 通过NVIDIA Spectrum Ethernet的自适应路由加速网络
通过NVIDIA Spectrum Ethernet的自适应路由加速网络
NVIDIA 加速 AI 平台和产品(如 NVIDIA EGX 、 DGX 、 OVX 和 NVIDIA AI for Enterprise )需要数据中心网络的最佳性能。 NVIDIA Spectrum Ethernet 平台通过芯片级创新实现了这一性能。
融合以太网 RDMA 自适应路由( RoCE )通过减少网络拥塞问题加快了应用程序的速度。这篇文章介绍了 NVIDIA 频谱以太网的自适应路由威廉希尔官方网站 ,并提供了一些初步的性能基准。
是什么让我的网络变慢了?
您不必是云服务提供商就可以从横向扩展网络中获益。网络行业已经发现,具有第 2 层转发和生成树的传统网络架构效率低下,而且难以扩展。他们过渡到 IP 网络结构。
这是一个很好的开始,但在某些情况下,它可能不足以解决新类型的应用程序和跨数据中心引入的流量。
可扩展 IP 网络的一个关键属性是它们能够跨多个交换机层次结构分布大量流量和流量。
在一个完美的世界中,数据流是完全不相关的,因此在多个网络链路上分布均匀、负载平衡平稳。该方法依赖于现代哈希和多路径算法,包括等成本多路径( ECMP )。运营商受益于任何规模的数据中心中的高端口数、固定外形的交换机。
然而,在许多情况下,这是行不通的,通常包括无处不在的现代工作负载,如 AI 、云和存储。
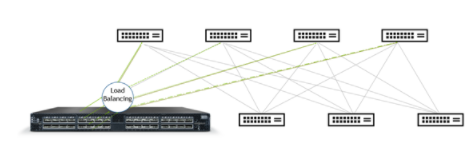
图 1 :。介绍 NVIDIA 自适应路由
问题是有限熵的问题。熵是一种衡量流经给定网络的流量的丰富性和多样性的方法。
当您有数千个从全球各地的客户端随机连接的流时,您的网络被称为有 high entropy 。然而,当您只有少数大型流时(这在 AI 和存储工作负载中经常发生),大型流会控制带宽,因此会出现 low entropy 。这种低熵流量模式也称为 elephant flow 分布,在许多数据中心工作负载中都很明显。
那么为什么熵很重要呢?
使用静态 ECMP 的传统威廉希尔官方网站 ,您需要高熵来将流量均匀地分布在多个链路上,而不会出现拥塞。然而,在大象流场景中,多个流可以在同一条链路上对齐,从而创建一个超额预订的热点或微爆发。这会导致拥塞、延迟增加、数据包丢失和重传。
对于许多应用程序,性能不仅取决于网络的平均带宽,还取决于流完成时间的分布。完成时间分布中的长尾或异常值可能会显著降低应用程序性能。图 2 显示了低熵对流完成时间的影响。
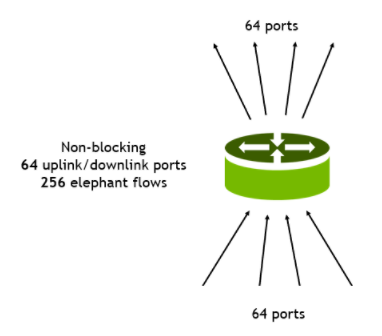
图 2 :。网络拥塞示例
此示例由单个机架顶部交换机组成,具有 128 个 100G 端口。
64 个端口是连接到服务器的 100G 下游端口。
64 个端口是连接到第 1 层交换机的 100G 上游端口。
每个下游端口接收四个带宽相等的流量: 25G 每个流量,总共 256 个流量。
所有流量都通过静态哈希和 ECMP 处理。
在最好的情况下,此配置的可用带宽不会超额使用,因此可能会出现以下结果。在最坏的情况下,与理想情况相比,流程可能需要长达 2.5 倍的时间才能完成(图 3)。
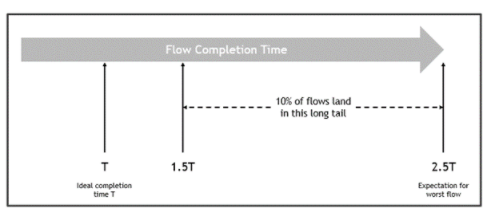
图 3 :。流量完成时间可能会有很大变化
