对比学习和条件变分自编码器框架的效果,我们进行了一些可视化。
图7给出了使用对比学习前后的特征空间分析,绿色代表的是目标对象词特征,红色是图像特征。可以看到对比学习很好地对齐了两类特征(例如狗的目标对象词特征和对应图像特征十分相近),从而成功统一了成对事实性数据和非成对风格数据的训练。
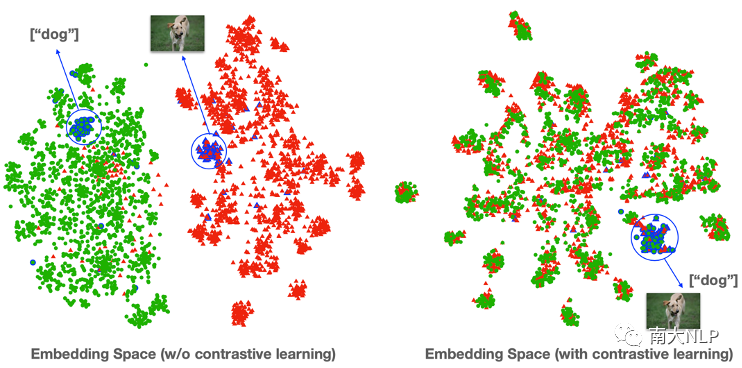 图7:对比学习效果
图7:对比学习效果
如图8所示,训练好的CVAE隐空间实际上被按照风格划分为不同的区域,并且在每个区域中编码了多种多样的风格表达,例如对于浪漫的风格,这里展示了其中几个点对应的风格表达,有enjoying the beauty of nature、with full joy等等;因此,测试时在每个区域中采样即可得到多样化的风格描述。
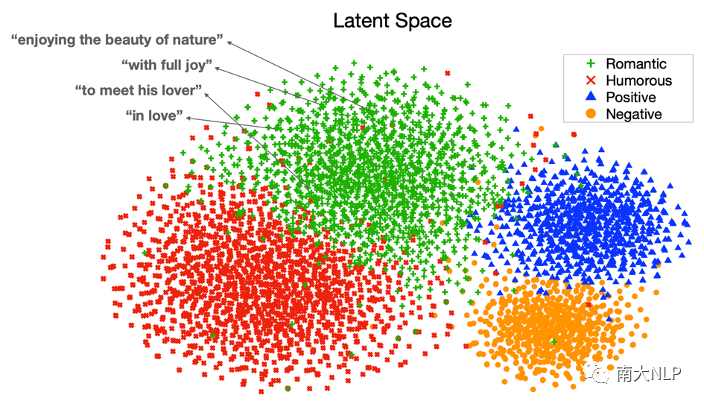 图8:条件变分自编码器隐空间
图8:条件变分自编码器隐空间
05
总结
本工作为图像风格化描述任务提出了一个使用对比学习和条件变分自编码器的新颖框架ADS-Cap。我们的模型能够高效地利用非成对风格文本语料库训练,并能够生成视觉内容准确、文本风格可控且风格表达多样的图像风格化描述。在两个图像风格化描述benchmark上的实验证明了我们方法的有效性。
-
编码器
+关注
关注
45文章
3640浏览量
134466 -
模型
+关注
关注
1文章
3238浏览量
48824 -
自然语言
+关注
关注
1文章
288浏览量
13348
原文标题:NLPCC'22 | 一种兼具准确性和多样性的图像风格化描述生成框架
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于变分自编码器的异常小区检测
是什么让变分自编码器成为如此成功的多媒体生成工具呢?

自编码器是什么?有什么用
自编码器介绍
稀疏自编码器及TensorFlow实现详解
基于变分自编码器的海面舰船轨迹预测算法
自编码器基础理论与实现方法、应用综述
一种多通道自编码器深度学习的入侵检测方法

一种基于变分自编码器的人脸图像修复方法

基于变分自编码器的网络表示学习方法
结合深度学习的自编码器端到端物理层优化方案
自编码器神经网络应用及实验综述
基于交叉熵损失函欻的深度自编码器诊断模型
自编码器 AE(AutoEncoder)程序






 工商网监
工商网监
评论