 摘要模型理解或捕获输入文本的要点
摘要模型理解或捕获输入文本的要点
Abstract & Intro
尽管基于预训练的语言模型的摘要取得了成功,但一个尚未解决的问题是生成的摘要并不总是忠实于输入文档。造成不忠实问题的原因可能有两个: (1)摘要模型未能理解或捕获输入文本的要点; (2)模型过度依赖语言模型,生成流畅但不充分的单词。 在本文研究中,提出了一个忠实增强摘要模型(FES),旨在解决这两个问题,提高抽象摘要的忠实度。对于第一个问题,本文使用问答(QA)来检查编码器是否完全掌握输入文档,并能够回答关于输入中的关键信息的问题。QA 对适当输入词的注意也可以用来规定解码器应该如何处理输入。 对于第二个问题,本文引入了一个定义在语言和总结模型之间的差异上的最大边际损失,目的是防止语言模型的过度自信。在两个基准总结数据集(CNN/DM 和 XSum)上的大量实验表明,本文的模型明显优于强基准。事实一致性的评估也表明,本文的模型生成的摘要比基线更可靠。
本文的主要贡献如下: 1. 提出了一种信度增强摘要模型,从编码器端和解码器端都缓解了不信度问题。 2. 提出了一个多任务框架,通过自动 QA 任务来提高摘要性能。还提出了一个最大边际损失来控制 LM 的过度自信问题。 3. 实验结果表明,与基准数据集上的最新基线相比,本文提出的方法带来了实质性的改进,并可以提高生成摘要的忠实度。
Model Architecture
本文从三个方面实现了信度的提高: (1)多任务编码器。它通过检查辅助 QA 任务的编码文档表示的质量,提高了对输入文档的语义理解。编码的表示因此捕获关键输入,以便做出忠实的总结。 (2)QA 注意增强解码器。来自多任务编码器的注意使解码器与编码器对齐,以便解码器能够获取更准确的输入信息以生成摘要。 (3)Max-margin 损失。这是一个与代损耗正交的损耗。它测量 LM 的准确性,防止它在生成过程中过度自信。
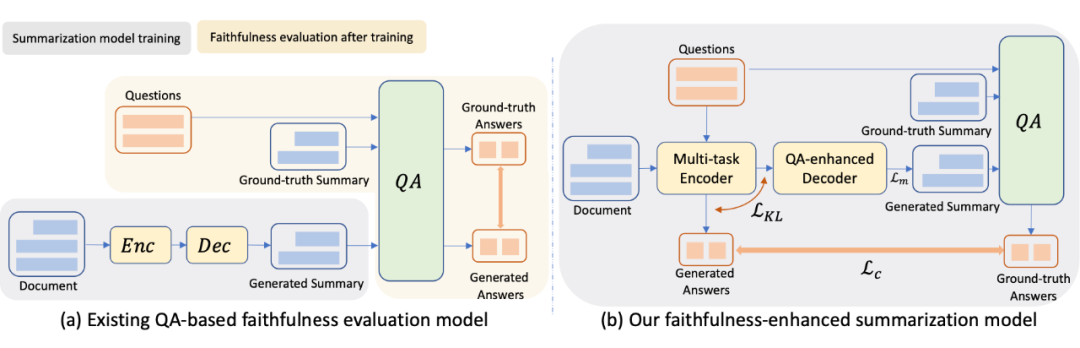
2.1 Multi-task Encoder
