 使用RAPIDS加速KubeFlow上的ETL
使用RAPIDS加速KubeFlow上的ETL
在 机器学习 和 MLOps world , GPU 被广泛用于加速模型训练和推理,但工作流的其他阶段(如 ETL 管道或超参数优化)如何?
在 RAPIDS 数据科学框架, ETL 工具的设计使使用 Python 的数据科学家具有熟悉的外观。您当前使用的是 Pandas , NumPy , Scikit Learn ,或 PyData Stack 在您的 KubeFlow 工作流中?如果是这样,您可以使用 RAPIDS 通过利用集群中可能已经存在的 GPU 来加速工作流的这些部分。
在本文中,将演示如何将 RAPIDS 放入 KubeFlow 环境。首先在交互式笔记本环境中使用 RAPIDS ,然后扩展到单个容器之外,使用 Dask 跨多个节点使用多个 GPU 。
可选:使用 GPU 安装 KubeFlow
本文假设您已经对 Kubernetes 和 KubeFlow 有所了解。要探索如何在 KubeFlow 上使用 GPU 和 RAPIDS ,您需要一个具有 GPU 节点的 KubeFlow 集群。如果您已经拥有集群或对 KubeFlow 安装说明不感兴趣,请随时跳过。
KubeFlow 是一种流行的机器学习和 MLOps 平台 Kubernetes 用于设计和运行机器学习管道、训练模型和提供推理服务。
KubeFlow 还提供了一个笔记本服务,您可以使用它在 Kubernetes 集群中启动一个交互式 Jupyter 服务器,以及一个管道服务,该服务带有一个用 Python 编写的 DSL 库,用于创建可重复的工作流。还可以访问用于调整超参数和运行模型推理服务器的工具。这基本上是构建健壮的机器学习服务所需的所有工具。
对于此帖子,您使用 谷歌 Kubernetes 引擎 ( GKE )启动具有 GPU 节点的 Kubernetes 集群并将 KubeFlow 安装到该集群上,但任何具有 GPU 的 KubeFlow 集群都可以。
使用 GPU 创建 Kubernetes 集群
首先,使用gcloud CLI 创建 Kubernetes 集群。
$ gcloud container clusters create rapids-gpu-kubeflow \ --accelerator type=nvidia-tesla-a100,count=2 --machine-type a2-highgpu-2g \ --zone us-central1-c --release-channel stable Note: Machines with GPUs have certain limitations which may affect your workflow. Learn more at https://cloud.google.com/kubernetes-engine/docs/how-to/gpus Creating cluster rapids-gpu-kubeflow in us-central1-c... Cluster is being health-checked (master is healthy)... Created kubeconfig entry generated for rapids-gpu-kubeflow. NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS rapids-gpu-kubeflow us-central1-c 1.21.12-gke.1500 34.132.107.217 a2-highgpu-2g 1.21.12-gke.1500 3 RUNNING
通过这个命令,您已经启动了一个名为rapids-gpu-kubeflow的 GKE 集群。您已经指定它应该使用a2-highgpu-2g类型的节点,每个节点都有两个 A100 GPU 。
KubeFlow 还需要一个稳定版本的 Kubernetes ,因此您指定了它以及启动集群的区域。
下一个 安装 NVIDIA 驱动程序 到每个节点上。
$ kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded-latest.yaml daemonset.apps/nvidia-driver-installer created
验证是否已成功安装 NVIDIA 驱动程序。
$ kubectl get po -A --watch | grep nvidiakube-system nvidia-driver-installer-6zwcn 1/1 Running 0 8m47s kube-system nvidia-driver-installer-8zmmn 1/1 Running 0 8m47s kube-system nvidia-driver-installer-mjkb8 1/1 Running 0 8m47s kube-system nvidia-gpu-device-plugin-5ffkm 1/1 Running 0 13m kube-system nvidia-gpu-device-plugin-d599s 1/1 Running 0 13m kube-system nvidia-gpu-device-plugin-jrgjh 1/1 Running 0 13m
安装驱动程序后,创建一个使用 GPU 计算的快速示例 pod ,以确保一切按预期运行。
