 识别网络爬虫的策略分析
识别网络爬虫的策略分析
识别网络爬虫的策略分析
一、网络爬虫
爬虫(crawler)也可以被称为spider和robot,通常是指对目标网站进行自动化浏览的脚本或者程序,包括使用requests库编写脚本等。随着互联网的不断发展,网络爬虫愈发常见,并占用了大量的网络资源。由爬虫产生的网络流量占总流量的37.2%,其中由恶意爬虫产生的流量约占65%[1]。如何在网络流量中识别爬虫,是判断爬虫行为意图的前提,常见的使用爬虫的场景包括:搜索引擎等使用爬虫爬取网站上的信息,研究机构使用爬虫搜集数据,以及攻击者使用爬虫搜集用户信息、识别软件后门等。
针对网络爬虫,目前常用的方法包括在服务器上的robots.txt文件中进行适当的配置,将用户代理列入白名单等,这些操作可以检测和阻止一些低级别的恶意爬虫。然而,高级和复杂的网络爬虫仍然难以检测,因为它们通常会伪装成合法的爬虫或正常用户。此外,运营部门需要投入较多的时间和资源来收集和分析网络流量记录报告,以发现隐藏的网络爬虫的痕迹。网络爬虫通常会触发大量告警,给安全运营人员带来了较大的数据处理压力。此外,部分恶意攻击者也会使用爬虫来收集信息,因此从海量的告警中,识别出网络爬虫,并判断其行为意图十分重要。在安全运营场景中,如何根据安全设备产生的告警数据,设计出识别爬虫,并判断其行为意图的方案,目前仍需要不断地探索以及深入的思考。
在往期内容中,笔者已经介绍了Aristaeus平台使用浏览器指纹、TLS指纹和IP行为分析等方式识别爬虫的行为意图的工作[2],由于Aristaeus平台使用的域名在实验前均未注册使用过,因此这一工作中采集到的流量均为爬虫,并在此基础上对良性/恶意的爬虫进行了区分。本文对基于web日志信息识别爬虫以及判断其行为意图的研究进行总结分析[3],包括常见的判断爬虫的方法,以及机器学习、深度学习等方法识别爬虫,以及各种识别爬虫行为意图的方法。
二、识别网络爬虫的常见方法
常用的判定爬虫的方法包括检查其HTTP协议头的User-agent字段,这一字段包含用户访问时所使用的操作系统及版本、浏览器类型及版本等标识信息。如果该字段中表明为浏览器等使用的爬虫,使用DNS正向和反向查找的方法可以确定发起请求的IP地址是否与其声明的一致,则可以将其进行判别。一个IP地址可能使用不同的用户代理或者不同的自动化工具生成HTTP请求头,这一现象可能是良性爬虫使用NAT或者代理造成的,但也可能是恶意爬虫在进行欺骗行为,包括在User-agent字段中更改操作系统、浏览器版本等[4],例如笔者在日常告警数据中观察到User-Agent字段存在
“User-Agent: Mozilla/5.0+(compatible;+Baiduspider/2.0;++http://www.baidu.com/search/spider.html) Mozilla/5.0+(compatible;+Googlebot/2.1;++http://www.google.com/bot.html)”
这类情况。目前也有许多开源的项目使用上述方法检测网络爬虫,例如CrawlerDetect 就是github上的一个开源项目[5],通过User-Agent和 http_from 字段检测爬虫,目前能够检测到 1,000 种网络爬虫。
由于上述方法只能判断一部分网络爬虫,在安全运营场景中,对于其余无法识别的爬虫,可以基于HTTP请求的速率、访问量、请求方法、请求文件大小等行为特征,设计算法进行识别。由合法机构运行的网络爬虫,包括搜索引擎和研究机构等,通常不会造成网络的阻塞。恶意的网络爬虫主要是在机器上运行的脚本编程,通常具有较高的 HTTP 请求率,且对URL访问量很大。基于网络爬虫的这一特点,可以提取各个IP地址发出HTTP请求的速率、以及其URL的访问量作为特征。由于爬虫的主要目的是从网站下载信息,所以较多地使用GET方法,而不是使用POST方法进行上传操作。此外,爬虫通常需要在尝试爬取文件之前确定文件的类型,所以与正常浏览相比,可能会使用更多的HEAD方法[4]。通过统计分析各个IP地址的HTTP请求中各类方法所占比例,可以提取出HTTP请求方法的分布特征。
通常网络爬虫对特定文件类型的请求更多,例如较多地请求 .html文件,而对 .jpeg等文件类型的请求较少。爬虫通常会进行策略优化,以实现在最短的时间内将爬取效率最大化,往往会跳过大文件而去寻找较小的文件,所以HTTP的 GET方法可能会返回更多的小文件。如果某些被爬取的URL需要进一步验证,爬虫的请求将被定向到这些验证页面,因此会产生3XX 或 4XX 的 HTTP 请求返回码[4]。通过统计分析各个IP地址请求的文件类型、大小的分布,以及响应码的分布,可以提取出描述请求文件和响应特征,对应于告警信息中的URI,content_length,q_body和r-body等字段。
Lagopoulos等人提出了一种用于网络机器人检测的语义方法[6],这一方法主要是基于以人为主体的网络用户通常对特定主题感兴趣,而爬虫则是随机地在网络上爬行的假设,设计出了一套检测方法。这一工作从会话中提取的典型特征包括:
