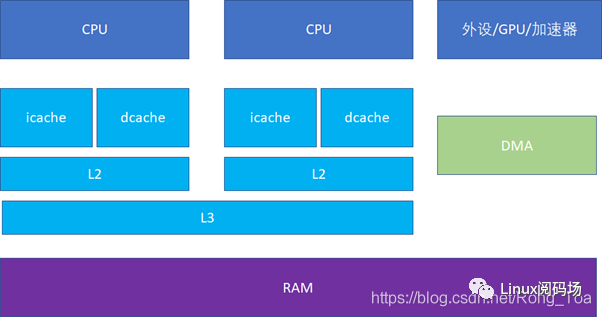
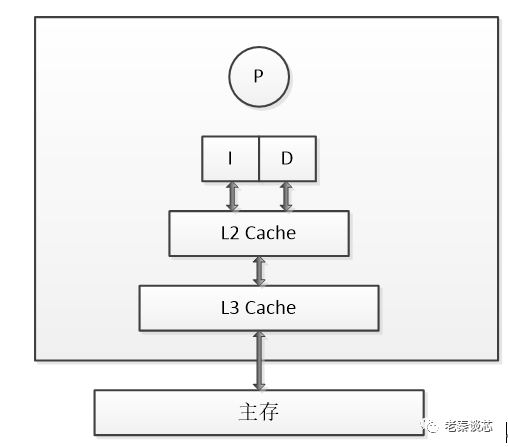
 cache的排布与CPU的典型分布
cache的排布与CPU的典型分布
CACHE 基础
对cache的掌握,对于Linux工程师(其他的非Linux工程师也一样)写出高效能代码,以及优化Linux系统的性能是至关重要的。简单来说,cache快,内存慢,硬盘更慢。在一个典型的现代CPU中比较接近改进的哈佛结构,cache的排布大概是这样的:
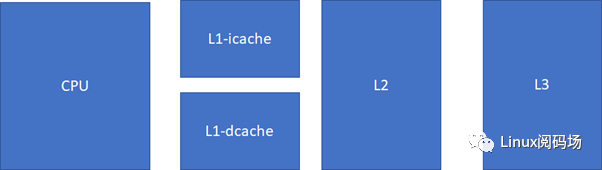
L1速度>L2速度>L3速度>RAM L1容量< L2容量< L3容量< RAM
现代CPU,通常L1 cache的指令和数据是分离的。
这样可以实现2条高速公路并行访问,CPU可以同时load指令和数据。当然,cache也不一定是一个core独享,现代很多CPU的典型分布是这样的,比如多个core共享一个L3。
比如这台的Linux里面运行 lstopo 命令:

人们也常常称呼L2cache为 MLC (MiddleLevel Cache), L3cache为 LLC(LastLevelCache)。
这些Cache究竟有多块呢?
我们来看看Intel的数据,具体配置:Intel i7-4770 (Haswell), 3.4 GHz (Turbo Boostoff), 22nm. RAM: 32 GB (PC3-12800 cl11 cr2)
访问延迟:
L1DataCacheLatency=4cyclesforsimpleaccessviapointer L1DataCacheLatency=5cyclesforaccesswithcomplexaddresscalculation(size_tn,*p;n=p[n]). L2CacheLatency=12cycles L3CacheLatency=36cycles(3.4GHzi7-4770) L3CacheLatency=43cycles(1.6GHzE5-2603v3) L3CacheLatency=58cycles(core9)-66cycles(core5)(3.6GHzE5-2699v3-18cores) RAMLatency=36cycles+57ns(3.4GHzi7-4770) RAMLatency=62cycles+100ns(3.6GHzE5-2699v3dual)
数据来源:https://www.7-cpu.com/cpu/Haswell.html
由此我们可以知道,我们应该尽可能追求cache的命中率高,以避免延迟, 最好是低级cache的命中率越高越好。
CACHE 的组织
SET、WAY、TAG、INDEX
现代的cache基本按照这个模式来组织:SET、WAY、TAG、INDEX
,这几个概念是理解Cache的关键。随便打开一个数据手册,就可以看到这样的字眼:

但是它的执行时间,则远远不到后者的8倍:
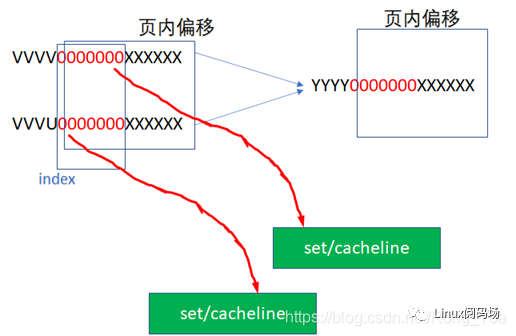