$ cat << EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvidia/samples:vectoradd-cuda11.2.1"
resources:
limits:
nvidia.com/gpu: 1
EOF
pod/cuda-vectoradd created
$ kubectl logs pod/cuda-vectoradd
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
如果您在输出中看到Test PASSED,您可以确信您的 Kubernetes 集群已经正确设置了 GPU 计算。接下来,清理那个吊舱。
$ kubectl delete po cuda-vectoradd pod "cuda-vectoradd" deleted
安装 KubeFlow
现在您有了 Kubernetes ,安装 KubeFlow 。 KubeFlow 使用 kustomize ,所以一定要安装它。
$ curl -s "https://raw.githubusercontent.com/kubernetes-sigs/kustomize/master/hack/install_kustomize.sh" | bash
然后,通过克隆 KubeFlow ,查看最新版本并应用它们。
$ git clone https://github.com/kubeflow/manifests $ cd manifests $ git checkout v1.5.1 # Or whatever the latest release is $ while ! kustomize build example | kubectl apply -f -; do echo "Retrying to apply resources"; sleep 10; done
在创建了所有资源之后, KubeFlow 仍然需要在集群上引导自己。即使在这个命令完成之后,事情可能还没有准备好。这可能需要 15 分钟以上。
最后,您将在kubeflow命名空间中看到 KubeFlow 服务的完整列表。
$ kubectl get po -n kubeflow NAME READY STATUS RESTARTS AGE admission-webhook-deployment-667bd68d94-4n62z 1/1 Running 0 10m cache-deployer-deployment-79fdf9c5c9-7cpn7 1/1 Running 2 10m cache-server-6566dc7dbf-7ndm5 1/1 Running 0 10m centraldashboard-8fc7d8cc-q62cd 1/1 Running 0 10m jupyter-web-app-deployment-84c459d4cd-krxq4 1/1 Running 0 10m katib-controller-68c47fbf8b-bjvst 1/1 Running 0 10m katib-db-manager-6c948b6b76-xtrwz 1/1 Running 2 10m katib-mysql-7894994f88-6ndtp 1/1 Running 0 10m katib-ui-64bb96d5bf-v598l 1/1 Running 0 10m kfserving-controller-manager-0 2/2 Running 0 9m54s kfserving-models-web-app-5d6cd6b5dd-hp2ch 1/1 Running 0 10m kubeflow-pipelines-profile-controller-69596b78cc-zrvhc 1/1 Running 0 10m metacontroller-0 1/1 Running 0 9m53s metadata-envoy-deployment-5b4856dd5-r7xnn 1/1 Running 0 10mmetadata-grpc-deployment-6b5685488-9rd9q 1/1 Running 6 10m metadata-writer-548bd879bb-7fr7x 1/1 Running 1 10m minio-5b65df66c9-dq2rr 1/1 Running 0 10m ml-pipeline-847f9d7f78-pl7z5 1/1 Running 0 10m ml-pipeline-persistenceagent-d6bdc77bd-wd4p8 1/1 Running 2 10m ml-pipeline-scheduledworkflow-5db54d75c5-6c5vv 1/1 Running 0 10m ml-pipeline-ui-5bd8d6dc84-sg9t8 1/1 Running 0 9m59s ml-pipeline-viewer-crd-68fb5f4d58-wjhvv 1/1 Running 0 9m59s ml-pipeline-visualizationserver-8476b5c645-96ptw 1/1 Running 0 9m59s mpi-operator-5c55d6cb8f-vwr8p 1/1 Running 0 9m58s mysql-f7b9b7dd4-pv767 1/1 Running 0 9m58s