 FP32推理TensorRT演示
FP32推理TensorRT演示
引言
YOLOv5最新版本的6.x已经支持直接导出engine文件并部署到TensorRT上了。
FP32推理TensorRT演示
可能很多人不知道YOLOv5新版本6.x中已经支持一键导出Tensor支持engine文件,而且只需要一条命令行就可以完成:演示如下:
python export.py --weights yolov5s.pt --include onnx engine --device 0
其中onnx表示导出onnx格式的模型文件,支持部署到:
- OpenCV DNN- OpenVINO- TensorRT- ONNXRUNTIME但是在TensorRT上推理想要速度快,必须转换为它自己的engine格式文件,参数engine就是这个作用。上面的命令行执行完成之后,就会得到onnx格式模型文件与engine格式模型文件。--device 0参数表示GPU 0,因为我只有一张卡!上述导出的FP32的engine文件。
使用tensorRT推理 YOLOv5 6.x中很简单,一条命令行搞定了,直接执行:
python detect.py --weights yolov5s.engine --view-img --source data/images/zidane.jpg
FP16推理TensorRT演示
在上面的导出命令行中修改为如下
python export.py --weights yolov5s.onnx --include engine --half --device 0其中就是把输入的权重文件改成onnx格式,然后再添加一个新的参 --half 表示导出半精度的engine文件。就这样直接执行该命令行就可以导出生成了,图示如下:
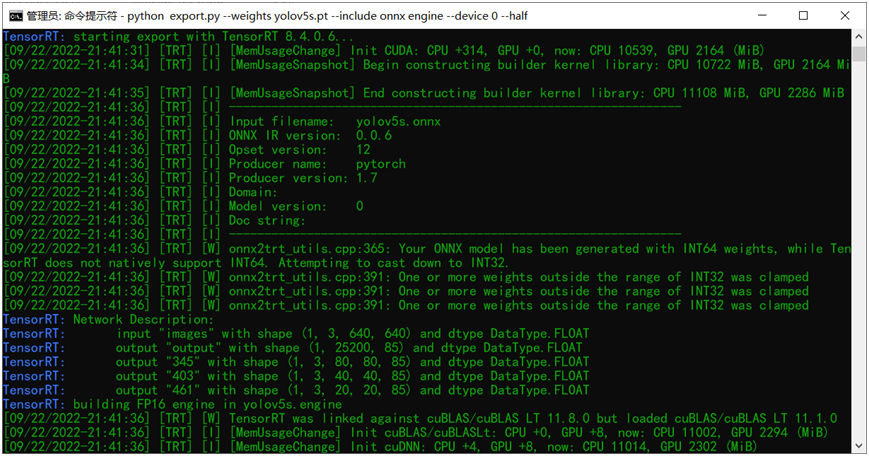
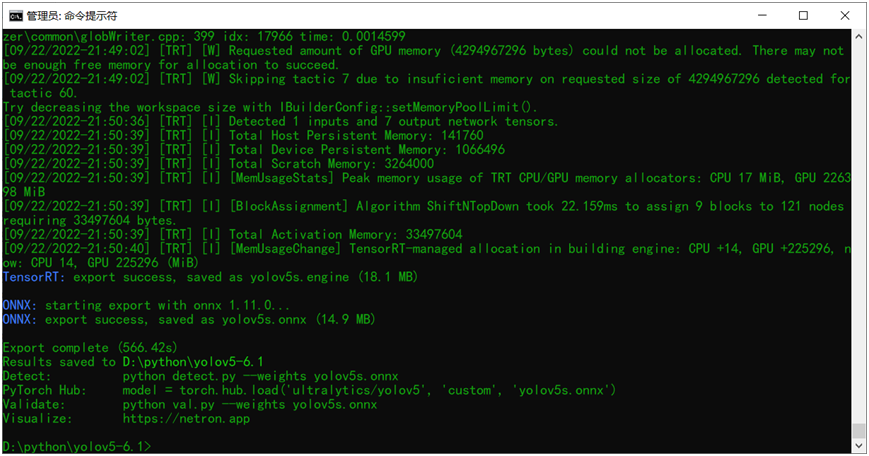
对比可以发现相比FP32大小的engine文件,FP16的engine文件比FP32的engine大小减少一半左右,整个文件只有17MB大小左右。
推理执行的命令跟FP32的相同,直接运行,显示结果如下:
对比发现FP32跟FP16版本相比,速度提升了但是精度几乎不受影响!
INT8量化与推理TensorRT演示
TensorRT的INT量化支持要稍微复杂那么一点点,最简单的就是训练后量化。只要完成Calibrator这个接口支持,我用的TensorRT版本是8.4.0.x的,它支持以下几种Calibrator:
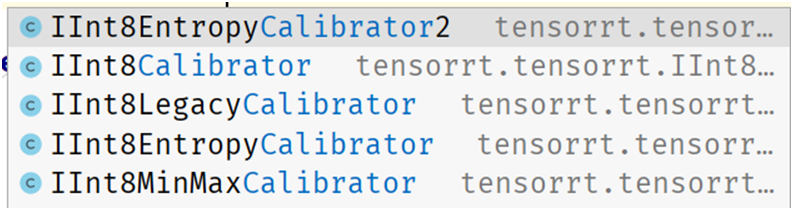
