 redis数据倾斜的原因以及应对方案 JD开源hotkey的源码解析
redis数据倾斜的原因以及应对方案 JD开源hotkey的源码解析
1 前言
之前旁边的小伙伴问我热点数据相关问题,在给他粗略的讲解一波redis数据倾斜的案例之后,自己也顺道回顾了一些关于热点数据处理的方法论,同时也想起去年所学习JD开源项目hotkey——专门用来解决热点数据问题的框架。在这里结合两者所关联到的知识点,通过几个小图和部分粗略的讲解,来让大家了解相关方法论以及hotkey的源码解析。
2 Redis数据倾斜
2.1 定义与危害
先说说数据倾斜的定义,借用百度词条的解释:
对于集群系统,一般缓存是分布式的,即不同节点负责一定范围的缓存数据。我们把缓存数据分散度不够,导致大量的缓存数据集中到了一台或者几台服务节点上,称为数据倾斜。一般来说数据倾斜是由于负载均衡实施的效果不好引起的。
从上面的定义中可以得知,数据倾斜的原因一般是因为LB的效果不好,导致部分节点数据量非常集中。
那这又会有什么危害呢?
如果发生了数据倾斜,那么保存了大量数据,或者是保存了热点数据的实例的处理压力就会增大,速度变慢,甚至还可能会引起这个实例的内存资源耗尽,从而崩溃。这是我们在应用切片集群时要避免的。
2.2 数据倾斜的分类
2.2.1 数据量倾斜(写入倾斜)
1.图示
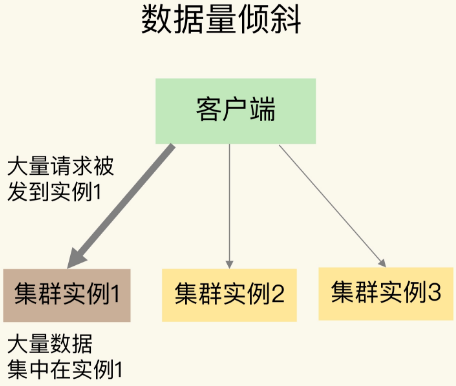
如图,在某些情况下,实例上的数据分布不均衡,某个实例上的数据特别多。
2.bigkey导致倾斜
某个实例上正好保存了 bigkey。bigkey 的 value 值很大(String 类型),或者是 bigkey 保存了大量集合元素(集合类型),会导致这个实例的数据量增加,内存资源消耗也相应增加。
应对方法
在业务层生成数据时,要尽量避免把过多的数据保存在同一个键值对中。
如果 bigkey 正好是集合类型,还有一个方法,就是把 bigkey 拆分成很多个小的集合类型数据,分散保存在不同的实例上。
3.Slot分配不均导致倾斜
先简单的介绍一下slot的概念,slot其实全名是Hash Slot(哈希槽),在Redis Cluster切片集群中一共有16384 个 Slot,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。Redis Cluster 方案采用哈希槽来处理数据和实例之间的映射关系。
一张图来解释,数据、哈希槽、实例这三者的映射分布情况。

这里的CRC16(city)%16384可以简单的理解为将key1根据CRC16算法取hash值然后对slot个数取模,得到的就是slot位置为14484,他所对应的实例节点是第三个。
运维在构建切片集群时候,需要手动分配哈希槽,并且把16384 个槽都分配完,否则 Redis 集群无法正常工作。由于是手动分配,则可能会导致部分实例所分配的slot过多,导致数据倾斜。
应对方法
使用CLUSTER SLOTS 命令来查看slot分配情况,使用CLUSTER SETSLOT,CLUSTER GETKEYSINSLOT,MIGRATE这三个命令来进行slot数据的迁移,具体内容不再这里细说,感兴趣的同学可以自行学习一下。
4.Hash Tag导致倾斜
Hash Tag 定义 :指当一个key包含 {} 的时候,就不对整个key做hash,而仅对 {} 包括的字符串做hash。
假设hash算法为sha1。对user:{user1}:ids和user:{user1}:tweets,其hash值都等同于sha1(user1)。
Hash Tag 优势 :如果不同 key 的 Hash Tag 内容都是一样的,那么,这些 key 对应的数据会被映射到同一个 Slot 中,同时会被分配到同一个实例上。
Hash Tag 劣势 :如果不合理使用,会导致大量的数据可能被集中到一个实例上发生数据倾斜,集群中的负载不均衡。
2.2.2 数据访问倾斜(读取倾斜-热key问题)
一般来说数据访问倾斜就是热key问题导致的,如何处理redis热key问题也是面试中常会问到的。所以了解相关概念及方法论也是不可或缺的一环。
1.图示
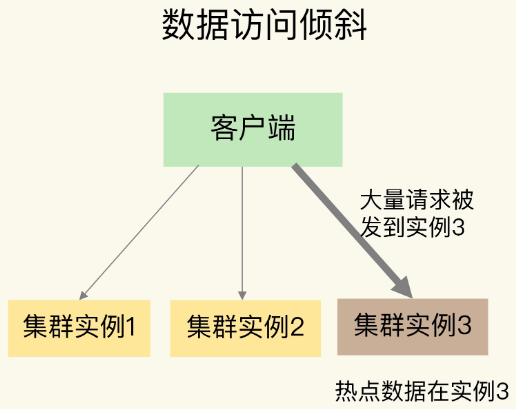
如图,虽然每个集群实例上的数据量相差不大,但是某个实例上的数据是热点数据,被访问得非常频繁。
但是为啥会有热点数据的产生呢?
2.产生热key的原因及危害
1)用户消费的数据远大于生产的数据(热卖商品、热点新闻、热点评论、明星直播)。
在日常工作生活中一些突发的的事件,例如:双十一期间某些热门商品的降价促销,当这其中的某一件商品被数万次点击浏览或者购买时,会形成一个较大的需求量,这种情况下就会造成热点问题。
同理,被大量刊发、浏览的热点新闻、热点评论、明星直播等,这些典型的读多写少的场景也会产生热点问题。
2)请求分片集中,超过单 Server 的性能极限。
在服务端读数据进行访问时,往往会对数据进行分片切分,此过程中会在某一主机 Server 上对相应的 Key 进行访问,当访问超过 Server 极限时,就会导致热点 Key 问题的产生。
如果热点过于集中,热点 Key 的缓存过多,超过目前的缓存容量时,就会导致缓存分片服务被打垮现象的产生。当缓存服务崩溃后,此时再有请求产生,会缓存到后台 DB 上,由于DB 本身性能较弱,在面临大请求时很容易发生请求穿透现象,会进一步导致雪崩现象,严重影响设备的性能。
3.常用的热key问题解决办法:
解决方案一: 备份热key
可以把热点数据复制多份,在每一个数据副本的 key 中增加一个随机后缀,让它和其它副本数据不会被映射到同一个 Slot 中。
这里相当于把一份数据复制到其他实例上,这样在访问的时候也增加随机前缀,将对一个实例的访问压力,均摊到其他实例上
例如:
我们在放入缓存时就将对应业务的缓存key拆分成多个不同的key。如下图所示,我们首先在更新缓存的一侧,将key拆成N份,比如一个key名字叫做”good_100”,那我们就可以把它拆成四份,“good_100_copy1”、“good_100_copy2”、“good_100_copy3”、“good_100_copy4”,每次更新和新增时都需要去改动这N个key,这一步就是拆key。
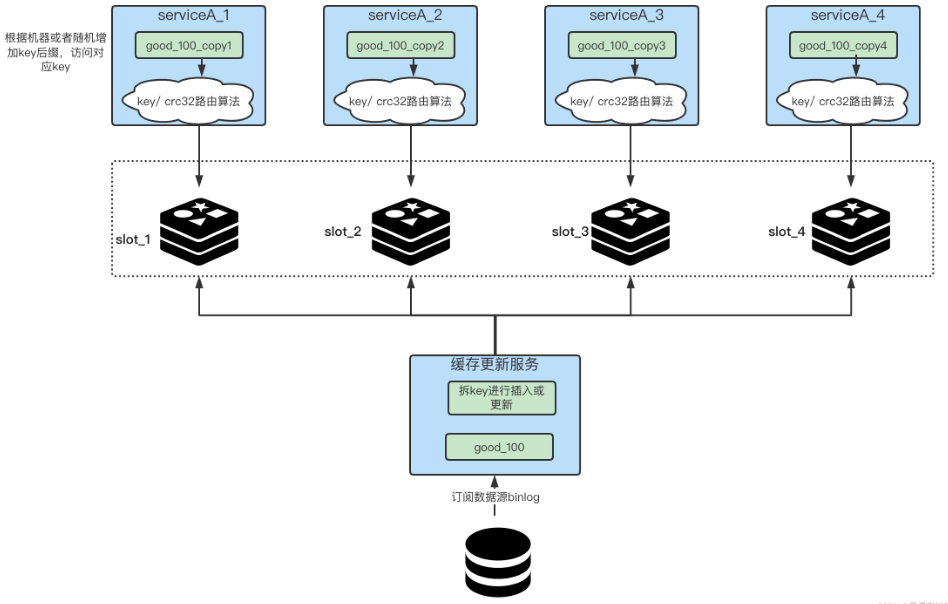
对于service端来讲,我们就需要想办法尽量将自己访问的流量足够的均匀。
如何给自己即将访问的热key上加入后缀?几种办法,根据本机的ip或mac地址做hash,之后的值与拆key的数量做取余,最终决定拼接成什么样的key后缀,从而打到哪台机器上;服务启动时的一个随机数对拆key的数量做取余。
伪代码如下:
const M = N * 2
//生成随机数
random = GenRandom(0, M)
//构造备份新key
bakHotKey = hotKey + “_” + random
data = redis.GET(bakHotKey)
if data == NULL {
data = GetFromDB()
redis.SET(bakHotKey, expireTime + GenRandom(0,5))
}
解决方案二: 本地缓存+动态计算自动发现热点缓存 基本流程图
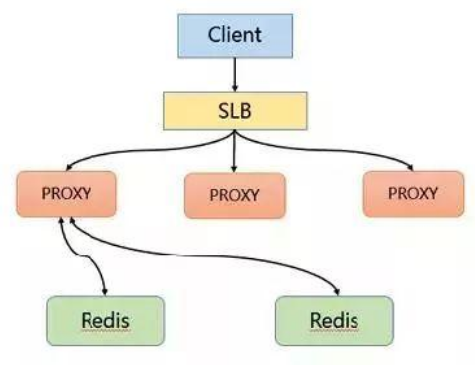
该方案通过主动发现热点并对其进行存储来解决热点 Key 的问题。首先 Client 也会访问 SLB,并且通过 SLB 将各种请求分发至 Proxy 中,Proxy 会按照基于路由的方式将请求转发至后端的 Redis 中。 在热点 key 的解决上是采用在服务端增加缓存的方式进行。具体来说就是在 Proxy 上增加本地缓存,本地缓存采用 LRU 算法来缓存热点数据,后端节点增加热点数据计算模块来返回热点数据。
Proxy 架构的主要有以下优点:
Proxy 本地缓存热点,读能力可水平扩展
DB 节点定时计算热点数据集合
DB 反馈 Proxy 热点数据
对客户端完全透明,不需做任何兼容
热点数据的发现与存储
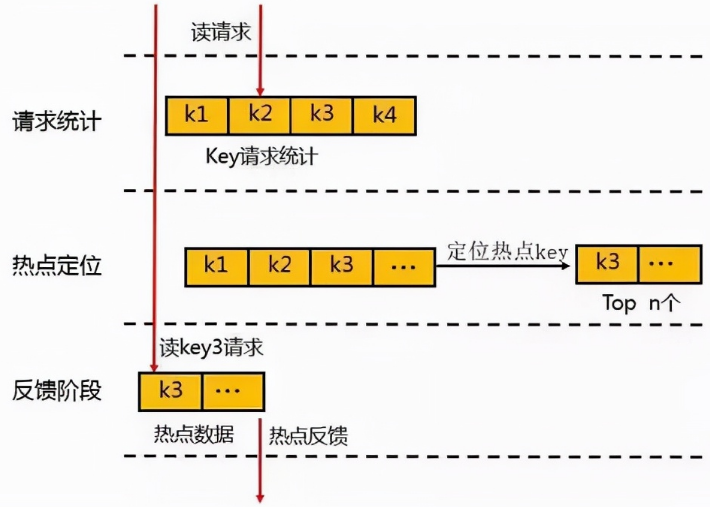
对于热点数据的发现,首先会在一个周期内对 Key 进行请求统计,在达到请求量级后会对热点 Key 进行热点定位,并将所有的热点 Key 放入一个小的 LRU 链表内,在通过 Proxy 请求进行访问时,若 Redis 发现待访点是一个热点,就会进入一个反馈阶段,同时对该数据进行标记。 可以使用一个etcd或者zk集群来存储反馈的热点数据,然后本地所有节点监听该热点数据,进而加载到本地JVM缓存中。
热点数据的获取
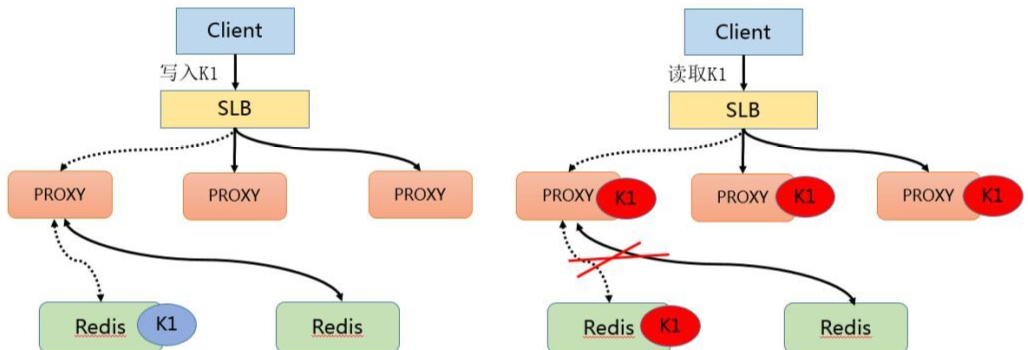
在热点 Key 的处理上主要分为写入跟读取两种形式,在数据写入过程当 SLB 收到数据 K1 并将其通过某一个 Proxy 写入一个 Redis,完成数据的写入。 假若经过后端热点模块计算发现 K1 成为热点 key 后, Proxy 会将该热点进行缓存,当下次客户端再进行访问 K1 时,可以不经 Redis。 最后由于 proxy 是可以水平扩充的,因此可以任意增强热点数据的访问能力。
最佳成熟方案: JD开源hotKey 这是目前较为成熟的自动探测热key、分布式一致性缓存解决方案。原理就是在client端做洞察,然后上报对应hotkey,server端检测到后,将对应hotkey下发到对应服务端做本地缓存,并且能保证本地缓存和远程缓存的一致性。
在这里咱们就不细谈了,这篇文章的第三部分:JD开源hotkey源码解析里面会带领大家了解其整体原理。
3 JD开源hotkey—自动探测热key、分布式一致性缓存解决方案
3.1 解决痛点
从上面可知,热点key问题在并发量比较高的系统中(特别是做秒杀活动)出现的频率会比较高,对系统带来的危害也很大。 那么针对此,hotkey诞生的目的是什么?需要解决的痛点是什么?以及它的实现原理。
在这里引用项目上的一段话来概述: 对任意突发性的无法预先感知的热点数据,包括并不限于热点数据(如突发大量请求同一个商品)、热用户(如恶意爬虫刷子)、热接口(突发海量请求同一个接口)等,进行毫秒级精准探测到。然后对这些热数据、热用户等,推送到所有服务端JVM内存中,以大幅减轻对后端数据存储层的冲击,并可以由使用者决定如何分配、使用这些热key(譬如对热商品做本地缓存、对热用户进行拒绝访问、对热接口进行熔断或返回默认值)。这些热数据在整个服务端集群内保持一致性,并且业务隔离。
核心功能:热数据探测并推送至集群各个服务器
3.2 集成方式
集成方式在这里就不详述了,感兴趣的同学可以自行搜索。
3.3 源码解析
3.3.1 架构简介
1.全景图一览
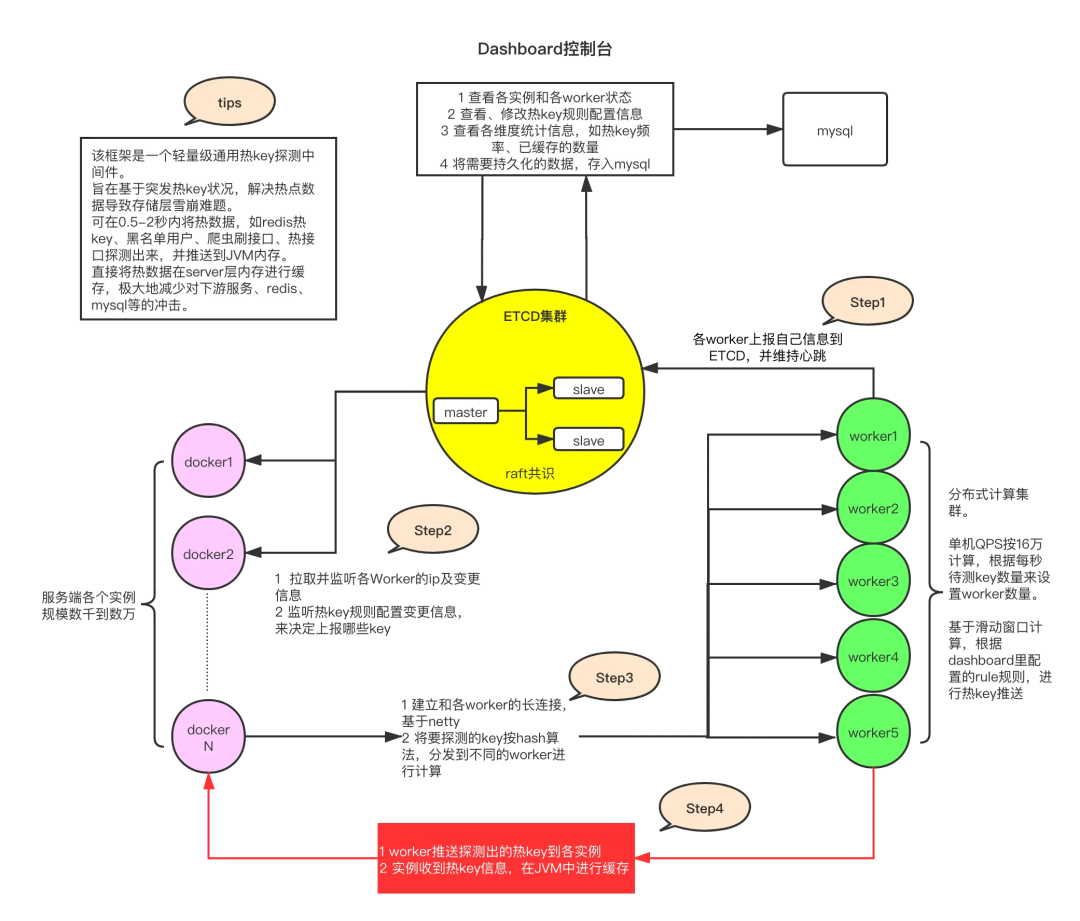
流程介绍:
客户端通过引用hotkey的client包,在启动的时候上报自己的信息给worker,同时和worker之间建立长连接。定时拉取配置中心上面的规则信息和worker集群信息。
客户端调用hotkey的ishot()的方法来首先匹配规则,然后统计是不是热key。
通过定时任务把热key数据上传到worker节点。
worker集群在收取到所有关于这个key的数据以后(因为通过hash来决定key 上传到哪个worker的,所以同一个key只会在同一个worker节点上),在和定义的规则进行匹配后判断是不是热key,如果是则推送给客户端,完成本地缓存。
2.角色构成
这里直接借用作者的描述: 1)etcd集群 etcd作为一个高性能的配置中心,可以以极小的资源占用,提供高效的监听订阅服务。主要用于存放规则配置,各worker的ip地址,以及探测出的热key、手工添加的热key等。
2)client端jar包 就是在服务中添加的引用jar,引入后,就可以以便捷的方式去判断某key是否热key。同时,该jar完成了key上报、监听etcd里的rule变化、worker信息变化、热key变化,对热key进行本地caffeine缓存等。
3) worker端集群 worker端是一个独立部署的Java程序,启动后会连接etcd,并定期上报自己的ip信息,供client端获取地址并进行长连接。之后,主要就是对各个client发来的待测key进行累加计算,当达到etcd里设定的rule阈值后,将热key推送到各个client。
4) dashboard控制台 控制台是一个带可视化界面的Java程序,也是连接到etcd,之后在控制台设置各个APP的key规则,譬如2秒20次算热。然后当worker探测出来热key后,会将key发往etcd,dashboard也会监听热key信息,进行入库保存记录。同时,dashboard也可以手工添加、删除热key,供各个client端监听。
3.hotkey工程结构
3.3.2 client端
主要从下面三个方面来解析源码:
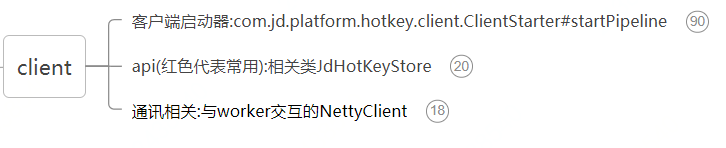
4.客户端启动器
1)启动方式
@PostConstruct
public void init() {
ClientStarter.Builder builder = new ClientStarter.Builder();
ClientStarter starter = builder.setAppName(appName).setEtcdServer(etcd).build();