notebook-controller-deployment-6b75d45f48-rpl5b 1/1 Running 0 9m57s profiles-deployment-58d7c94845-gbm8m 2/2 Running 0 9m57s tensorboard-controller-controller-manager-775777c4c5-b6c2k 2/2 Running 2 9m56s tensorboards-web-app-deployment-6ff79b7f44-g5cr8 1/1 Running 0 9m56s training-operator-7d98f9dd88-hq6v4 1/1 Running 0 9m55s volumes-web-app-deployment-8589d664cc-krfxs 1/1 Running 0 9m55s workflow-controller-5cbbb49bd8-b7qmd 1/1 Running 1 9m55s
在所有 Pod 都处于Running状态后,将 KubeFlow web 用户界面向前移植,并在浏览器中访问它。
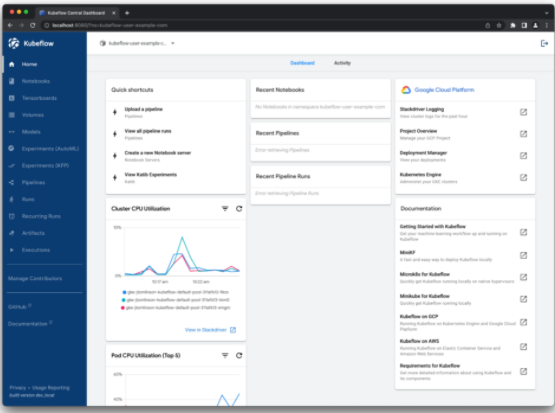
导航到127.0.0.1:8080,并使用默认凭据user@example.com和12341234登录。然后,您应该看到 KubeFlow 仪表板(图 1 )。
在 KubeFlow 笔记本电脑中使用 RAPIDS
要在 KubeFlow 集群上开始 RAPIDS ,请使用 官方 RAPIDS 容器图像 。
在启动集群之前,您必须创建一个配置配置文件,该配置文件对于以后开始使用 Dask 非常重要。为此,请应用以下清单:
# configure-dask-dashboard.yaml
apiVersion: "kubeflow.org/v1alpha1"
kind: PodDefault
metadata:
name: configure-dask-dashboardspec:
selector:
matchLabels:
configure-dask-dashboard: "true"
desc: "configure dask dashboard"
env:
- name: DASK_DISTRIBUTED__DASHBOARD__LINK
value: "{NB_PREFIX}/proxy/{host}:{port}/status" volumeMounts:
- name: jupyter-server-proxy-config
mountPath: /root/.jupyter/jupyter_server_config.py
subPath: jupyter_server_config.py
volumes:
- name: jupyter-server-proxy-config
configMap:
name: jupyter-server-proxy-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: jupyter-server-proxy-config
data:
jupyter_server_config.py: |
c.ServerProxy.host_allowlist = lambda app, host: True
使用此代码示例的内容创建一个文件,然后使用kubectl将其应用到user@example.com用户命名空间中。
$ kubectl apply -n kubeflow-user-example-com -f configure-dask-dashboard.yaml
现在 选择 RAPIDS 版本 使用。通常,您希望为最新版本选择容器映像。 GKE Stable 上安装的默认 CUDA 版本是 11.4 ,因此选择该版本。从版本 11.5 和更高版本开始,这并不重要,因为它们将向后兼容。从安装命令复制容器映像名称:
rapidsai/rapidsai-core:22.06-cuda11.5-runtime-ubuntu20.04-py3.9
回到 KubeFlow ,选择笔记本选项卡,然后选择新笔记本。
在此页面上,您必须设置几个配置选项:
姓名:急流
命名空间:kubeflow 用户示例 com
自定义图像:选中此复选框。
自定义图像: rapidsai/rapidsai-core:22.06-cuda11.4-runtime-ubuntu20.04-py3.9
请求 CPU :2
Gi 中请求的内存:8
GPU 的编号:1
GPU 供应商: NVIDIA
向下滚动到配置,查看配置 dask 仪表板选项,滚动到页面底部,然后选择发射。您应该看到它在笔记本列表中启动。 RAPIDS 容器图像中充满了令人惊叹的工具,因此这一步可能需要一些时间。
笔记本准备就绪后,要启动 Jupyter ,请选择连接通过打开终端窗口并运行nvidia-smi(图 2 ),验证一切正常。
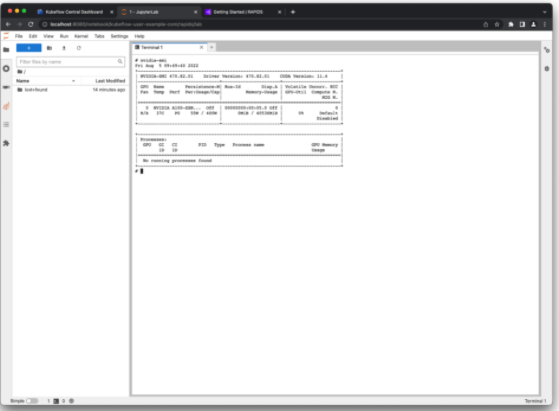
图 2 NVIDIA smi命令是检查 GPU 是否已设置的好方法
成功您的 A100 GPU 正在被传递到笔记本容器中。
您选择的 RAPIDS 容器还附带了一些示例笔记本,您可以在 /rapidsai/notebooks 。从主目录快速创建到这些文件的符号链接,以便您可以使用左侧的文件资源管理器进行导航:
ln -s /rapids/notebooks /home/jovyan/notebooks.