多任务编码器设计用于对输入文档进行编码,以便在集成训练过程中进行摘要和问题回答,如图 1(b)所示。这与之前的工作不同,之前的工作是在后期阶段使用 QA 来评估生成摘要的忠实度,如图 1(a)所示。本文让 QA 更接近编码器,而不是把它留给后生成的总结,并让编码器接受训练,同时完成 QA 和总结任务。在多任务编码器的综合训练中,除了摘要生成质量外,还将忠实度作为优化目标,答案是来自文档的关键实体,因此 QA 对关注输入中的关键信息。 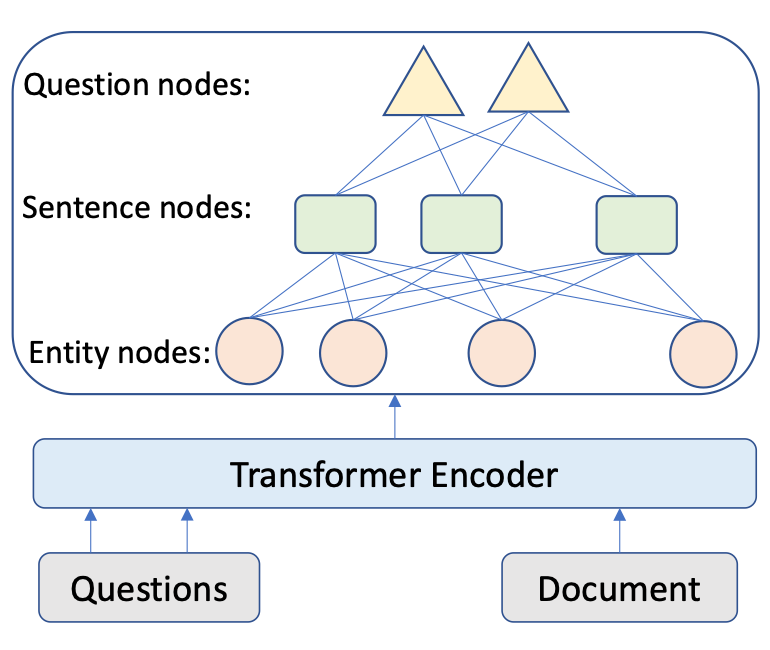
如图 2 所示,我们首先应用经典的 Transformer 架构,获得文档和问题的 token 表示, 和 ,然后设计编码器,从实体层和句子层理解问题和输入文档问题。
Encoding at Multi-level Granularity 本文通过在不同粒度级别组织表示学习来构建编码器。我们使用实体作为基本语义单位,因为它们包含贯穿全文的紧凑而突出的信息,而阅读理解题的重点是实体。由于问题通常很短,本文为每个问题创建一个节点。本文将双向边从问题添加到句子节点,从句子添加到实体节点。这些节点作为句与句之间的中介,丰富了句与句之间的关系。由于初始的有向边不足以学习反向信息,本文在前面的工作的基础上,在图中添加了反向边和自环边。 在构造了具有节点特征的图之后,使用图注意网络来更新语义节点的表示,图注意层(GAT)设计如下:
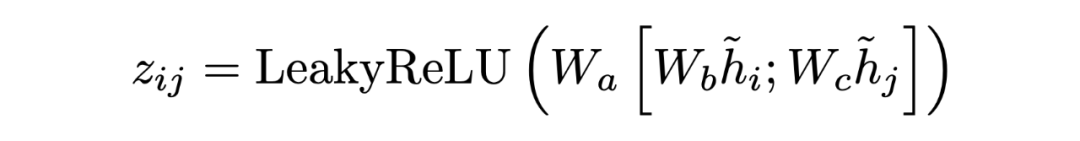
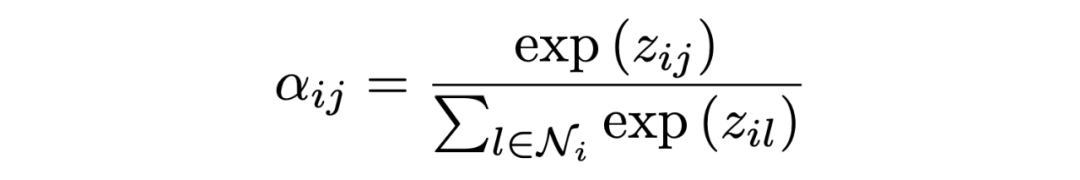
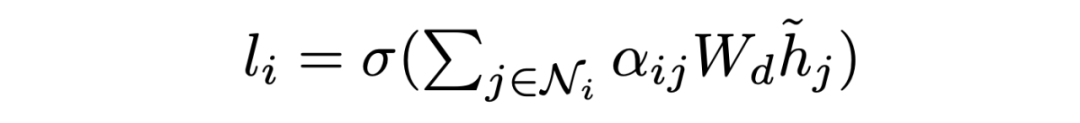
其中 是输入节点的隐藏状态,其中 N 是节点 i 的相邻节点集, 是可训练权值, 是 和 之间的注意权值。输出实体特征矩阵、句子特征矩阵和问题矩阵:。 Answer Selector for the QA task 在融合来自问题和文档的信息之后,可以从文档中选择实体作为问题的答案。具体来说,本文在问题和图中的实体之间应用了多头交叉注意以获得识别问题的实体表示:=MHAtt(),i 是问题索引。本文采用前馈网络(FFN)生成实体提取概率 ,QA 的目标是最大限度地提高所有基本事实实体标签的可能性: 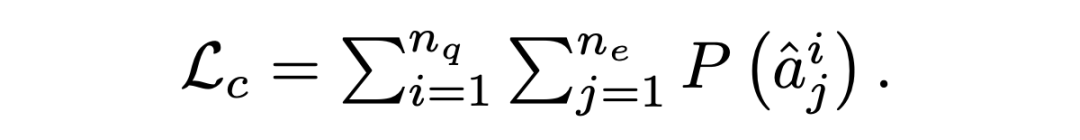
