 AT&T利用GPU优化速度、成本和效率
AT&T利用GPU优化速度、成本和效率
众所周知, GPU 是大型机器学习( ML )应用程序的典型解决方案,但如果 GPU 应用于 AI 管道数据的早期阶段,该怎么办?
例如,如果不必为每个管道处理阶段切换集群配置,则会更简单。您可能仍然有一些问题:
从成本角度来看,这是否可行?
对于一些接近实时处理的数据处理时间预算,您还能满足 SLA 吗?
优化这些 GPU 集群有多困难?
如果您为一个阶段优化了配置,那么其他阶段也会这样吗?
在 At&T ,当我们的数据团队在规模上平衡简单性的同时管理云成本时,这些问题就出现了。我们还观察到,我们的许多数据工程师和科学家同事都不知道 GPU 是一个有效和高效的基础设施,可以在其上运行更普通的 ETL ,并具有工程阶段的特点。
与 GPU 配置相比, CPU 的相对性能也不清楚。我们在 at & T 的目标是运行一些典型的配置示例以了解差异。
在本文中,我们将从速度、成本和完整管道的简单性方面分享我们的数据管道分析。我们还提供有关设计考虑的见解,并解释我们如何优化 GPU 集群的性能和价格。优化来自于使用 RAPIDS accelerator for Apache Spark, 这一开源库,它支持 GPU 加速 ETL 和特性工程。
SPOILER ALERT :我们惊喜地发现,至少对于所研究的示例来说,在每个管道阶段使用 GPU 证明是更快、更便宜、更简单的!
用例
AI 管道的数据包括多个批处理阶段:
数据准备或联合
转型
功能工程
数据提取
批处理涉及处理包含数万亿条记录的大量数据。批处理作业通常针对成本或性能进行优化,具体取决于该用例的 SLA 。
针对成本进行优化的批处理作业的一个很好的例子是从调用记录中创建功能,这些功能将用于训练 ML 模型。另一方面,用于检测欺诈的实时推理用例针对性能进行了优化。 GPU 经常被忽视,对于 AI / ML 管道的这些批处理阶段来说,它被认为是昂贵的。
这些批处理作业通常涉及大型联接、聚合、排名和转换操作。可以想象, AT & T 有许多涉及批量处理的数据和 AI 用例:
网络规划和优化
欺诈
销售和营销
税
根据用例的不同,这些管道可以使用 NVIDIA GPU 和 RAPIDS Accelerator for Apache Spark 来优化成本或提高性能。
为了进行此分析,我们查看了两个到 AI 管道的数据。第一个用例将呼叫记录的特征工程用于营销用例,第二个用例执行复杂税务数据集的 ETL 转换。
使用 GPU 加速特征工程和转换
高效地将数据扩展到 AI 管道仍然是数据团队的需要。高成本的管道每月、每周甚至每天都要处理数百 TB 到 PB 的数据。
在检查效率时,重要的是确定所有 ETL 和特征工程阶段的优化机会,然后比较速度、成本和管道简单性。
对于我们的数据管道分析,我们比较了三个选项:
各种基于 CPU 的 Spark 集群解决方案
GPU Spark 集群上的 RAPIDS accelerator for Apache Spark