导航到这些示例笔记本,探索 RAPIDS 提供的所有库。例如,使用 pandas 的 ETL 开发人员应查看 cuDF 笔记本以获取加速数据帧的示例。
扩展您的 RAPIDS 工作流
许多 RAPIDS 库还支持将计算扩展到多个 GPU 节点上,以增加加速。为此,请使用 Dask ,一个用于分布式计算的开源 Python 库。
要使用 Dask ,请创建一个调度程序和一些工作程序来执行计算。这些工作人员还需要 GPU 和与笔记本会话相同的 Python 环境。 Dask 有一个 Kubernetes 的操作符 您可以使用它来管理 KubeFlow 集群上的 Dask 集群,因此现在就安装它。
安装 Dask Kubernetes 运算符
要安装运算符,您需要创建运算符本身及其关联的自定义资源。
在用于创建 KubeFlow 集群的终端窗口中,运行以下命令:
$ kubectl apply -f https://raw.githubusercontent.com/dask/dask-kubernetes/main/dask_kubernetes/operator/deployment/manifests/daskcluster.yaml $ kubectl apply -f https://raw.githubusercontent.com/dask/dask-kubernetes/main/dask_kubernetes/operator/deployment/manifests/daskworkergroup.yaml $ kubectl apply -f https://raw.githubusercontent.com/dask/dask-kubernetes/main/dask_kubernetes/operator/deployment/manifests/daskjob.yaml $ kubectl apply -f https://raw.githubusercontent.com/dask/dask-kubernetes/main/dask_kubernetes/operator/deployment/manifests/operator.yaml
通过列出 Dask 集群,验证资源是否已成功应用。您不应该期望看到任何命令,但命令应该成功。
$ kubectl get daskclusters No resources found in default namespace.
您还可以检查 operator pod 是否正在运行并准备启动新的 Dask 集群。
$ kubectl get pods -A -l application=dask-kubernetes-operator NAMESPACE NAME READY STATUS RESTARTS AGE dask-operator dask-kubernetes-operator-775b8bbbd5-zdrf7 1/1 Running 0 74s
最后,确保笔记本会话可以创建和管理 Dask 自定义资源。为此,编辑应用于笔记本播客的kubeflow-kubernetes-edit群集角色。将新规则添加到此角色的规则部分,以允许kubernetes.dask.orgAPI 组中的所有内容。
$ kubectl edit clusterrole kubeflow-kubernetes-edit … rules: … - apiGroups: - "kubernetes.dask.org" verbs: - "*" resources: - "*" …
创建 Dask 集群
现在,在 Kubernetes 中创建 DaskCluster 资源,以启动集群工作所需的所有 pod 和服务。你可以这样做 通过 Kubernetes API 实现 YAML 如果您喜欢,但对于本文,请使用笔记本会话中的 Python API 。
回到 Jupyter 会话,创建一个新笔记本并安装启动集群所需的dask-kubernetes软件包。
!pip install dask-kubernetes