16KB 的cache是 4way 的话,每个set包括 4*64B ,则整个cache分为 16KB/64B/4 =64set
,也即2的6次方。当CPU从cache里面读数据的时候,它会用地址位的BIT6-BIT11来寻址set,BIT0-BIT5是cacheline内的offset。
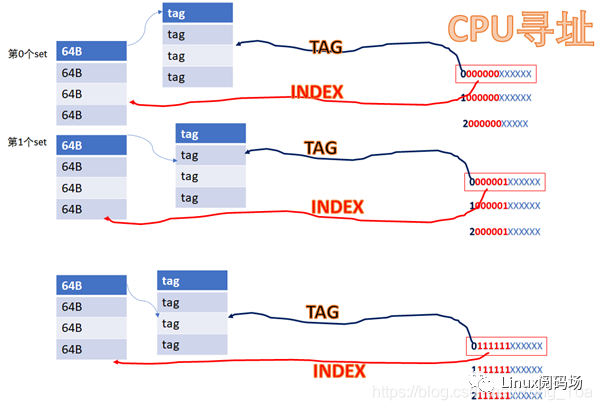
比如CPU访问地址
0 000000 XXXXXX
或者
1 000000 XXXXXX
或者
YYYY 000000 XXXXXX
由于它们红色的6位都相同,所以他们全部都会找到第0个set的cacheline。第0个set里面有4个way,之后硬件会用地址的高位如0,1,YYYY作为tag,去检索这4个way的tag是否与地址的高位相同,而且cacheline是否有效,如果tag匹配且cacheline有效,则cache命中。
所以地址YYYYYY000000XXXXXX全部都是找第0个set,YYYYYY000001XXXXXX全部都是找第1个set,YYYYYY111111XXXXXX全部都是找第63个set。每个set中的4个way,都有可能命中。
中间红色的位就是INDEX,前面YYYY这些位就是TAG。
具体的实现可以是用虚拟地址或者物理地址的相应位做TAG或者INDEX。
如果用虚拟地址做TAG,我们叫VT;
如果用物理地址做TAG,我们叫PT;
如果用虚拟地址做INDEX,我们叫VI;
如果用物理地址做INDEX,我们叫PI。
工程中碰到的cache可能有这么些组合:VIVT、VIPT、PIPT。
VIVT、VIPT、PIPT
具体的实现可以是用虚拟地址或者物理地址的相应位做TAG或者INDEX。
如果用虚拟地址做TAG,我们叫VT;
如果用物理地址做TAG,我们叫PT;
如果用虚拟地址做INDEX,我们叫VI;
如果用物理地址做INDEX,我们叫PI。
VIVT的硬件实现开销最低,但是软件维护成本高;PIPT的硬件实现开销最高,但是软件维护成本最低;VIPT介于二者之间,但是有些硬件是VIPT,但是behave
as PIPT,这样对软件而言,维护成本与PIPT一样。
在VIVT的情况下,CPU发出的虚拟地址,不需要经过MMU的转化,直接就可以去查cache。
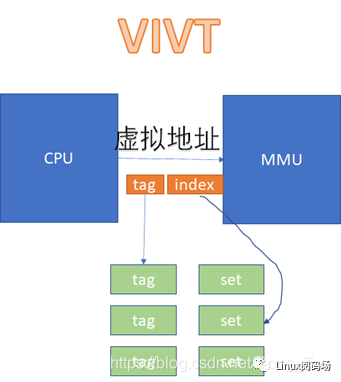
而在VIPT和PIPT的场景下,都涉及到虚拟地址转换为物理地址后,再去比对cache的过程。VIPT如下:

PIPT如下:
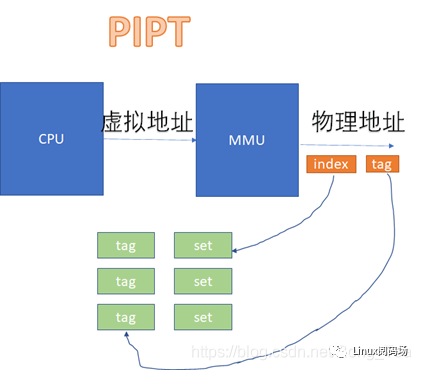
从图上看起来,VIVT的硬件实现效率很高,不需要经过MMU就可以去查cache了。不过,对软件来说,这是个灾难。因为VIVT有严重的歧义和别名问题。
歧义:一个虚拟地址先后指向两个(或者多个)物理地址
别名:两个(或者多个)虚拟地址同时指向一个物理地址
Cache别名问题