不同的量化策略,得到的结果可能稍有差异,另外高版本上的INT8量化之后到低版本的TensorRT机器上可能无法运行,我就遇到过!所以建议不同平台要统一TensorRT版本之后,再量化部署会比较好。上面的Calibrator都必须完成四个方法,分别是:
#使用calibrator验证时候每次张数,跟显存有关系,最少1张get_batch_size #获取每个批次的图像数据,组装成CUDA内存数据get_batch #如果以前运行过保存过,可以直接读取量化,低碳给国家省电read_calibration_cache#保存calibration文件,量化时候会用到write_calibration_cache
这块对函数集成不懂建议参考TensorRT自带的例子:
TensorRT-8.4.0.6samplespythonint8_caffe_mnist几乎是可以直接用的!Copy过来改改就好了!
搞定了Calibrator之后,需要一个验证数据集,对YOLOv5来说,其默认coco128数据集就是一个很好的验证数据,在data文件夹下有一个coco128.yaml文件,最后一行就是就是数据集的下载URL,直接通过URL下载就好啦。
完成自定义YOLOv5的Calibrator之后,就可以直接读取onnx模型文件,跟之前的官方转换脚本非常相似了,直接在上面改改,最重要的配置与生成量化的代码如下:
# build trt enginebuilder.max_batch_size = 1config.max_workspace_size = 1 << 30config.set_flag(trt.BuilderFlag.INT8)config.int8_calibrator = calibratorprint('Int8 mode enabled')plan = builder.build_serialized_network(network, config)主要就是设置config中的flag为INT8,然后直接运行,得到plan对象,反向序列化为engine文件,保存即可。最终得到的INT8量化engine文件的大小在9MB左右。
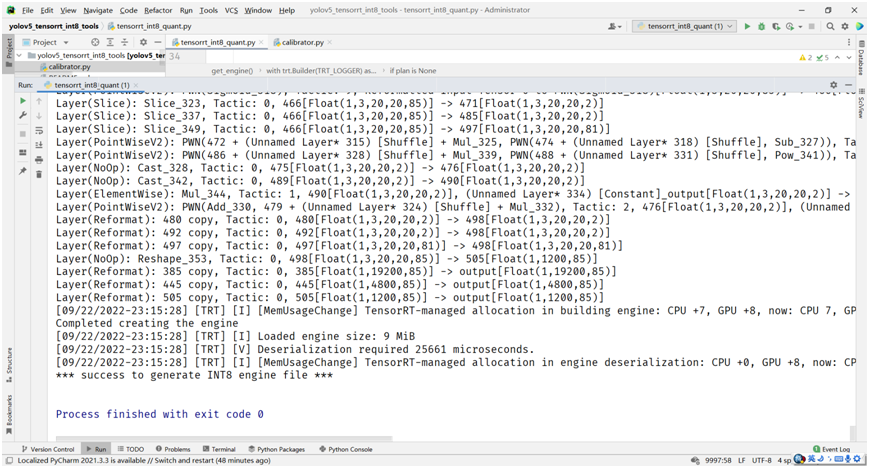
数据太少,只有128张, INT8量化之后的YOLOv5s模型推理结果并不尽如人意。但是我也懒得再去下载COCO数据集, COCO训练集一半数据作为验证完成的量化效果是非常好。 这里,我基于YOLOv5s模型自定义数据集训练飞鸟跟无人机,对得到模型,直接用训练集270张数据做完INT8量化之后的推理效果如下:
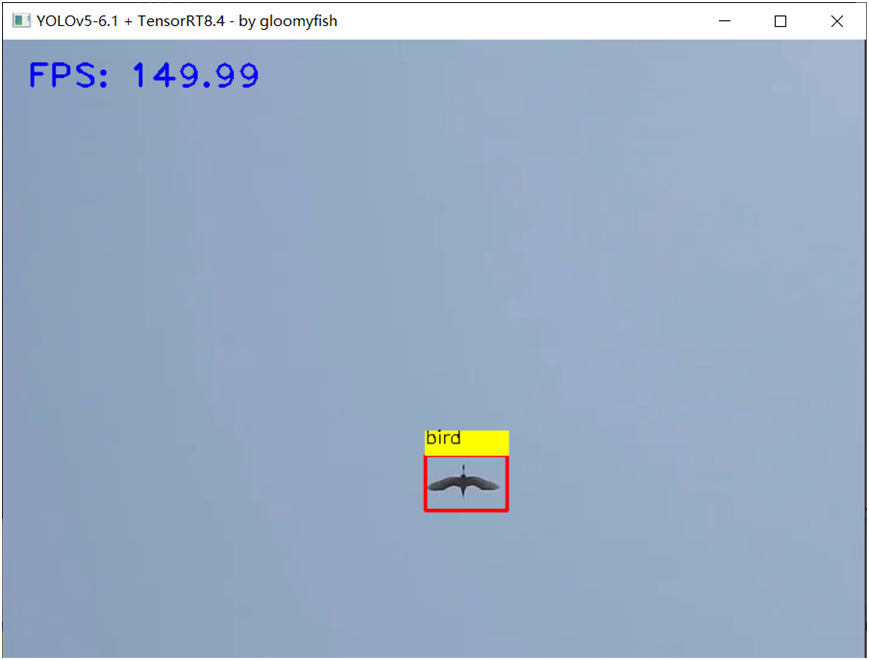