请求总数:请求的数量。
会话持续时间:第一个请求和最后一个请求之间经过的总时间
平均时间:两个连续请求之间的平均时间。
标准偏差时间:两个连续请求之间时间的标准偏差。
重复请求:使用与以前相同的HTTP方法请求已经访问过的页面。
HTTP请求:四个特性,每个特性包含与以下HTTP响应代码之一相关联的请求的百分比:成功(2xx)、重定向(3xx)、客户机错误(4xx)和服务器错误(5xx)。
特定类型请求:特定类型的请求占所有请求数的百分比,这一特征在不同的应用程序中表现不同。
除了上述特征外,这一工作从会话中提取到了一部分语义特征:包括主题总数、独特主题、页面相似度、页面的语义差异等,并使用了四种不同的模型,包括使用RBF的SVM,梯度增强模型,多层感知器和极端梯度增强来测试检测结果。从不同特征集上的实验结果可以看出,RBF在语义特征上取得了最好的性能,GB在简单典型特征上取得了最好的性能,GB在典型特征和语义特征的结合上也取得了最好的性能。
此外,Wan等人在2019年提出了一种名为PathMarker的反爬虫威廉希尔官方网站 ,可以通过检测网页或请求之间的关系来检测分布式爬虫[7]。在这一方法中,通过向URL添加标记来跟踪访问该URL之前的页面,并识别访问该URL的用户。根据URL访问路径和访问时间的不同模式,使用支持向量机模型来区分恶意网络爬虫和普通用户。实验结果表明,该系统能够成功识别96.74%的爬虫长会话和96.43%的普通用户长会话。PathMarker的体系结构如图1所示,最后使用自动化的公共图灵测试(CAPTCHA)实时地识别爬虫和普通用户。
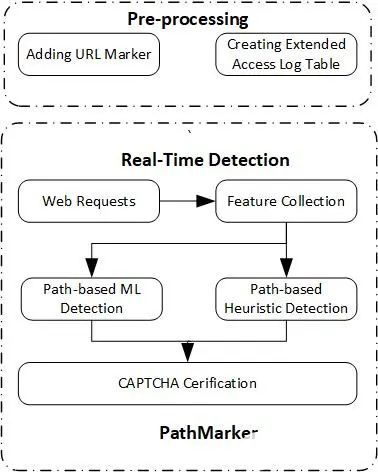
图1 PathMarker的体系架构
上述两个工作均引入了语义内容作为检测爬虫的特征之一,其核心思想在于普通用户和爬虫请求网页的主题不同。基于这一结果,可以使用doc2vec 和 word2vec替换LDA,以更好地表示会话中访问内容的语义[6]。
三、识别爬虫的行为意图
匹配黑名单是常用的识别恶意爬虫的方式,然而在目前观测到的攻击中,大多数恶意IP都是被感染的个人设备,且爬虫经常会切换新的IP地址,多数IP的生存周期都不超过一天,这些操作都可以避免被黑名单过滤。例如,在Aristaeus平台监测到的发出恶意请求的IP地址中,只有13%出现在当前流行的恶意IP黑名单中,这表明黑名单对恶意爬虫的IP地址覆盖率较低[2]。此外,还可以根据访问行为是否符合robots协议来判断是否为恶意爬虫。通常每个网站都会设置robots.txt,内容包含不要访问某些文件夹或文件,或限制爬虫访问网站的频率。通常我们认为恶意爬虫不会遵守robots协议,并且会使用robots.txt来识别他们可能忽略的站点,这一行为模式可以用于识别恶意爬虫。然而,在Aristaeus平台的研究中,并未发现爬虫发出的请求违背robots协议的现象[2],这表明爬虫采取的策略中已明确避免出现上述行为,所以这类方式在实际应用中可能难以有效地识别爬虫。
基于这一实际情况,采用更加细粒度的方式描述爬虫行为,并提取相应的行为特征是后续识别爬虫行为意图的解决方向。例如,良性的爬虫不会发送未经请求的POST或利用漏洞进行攻击,与之相反,恶意爬虫则会向身份验证端点发送未经请求的POST或无效的请求,可以视为侦察行为。爬虫请求中是否存在欺骗的行为也可以用于判断其意图,例如构建wget、curl、Chrome等工具的TLS指纹库,通过将请求中声明的用户代理与其TLS指纹进行匹配[2],可以检测出进行身份欺瞒的爬虫,并在后续的分析中进一步分析其行为特征。
四、结论
通过使用User-Agent字段及DNS正方向查询可以初步识别常见搜索引擎的爬虫,基于IP地址发出HTTP请求的行为特征,并引入对请求行为的语义特征描述等,可以在剩余告警信息中检测出使用脚本得到的爬虫。随着爬虫策略的优化更新,使用静态黑名单过滤或判断爬虫是否遵守robots协议,通常很难达到较好的效果。如果需要进一步辨别爬虫的行为意图,可以通过建立构建爬虫程序的指纹库,判断爬虫的真实身份是否与其声明一致。针对IP的请求内容,构建描述是否对web应用程序进行指纹识别、是否在扫描可能存在的敏感文件等指纹库,可以更加精确地检测恶意爬虫。在后续的研究工作中,笔者希望通过将上述检测方法付诸实践,基于告警信息对爬虫进行检测,并深入分析爬虫的行为意图,进而辅助安全运营人员研判。
审核编辑:汤梓红
-
服务器
+关注
关注
12文章
9129浏览量
85341 -
网络爬虫
+关注
关注
1文章
52浏览量
8652
发布评论请先 登录
相关推荐
应对反爬虫的策略
网络爬虫之关于爬虫http代理的常见使用方式
python网络爬虫概述
网络爬虫 Python和数据分析
一种维护WAP网站的网络爬虫的设计
一种新型网络爬虫的设计与实现
网络爬虫的原理是什么
网络爬虫是否合法
如何使用本体语义实现灾害主题爬虫的策略





 工商网监
工商网监
评论