这里我们重点看别名问题。比如2个虚拟地址对应同一个物理地址,基于VIVT的逻辑,无论是INDEX还是TAG,2个虚拟地址都是可能不一样的(尽管他们的物理地址一样,但是物理地址在cache比对中完全不掺和),这样它们完全可能在2个cacheline同时命中。
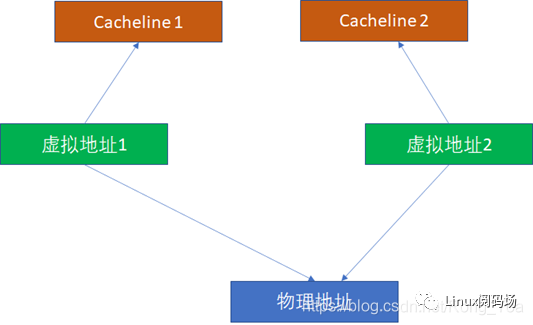
由于2个虚拟地址指向1个物理地址,这样CPU写过第一个虚拟地址后,写入cacheline1。CPU读第2个虚拟地址,读到的是过时的cacheline2,这样就出现了不一致。所以,为了避免这种情况,软件必须写完虚拟地址1后,对虚拟地址1对应的cache执行clean,对虚拟地址2对应的cache执行invalidate。
而PIPT完全没有这样的问题,因为无论多少虚拟地址对应一个物理地址,由于物理地址一样,我们是基于物理地址去寻找和比对cache的,所以不可能出现这种别名问题。
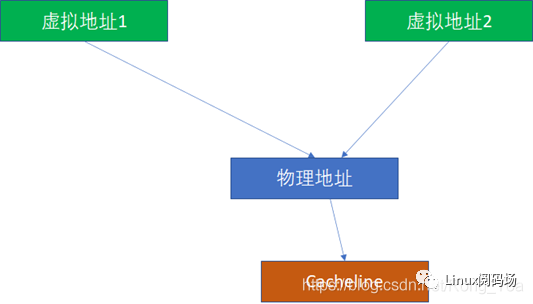
那么VIPT有没有可能出现别名呢?答案是有可能,也有可能不能。 如果VI恰好对于PI,就不可能,这个时候,VIPT对软件而言就是PIPT了:
VI=PI PT=PT
那么什么时候VI会等于PI呢?这个时候我们来回忆下虚拟地址往物理地址的转换过程,它是以页为单位的。假设一页是4K,那么地址的低12位虚拟地址和物理地址是完全一样的。回忆我们前面的地址:
YYYYY000000XXXXXX
其中红色的000000是INDEX。在我们的例子中,红色的6位和后面的XXXXXX(cache内部偏移)加起来正好12位,所以这个000000经过虚实转换后,其实还是000000的,这个时候
VI=PI ,VIPT没有别名问题。
我们原先假设的cache是:16KB大小的cache,假设是4路组相联,cacheline的长度是 64字节
,这样我们正好需要红色的6位来作为INDEX。但是如果我们把cache的大小增加为32KB,这样我们需要
32KB/4/64B=128=2^7,也即7位来做INDEX。
YYYY0000000XXXXXX
这样VI就可能不等于PI了,因为红色的最高位超过了2^12的范围,完全可能出现如下2个虚拟地址,指向同一个物理地址:
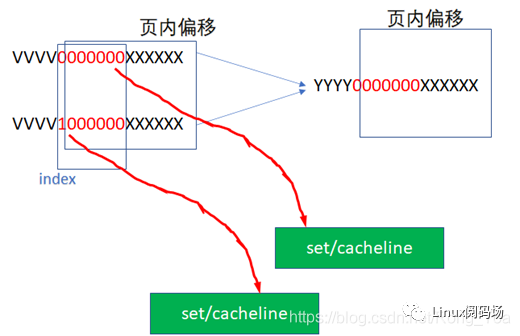
这样就出现了别名问题,
我们在工程里,可能可以通过一些办法避免这种别名问题,比如软件在建立虚实转换的时候,把虚实转换往2^13而不是2^12对齐,让物理地址的低13位而不是低12位与物理地址相同,这样强行绕开别名问题,下图中,2个虚拟地址指向了同一个物理地址,但是它们的INDEX是相同的,这样VI=PI,就绕开了别名问题。这通常是PAGE
COLOURING威廉希尔官方网站
中的一种技巧。
如果这种PAGE
COLOURING的限制对软件仍然不可接受,而我们又想享受VIPT的INDEX不需要经过MMU虚实转换的快捷?有没有什么硬件威廉希尔官方网站
来解决VIPT别名问题呢?确实是存在的,现代CPU很多都是把L1
CACHE做成VIPT,但是表现地(behave as)像PIPT。这是怎么做到的呢?