2.2 QA Attention-enhanced Decoder
一个忠实的解码器需要注意并从编码器中获取重要的内容,而不是混合输入。QA 对关键实体的关注可以被视为重要信号,表明哪些实体应该包含在摘要中。因此,本文提出了一个由 QA 关注增强的摘要生成器。一般来说,以实体为中介的解码器状态关注编码器状态,其中实体级别的注意由 QA 注意指导。
具体来说,对于每一层,在第 t 步解码时,我们对 masked 摘要嵌入矩阵E进行自注意,得到 。基于 ,我们计算实体的交叉注意分数 。 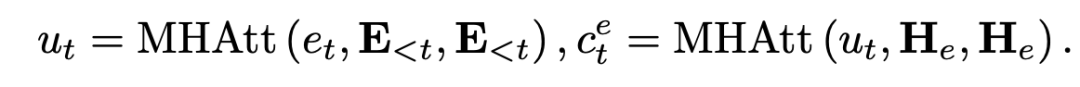 实际上,第一个注意层捕获已解码序列的上下文特征,而第二层则包含 中的实体信息.我们最小化在第 t 步的实体上的 QA 注意 Ai 和摘要注意 Et 之间的 KL 散度,以帮助总结模型了解哪些实体是重要的:
实际上,第一个注意层捕获已解码序列的上下文特征,而第二层则包含 中的实体信息.我们最小化在第 t 步的实体上的 QA 注意 Ai 和摘要注意 Et 之间的 KL 散度,以帮助总结模型了解哪些实体是重要的:
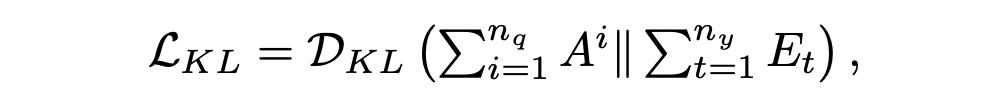
然后,通过在源词序列 Hw 和 上应用另一个 MHAtt 层,我们使用实体级注意来指导与关键实体相关的源标记的选择:
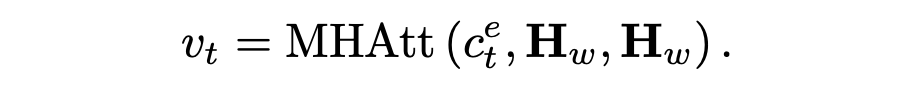
该上下文向量 vt 被视为从各种来源总结的显著内容,被发送到前馈网络以生成目标词汇表的分布,即 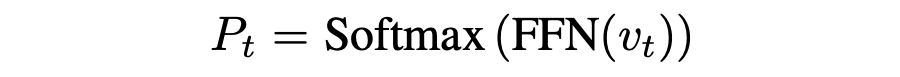 通过优化预测目标词的负对数似然目标函数,更新所有可学习参数
通过优化预测目标词的负对数似然目标函数,更新所有可学习参数 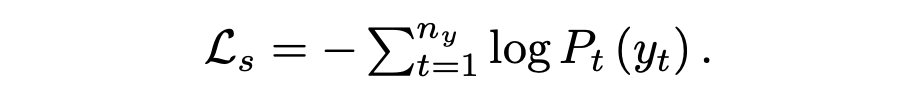