使用 Databricks 最新发布的 Photon 引擎的 Apache Spark CPU 集群
为了衡量我们离最佳成本有多远,我们使用 AT & T 的开源 GS-lite 解决方案比较了一个基本 VM 解决方案,该解决方案使您能够编写 SQL ,然后将其编译为 C ++。
如前所述,在优化每个解决方案后,我们发现在 GPU 集群上运行的 Apache Spark 加速器具有最佳的总体速度、成本和设计简单性权衡。
在下面的部分中,我们将讨论为每种类型选择的优化和设计注意事项。
优化 AI / ML 管道解决方案的设计考虑
为了比较这三个潜在解决方案的性能,我们进行了两个实验,每个实验针对选定的用例。对于每种情况,我们都优化了不同的参数,以深入了解速度、成本和设计是如何受到影响的。
示例 1 :通过聚合为呼叫记录优化简单组用例
对于第一个特性工程示例,我们选择从每月包含近 3 万亿条记录(行)的调用记录数据集创建特性(表 1 )。此数据预处理用例是几个销售和营销 AI 管道中的基本构建块,例如客户细分、预测客户流失以及预测客户趋势和情绪。在这个用例中有各种各样的数据转换,但其中许多都涉及简单的“分组”聚合,例如下面的聚合,我们希望对其进行优化处理。
res=spark.sql("""
Select DataHour, dev_id,
sum(fromsubbytes) as fromsubbytes_total,
sum(tosubbytes) as tosubbytes_total,
From df
Group By DataHour, dev_id
""")
从数据中获取见解并进行数据分析仍然是许多企业的最大痛点之一。这并不是因为缺乏数据,而是因为在数据准备和分析上花费的时间仍然是数据工程师和数据科学家的障碍。
以下是此预处理示例中的一些关键基础架构挑战:
CPU 集群上的查询执行时间过长,导致超时问题。
计算成本昂贵。
此外,这个调用记录用例在压缩类型方面有额外的实验维度。数据通过某种形式的压缩从网络边缘到达云端,我们可以指定并评估折衷。因此,我们试验了几种压缩方案,包括 txt / gzip 、 Parquet / Z 标准和 Parquet / Snappy 。
Z 标准压缩的文件大小最小(在本例中约为一半)。正如我们稍后所展示的,我们发现了与 Parquet / Snappy 更好的速度/成本权衡。
接下来,我们考虑了集群的类型,包括每个 VM 的内核数、 VM 数、工作节点的分配,以及是使用 CPU 还是 GPU 。
对于 CPU 集群,我们选择了能够处理工作负载的最低数量的核心,即 VM 和工人的最低数量,以防止资源过度分配。
对于 GPU ,我们使用了 RAPIDS Accelerator 调优指南[spark rapids tuning],该指南针对每个执行器的并发任务、 maxPartitionBytes 、 shuffle 分区和并发 GPU 任务提供了分级建议。
在 GPU 上实施数据处理后的一个目标是确保所有关键特征工程步骤都保留在 GPU 上(图 1 )。