这要求VIPT的cache,硬件上具备alias detection的能力。比如,硬件知道YYYY 0000000 XXXXXX既有可能出现在第
0000000 ,又可能出现在 1000000
这2个set,然后硬件自动去比对这2个set里面是否出现映射到相同物理地址的cacheline,并从硬件上解决好别名同步,那么软件就完全不用操心了。
下面我们记住一个简单的规则:
对于VIPT,如果cache的size除以WAY数,小于等于1个page的大小,则天然VI=PI,无别名问题;
对于VIPT,如果cache的size除以WAY数,大于1个page的大小,则天然VI≠PI,有别名问题;这个时候又分成2种情况:
硬件不具备alias detection能力,软件需要pagecolouring;
硬件具备alias detection能力,软件把cache当成PIPT用。
比如cache大小64KB,4WAY,PAGE SIZE是4K,显然有别名问题;这个时候,如果cache改为16WAY,或者PAGE
SIZE改为16K,不再有别名问题。为什么?感觉小学数学知识也能算得清
CACHE 的一致性
Cache的一致性有这么几个层面
2.多个CPU各自的cache同步问题
3.CPU与设备(其实也可能是个异构处理器,不过在Linux运行的CPU眼里,都是设备,都是 DMA )的cache同步问题
cache中的映射
1. 直接映射
一个内存地址能被映射到的Cache line是固定的。就如每个人的停车位是固定分配好的,可以直接找到。缺点是:因为人多车位少,很可能几个人争用同一个车位,导致Cache淘汰换出频繁,需要频繁的从主存读取数据到Cache,这个代价也较高。
2. 全相联映射
主存中的一个地址可被映射进任意cache line,问题是:当寻找一个地址是否已经被cache时,需要遍历每一个cache line来寻找,这个代价很高。就像停车位可以大家随便停一样,停的时候简单,找车的时候需要一个一个停车位的找了。
主存中任何一块都可以映射到Cache中的任何一块位置上。
全相联映射方式比较灵活,主存的各块可以映射到Cache的任一块中,Cache的利用率高,块冲突概率低,只要淘汰Cache中的某一块,即可调入主存的任一块。但是,由于Cache比较电路的设计和实现比较困难,这种方式只适合于小容量Cache采用。
3. 组相联映射
组相联映射实际上是直接映射和全相联映射的折中方案,其组织结构如图(3)所示。
主存和Cache都分组,主存中一个组内的块数与Cache中的分组数相同,组间采用直接映射,组内采用全相联映射。也就是说,将Cache分成2^u组,每组包含2^v块,主存块存放到哪个组是固定的,至于存到该组哪一块则是灵活的。即主存的某块只能映射到Cache的特定组中的任意一块。主存的某块b与Cache的组k之间满足以下关系:k=b%(2^u).