接下来,使用 KubeCluster 类创建一个 Dask 集群。确认您将容器映像设置为与您为笔记本环境选择的映像相匹配,并将 GPU 的编号设置为 1 。您还可以告诉 RAPIDS 容器在默认情况下不要启动 Jupyter ,而是运行 Dask 命令。
这可能需要类似的时间来启动笔记本容器,因为它还需要拉取 RAPIDS Docker 映像。
from dask_kubernetes.experimental import KubeCluster
cluster = KubeCluster(name="rapids-dask",
image="rapidsai/rapidsai-core:22.06-cuda11.4-runtime-ubuntu20.04-py3.9",
worker_command="dask-cuda-worker",
n_workers=2,
resources={"limits": {"nvidia.com/gpu": "1"}},
env={"DISABLE_JUPYTER": "true"})
图 3 显示了一个 Dask 集群,其中有两个工作进程,每个工作进程都有一个 A100 GPU ,与 Jupyter 会话相同。

您可以使用 Jupyter 中小部件中的缩放选项卡或通过调用cluster.scale(n)来上下缩放该集群,以设置工作人员的数量,从而设置 GPU 的数量。
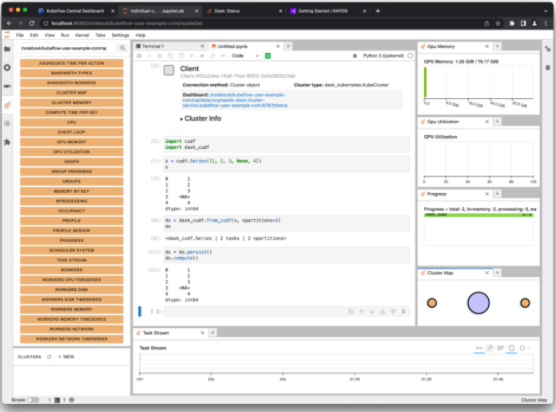
现在,将 Dask 客户端连接到集群。从那时起,任何支持 Dask 的 RAPIDS 库,如dask_cudf,都会使用集群将计算分布到所有 GPU 。图 4 显示了创建Series对象并使用 Dask 分发该对象的一个简短示例。

访问 Dask 仪表板
在本节的开头,您添加了一个额外的配置文件,其中包含 Dask 仪表板的一些选项。这些选项对于让您能够从 Jupyter 环境访问 Kubernetes 集群上调度器 pod 中运行的仪表板是必要的。
您可能已经注意到集群和客户端小部件都有到仪表板的链接。选择这些链接以在新选项卡中打开仪表板(图 5 )。

您也可以使用 Dask JupyterLab 扩展 在 JupyterLab 中查看您的 Dask 集群的各种图表和统计数据。
上达斯克选项卡,选择搜索图标。这将通过笔记本中的客户端将 JupyterLab 连接到仪表板。通过拖动选项卡,选择各种绘图并在 JupyterLab 中排列它们。
如果您跟随这篇文章,请通过删除开始时创建的 GKE 集群来清理所有创建的资源。
$ gcloud container clusters delete rapids-gpu-kubeflow --zone us-central1-c
结语
RAPIDS 与 KubeFlow 无缝集成,使您能够在工作流的 ETL 阶段以及培训和推理期间使用 GPU 资源。
关于作者
Jacob Tomlinson 是 NVIDIA 的高级 Python 软件工程师,专注于分布式系统的部署工具。他的工作包括维护开源项目,包括 RAPIDS 和 Dask 。
审核编辑:郭婷
-
机器学习
+关注
关注
66文章
8411浏览量
132596 -
python
+关注
关注
56文章
4795浏览量
84647
发布评论请先 登录
相关推荐
美国ETL认证简介
基于数据质量监管的ETL设计
Google Kubernetes机器学习工具包Kubeflow发布0.1版
Nvidia宣布推出了一套新的开源RAPIDS库
NVIDIA RAPIDS加速器可将工作分配集群中各节点
具有RAPIDS cuML的GPU加速分层DBSCAN
如何使用RAPIDS和CuPy时加速Gauss 秩变换

NVIDIA RAPIDS加速器v21.08的功能应用
利用Apache Spark和RAPIDS Apache加速Spark实践
通过RAPIDS加速单细胞DNA和RNA基因组分析
Sapphire Rapids加速器::AMX、DLB、DSA、IAA和AMX
RAPIDS cuDF将pandas提速近150倍






 工商网监
工商网监
评论