图 1. GPU 物理处理计划
示例 2 :为税务数据集优化多个 ETL 和功能创建阶段
示例 2 的用例允许我们比较 ETL 、特性创建和 AI 的许多不同转换和处理阶段。每个阶段有不同的记录体积大小(图 2 )。

图 2.ETL / AI 流量和记录体积大小
这种具有多个阶段的 ETL 管道是数据存储在竖井中的企业中的常见瓶颈。大多数情况下,海量数据处理需要使用模糊逻辑查询和连接来自两个或多个数据源的数据。如图 2 所示,尽管我们一开始只有 2000 万行数据,但随着数据处理阶段的推移,数据量呈指数级增长。
如示例 1 所示,在比较 CPU 和 GPU 时,设计考虑的是每个 VM 的内核数、 VM 数和工作节点的分配。
后果
在为示例 1 和 2 中所示的用例尝试了不同的核心、工作机和集群配置之后,我们收集了结果。我们确保在分配的时间内完成任何特定 ETL 作业,以跟上数据输入数据速率。两者中最好的方法都具有最低的成本和最高的简单性。
示例 1 结果
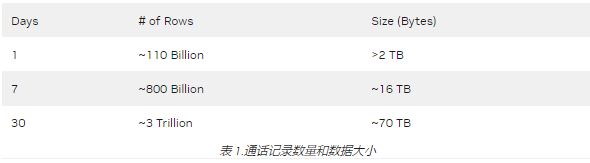
图 3 显示了调用记录用例中简单分组聚合的一系列设置之间的成本/速度权衡。您可以进行几个观察:
成本最低、最简单的解决方案是使用具有 Snappy 压缩功能的 GPU 集群,它比成本最低的 Photon 解决方案便宜约 33% ,比最快的 Photon 方案便宜近一半。
所有标准 Databricks 集群在成本和执行时间方面都表现较差。光子是最好的 CPU 溶液。
虽然图 3 中没有显示,但 GS-lite 解决方案实际上是最便宜的,只需要两个 VM 。
图 3.不同 Databricks 集群配置的成本/执行和时间权衡
示例 2 结果
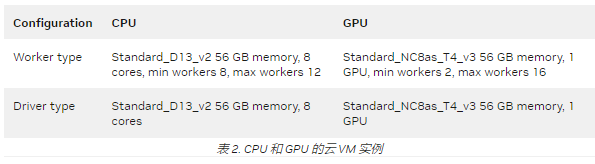
与示例 1 一样,我们使用 Databricks 10.4 LTS ML 运行时为五个 ETL 和 AI 数据处理阶段尝试了几个 CPU 和 GPU 集群配置。表 2 显示了得到的最佳配置。
这些配置产生了有利于 GPU 的相对成本和执行时间(速度)性能(图 4 )。
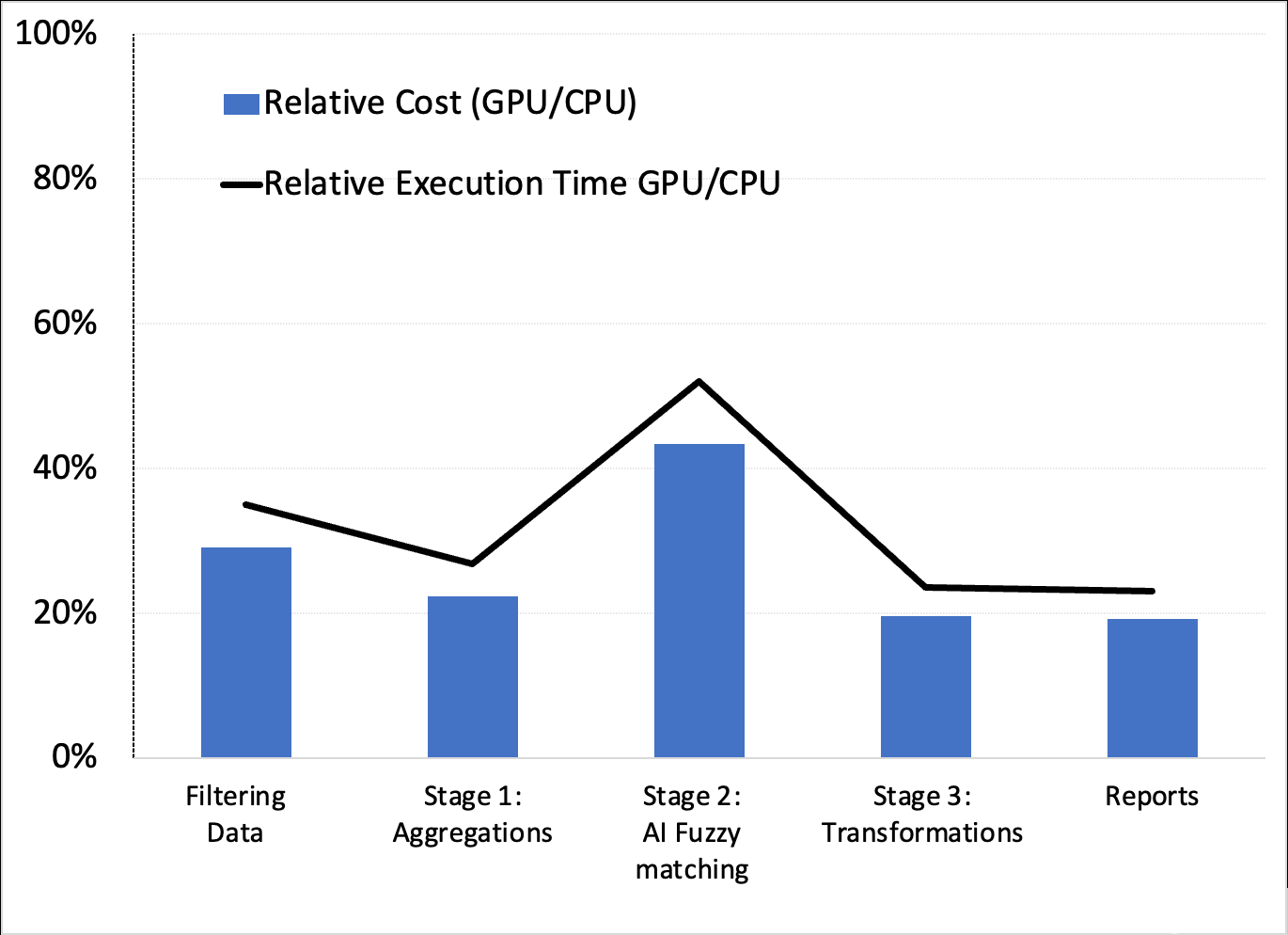
图 4.成本和执行时间权衡
虽然此处未显示,但我们确认,示例 1 中使用 XGBoost 建模的 AI 管道的下一阶段也受益于 GPU 和 RAPIDS Accelerator for Apache Spark 。这证实了 GPU 可能是最好的端到端解决方案。
结论
虽然并非所有 AT & T 数据和 AI 管道都详尽无遗,但基于 GPU 的管道似乎在所有示例中都是有益的。在这些情况下,我们能够减少数据准备、模型培训和优化的时间。这导致在更简单的设计上花费更少的钱,因为没有跨阶段的配置切换。
关于作者