icache、dcache同步 - 指令流( icache )和数据流( dcache )
先看一下 ICACHE 和 DCACHE 同步问题。由于程序的运行而言, 指令流的都流过icache ,而指令中涉及到的数据流经过dcache 。所以对于自修改的代码(Self-Modifying Code)而言,比如我们修改了内存p这个位置的代码(典型多见于JIT
compiler),这个时候我们是通过store的方式去写的p,所以新的指令会进入dcache。但是我们接下来去执行p位置的指令的时候,icache里面可能命中的是修改之前的指令。
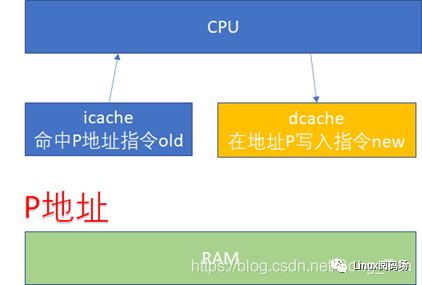
所以这个时候软件需要把dcache的东西clean出去,然后让icache invalidate,这个开销显然还是比较大的。
但是,比如ARM64的N1处理器,它支持硬件的icache同步,详见文档:The Arm Neoverse N1 Platform: BuildingBlocks for the Next-Gen Cloud-to-Edge InfrastructureSoC

特别注意画红色的几行。软件维护的成本实际很高,还涉及到icache的invalidation向所有核广播的动作。
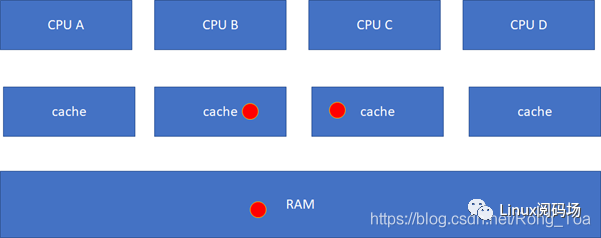
接下来的一个问题就是多个核之间的cache同步。下面是一个简化版的处理器,CPU_A和B共享了一个L3,CPU_C和CPU_D共享了一个L3。实际的硬件架构由于涉及到NUMA,会比这个更加复杂,但是这个图反映层级关系是足够了。
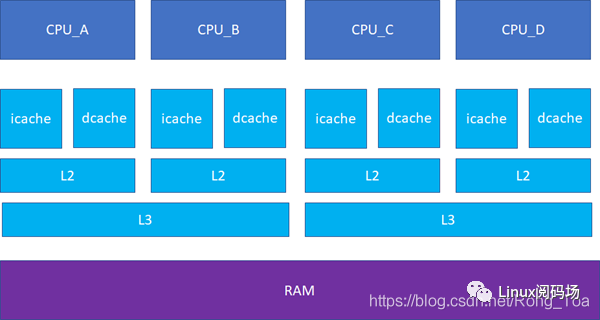
比如CPU_A读了一个地址p的变量?CPU_B、C、D又读,难道B,C,D又必须从RAM里面经过L3,L2,L1再读一遍吗?这个显然是没有必要的,在硬件上,cache的snooping控制单元,可以协助直接把CPU_A的p地址cache拷贝到CPU_B、C和D的cache
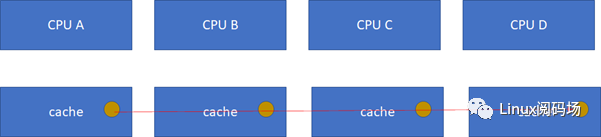
这样A-B-C-D都得到了相同的p地址的棕色小球。
假设CPU B这个时候,把棕色小球写成红色,而其他CPU里面还是棕色,这样就会不一致了:
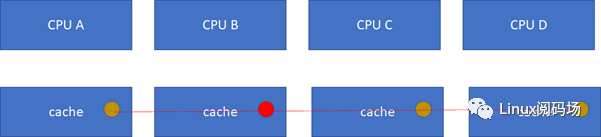
这个时候怎么办?这里面显然需要一个协议,典型的多核cache同步协议有MESI和MOESI。MOESI相对MESI有些细微的差异,不影响对全局的理解。下面我们重点看MESI协议。
MESI 协议
MESI协议定义了4种状态:
M(Modified) :
当前cache的内容有效,数据已被修改而且与内存中的数据不一致,数据只在当前cache里存在;类似RAM里面是棕色球,B里面是红色球(CACHE与RAM不一致),A、C、D都没有球。
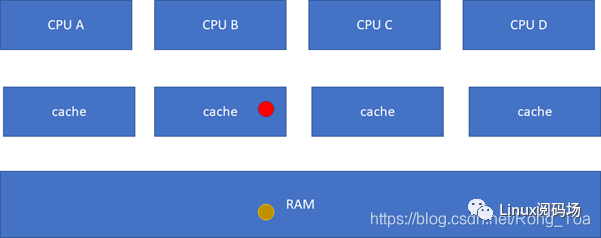
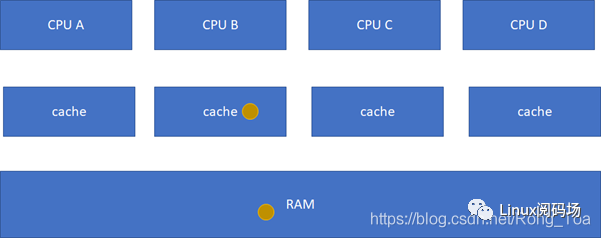
E(Exclusive 独有的 )