2.3 Max-margin Loss
信息不充分的解码器会忽略一些源段,更像是一个开放的 LM,因此容易产生外部错误。受信度增强机器翻译工作的启发,本文在摘要任务中引入了一个 max-margin loss,以使摘要模型的每个 token 与 LM 的预测概率的差值最大化,如图 3 所示,这抑制了摘要器产生常见但不忠实的单词的趋势。 
▲ 当 LM 不够准确时,本文的模型可以通过最大边际损失防止 LM 的过度自信,预测出正确的目标词,而基线模型则不能。
具体来说,我们首先将摘要模型和 LM 之间的差值定义为预测概率的差值:
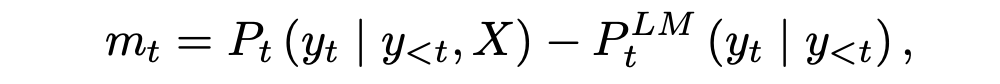
其中 X 为输入文档, 表示 LM 的第 t 个令牌的预测概率。如果 mt 很大,那么总结模型显然比 LM 好。当 mt 很小的时候,有两种可能。一是 LM 模型和总结模型都有很好的性能,因此预测的概率应该是相似的。另一种可能是 LM 不够好,但过于自信,这会导致总结器性能不佳。LM 够好,但过于自信,这会导致总结器性能不佳。 本文给出了最大边际损失 Lm,它在边际上增加了一个系数
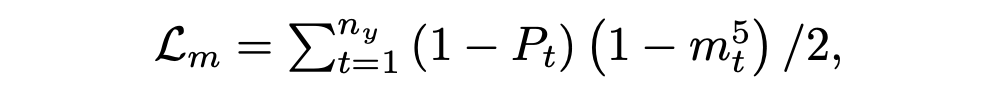
当 Pt 较大时,摘要模型可以很好地学习,不需要过多关注 mt。这体现在 mt 的小系数(1−Pt)上。另一方面,当 Pt 较小时,意味着摘要器需要更好地优化,大系数(1−Pt)使模型能够从边际信息中学习。
、、、 这四种损耗是正交的,可以组合使用来提高信度。
Experiment
3.1 Dataset
本文在两个公共数据集(CNN/DM 和 XSum)上演示了方法的有效性,这两个公共数据集在以前的摘要工作中被广泛使用。这两个数据集都基于新闻,由大量事件、实体和关系组成,可用于测试摘要模型的事实一致性。
本文的摘要模型伴随着一个 QA 任务。因此,使用由 QuestEval 工具为每个用例预先构建 QA 对。
3.2 Result
Automatic Evaluation
 ▲ QE 加权 F1 分数