作为 at & T 数据科学副总裁, Mark Austin 博士领导了数百名数据科学家和工程师团队,他们实施了新的创新威廉希尔官方网站 ,帮助 at & T 业务部门采用人工智能和机器学习威廉希尔官方网站 。他获得了马里兰大学和佐治亚理工大学的电气和电子工程学士和硕士学位。奥斯汀博士还拥有佐治亚科技大学的电气工程博士学位。
Satya Vivek Kanakadandila 是 at & T 的主要大数据软件工程师,他利用自己在软件开发方面的丰富经验为公司的数据驱动计划构建新功能。 Kanakadandila 拥有德克萨斯理工大学电气和计算机工程硕士学位。他在 Hive 、 Apache Spark 、需求分析、数据工程和 shell 脚本编写方面也有丰富的经验。
Abhay Dabholkar 是一位实践经验丰富的 AI / ML 和大数据软件工程主管,在大规模转型、制定业务战略和领导端到端数据科学/ AI 项目方面具有丰富经验。 Abhay 目前是 at & T 杰出的 AI / ML 企业架构师,他建立并领导了全球分布的高绩效团队。 Abhay 还参与了数据科学和文本分析领域的多项专利。
Chris Vo 是 at & T 威廉希尔官方网站 人员的主要成员。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
10858浏览量
211671 -
gpu
+关注
关注
28文章
4735浏览量
128914 -
机器学习
+关注
关注
66文章
8414浏览量
132601
发布评论请先 登录
相关推荐
AT&;amp;T网络上未收到NTP udp数据包如何解决?
一男子认为5G能监控,炸弹袭击AT&;amp;amp;T大楼
AT&;amp;T如何借助数据科学抓住新机遇
广和通LTE-A模组FM101-NA强势取得北美运营商AT&;amp;amp;T认证

美格智能SLM750模组再获北美运营商AT&;amp;T认证,助力终端客户扬帆出海
威廉希尔官方网站 角度看AT&;amp;T为何“抛弃”诺基亚
AT&;amp;T正式道歉并承诺提供信用额度及5美元话费补贴以弥补断网之失
Open RAN的未来及其对AT&;amp;T的意义
爱立信旗下Vonage与AT&;amp;T合作,通过API为开发者提供更丰富的网络能力
解读北美运营商,AT&;amp;amp;T的认证分类与认证内容分享

北美运营商AT&;amp;amp;T认证入库产品范围名单相关

北美运营商AT&;amp;amp;T认证的费用受哪些因素影响
北美运营商AT&;amp;amp;T认证的测试内容有哪些?

北美运营商AT&;amp;amp;T认证中的VoLTE测试项
如何判断产品需不需要做AT&;amp;amp;T认证?AT&;amp;amp;T测试内容和要求分享





 工商网监
工商网监
评论