:当前cache的内容有效,数据与内存中的数据一致,数据只在当前cache里存在;类似RAM里面是棕色球,B里面是棕色球(RAM和CACHE一致),A、C、D都没有球。
S(Shared) :当前cache的内容有效,数据与内存中的数据一致,数据在多个cache里存在。类似如下图,在CPU A-B-C里面cache的棕色球都与RAM一致。
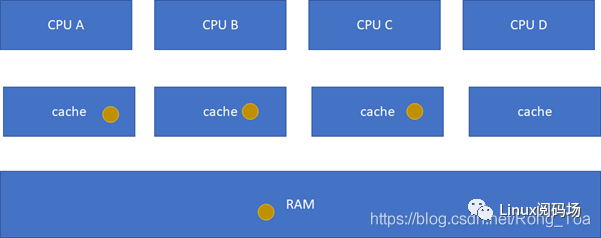
I(Invalid) :当前cache无效。前面三幅图里面cache没有球的那些都是属于这个情况。
然后它有个状态机
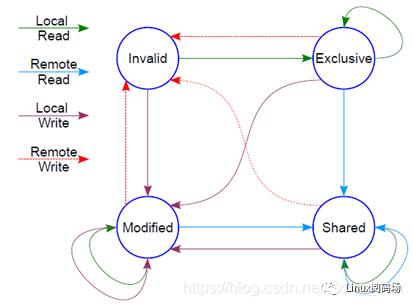
这个状态机比较难记,死记硬背是记不住的,也没必要记,它讲的cache原先的状态,经过一个硬件在本cache或者其他cache的读写操作后,各个cache的状态会如何变迁。所以,硬件上不仅仅是监控本CPU的cache读写行为,还会监控其他CPU的。只需要记住一点:这个状态机是为了保证多核之间cache的一致性,比如一个干净的数据,可以在
多个CPU的cache share ,这个没有一致性问题;但是,假设其中一个CPU写过了,比如A-B-C本来是这样:
然后B被写过了:
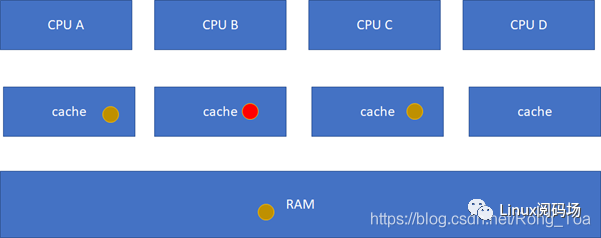
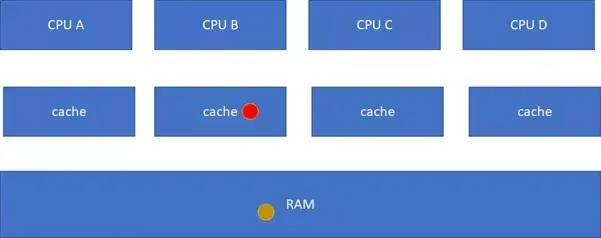
这样A、C的cache实际是过时的数据,这是不允许的。这个时候,硬件会自动把A、C的cache
invalidate掉,不需要软件的干预,A、C其实变地相当于不命中这个球了:
这个时候,你可能会继续问,如果C要读这个球呢?它目前的状态在B里面是modified的,而且与RAM不一致,这个时候,硬件会把红球clean,然后B、C、RAM变地一致,B、C的状态都变化为S(Shared):
这一系列的动作虽然由硬件完成,但是对软件而言不是免费的,因为它耗费了时间。如果编程的时候不注意,引起了硬件的大量cache同步行为,则程序的效率可能会急剧下降。
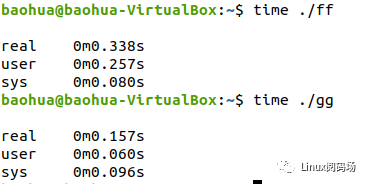
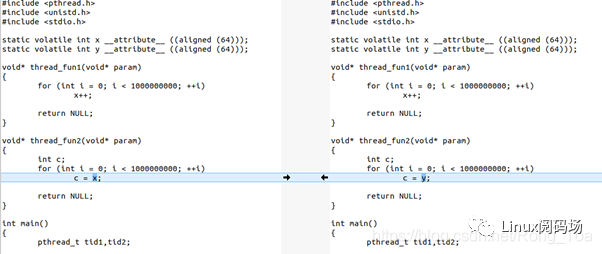
为了让大家直观感受到这个cache同步的开销,下面我们写一个程序,这个程序有2个线程,一个写变量,一个读变量:

这个程序里,x和y都是cacheline对齐的,这个程序的thread1的写,会不停地与thread2的读,进行cache同步。
它的执行时间为:
$time./a.out real0m3.614s user0m7.021s sys0m0.004s
它在2个CPU上的userspace共运行了7.021秒,累计这个程序从开始到结束的对应真实世界的时间是3.614秒(就是从命令开始到命令结束的时间)。
如果我们把程序改一句话,把thread2里面的c = x改为c =
y,这样2个线程在2个CPU运行的时候,读写的是不同的cacheline,就没有这个硬件的cache同步开销了:
它的运行时间:
$time./b.out real0m1.820s user0m3.606s sys0m0.008s
现在只需要1.8秒,几乎减小了一半。
感觉前面那个a.out,双核的帮助甚至都不大。如果我们改为单核跑呢?