starter.startPipeline();
}
appName:是这个应用的名称,一般为${spring.application.name}的值,后续所有的配置都以此为开头 etcd:是etcd集群的地址,用逗号分隔,配置中心。 还可以看到ClientStarter实现了建造者模式,使代码更为简介。
2)核心入口 com.jd.platform.hotkey.client.ClientStarter#startPipeline
/**
* 启动监听etcd
*/
public void startPipeline() {
JdLogger.info(getClass(), "etcdServer:" + etcdServer);
//设置caffeine的最大容量
Context.CAFFEINE_SIZE = caffeineSize;
//设置etcd地址
EtcdConfigFactory.buildConfigCenter(etcdServer);
//开始定时推送
PushSchedulerStarter.startPusher(pushPeriod);
PushSchedulerStarter.startCountPusher(10);
//开启worker重连器
WorkerRetryConnector.retryConnectWorkers();
registEventBus();
EtcdStarter starter = new EtcdStarter();
//与etcd相关的监听都开启
starter.start();
}
该方法主要有五个功能:
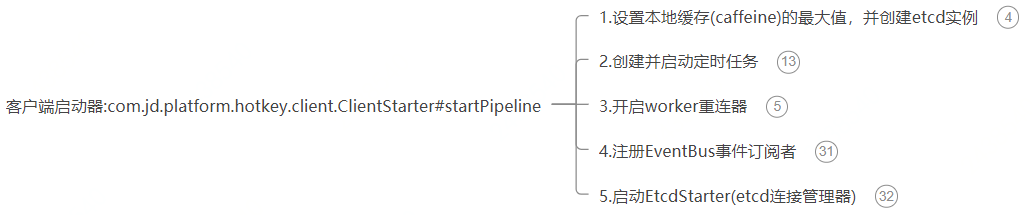
① 设置本地缓存(caffeine)的最大值,并创建etcd实例
//设置caffeine的最大容量
Context.CAFFEINE_SIZE = caffeineSize;
//设置etcd地址
EtcdConfigFactory.buildConfigCenter(etcdServer);
caffeineSize是本地缓存的最大值,在启动的时候可以设置,不设置默认为200000。 etcdServer是上面说的etcd集群地址。
Context可以理解为一个配置类,里面就包含两个字段:
public class Context {
public static String APP_NAME;
public static int CAFFEINE_SIZE;
}
EtcdConfigFactory是ectd配置中心的工厂类
public class EtcdConfigFactory {
private static IConfigCenter configCenter;
private EtcdConfigFactory() {}
public static IConfigCenter configCenter() {
return configCenter;
}
public static void buildConfigCenter(String etcdServer) {
//连接多个时,逗号分隔
configCenter = JdEtcdBuilder.build(etcdServer);
}
}
通过其configCenter()方法获取创建etcd实例对象,IConfigCenter接口封装了etcd实例对象的行为(包括基本的crud、监控、续约等)
② 创建并启动定时任务:PushSchedulerStarter
//开始定时推送
PushSchedulerStarter.startPusher(pushPeriod);//每0.5秒推送一次待测key
PushSchedulerStarter.startCountPusher(10);//每10秒推送一次数量统计,不可配置
pushPeriod是推送的间隔时间,可以再启动的时候设置,最小为0.05s,推送越快,探测的越密集,会越快探测出来,但对client资源消耗相应增大
PushSchedulerStarter类
/**
* 每0.5秒推送一次待测key
*/
public static void startPusher(Long period) {
if (period == null || period <= 0) {
period = 500L;
}
@SuppressWarnings("PMD.ThreadPoolCreationRule")
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("hotkey-pusher-service-executor", true));
scheduledExecutorService.scheduleAtFixedRate(() -> {
//热key的收集器
IKeyCollector
//这里相当于每0.5秒,通过netty来给worker来推送收集到的热key的信息,主要是一些热key的元数据信息(热key来源的app和key的类型和是否是删除事件,还有该热key的上报次数)
//这里面还有就是该热key在每次上报的时候都会生成一个全局的唯一id,还有该热key每次上报的创建时间是在netty发送的时候来生成,同一批次的热key时间是相同的
List
if(CollectionUtil.isNotEmpty(hotKeyModels)){
//积攒了半秒的key集合,按照hash分发到不同的worker
KeyHandlerFactory.getPusher().send(Context.APP_NAME, hotKeyModels);
collectHK.finishOnce();
}
},0, period, TimeUnit.MILLISECONDS);
}
/**
* 每10秒推送一次数量统计
*/
public static void startCountPusher(Integer period) {
if (period == null || period <= 0) {
period = 10;
}
@SuppressWarnings("PMD.ThreadPoolCreationRule")
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("hotkey-count-pusher-service-executor", true));
scheduledExecutorService.scheduleAtFixedRate(() -> {
IKeyCollector
List
if(CollectionUtil.isNotEmpty(keyCountModels)){
//积攒了10秒的数量,按照hash分发到不同的worker
KeyHandlerFactory.getPusher().sendCount(Context.APP_NAME, keyCountModels);
collectHK.finishOnce();
}
},0, period, TimeUnit.SECONDS);
}
从上面两个方法可知,都是通过定时线程池来实现定时任务的,都是守护线程。
咱们重点关注一下KeyHandlerFactory类,它是client端设计的一个比较巧妙的地方,从类名上直译为key处理工厂。具体的实例对象是DefaultKeyHandler:
public class DefaultKeyHandler {
//推送HotKeyMsg消息到Netty的推送者
private IKeyPusher iKeyPusher = new NettyKeyPusher();
//待测key的收集器,这里面包含两个map,key主要是热key的名字,value主要是热key的元数据信息(比如:热key来源的app和key的类型和是否是删除事件)
private IKeyCollector
//数量收集器,这里面包含两个map,这里面key是相应的规则,HitCount里面是这个规则的总访问次数和热后访问次数
private IKeyCollector
public IKeyPusher keyPusher() {
return iKeyPusher;
}
public IKeyCollector
return iKeyCollector;
}
public IKeyCollector
return iKeyCounter;
}
}
这里面有三个成员对象,分别是封装推送消息到netty的NettyKeyPusher、待测key收集器TurnKeyCollector、数量收集器TurnCountCollector,其中后两者都实现了接口IKeyCollector,能对hotkey的处理起到有效的聚合,充分体现了代码的高内聚。 先来看看封装推送消息到netty的NettyKeyPusher:
/**
* 将msg推送到netty的pusher
* @author wuweifeng wrote on 2020-01-06
* @version 1.0
*/
public class NettyKeyPusher implements IKeyPusher {
@Override
public void send(String appName, List
//积攒了半秒的key集合,按照hash分发到不同的worker
long now = System.currentTimeMillis();
Map
for(HotKeyModel model : list) {
model.setCreateTime(now);
Channel channel = WorkerInfoHolder.chooseChannel(model.getKey());
if (channel == null) {
continue;
}
List
newList.add(model);
}
for (Channel channel : map.keySet()) {
try {
List
HotKeyMsg hotKeyMsg = new HotKeyMsg(MessageType.REQUEST_NEW_KEY, Context.APP_NAME);
hotKeyMsg.setHotKeyModels(batch);
channel.writeAndFlush(hotKeyMsg).sync();
} catch (Exception e) {
try {
InetSocketAddress insocket = (InetSocketAddress) channel.remoteAddress();
JdLogger.error(getClass(),"flush error " + insocket.getAddress().getHostAddress());
} catch (Exception ex) {
JdLogger.error(getClass(),"flush error");
}
}
}
}
@Override
public void sendCount(String appName, List
//积攒了10秒的数量,按照hash分发到不同的worker
long now = System.currentTimeMillis();
Map
for(KeyCountModel model : list) {
model.setCreateTime(now);
Channel channel = WorkerInfoHolder.chooseChannel(model.getRuleKey());
if (channel == null) {
continue;
}
List
newList.add(model);
}
for (Channel channel : map.keySet()) {
try {
List
HotKeyMsg hotKeyMsg = new HotKeyMsg(MessageType.REQUEST_HIT_COUNT, Context.APP_NAME);
hotKeyMsg.setKeyCountModels(batch);
channel.writeAndFlush(hotKeyMsg).sync();
} catch (Exception e) {
try {
InetSocketAddress insocket = (InetSocketAddress) channel.remoteAddress();
JdLogger.error(getClass(),"flush error " + insocket.getAddress().getHostAddress());
} catch (Exception ex) {
JdLogger.error(getClass(),"flush error");
}
}
}
}
}