在这种情况下,一些端口拥塞,而其他端口未使用。最后一个流量(最坏流量)的预期持续时间是预期第一个流量持续时间的 250% 。此外, 10% 的流量预计流量完成时间超过 150% 。也就是说,有一个长尾流,完成时间比预期的要长。为了避免高置信度拥塞( 98% ),必须将所有流的带宽降低到 50% 以下。
为什么有许多流会因完成时间过长而受到影响?这是因为 ECMP 上的一些端口非常拥挤。当流完成传输并释放一些端口带宽时,滞后流通过相同的拥塞端口,导致更多拥塞。这是因为在对标头进行哈希处理后,路由是静态的。
自适应路由
NVIDIA 正在为频谱交换机引入自适应路由。通过自适应路由,转发到 ECMP 组的流量选择拥塞程度最低的端口进行传输。拥塞基于出口队列负载进行评估,确保 ECMP 组在不考虑熵级别的情况下保持良好平衡。向多个服务器发出多个请求的应用程序以最小的时间变化接收数据。
这是如何实现的?对于转发到 ECMP 组的每个数据包,交换机在其出口队列上选择负载最小的端口。评估的队列是那些与数据包服务质量匹配的队列。
相比之下,传统的 ECMP 基于哈希方法进行端口决策,这通常无法产生清晰的比较。当相同流的不同数据包通过网络的不同路径传输时,它们可能会无序到达目的地。在 RoCE 传输层, NVIDIA ConnectX NIC 负责处理无序数据包,并将数据按顺序转发给应用程序。这使得从中受益的应用程序看不到自适应路由的魔力。
在发送方方面, ConnectX 可以动态标记流量,以符合网络重新排序的条件,从而确保在需要时可以强制执行消息间排序。交换机自适应路由分类器只能对这些标记的 RoCE 流量进行分类,使其服从其唯一的转发。
频谱自适应路由威廉希尔官方网站 支持各种网络拓扑。对于 CLO (或叶/脊椎)等典型拓扑,到给定目标的各种路径的距离是相同的。因此,交换机通过拥塞最小的端口传输数据包。在路径之间距离不同的其他拓扑中,交换机倾向于通过最短路径发送流量。如果拥塞发生在最短路径上,则选择拥塞最小的备选路径。这确保了网络带宽得到有效利用。
工作量结果
存储
为了验证 RoCE 中自适应路由的效果,我们从测试简单的 RDMA 写测试应用程序开始。在这些在多个 50 Gb / s 主机上运行的测试中,我们将主机分成几对,每对主机在很长一段时间内互相发送大型 RDMA 写流。这种类型的流量模式是存储应用程序工作负载中的典型模式。
图 4 显示了基于哈希的静态路由在上行链路端口上发生冲突,导致流完成时间增加,带宽减少,流之间的公平性降低。在转移到自适应路由后,所有问题都得到了解决。
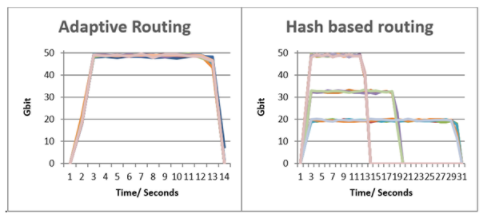
图 4 :。针对存储工作负载的自适应路由
在第一个图中,所有流几乎同时完成,峰值带宽相当。
在第二个图中,一些流实现了相同的带宽和完成时间,而其他流发生冲突,导致完成时间更长,带宽更低。实际上,在 ECMP 的情况下,一些流在 13 秒的理想完成时间 T 内完成,而性能最差的流需要 31 秒,约为 T 的 2.5 倍。
人工智能/高性能混凝土
为了继续评估 RoCE 工作负载中的自适应路由,我们在一个 32 服务器测试台上测试了常见 AI 基准的性能增益,该测试台在两级 fat 树网络拓扑中使用四个 NVIDIA 频谱交换机构建。该基准评估了分布式 AI 培训和 HPC 工作负载中常见的集体操作和网络流量模式,如全对全流量和全减少集体操作。