$timetaskset-c0./a.out real0m3.299s user0m3.297s sys0m0.000s
它单核跑,居然只需要3.299秒跑完,而双核跑,需要3.614s跑完。单核跑完这个程序,甚至比双核还快,有没有惊掉下巴?!!!因为单核里面没有cache同步的开销。
下一个cache同步的重大问题,就是设备与CPU之间。如果设备感知不到CPU的cache的话(下图中的红色数据流向不经过cache),这样,做DMA前后,CPU就需要进行相关的cacheclean和invalidate的动作,软件的开销会比较大。

这些软件的动作,若我们在Linux编程的时候,使用的是 streaming DMA APIs 的话,都会被类似这样的API自动搞定:
dma_map_single() dma_unmap_single() dma_sync_single_for_cpu() dma_sync_single_for_device() dma_sync_sg_for_cpu() dma_sync_sg_for_device()
如果是使用的 dma_alloc_coherent ()API呢,则设备和CPU之间的buffer是cache一致的,不需要每次DMA进行同步。对于不支持硬件cache一致性的设备而言,很可能dma_alloc_coherent()会把CPU对那段DMA
buffer的访问设置为uncachable的。
这些API把底层的硬件差异封装掉了,如果硬件不支持CPU和设备的cache同步的话,延时还是比较大的。那么,对于底层硬件而言,更好的实现方式,应该仍然是硬件帮我们来搞定。比如我们需要修改总线协议,延伸红线的触角:
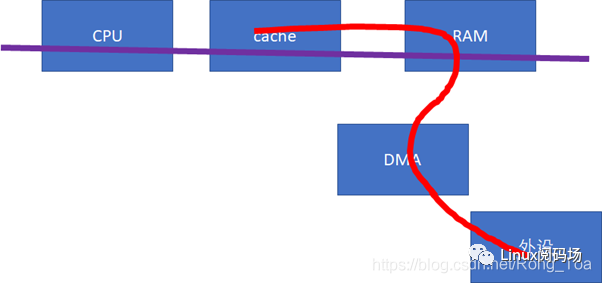
当设备访问RAM的时候,可以去snoop CPU的cache:
如果做内存到外设的DMA,则直接从CPU的cache取modified的数据;
如果做外设到内存的DMA,则直接把CPU的cache invalidate掉。
这样,就实现硬件意义上的cache同步。当然,硬件的cache同步,还有一些其他方法,原理上是类似的。注意,这种同步仍然不是免费的,它仍然会消耗bus
cycles的。实际上,cache的同步开销还与距离相关,可以说距离越远,同步开销越大,比如下图中A、B的同步开销比A、C小。
对于一个NUMA服务器而言,跨NUMA的cache同步开销显然是要比NUMA内的同步开销大。
意识到 CACHE 的编程
通过上一节的代码,读者应该意识到了cache的问题不处理好,程序的运行性能会急剧下降。所以意识到cache的编程,对程序员是至关重要的。
7-zip LZMA 基准
https://www.7-cpu.com/
LZMA基准说明
LZMA基准测试显示了MIPS等级(每秒百万条指令)。额定值是根据测得的速度计算得出的,并通过关闭多线程选项的Intel Core 2CPU的结果进行了标准化。因此,如果您拥有Intel或AMD的现代CPU,则单线程模式下的额定值必须接近实际CPU频率。
该测试中用于压缩的测试数据是使用特殊算法生成的,该算法创建的数据流具有真实数据的某些属性,例如文本或执行代码。请注意,用于实际数据的LZMA的速度可能会略有不同。
压缩速度 很大程度上取决于内存(RAM)延迟,数据高速缓存大小/速度和TLB。CPU的无序执行功能对该测试也很重要。
解压缩速度在
很大程度上取决于CPU整数运算。该测试最重要的事情是:分支错误预测损失(流水线的长度)和32位指令的延迟(“乘”,“移位”,“加”和其他)。减压测试具有大量不可预测的分支。请注意,某些CPU体系结构(例如32位ARM)支持可以有条件执行的指令。因此,在LZMA解压缩代码中的许多情况下,此类CPU可以在没有分支的情况下工作(也无需管道冲洗)。与不支持复杂的有条件执行的其他体系结构相比,此类CPU具有一些速度优势。乱序执行功能对于LZMA减压并不那么重要。