send(String appName, Listlist) 主要是将TurnKeyCollector收集的待测key通过netty推送给worker,HotKeyModel对象主要是一些热key的元数据信息(热key来源的app和key的类型和是否是删除事件,还有该热key的上报次数) sendCount(String appName, Listlist) 主要是将TurnCountCollector收集的规则所对应的key通过netty推送给worker,KeyCountModel对象主要是一些key所对应的规则信息以及访问次数等 WorkerInfoHolder.chooseChannel(model.getRuleKey()) 根据hash算法获取key对应的服务器,分发到对应服务器相应的Channel 连接,所以服务端可以水平无限扩容,毫无压力问题。
再来分析一下key收集器:TurnKeyCollector与TurnCountCollector: 实现IKeyCollector接口:
/**
* 对hotkey进行聚合
* @author wuweifeng wrote on 2020-01-06
* @version 1.0
*/
public interface IKeyCollector
/**
* 锁定后的返回值
*/
List
/**
* 输入的参数
*/
void collect(T t);
void finishOnce();
}
lockAndGetResult() 主要是获取返回collect方法收集的信息,并将本地暂存的信息清空,方便下个统计周期积攒数据。 collect(T t) 顾名思义他是收集api调用的时候,将收集的到key信息放到本地存储。 finishOnce() 该方法目前实现都是空,无需关注。
待测key收集器:TurnKeyCollector
public class TurnKeyCollector implements IKeyCollector
//这map里面的key主要是热key的名字,value主要是热key的元数据信息(比如:热key来源的app和key的类型和是否是删除事件)
private ConcurrentHashMap
private ConcurrentHashMap
private AtomicLong atomicLong = new AtomicLong(0);
@Override
public List
//自增后,对应的map就会停止被写入,等待被读取
atomicLong.addAndGet(1);
List
//可以观察这里与collect方法里面的相同位置,会发现一个是操作map0一个是操作map1,这样保证在读map的时候,不会阻塞写map,
//两个map同时提供轮流提供读写能力,设计的很巧妙,值得学习
if (atomicLong.get() % 2 == 0) {
list = get(map1);
map1.clear();
} else {
list = get(map0);
map0.clear();
}
return list;
}
private List
return CollectionUtil.list(false, map.values());
}
@Override
public void collect(HotKeyModel hotKeyModel) {
String key = hotKeyModel.getKey();
if (StrUtil.isEmpty(key)) {
return;
}
if (atomicLong.get() % 2 == 0) {
//不存在时返回null并将key-value放入,已有相同key时,返回该key对应的value,并且不覆盖
HotKeyModel model = map0.putIfAbsent(key, hotKeyModel);
if (model != null) {
//增加该hotMey上报的次数
model.add(hotKeyModel.getCount());
}
} else {
HotKeyModel model = map1.putIfAbsent(key, hotKeyModel);
if (model != null) {
model.add(hotKeyModel.getCount());
}
}
}
@Override
public void finishOnce() {}
}
可以看到该类中有两个ConcurrentHashMap和一个AtomicLong,通过对AtomicLong来自增,然后对2取模,来分别控制两个map的读写能力,保证每个map都能做读写,并且同一个map不能同时读写,这样可以避免并发集合读写不阻塞,这一块无锁化的设计还是非常巧妙的,极大的提高了收集的吞吐量。 key数量收集器:TurnCountCollector 这里的设计与TurnKeyCollector大同小异,咱们就不细谈了。值得一提的是它里面有个并行处理的机制,当收集的数量超过DATA_CONVERT_SWITCH_THRESHOLD=5000的阈值时,lockAndGetResult处理是使用java Stream并行流处理,提升处理的效率。
③ 开启worker重连器
//开启worker重连器
WorkerRetryConnector.retryConnectWorkers();
public class WorkerRetryConnector {
/**
* 定时去重连没连上的workers
*/
public static void retryConnectWorkers() {
@SuppressWarnings("PMD.ThreadPoolCreationRule")
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("worker-retry-connector-service-executor", true));
//开启拉取etcd的worker信息,如果拉取失败,则定时继续拉取
scheduledExecutorService.scheduleAtFixedRate(WorkerRetryConnector::reConnectWorkers, 30, 30, TimeUnit.SECONDS);
}
private static void reConnectWorkers() {
List
if (nonList.size() == 0) {
return;
}
JdLogger.info(WorkerRetryConnector.class, "trying to reConnect to these workers :" + nonList);
NettyClient.getInstance().connect(nonList);//这里会触发netty连接方法channelActive
}
}
也是通过定时线程来执行,默认时间间隔是30s,不可设置。 通过WorkerInfoHolder来控制client的worker连接信息,连接信息是个List,用的CopyOnWriteArrayList,毕竟是一个读多写少的场景,类似与元数据信息。
/**
* 保存worker的ip地址和Channel的映射关系,这是有序的。每次client发送消息时,都会根据该map的size进行hash
* 如key-1就发送到workerHolder的第1个Channel去,key-2就发到第2个Channel去
*/
private static final List
④ 注册EventBus事件订阅者
private void registEventBus() {
//netty连接器会关注WorkerInfoChangeEvent事件
EventBusCenter.register(new WorkerChangeSubscriber());
//热key探测回调关注热key事件
EventBusCenter.register(new ReceiveNewKeySubscribe());
//Rule的变化的事件
EventBusCenter.register(new KeyRuleHolder());
}
使用guava的EventBus事件消息总线,利用发布/订阅者模式来对项目进行解耦。它可以利用很少的代码,来实现多组件间通信。 基本原理图如下: 
监听worker信息变动:WorkerChangeSubscriber
/**
* 监听worker信息变动
*/
@Subscribe
public void connectAll(WorkerInfoChangeEvent event) {
List
if (addresses == null) {
addresses = new ArrayList<>();
}
WorkerInfoHolder.mergeAndConnectNew(addresses);
}
/**
* 当client与worker的连接断开后,删除
*/
@Subscribe
public void channelInactive(ChannelInactiveEvent inactiveEvent) {
//获取断线的channel
Channel channel = inactiveEvent.getChannel();
InetSocketAddress socketAddress = (InetSocketAddress) channel.remoteAddress();
String address = socketAddress.getHostName() + ":" + socketAddress.getPort();
JdLogger.warn(getClass(), "this channel is inactive : " + socketAddress + " trying to remove this connection");
WorkerInfoHolder.dealChannelInactive(address);
}

监听热key回调事件:ReceiveNewKeySubscribe
private ReceiveNewKeyListener receiveNewKeyListener = new DefaultNewKeyListener();
@Subscribe
public void newKeyComing(ReceiveNewKeyEvent event) {
HotKeyModel hotKeyModel = event.getModel();
if (hotKeyModel == null) {
return;
}
//收到新key推送
if (receiveNewKeyListener != null) {
receiveNewKeyListener.newKey(hotKeyModel);
}
}
该方法会收到新的热key订阅事件之后,会将其加入到KeyHandlerFactory的收集器里面处理。
核心处理逻辑
@Override
public void newKey(HotKeyModel hotKeyModel) {
long now = System.currentTimeMillis();
//如果key到达时已经过去1秒了,记录一下。手工删除key时,没有CreateTime
if (hotKeyModel.getCreateTime() != 0 && Math.abs(now - hotKeyModel.getCreateTime()) > 1000) {
JdLogger.warn(getClass(), "the key comes too late : " + hotKeyModel.getKey() + " now " +
+now + " keyCreateAt " + hotKeyModel.getCreateTime());
}
if (hotKeyModel.isRemove()) {
//如果是删除事件,就直接删除
deleteKey(hotKeyModel.getKey());
return;
}
//已经是热key了,又推过来同样的热key,做个日志记录,并刷新一下
if (JdHotKeyStore.isHot(hotKeyModel.getKey())) {
JdLogger.warn(getClass(), "receive repeat hot key :" + hotKeyModel.getKey() + " at " + now);
}
addKey(hotKeyModel.getKey());
}
private void deleteKey(String key) {
CacheFactory.getNonNullCache(key).delete(key);
}
private void addKey(String key) {
ValueModel valueModel = ValueModel.defaultValue(key);
if (valueModel == null) {
//不符合任何规则
deleteKey(key);
return;
}
//如果原来该key已经存在了,那么value就被重置,过期时间也会被重置。如果原来不存在,就新增的热key
JdHotKeyStore.setValueDirectly(key, valueModel);
}
如果该HotKeyModel里面是删除事件,则获取RULE_CACHE_MAP里面该key超时时间对应的caffeine,然后从中删除该key缓存,然后返回(这里相当于删除了本地缓存)。
如果不是删除事件,则在RULE_CACHE_MAP对应的caffeine缓存中添加该key的缓存。