▲ QE 加权 F1 分数
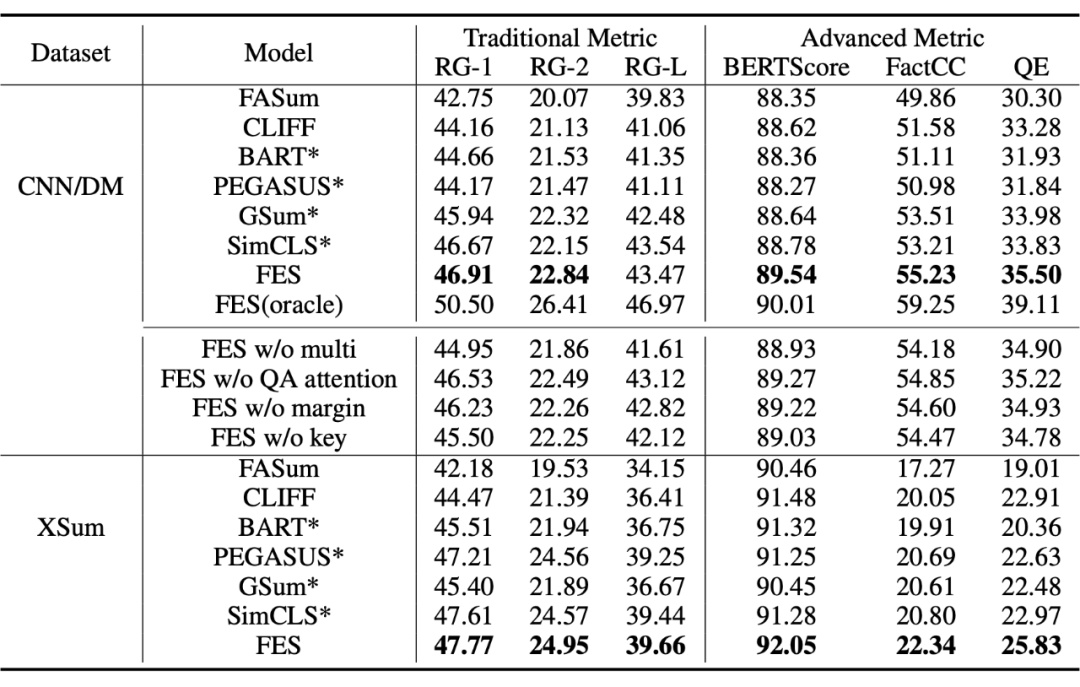
当使用 oracle QA(黄金问答)对评估 QA 任务带来的效益的上限时,我们还展示了我们的模型在测试数据集上的性能。我们可以看到,oracle 显著地提高了性能,性能最好的模型达到了50.50 的 ROUGE-1 评分。结果表明:1)如果有较好的 QA 对,模型性能有进一步提高的潜力;2)辅助 QA 任务确实对模型有帮助。
Human Evaluation

▲ 在 CNN/DM 数据集上,比 BART 差、持平或更好的摘要的百分比。XSum 数据集上比 PEGASUS 差、与 PEGASUS 持平或优于 PEGASUS 的摘要的百分比
Ablation Study
1. 没有多任务框架,各项指标都有所下降,表明在使用 QA 多任务时,编码器确实增强了学习更全面表示的能力。
2. QA 注意指导被移除后,QE 分数下降了 0.28。这表明,将 QA 注意与重要实体的摘要注意对齐,可以帮助模型从输入中捕获要点信息,而将这种损失限制在有限部分实体上,可以引导解码器从输入中获取有意义的内容。
3. 除去最大边际损失后,FactCC 评分下降了 0.63。这表明,防止 LM 过度自信有助于提高信任度。
4. 最后,当使用随机 QA 对作为引导时,FES 的性能有所下降,但大大优于 BART。这表明,加强对文档的理解是有帮助的,即使它并不总是与关键信息相关。但是,通过对关键实体提出问题,可以进一步提高性能。
The Number of QA pairs
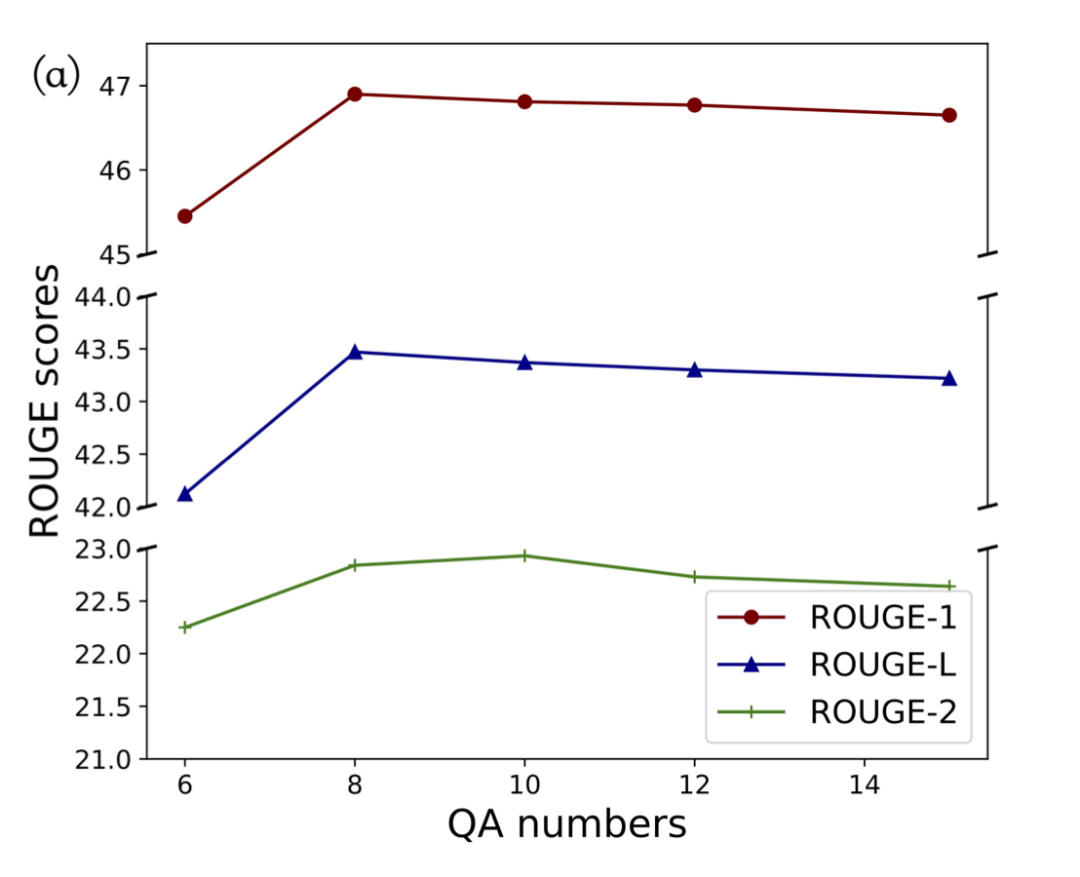 首先看到 ROUGE 分数随着 QA 对的数量而增加。达到 8 之后,这种改善开始消失。一个可能的原因是,答案不再关注文档中的重要信息。注意,FES 的性能在 8-15 个 QA 对范围内保持在较高水平,证明了 FES 的有效性和鲁棒性。最后,我们选择在模型中默认包含 8 个 QA 对。