测试代码不使用FPU和SSE。大多数代码是32位整数代码。压缩代码中只有一小部分也使用64位整数。RAM和缓存带宽对于这些测试而言并不那么重要。延迟要重要得多。
对于这些测试,CPU的IPC(每个周期的指令)速率不是很高。对于现代CPU,测试IPC的估计值为1(每个周期一条指令)。压缩测试具有对RAM和数据缓存的大量随机访问。执行时间中很大一部分,CPU等待数据缓存或RAM中的数据。在分支预测错误之后,减压测试会进行大量的管道冲洗。如此低的IPC意味着有一些未使用的CPU资源。但是具有超线程功能的CPU可以使用两个线程来加载这些CPU资源。因此,超线程在这些测试中提供了很大的改进。
多线程模式下的LZMA
当您指定(N *2)个线程进行测试时,程序将创建N份LZMA编码器副本,并且每个LZMA编码器实例都会压缩单独的测试数据块。每个LZMA编码器实例都会创建3个非对称执行线程:两个大线程和一个小线程。这3个线程的总CPU负载可以在140%到200%之间变化。为了在压缩过程中提供更好的CPU负载,我们还测试了基准线程数大于硬件线程数的模式。
每个处于多线程模式的LZMA编码器实例将压缩任务分为3个不同的任务,其中每个任务在单独的线程中执行。这些任务中的每一个都比原始任务简单,并且使用更少的内存。因此,每个线程在多线程模式下都会更有效地使用数据缓存和TLB。LZMA编码器在“多线程”模式下将“速度”的值除以“
CPU使用率”会更有效。
请注意,LZMA编码器的3个线程之间存在一些数据通信。因此,通过CPU线程之间的内存进行数据交换的带宽也很重要,尤其是在具有大量内核或CPU的多核系统中。
所有LZMA解码器线程都是对称且独立的。因此,如果使用了硬件线程数,则解压缩测试将使用所有硬件线程。
LZMA成绩
我们将基准测试结果用于32 MB词典(控制台版本的结果中的“ 25:”行)。如果没有32
MB的字典结果,则将结果用于较小的字典。大多数x86测试都是在Windows
7官方二进制文件上进行的。一些测试是在64位模式下执行的。其他平台上的大多数测试都是使用GCC编译的p7zip进行速度优化的。
新版本的7-Zip提供了改进的性能。例如,最新版本的x64平台的7-Zip使用以汇编器编写的用于解压缩的优化代码,因此评级结果可以是以前版本的7-Zip的1.7倍。但是表中的大多数结果表示在进行这些优化之前,使用旧版本的7-Zip执行的度量。如果某些CPU已通过7-Zip的新版本进行了测试,则会在7-Zip的版本号上打上标记。
-
cpu
+关注
关注
68文章
10858浏览量
211657 -
数据
+关注
关注
8文章
7010浏览量
88978 -
Cache
+关注
关注
0文章
129浏览量
28340 -
代码
+关注
关注
30文章
4786浏览量
68546
原文标题:深入理解CPU cache:组织、一致性(同步)、编程
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
cpu与cache内存交互的过程
CPU Cache是如何保证缓存一致性的?
嵌入式CPU指令Cache的设计与实现
什么是缓存Cache
什么是Cache/SIMD?
什么是Instructions Cache/IMM/ID
高速缓存(Cache),高速缓存(Cache)原理是什么?
Buffer和Cache之间区别是什么?
cache对写好代码真的有那么重要吗

宋宝华:深入理解cache对写好代码至关重要
CPU Cache伪共享问题
CPU设计之Cache存储器
多个CPU各自的cache同步问题





 工商网监
工商网监
评论