这里有个注意点,如果不为删除事件,调用addKey()方法在caffeine增加缓存的时候,value是一个魔术值0x12fcf76,这个值只代表加了这个缓存,但是这个缓存在查询的时候相当于为null。
监听Rule的变化事件:KeyRuleHolder
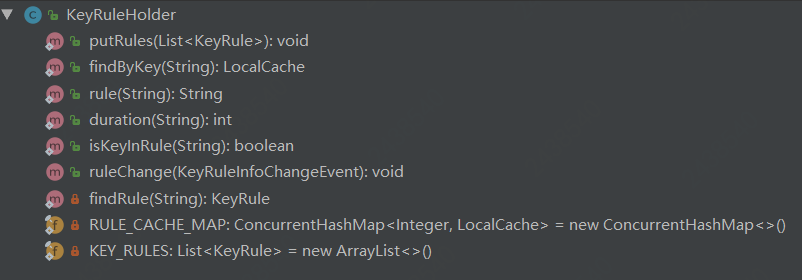
可以看到里面有两个成员属性:RULE_CACHE_MAP,KEY_RULES
/**
* 保存超时时间和caffeine的映射,key是超时时间,value是caffeine[(String,Object)]
*/
private static final ConcurrentHashMap
/**
* 这里KEY_RULES是保存etcd里面该appName所对应的所有rule
*/
private static final List
ConcurrentHashMapRULE_CACHE_MAP:
保存超时时间和caffeine的映射,key是超时时间,value是caffeine[(String,Object)]。
巧妙的设计:这里将key的过期时间作为分桶策略,这样同一个过期时间的key就会在一个桶(caffeine)里面,这里面每一个caffeine都是client的本地缓存,也就是说hotKey的本地缓存的KV实际上是存储在这里面的。
ListKEY_RULES:
这里KEY_RULES是保存etcd里面该appName所对应的所有rule。
具体监听KeyRuleInfoChangeEvent事件方法:
@Subscribe
public void ruleChange(KeyRuleInfoChangeEvent event) {
JdLogger.info(getClass(), "new rules info is :" + event.getKeyRules());
List
if (ruleList == null) {
return;
}
putRules(ruleList);
}
核心处理逻辑
/**
* 所有的规则,如果规则的超时时间变化了,会重建caffeine
*/
public static void putRules(List
synchronized (KEY_RULES) {
//如果规则为空,清空规则表
if (CollectionUtil.isEmpty(keyRules)) {
KEY_RULES.clear();
RULE_CACHE_MAP.clear();
return;
}
KEY_RULES.clear();
KEY_RULES.addAll(keyRules);
Set
for (Integer duration : RULE_CACHE_MAP.keySet()) {
//先清除掉那些在RULE_CACHE_MAP里存的,但是rule里已没有的
if (!durationSet.contains(duration)) {
RULE_CACHE_MAP.remove(duration);
}
}
//遍历所有的规则
for (KeyRule keyRule : keyRules) {
int duration = keyRule.getDuration();
//这里如果RULE_CACHE_MAP里面没有超时时间为duration的value,则新建一个放入到RULE_CACHE_MAP里面
//比如RULE_CACHE_MAP本来就是空的,则在这里来构建RULE_CACHE_MAP的映射关系
//TODO 如果keyRules里面包含相同duration的keyRule,则也只会建一个key为duration,value为caffeine,其中caffeine是(string,object)
if (RULE_CACHE_MAP.get(duration) == null) {
LocalCache cache = CacheFactory.build(duration);
RULE_CACHE_MAP.put(duration, cache);
}
}
}
}
使用synchronized关键字来保证线程安全;
如果规则为空,清空规则表(RULE_CACHE_MAP、KEY_RULES);
使用传递进来的keyRules来覆盖KEY_RULES;
清除掉RULE_CACHE_MAP里面在keyRules没有的映射关系;
遍历所有的keyRules,如果RULE_CACHE_MAP里面没有相关的超时时间key,则在里面赋值;
⑤ 启动EtcdStarter(etcd连接管理器)
EtcdStarter starter = new EtcdStarter();
//与etcd相关的监听都开启
starter.start();
public void start() {
fetchWorkerInfo();
fetchRule();
startWatchRule();
//监听热key事件,只监听手工添加、删除的key
startWatchHotKey();
}
fetchWorkerInfo() 从etcd里面拉取worker集群地址信息allAddress,并更新WorkerInfoHolder里面的WORKER_HOLDER
/**
* 每隔30秒拉取worker信息
*/
private void fetchWorkerInfo() {
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
//开启拉取etcd的worker信息,如果拉取失败,则定时继续拉取
scheduledExecutorService.scheduleAtFixedRate(() -> {
JdLogger.info(getClass(), "trying to connect to etcd and fetch worker info");
fetch();
}, 0, 30, TimeUnit.SECONDS);
}
使用定时线程池来执行,单线程。
定时从etcd里面获取,地址/jd/workers/+$appName或default,时间间隔不可设置,默认30秒,这里面存储的是worker地址的ip+port。
发布WorkerInfoChangeEvent事件。
备注:地址有$appName或default,在worker里面配置,如果把worker放到某个appName下,则该worker只会参与该app的计算。
fetchRule() 定时线程来执行,单线程,时间间隔不可设置,默认是5秒,当拉取规则配置和手动配置的hotKey成功后,该线程被终止(也就是说只会成功执行一次),执行失败继续执行
private void fetchRule() {
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
//开启拉取etcd的worker信息,如果拉取失败,则定时继续拉取
scheduledExecutorService.scheduleAtFixedRate(() -> {
JdLogger.info(getClass(), "trying to connect to etcd and fetch rule info");
boolean success = fetchRuleFromEtcd();
if (success) {
//拉取已存在的热key
fetchExistHotKey();
//这里如果拉取规则和拉取手动配置的hotKey成功之后,则该定时执行线程停止
scheduledExecutorService.shutdown();
}
}, 0, 5, TimeUnit.SECONDS);
}
fetchRuleFromEtcd()
从etcd里面获取该appName配置的rule规则,地址/jd/rules/+$appName。
如果查出来规则rules为空,会通过发布KeyRuleInfoChangeEvent事件来清空本地的rule配置缓存和所有的规则key缓存。
发布KeyRuleInfoChangeEvent事件。
fetchExistHotKey()
从etcd里面获取该appName手动配置的热key,地址/jd/hotkeys/+$appName。
发布ReceiveNewKeyEvent事件,并且内容HotKeyModel不是删除事件。
startWatchRule()
/**
* 异步监听rule规则变化
*/
private void startWatchRule() {
ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.submit(() -> {
JdLogger.info(getClass(), "--- begin watch rule change ----");
try {
IConfigCenter configCenter = EtcdConfigFactory.configCenter();
KvClient.WatchIterator watchIterator = configCenter.watch(ConfigConstant.rulePath + Context.APP_NAME);
//如果有新事件,即rule的变更,就重新拉取所有的信息
while (watchIterator.hasNext()) {
//这句必须写,next会让他卡住,除非真的有新rule变更
WatchUpdate watchUpdate = watchIterator.next();
List
JdLogger.info(getClass(), "rules info changed. begin to fetch new infos. rule change is " + eventList);
//全量拉取rule信息
fetchRuleFromEtcd();
}
} catch (Exception e) {
JdLogger.error(getClass(), "watch err");
}
});
}
异步监听rule规则变化,使用etcd监听地址为/jd/rules/+$appName的节点变化。
使用线程池,单线程,异步监听rule规则变化,如果有事件变化,则调用fetchRuleFromEtcd()方法。
startWatchHotKey() 异步开始监听热key变化信息,使用etcd监听地址前缀为/jd/hotkeys/+$appName
/**
* 异步开始监听热key变化信息,该目录里只有手工添加的key信息
*/
private void startWatchHotKey() {
ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.submit(() -> {
JdLogger.info(getClass(), "--- begin watch hotKey change ----");
IConfigCenter configCenter = EtcdConfigFactory.configCenter();
try {
KvClient.WatchIterator watchIterator = configCenter.watchPrefix(ConfigConstant.hotKeyPath + Context.APP_NAME);
//如果有新事件,即新key产生或删除
while (watchIterator.hasNext()) {
WatchUpdate watchUpdate = watchIterator.next();
List
KeyValue keyValue = eventList.get(0).getKv();
Event.EventType eventType = eventList.get(0).getType();
try {
//从这个地方可以看出,etcd给的返回是节点的全路径,而我们需要的key要去掉前缀
String key = keyValue.getKey().toStringUtf8().replace(ConfigConstant.hotKeyPath + Context.APP_NAME + "/", "");
//如果是删除key,就立刻删除
if (Event.EventType.DELETE == eventType) {
HotKeyModel model = new HotKeyModel();
model.setRemove(true);
model.setKey(key);
EventBusCenter.getInstance().post(new ReceiveNewKeyEvent(model));
} else {
HotKeyModel model = new HotKeyModel();
model.setRemove(false);
String value = keyValue.getValue().toStringUtf8();
//新增热key
JdLogger.info(getClass(), "etcd receive new key : " + key + " --value:" + value);
//如果这是一个删除指令,就什么也不干
//TODO 这里有个疑问,监听到worker自动探测发出的惰性删除指令,这里之间跳过了,但是本地缓存没有更新吧?