量化效果非常好,精度只有一点下降,但是速度比FP32的提升了1.5倍左右(3050Ti)。
已知问题与解决
量化过程遇到这个错误
[09/22/2022-2313] [TRT] [I] Calibrated batch 127 in 0.30856 seconds.[09/22/2022-2316] [TRT] [E] 2: [quantization.cpp::70] Error Code 2: Internal Error (Assertion min_ <= max_ failed. )[09/22/2022-2316] [TRT] [E] 2: [builder.cpp::619] Error Code 2: Internal Error (Assertion engine != nullptr failed. )Failed to create the engineTraceback (most recent call last):
解决方法,把Calibrator中getBtach方法里面的代码:
img = np.ascontiguousarray(img, dtype=np.float32)
to
img = np.ascontiguousarray(img, dtype=np.float16)
这样就可以避免量化失败。
-
格式
+关注
关注
0文章
23浏览量
16886 -
模型
+关注
关注
1文章
3241浏览量
48833 -
数据集
+关注
关注
4文章
1208浏览量
24699
原文标题:YOLOv5模型部署TensorRT之 FP32、FP16、INT8推理
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何在GPU上使用TensorRT部署深度学习应用程序
全志XR806+TinyMaix,在全志XR806上实现ML推理
推断FP32模型格式的速度比CPU上的FP16模型格式快是为什么?
C++演示中的推理速度比Python演示中的推理速度更快是为什么?
初次尝试Tengine 适配 Ncnn FP32 模型

NVIDIA TensorRT 8.2将推理速度提高6倍
使用NVIDIA TensorRT优化T5和GPT-2

NVIDIA TensorRT和DLA分析
NVIDIA T4 GPU和TensorRT提高微信搜索速度
TensorRT 8.6 C++开发环境配置与YOLOv8实例分割推理演示
三种主流模型部署框架YOLOv8推理演示
边缘生成人工智能推理威廉希尔官方网站 面临的挑战有哪些

Torch TensorRT是一个优化PyTorch模型推理性能的工具

TensorRT-LLM低精度推理优化






 工商网监
工商网监
评论