首先看到 ROUGE 分数随着 QA 对的数量而增加。达到 8 之后,这种改善开始消失。一个可能的原因是,答案不再关注文档中的重要信息。注意,FES 的性能在 8-15 个 QA 对范围内保持在较高水平,证明了 FES 的有效性和鲁棒性。最后,我们选择在模型中默认包含 8 个 QA 对。
Margin between FES and the LM
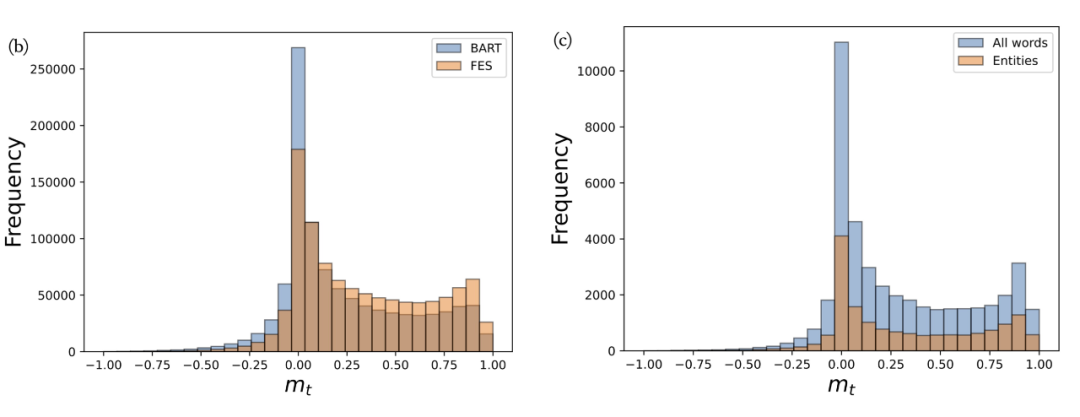
▲ 负 mt 为过度自信,mt 为 0 和 1 时模型准确 首先,图(b)中 BART 仍然有很多 mt 为负的 token,并且有大量 mt 在 0 附近,这说明 LM 对于很多令牌可能是过度自信的。与 BART 相比,FES 降低了 2.33% 的负 mt,提高了 0.11 点的平均 mt。这证明 LM 的过度自信问题在很大程度上得到了解决。此外,我们在图(c)中绘制了 mt 在所有单词和实体单词上的比较。可以看出,实体词在 0 左右的比例明显降低,验证了我们的假设,LM 对于很多虚词是准确的。
Conclucion
本文提出了具有最大边际损失的多任务框架来生成可靠的摘要。辅助问答任务可以增强模型对源文档的理解能力,最大边际损失可以防止 LM 的过度自信。实验结果表明,该模型在不同的数据集上都是有效的。
-
编码器
+关注
关注
45文章
3639浏览量
134439 -
语言模型
+关注
关注
0文章
521浏览量
10268 -
数据集
+关注
关注
4文章
1208浏览量
24690
原文标题:NIPS'22 | 如何提高生成摘要的忠实度?
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【《大语言模型应用指南》阅读体验】+ 基础知识学习
基于统计和理解的自动摘要方法

一种基于多任务联合训练的阅读理解模型

基于图集成模型的自动摘要生产方法

基于多层CNN和注意力机制的文本摘要模型


基于语义感知的中文短文本摘要生成威廉希尔官方网站
基于LSTM的表示学习-文本分类模型
输入捕获-获取一个高电平的持续时间

如何使用BERT模型进行抽取式摘要





 工商网监
工商网监
评论