//TODO 所以我猜测在客户端使用判断缓存是否存在的api里面,应该会判断相关缓存的value值是否为"#[DELETE]#"删除标记
//解疑:这里确实只监听手工配置的hotKey,etcd的/jd/hotkeys/+$appName该地址只是手动配置hotKey,worker自动探测的hotKey是直接通过netty通道来告知client的
if (Constant.DEFAULT_DELETE_VALUE.equals(value)) {
continue;
}
//手工创建的value是时间戳
model.setCreateTime(Long.valueOf(keyValue.getValue().toStringUtf8()));
model.setKey(key);
EventBusCenter.getInstance().post(new ReceiveNewKeyEvent(model));
}
} catch (Exception e) {
JdLogger.error(getClass(), "new key err :" + keyValue);
}
}
} catch (Exception e) {
JdLogger.error(getClass(), "watch err");
}
});
}
使用线程池,单线程,异步监听热key变化
使用etcd监听前缀地址的当前节点以及子节点的所有变化值
删除节点动作
发布ReceiveNewKeyEvent事件,并且内容HotKeyModel是删除事件
新增or更新节点动作
事件变化的value值为删除标记#[DELETE]#
如果是删除标记的话,代表是worker自动探测或者client需要删除的指令。
如果是删除标记则什么也不做,直接跳过(这里从HotKeyPusher#push方法可以看到,做删除事件的操作时候,他会给/jd/hotkeys/+$appName的节点里面增加一个值为删除标记的节点,然后再删除相同路径的节点,这样就可以触发上面的删除节点事件,所以这里判断如果是删除标记直接跳过)。
不为删除标记
发布ReceiveNewKeyEvent事件,事件内容HotKeyModel里面的createTime是kv对应的时间戳
疑问: 这里代码注释里面说只监听手工添加或者删除的hotKey,难道说/jd/hotkeys/+$appName地址只是手工配置的地址吗? 解疑: 这里确实只监听手工配置的hotKey,etcd的/jd/hotkeys/+$appName该地址只是手动配置hotKey,worker自动探测的hotKey是直接通过netty通道来告知client的
5.API解析
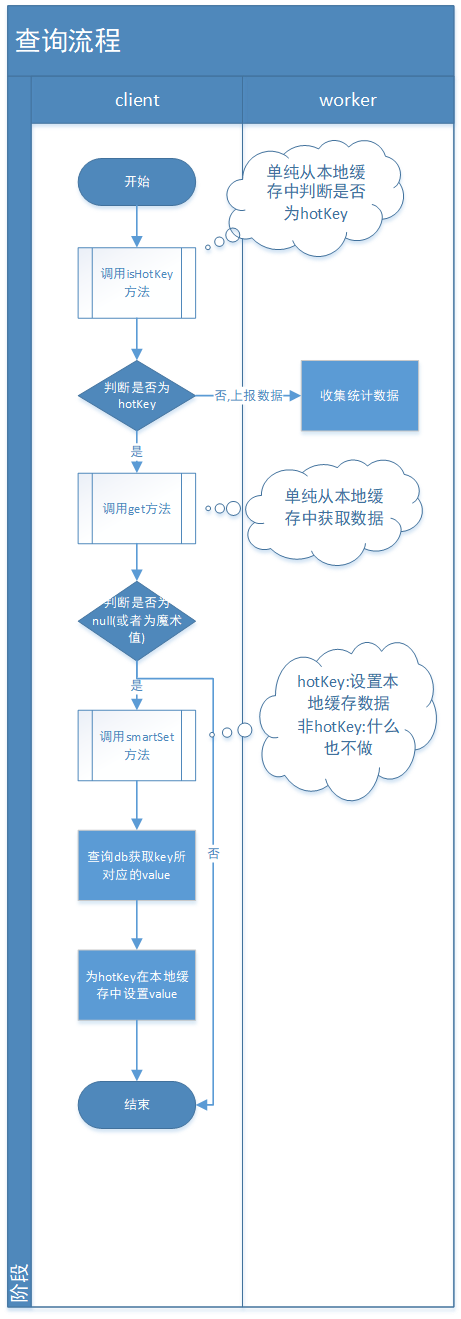
1)流程图示 ① 查询流程
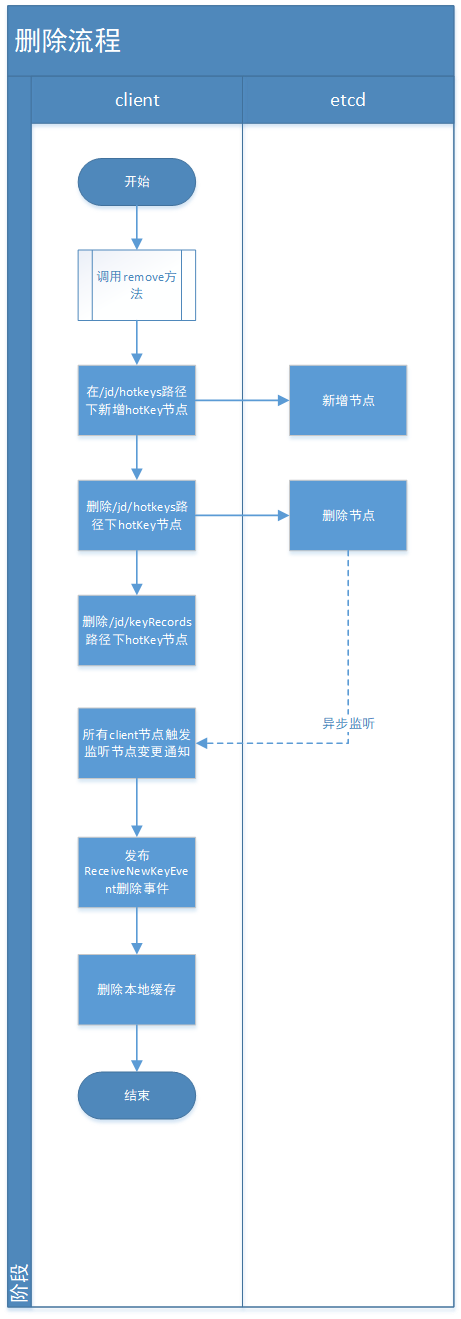
② 删除流程:
从上面的流程图中,大家应该知道该热点key在代码中是如何扭转的,这里再给大家讲解一下核心API的源码解析,限于篇幅的原因,咱们不一个个贴相关源码了,只是单纯的告诉你它的内部逻辑是怎么样的。 2)核心类:JdHotKeyStore
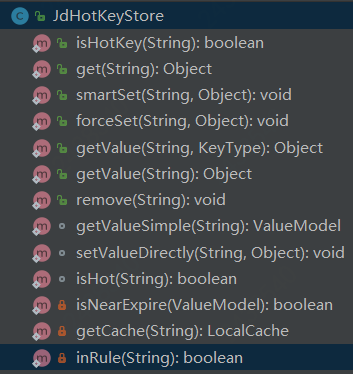
JdHotKeyStore是封装client调用的api核心类,包含上面10个公共方法,咱们重点解析其中6个重要方法: ① isHotKey(String key) 判断是否在规则内,如果不在返回false 判断是否是热key,如果不是或者是且过期时间在2s内,则给TurnKeyCollector#collect收集 最后给TurnCountCollector#collect做统计收集 ② get(String key) 从本地caffeine取值 如果取到的value是个魔术值,只代表加入到caffeine缓存里面了,查询的话为null ③ smartSet(String key, Object value) 判断是否是热key,这里不管它在不在规则内,如果是热key,则给value赋值,如果不为热key什么也不做 ④ forceSet(String key, Object value) 强制给value赋值 如果该key不在规则配置内,则传递的value不生效,本地缓存的赋值value会被变为null ⑤ getValue(String key, KeyType keyType) 获取value,如果value不存在则调用HotKeyPusher#push方法发往netty 如果没有为该key配置规则,就不用上报key,直接返回null 如果取到的value是个魔术值,只代表加入到caffeine缓存里面了,查询的话为null ⑥ remove(String key) 删除某key(本地的caffeine缓存),会通知整个集群删除(通过etcd来通知集群删除) 3)client上传热key入口调用类:HotKeyPusher 核心方法:
public static void push(String key, KeyType keyType, int count, boolean remove) {
if (count <= 0) {
count = 1;
}
if (keyType == null) {
keyType = KeyType.REDIS_KEY;
}
if (key == null) {
return;
}
//这里之所以用LongAdder是为了保证多线程计数的线程安全性,虽然这里是在方法内调用的,但是在TurnKeyCollector的两个map里面,
//存储了HotKeyModel的实例对象,这样在多个线程同时修改count的计数属性时,会存在线程安全计数不准确问题
LongAdder adderCnt = new LongAdder();
adderCnt.add(count);
HotKeyModel hotKeyModel = new HotKeyModel();
hotKeyModel.setAppName(Context.APP_NAME);
hotKeyModel.setKeyType(keyType);
hotKeyModel.setCount(adderCnt);
hotKeyModel.setRemove(remove);
hotKeyModel.setKey(key);
if (remove) {
//如果是删除key,就直接发到etcd去,不用做聚合。但是有点问题现在,这个删除只能删手工添加的key,不能删worker探测出来的
//因为各个client都在监听手工添加的那个path,没监听自动探测的path。所以如果手工的那个path下,没有该key,那么是删除不了的。
//删不了,就达不到集群监听删除事件的效果,怎么办呢?可以通过新增的方式,新增一个热key,然后删除它
//TODO 这里为啥不直接删除该节点,难道worker自动探测处理的hotKey不会往该节点增加新增事件吗?
//释疑:worker根据探测配置的规则,当判断出某个key为hotKey后,确实不会往keyPath里面加入节点,他只是单纯的往本地缓存里面加入一个空值,代表是热点key
EtcdConfigFactory.configCenter().putAndGrant(HotKeyPathTool.keyPath(hotKeyModel), Constant.DEFAULT_DELETE_VALUE, 1);
EtcdConfigFactory.configCenter().delete(HotKeyPathTool.keyPath(hotKeyModel));//TODO 这里很巧妙待补充描述
//也删worker探测的目录
EtcdConfigFactory.configCenter().delete(HotKeyPathTool.keyRecordPath(hotKeyModel));
} else {
//如果key是规则内的要被探测的key,就积累等待传送
if (KeyRuleHolder.isKeyInRule(key)) {
//积攒起来,等待每半秒发送一次
KeyHandlerFactory.getCollector().collect(hotKeyModel);
}
}
}
从上面的源码中可知:
这里之所以用LongAdder是为了保证多线程计数的线程安全性,虽然这里是在方法内调用的,但是在TurnKeyCollector的两个map里面,存储了HotKeyModel的实例对象,这样在多个线程同时修改count的计数属性时,会存在线程安全计数不准确问题。
如果是remove删除类型,在删除手动配置的热key配置路径的同时,还会删除dashboard展示热key的配置路径。
只有在规则配置的key,才会被积攒探测发送到worker内进行计算。
6.通讯机制(与worker交互)
1)NettyClient:netty连接器
public class NettyClient {
private static final NettyClient nettyClient = new NettyClient();
private Bootstrap bootstrap;
public static NettyClient getInstance() {
return nettyClient;
}
private NettyClient() {
if (bootstrap == null) {
bootstrap = initBootstrap();
}
}
private Bootstrap initBootstrap() {
//少线程
EventLoopGroup group = new NioEventLoopGroup(2);
Bootstrap bootstrap = new Bootstrap();
NettyClientHandler nettyClientHandler = new NettyClientHandler();
bootstrap.group(group).channel(NioSocketChannel.class)
.option(ChannelOption.SO_KEEPALIVE, true)
.option(ChannelOption.TCP_NODELAY, true)
.handler(new ChannelInitializer
@Override
protected void initChannel(SocketChannel ch) {
ByteBuf delimiter = Unpooled.copiedBuffer(Constant.DELIMITER.getBytes());
ch.pipeline()
.addLast(new DelimiterBasedFrameDecoder(Constant.MAX_LENGTH, delimiter))//这里就是定义TCP多个包之间的分隔符,为了更好的做拆包
.addLast(new MsgDecoder())
.addLast(new MsgEncoder())
//30秒没消息时,就发心跳包过去
.addLast(new IdleStateHandler(0, 0, 30))
.addLast(nettyClientHandler);
}
});
return bootstrap;
}
}
使用Reactor线程模型,只有2个工作线程,没有单独设置主线程
长连接,开启TCP_NODELAY
netty的分隔符”$()$”,类似TCP报文分段的标准,方便拆包
Protobuf序列化与反序列化
30s没有消息发给对端的时候,发送一个心跳包判活
工作线程处理器NettyClientHandler
JDhotkey的tcp协议设计就是收发字符串,每个tcp消息包使用特殊字符$()$来分割 优点:这样实现非常简单。 获得消息包后进行json或者protobuf反序列化。 缺点:是需要,从字节流-》反序列化成字符串-》反序列化成消息对象,两层序列化损耗了一部分性能。 protobuf还好序列化很快,但是json序列化的速度只有几十万每秒,会损耗一部分性能。 2)NettyClientHandler:工作线程处理器
@ChannelHandler.Sharable
public class NettyClientHandler extends SimpleChannelInboundHandler
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
if (evt instanceof IdleStateEvent) {
IdleStateEvent idleStateEvent = (IdleStateEvent) evt;
//这里表示如果读写都挂了
if (idleStateEvent.state() == IdleState.ALL_IDLE) {
//向服务端发送消息
ctx.writeAndFlush(new HotKeyMsg(MessageType.PING, Context.APP_NAME));
}
}
super.userEventTriggered(ctx, evt);
}
//在Channel注册EventLoop、绑定SocketAddress和连接ChannelFuture的时候都有可能会触发ChannelInboundHandler的channelActive方法的调用
//类似TCP三次握手成功之后触发
@Override
public void channelActive(ChannelHandlerContext ctx) {
JdLogger.info(getClass(), "channelActive:" + ctx.name());
ctx.writeAndFlush(new HotKeyMsg(MessageType.APP_NAME, Context.APP_NAME));
}
//类似TCP四次挥手之后,等待2MSL时间之后触发(大概180s),比如channel通道关闭会触发(channel.close())
//客户端channel主动关闭连接时,会向服务端发送一个写请求,然后服务端channel所在的selector会监听到一个OP_READ事件,然后
//执行数据读取操作,而读取时发现客户端channel已经关闭了,则读取数据字节个数返回-1,然后执行close操作,关闭该channel对应的底层socket,
//并在pipeline中,从head开始,往下将InboundHandler,并触发handler的channelInactive和channelUnregistered方法的执行,以及移除pipeline中的handlers一系列操作。
@Override
public void channelInactive(ChannelHandlerContext ctx) throws Exception {
super.channelInactive(ctx);
//断线了,可能只是client和server断了,但都和etcd没断。也可能是client自己断网了,也可能是server断了
//发布断线事件。后续10秒后进行重连,根据etcd里的worker信息来决定是否重连,如果etcd里没了,就不重连。如果etcd里有,就重连
notifyWorkerChange(ctx.channel());
}
private void notifyWorkerChange(Channel channel) {
EventBusCenter.getInstance().post(new ChannelInactiveEvent(channel));
}
@Override
protected void channelRead0(ChannelHandlerContext channelHandlerContext, HotKeyMsg msg) {
if (MessageType.PONG == msg.getMessageType()) {
JdLogger.info(getClass(), "heart beat");
return;
}
if (MessageType.RESPONSE_NEW_KEY == msg.getMessageType()) {
JdLogger.info(getClass(), "receive new key : " + msg);
if (CollectionUtil.isEmpty(msg.getHotKeyModels())) {
return;
}
for (HotKeyModel model : msg.getHotKeyModels()) {
EventBusCenter.getInstance().post(new ReceiveNewKeyEvent(model));
}
}
}
}
userEventTriggered
收到对端发来的心跳包,返回new HotKeyMsg(MessageType.PING, Context.APP_NAME)
channelActive
在Channel注册EventLoop、绑定SocketAddress和连接ChannelFuture的时候都有可能会触发ChannelInboundHandler的channelActive方法的调用
类似TCP三次握手成功之后触发,给对端发送new HotKeyMsg(MessageType.APP_NAME, Context.APP_NAME)
channelInactive
类似TCP四次挥手之后,等待2MSL时间之后触发(大概180s),比如channel通道关闭会触发(channel.close())该方法,发布ChannelInactiveEvent事件,来10s后重连
channelRead0
接收PONG消息类型时,打个日志返回
接收RESPONSE_NEW_KEY消息类型时,发布ReceiveNewKeyEvent事件
3.3.3 worker端
1.入口启动加载:7个@PostConstruct
1)worker端对etcd相关的处理:EtcdStarter ① 第一个@PostConstruct:watchLog()
@PostConstruct
public void watchLog() {
AsyncPool.asyncDo(() -> {
try {
//取etcd的是否开启日志配置,地址/jd/logOn
String loggerOn = configCenter.get(ConfigConstant.logToggle);
LOGGER_ON = "true".equals(loggerOn) || "1".equals(loggerOn);
} catch (StatusRuntimeException ex) {
logger.error(ETCD_DOWN);
}
//监听etcd地址/jd/logOn是否开启日志配置,并实时更改开关
KvClient.WatchIterator watchIterator = configCenter.watch(ConfigConstant.logToggle);
while (watchIterator.hasNext()) {
WatchUpdate watchUpdate = watchIterator.next();
List
KeyValue keyValue = eventList.get(0).getKv();
logger.info("log toggle changed : " + keyValue);
String value = keyValue.getValue().toStringUtf8();
LOGGER_ON = "true".equals(value) || "1".equals(value);
}
});
}
放到线程池里面异步执行
取etcd的是否开启日志配置,地址/jd/logOn,默认true
监听etcd地址/jd/logOn是否开启日志配置,并实时更改开关
由于有etcd的监听,所以会一直执行,而不是执行一次结束
② 第二个@PostConstruct:watch()
/**
* 启动回调监听器,监听rule变化
*/
@PostConstruct
public void watch() {
AsyncPool.asyncDo(() -> {
KvClient.WatchIterator watchIterator;
if (isForSingle()) {
watchIterator = configCenter.watch(ConfigConstant.rulePath + workerPath);
} else {
watchIterator = configCenter.watchPrefix(ConfigConstant.rulePath);
}
while (watchIterator.hasNext()) {
WatchUpdate watchUpdate = watchIterator.next();
List
KeyValue keyValue = eventList.get(0).getKv();
logger.info("rule changed : " + keyValue);
try {
ruleChange(keyValue);
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
/**
* rule发生变化时,更新缓存的rule
*/
private synchronized void ruleChange(KeyValue keyValue) {
String appName = keyValue.getKey().toStringUtf8().replace(ConfigConstant.rulePath, "");
if (StrUtil.isEmpty(appName)) {
return;
}
String ruleJson = keyValue.getValue().toStringUtf8();
List
KeyRuleHolder.put(appName, keyRules);
}
通过etcd.workerPath配置,来判断该worker是否为某个app单独服务的,默认为”default”,如果是默认值,代表该worker参与在etcd上所有app client的计算,否则只为某个app来服务计算 使用etcd来监听rule规则变化,如果是共享的worker,监听地址前缀为”/jd/rules/“,如果为某个app独享,监听地址为”/jd/rules/“+$etcd.workerPath 如果规则变化,则修改对应app在本地存储的rule缓存,同时清理该app在本地存储的KV缓存
KeyRuleHolder:rule缓存本地存储
Map,>
相对于client的KeyRuleHolder的区别:worker是存储所有app规则,每个app对应一个规则桶,所以用map
CaffeineCacheHolder:key缓存本地存储
Map,>
相对于client的caffeine,第一是worker没有做缓存接口比如LocalCache,第二是client的map的kv分别是超时时间、以及相同超时时间所对应key的缓存桶
放到线程池里面异步执行,由于有etcd的监听,所以会一直执行,而不是执行一次结束
③ 第三个@PostConstruct:watchWhiteList()
/**
* 启动回调监听器,监听白名单变化,只监听自己所在的app,白名单key不参与热key计算,直接忽略
*/
@PostConstruct
public void watchWhiteList() {
AsyncPool.asyncDo(() -> {
//从etcd配置中获取所有白名单
fetchWhite();
KvClient.WatchIterator watchIterator = configCenter.watch(ConfigConstant.whiteListPath + workerPath);
while (watchIterator.hasNext()) {
WatchUpdate watchUpdate = watchIterator.next();
logger.info("whiteList changed ");
try {
fetchWhite();
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
拉取并监听etcd白名单key配置,地址为/jd/whiteList/+$etcd.workerPath
在白名单的key,不参与热key计算,直接忽略
放到线程池里面异步执行,由于有etcd的监听,所以会一直执行,而不是执行一次结束 ④ 第四个@PostConstruct:makeSureSelfOn()
/**
* 每隔一会去check一下,自己还在不在etcd里
*/
@PostConstruct
public void makeSureSelfOn() {
//开启上传worker信息
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
scheduledExecutorService.scheduleAtFixedRate(() -> {
try {
if (canUpload) {
uploadSelfInfo();
}
} catch (Exception e) {
//do nothing
}
}, 0, 5, TimeUnit.SECONDS);
}
在线程池里面异步执行,定时执行,时间间隔为5s
将本机woker的hostName,ip+port以kv的形式定时上报给etcd,地址为/jd/workers/+$etcd.workPath+”/“+$hostName,续期时间为8s
有一个canUpload的开关来控制worker是否向etcd来定时续期,如果这个开关关闭了,代表worker不向etcd来续期,这样当上面地址的kv到期之后,etcd会删除该节点,这样client循环判断worker信息变化了
2)将热key推送到dashboard供入库:DashboardPusher ① 第五个@PostConstruct:uploadToDashboard()
@Component
public class DashboardPusher implements IPusher {
/**
* 热key集中营
*/
private static LinkedBlockingQueue
@PostConstruct
public void uploadToDashboard() {
AsyncPool.asyncDo(() -> {
while (true) {
try {
//要么key达到1千个,要么达到1秒,就汇总上报给etcd一次
List
Queues.drain(hotKeyStoreQueue, tempModels, 1000, 1, TimeUnit.SECONDS);
if (CollectionUtil.isEmpty(tempModels)) {
continue;
}
//将热key推到dashboard
DashboardHolder.flushToDashboard(FastJsonUtils.convertObjectToJSON(tempModels));
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
}
当热key的数量达到1000或者每隔1s,把热key的数据通过与dashboard的netty通道来发送给dashboard,数据类型为REQUEST_HOT_KEY
LinkedBlockingQueue
hotKeyStoreQueue:worker计算的给dashboard热key的集中营,所有给dashboard推送热key存储在里面 3)推送到各客户端服务器:AppServerPusher ① 第六个@PostConstruct:batchPushToClient()
public class AppServerPusher implements IPusher {
/**
* 热key集中营
*/
private static LinkedBlockingQueue
/**
* 和dashboard那边的推送主要区别在于,给app推送每10ms一次,dashboard那边1s一次
*/
@PostConstruct
public void batchPushToClient() {
AsyncPool.asyncDo(() -> {
while (true) {
try {
List
//每10ms推送一次
Queues.drain(hotKeyStoreQueue, tempModels, 10, 10, TimeUnit.MILLISECONDS);
if (CollectionUtil.isEmpty(tempModels)) {
continue;
}
Map
//拆分出每个app的热key集合,按app分堆
for (HotKeyModel hotKeyModel : tempModels) {
List
oneAppModels.add(hotKeyModel);
}
//遍历所有app,进行推送
for (AppInfo appInfo : ClientInfoHolder.apps) {
List
if (CollectionUtil.isEmpty(list)) {
continue;
}
HotKeyMsg hotKeyMsg = new HotKeyMsg(MessageType.RESPONSE_NEW_KEY);
hotKeyMsg.setHotKeyModels(list);
//整个app全部发送
appInfo.groupPush(hotKeyMsg);
}
//推送完,及时清理不使用内存
allAppHotKeyModels = null;
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
}
会按照key的appName来进行分组,然后通过对应app的channelGroup来推送
当热key的数量达到10或者每隔10ms,把热key的数据通过与app的netty通道来发送给app,数据类型为RESPONSE_NEW_KEY
LinkedBlockingQueue
hotKeyStoreQueue:worker计算的给client热key的集中营,所有给client推送热key存储在里面 4)client实例节点处理:NodesServerStarter ① 第七个@PostConstruct:start()
public class NodesServerStarter {
@Value("${netty.port}")
private int port;
private Logger logger = LoggerFactory.getLogger(getClass());
@Resource
private IClientChangeListener iClientChangeListener;
@Resource
private List
@PostConstruct
public void start() {
AsyncPool.asyncDo(() -> {
logger.info("netty server is starting");
NodesServer nodesServer = new NodesServer();
nodesServer.setClientChangeListener(iClientChangeListener);
nodesServer.setMessageFilters(messageFilters);
try {
nodesServer.startNettyServer(port);
} catch (Exception e) {
e.printStackTrace();
}
});
}
}
线程池里面异步执行,启动client端的nettyServer
iClientChangeListener和messageFilters这两个依赖最终会被传递到netty消息处理器里面,iClientChangeListener会作为channel下线处理来删除ClientInfoHolder下线或者超时的通道,messageFilters会作为netty收到事件消息的处理过滤器(责任链模式) ② 依赖的bean:IClientChangeListener iClientChangeListener
public interface IClientChangeListener {
/**
* 发现新连接
*/
void newClient(String appName, String channelId, ChannelHandlerContext ctx);
/**
* 客户端掉线
*/
void loseClient(ChannelHandlerContext ctx);
}
对客户端的管理,新来(newClient)(会触发netty的连接方法channelActive)、断线(loseClient)(会触发netty的断连方法channelInactive())的管理 client的连接信息主要是在ClientInfoHolder里面
List
apps,这里面的AppInfo主要是appName和对应的channelGroup
对apps的add和remove主要是通过新来(newClient)、断线(loseClient) ③ 依赖的bean:List
messageFilters
/**
* 对netty来的消息,进行过滤处理
* @author wuweifeng wrote on 2019-12-11
* @version 1.0
*/
public interface INettyMsgFilter {
boolean chain(HotKeyMsg message, ChannelHandlerContext ctx);
}
对client发给worker的netty消息,进行过滤处理,共有四个实现类,也就是说底下四个过滤器都是收到client发送的netty消息来做处理 ④ 各个消息处理的类型:MessageType
APP_NAME((byte) 1),
REQUEST_NEW_KEY((byte) 2),
RESPONSE_NEW_KEY((byte) 3),
REQUEST_HIT_COUNT((byte) 7), //命中率
REQUEST_HOT_KEY((byte) 8), //热key,worker->dashboard
PING((byte) 4), PONG((byte) 5),
EMPTY((byte) 6);
顺序1:HeartBeatFilter
当消息类型为PING,则给对应的client示例返回PONG
顺序2:AppNameFilter
当消息类型为APP_NAME,代表client与worker建立连接成功,然后调用iClientChangeListener的newClient方法增加apps元数据信息
顺序3:HotKeyFilter
处理接收消息类型为REQUEST_NEW_KEY
先给HotKeyFilter.totalReceiveKeyCount原子类增1,该原子类代表worker实例接收到的key的总数
publishMsg方法,将消息通过自建的生产者消费者模型(KeyProducer,KeyConsumer),来把消息给发到生产者中分发消费
接收到的消息HotKeyMsg里面List
首先判断HotKeyModel里面的key是否在白名单内,如果在则跳过,否则将HotKeyModel通过KeyProducer发送
顺序4:KeyCounterFilter
处理接收类型为REQUEST_HIT_COUNT
这个过滤器是专门给dashboard来汇算key的,所以这个appName直接设置为该worker配置的appName
该过滤器的数据来源都是client的NettyKeyPusher#sendCount(String appName, List
list),这里面的数据都是默认积攒10s的,这个10s是可以配置的,这一点在client里面有讲
将构造的new KeyCountItem(appName, models.get(0).getCreateTime(), models)放到阻塞队列LinkedBlockingQueue
COUNTER_QUEUE中,然后让CounterConsumer来消费处理,消费逻辑是单线程的
CounterConsumer:热key统计消费者
放在公共线程池中,来单线程执行
从阻塞队列COUNTER_QUEUE里面取数据,然后将里面的key的统计数据发布到etcd的/jd/keyHitCount/+ appName + “/“ + IpUtils.getIp() + “-“ + System.currentTimeMillis()里面,该路径是worker服务的client集群或者default,用来存放客户端hotKey访问次数和总访问次数的path,然后让dashboard来订阅统计展示
2.三个定时任务:3个@Scheduled
1)定时任务1:EtcdStarter#pullRules()
/**
* 每隔1分钟拉取一次,所有的app的rule
*/
@Scheduled(fixedRate = 60000)
public void pullRules() {
try {
if (isForSingle()) {
String value = configCenter.get(ConfigConstant.rulePath + workerPath);
if (!StrUtil.isEmpty(value)) {
List
KeyRuleHolder.put(workerPath, keyRules);
}
} else {
List
for (KeyValue keyValue : keyValues) {
ruleChange(keyValue);
}
}
} catch (StatusRuntimeException ex) {
logger.error(ETCD_DOWN);
}
}
每隔1分钟拉取一次etcd地址为/jd/rules/的规则变化,如果worker所服务的app或者default的rule有变化,则更新规则的缓存,并清空该appName所对应的本地key缓存 2)定时任务2:EtcdStarter#uploadClientCount()
/**
* 每隔10秒上传一下client的数量到etcd中
*/
@Scheduled(fixedRate = 10000)
public void uploadClientCount() {
try {
String ip = IpUtils.getIp();
for (AppInfo appInfo : ClientInfoHolder.apps) {
String appName = appInfo.getAppName();
int count = appInfo.size();
//即便是full gc也不能超过3秒,因为这里给的过期时间是13s,由于该定时任务每隔10s执行一次,如果full gc或者说上报给etcd的时间超过3s,
//则在dashboard查询不到client的数量
configCenter.putAndGrant(ConfigConstant.clientCountPath + appName + "/" + ip, count + "", 13);
}
configCenter.putAndGrant(ConfigConstant.caffeineSizePath + ip, FastJsonUtils.convertObjectToJSON(CaffeineCacheHolder.getSize()), 13);
//上报每秒QPS(接收key数量、处理key数量)
String totalCount = FastJsonUtils.convertObjectToJSON(new TotalCount(HotKeyFilter.totalReceiveKeyCount.get(), totalDealCount.longValue()));
configCenter.putAndGrant(ConfigConstant.totalReceiveKeyCount + ip, totalCount, 13);
logger.info(totalCount + " expireCount:" + expireTotalCount + " offerCount:" + totalOfferCount);
//如果是稳定一直有key发送的应用,建议开启该监控,以避免可能发生的网络故障
if (openMonitor) {
checkReceiveKeyCount();
}
// configCenter.putAndGrant(ConfigConstant.bufferPoolPath + ip, MemoryTool.getBufferPool() + "", 10);
} catch (Exception ex) {
logger.error(ETCD_DOWN);
}
}
每个10s将worker计算存储的client信息上报给etcd,来方便dashboard来查询展示,比如/jd/count/对应client数量,/jd/caffeineSize/对应caffeine缓存的大小,/jd/totalKeyCount/对应该worker接收的key总量和处理的key总量
可以从代码中看到,上面所有etcd的节点租期时间都是13s,而该定时任务是每10s执行一次,意味着如果full gc或者说上报给etcd的时间超过3s,则在dashboard查询不到client的相关汇算信息
长时间不收到key,判断网络状态不好,断开worker给etcd地址为/jd/workers/+$workerPath节点的续租,因为client会循环判断该地址的节点是否变化,使得client重新连接worker或者断开失联的worker 3)定时任务3:EtcdStarter#fetchDashboardIp()
/**
* 每隔30秒去获取一下dashboard的地址
*/
@Scheduled(fixedRate = 30000)
public void fetchDashboardIp() {
try {
//获取DashboardIp
List
//是空,给个警告
if (CollectionUtil.isEmpty(keyValues)) {
logger.warn("very important warn !!! Dashboard ip is null!!!");
return;
}
String dashboardIp = keyValues.get(0).getValue().toStringUtf8();
NettyClient.getInstance().connect(dashboardIp);
} catch (Exception e) {
e.printStackTrace();
}
}
每隔30s拉取一次etcd前缀为/jd/dashboard/的dashboard连接ip的值,并且判断DashboardHolder.hasConnected里面是否为未连接状态,如果是则重新连接worker与dashboard的netty通道
3.自建的生产者消费者模型(KeyProducer,KeyConsumer)
一般生产者消费者模型包含三大元素:生产者、消费者、消息存储队列 这里消息存储队列是DispatcherConfig里面的QUEUE,使用LinkedBlockingQueue,默认大小为200W 1)KeyProducer
@Component
public class KeyProducer {
public void push(HotKeyModel model, long now) {
if (model == null || model.getKey() == null) {
return;
}
//5秒前的过时消息就不处理了
if (now - model.getCreateTime() > InitConstant.timeOut) {
expireTotalCount.increment();
return;
}
try {
QUEUE.put(model);
totalOfferCount.increment();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
判断接收到的HotKeyModel是否超出”netty.timeOut”配置的时间,如果是将expireTotalCount纪录过期总数给自增,然后返回 2)KeyConsumer
public class KeyConsumer {
private IKeyListener iKeyListener;
public void setKeyListener(IKeyListener iKeyListener) {
this.iKeyListener = iKeyListener;
}
public void beginConsume() {
while (true) {
try {
//从这里可以看出,这里的生产者消费者模型,本质上还是拉模式,之所以不使用EventBus,是因为需要队列来做缓冲
HotKeyModel model = QUEUE.take();
if (model.isRemove()) {
iKeyListener.removeKey(model, KeyEventOriginal.CLIENT);
} else {
iKeyListener.newKey(model, KeyEventOriginal.CLIENT);
}
//处理完毕,将数量加1
totalDealCount.increment();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
@Override
public void removeKey(HotKeyModel hotKeyModel, KeyEventOriginal original) {
//cache里的key,appName+keyType+key
String key = buildKey(hotKeyModel);
hotCache.invalidate(key);
CaffeineCacheHolder.getCache(hotKeyModel.getAppName()).invalidate(key);
//推送所有client删除
hotKeyModel.setCreateTime(SystemClock.now());
logger.info(DELETE_KEY_EVENT + hotKeyModel.getKey());
for (IPusher pusher : iPushers) {
//这里可以看到,删除热key的netty消息只给client端发了过去,没有给dashboard发过去(DashboardPusher里面的remove是个空方法)
pusher.remove(hotKeyModel);
}
}
@Override
public void newKey(HotKeyModel hotKeyModel, KeyEventOriginal original) {
//cache里的key
String key = buildKey(hotKeyModel);
//判断是不是刚热不久
//hotCache对应的caffeine有效期为5s,也就是说该key会保存5s,在5s内不重复处理相同的hotKey。
//毕竟hotKey都是瞬时流量,可以避免在这5s内重复推送给client和dashboard,避免无效的网络开销
Object o = hotCache.getIfPresent(key);
if (o != null) {
return;
}
//********** watch here ************//
//该方法会被InitConstant.threadCount个线程同时调用,存在多线程问题
//下面的那句addCount是加了锁的,代表给Key累加数量时是原子性的,不会发生多加、少加的情况,到了设定的阈值一定会hot
//譬如阈值是2,如果多个线程累加,在没hot前,hot的状态肯定是对的,譬如thread1 加1,thread2加1,那么thread2会hot返回true,开启推送
//但是极端情况下,譬如阈值是10,当前是9,thread1走到这里时,加1,返回true,thread2也走到这里,加1,此时是11,返回true,问题来了
//该key会走下面的else两次,也就是2次推送。
//所以出现问题的原因是hotCache.getIfPresent(key)这一句在并发情况下,没return掉,放了两个key+1到addCount这一步时,会有问题
//测试代码在TestBlockQueue类,直接运行可以看到会同时hot
//那么该问题用解决吗,NO,不需要解决,1 首先要发生的条件极其苛刻,很难触发,以京东这样高的并发量,线上我也没见过触发连续2次推送同一个key的
//2 即便触发了,后果也是可以接受的,2次推送而已,毫无影响,客户端无感知。但是如果非要解决,就要对slidingWindow实例加锁了,必然有一些开销
//所以只要保证key数量不多计算就可以,少计算了没事。因为热key必然频率高,漏计几次没事。但非热key,多计算了,被干成了热key就不对了
SlidingWindow slidingWindow = checkWindow(hotKeyModel, key);//从这里可知,每个app的每个key都会对应一个滑动窗口
//看看hot没
boolean hot = slidingWindow.addCount(hotKeyModel.getCount());
if (!hot) {
//如果没hot,重新put,cache会自动刷新过期时间
CaffeineCacheHolder.getCache(hotKeyModel.getAppName()).put(key, slidingWindow);
} else {
//这里之所以放入的value为1,是因为hotCache是用来专门存储刚生成的hotKey
//hotCache对应的caffeine有效期为5s,也就是说该key会保存5s,在5s内不重复处理相同的hotKey。
//毕竟hotKey都是瞬时流量,可以避免在这5s内重复推送给client和dashboard,避免无效的网络开销
hotCache.put(key, 1);
//删掉该key
//这个key从实际上是专门针对slidingWindow的key,他的组合逻辑是appName+keyType+key,而不是给client和dashboard推送的hotKey
CaffeineCacheHolder.getCache(hotKeyModel.getAppName()).invalidate(key);
//开启推送
hotKeyModel.setCreateTime(SystemClock.now());
//当开关打开时,打印日志。大促时关闭日志,就不打印了
if (EtcdStarter.LOGGER_ON) {
logger.info(NEW_KEY_EVENT + hotKeyModel.getKey());
}
//分别推送到各client和etcd
for (IPusher pusher : iPushers) {
pusher.push(hotKeyModel);
}
}
}
“thread.count”配置即为消费者个数,多个消费者共同消费一个QUEUE队列 生产者消费者模型,本质上还是拉模式,之所以不使用EventBus,是因为需要队列来做缓冲 根据HotKeyModel里面是否是删除消息类型
删除CaffeineCacheHolder里面对应newkey的滑动窗口缓存。
向该hotKeyModel对应的app的client推送netty消息,表示新产生hotKey,使得client本地缓存,但是推送的netty消息只代表为热key,client本地缓存不会存储key对应的value值,需要调用JdHotKeyStore里面的api来给本地缓存的value赋值
向dashboard推送hotKeyModel,表示新产生hotKey
删除消息类型
根据HotKeyModel里面的appName+keyType+key的名字,来构建caffeine里面的newkey,该newkey在caffeine里面主要是用来与slidingWindow滑动时间窗对应
删除hotCache里面newkey的缓存,放入的缓存kv分别是newKey和1,hotCache作用是用来存储该生成的热key,hotCache对应的caffeine有效期为5s,也就是说该key会保存5s,在5s内不重复处理相同的hotKey。毕竟hotKey都是瞬时流量,可以避免在这5s内重复推送给client和dashboard,避免无效的网络开销
删除CaffeineCacheHolder里面对应appName的caffeine里面的newKey,这里面存储的是slidingWindow滑动窗口
推送给该HotKeyModel对应的所有client实例,用来让client删除该HotKeyModel
非删除消息类型
根据HotKeyModel里面的appName+keyType+key的名字,来构建caffeine里面的newkey,该newkey在caffeine里面主要是用来与slidingWindow滑动时间窗对应
通过hotCache来判断该newkey是否刚热不久,如果是则返回
根据滑动时间窗口来计算判断该key是否为hotKey(这里可以学习一下滑动时间窗口的设计),并返回或者生成该newKey对应的滑动窗口
如果没有达到热key的标准
通过CaffeineCacheHolder重新put,cache会自动刷新过期时间
如果达到了热key标准
向hotCache里面增加newkey对应的缓存,value为1表示刚为热key。
3)计算热key滑动窗口的设计 限于篇幅的原因,这里就不细谈了,直接贴出项目作者对其写的说明文章:Java简单实现滑动窗口
3.3.4 dashboard端
这个没啥可说的了,就是连接etcd、mysql,增删改查,不过京东的前端框架很方便,直接返回list就可以成列表。
4 总结
文章第二部分为大家讲解了redis数据倾斜的原因以及应对方案,并对热点问题进行了深入,从发现热key到解决热key的两个关键问题的总结。 文章第三部分是热key问题解决方案——JD开源hotkey的源码解析,分别从client端、worker端、dashboard端来进行全方位讲解,包括其设计、使用及相关原理。 希望通过这篇文章,能够使大家不仅学习到相关方法论,也能明白其方法论具体的落地方案,一起学习,一起成长。
审核编辑:汤梓红
-
开源
+关注
关注
3文章
3349浏览量
42501 -
Redis
+关注
关注
0文章
376浏览量
10878
原文标题:Redis数据倾斜与JD开源hotkey源码分析揭秘
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
快充EOS 应对方案OVP和TVS
企业打开Redis的正确方式,来自阿里云云数据库团队的解读
Redis Stream应用案例
如何使得redis中的数据不再有
【昉·星光 2 高性能RISC-V单板计算机体验】Redis源码编译和性能测试以及与树莓派4B对比
【爱芯派 Pro 开发板试用体验】Redis源码编译和基准测试
舵机失灵的主要原因_舵机失灵的应对方法

电源电压变化对晶振性能的影响以及应对方法
新版 Redis 不再“开源”,对使用者都有哪些影响?
Redis开源版与Redis企业版,怎么选用?






 工商网监
工商网监
评论