总结
在许多情况下,基于静态哈希的转发会导致高拥塞和可变流完成时间。这会降低应用程序级性能。
NVIDIA 频谱自适应路由解决了这个问题。这项威廉希尔官方网站 增加了网络使用的带宽,最大限度地减少了流完成时间的变化,从而提高了应用程序的性能。
将此威廉希尔官方网站 与 NVIDIA ConnectX NIC 提供的 RoCE 无序支持相结合,应用程序对所使用的威廉希尔官方网站 是透明的。这确保了 NVIDIA Spectrum Ethernet 平台提供了实现最大数据中心性能所需的加速以太网。
关于作者
Gil Levy 拥有 25 年的网络产品 ASIC 设计经验。他的重点领域是高速数据包处理、数据包缓冲、拥塞控制、可编程性和遥测。在过去的 8 年中,他一直在 NVIDIA 的频谱以太网产品线工作。他之前曾为 Marvell 、 Broadlight 和 Galileo 工作,为企业、 metro 和数据中心市场开发以太网交换机和网络处理器 ASIC 。吉尔拥有特拉维夫大学电气工程学士学位,目前正在瑞奇曼大学攻读计算机科学硕士学位。
Yonatan Piasetzky 在 NVIDIA 网络业务部门( NBU )的端到端高级开发团队工作。 Yonatan 从端到端的角度研究 HPC 和 AI 工作负载的加速网络,包括 DPU 和交换机,以及下一代高性能网络的虚拟化和云解决方案。 Yonatan 在特拉维夫大学获得物理和电气工程学士学位,在魏茨曼研究所获得理学硕士学位,目前正在特拉维夫大学攻读集成光子学量子计算博士学位。
Barak Gafni 是 NVIDIA 的架构师,专注于实现未来的高性能、可扩展和简单网络。巴拉克拥有特拉维夫大学电气工程学士学位,曾参与撰写多份 IETF 草案,并在网络领域拥有多项专利。
审核编辑:郭婷
-
以太网
+关注
关注
40文章
5425浏览量
171728 -
NVIDIA
+关注
关注
14文章
4986浏览量
103064 -
服务器
+关注
关注
12文章
9160浏览量
85423
发布评论请先 登录
相关推荐
NVIDIA加速计算如何推动医疗健康
NVIDIA 以太网加速 xAI 构建的全球最大 AI 超级计算机

步进电机如何自适应控制?步进电机如何细分驱动控制?
简单认识NVIDIA网络平台
应用NVIDIA Spectrum-X网络构建新型主权AI云
如何在自己的固件中增加wifi自适应性相关功能,以通过wifi自适应认证测试?
NVIDIA Spectrum-X 以太网网络平台已被业界广泛使用
借助NVIDIA DOCA 2.7增强AI 云数据中心和NVIDIA Spectrum-X
PMP22165.1-适用于 Xilinx 通用自适应计算加速平台 (ACAP) 的电源 PCB layout 设计

NVIDIA 通过 CUDA-Q 平台为全球各地的量子计算中心提供加速

NVIDIA发布专为大规模AI量身订制的全新网络交换机-X800系列
什么是自适应光学?自适应光学原理与方法的发展
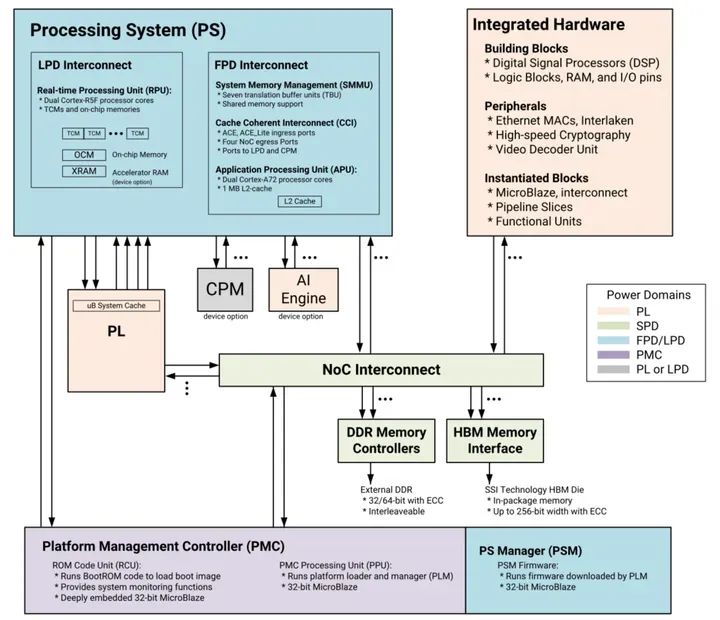
【ALINX 威廉希尔官方网站 分享】AMD Versal AI Edge 自适应计算加速平台之 Versal 介绍(2)
【ALINX 威廉希尔官方网站 分享】AMD Versal AI Edge 自适应计算加速平台之准备工作(1)
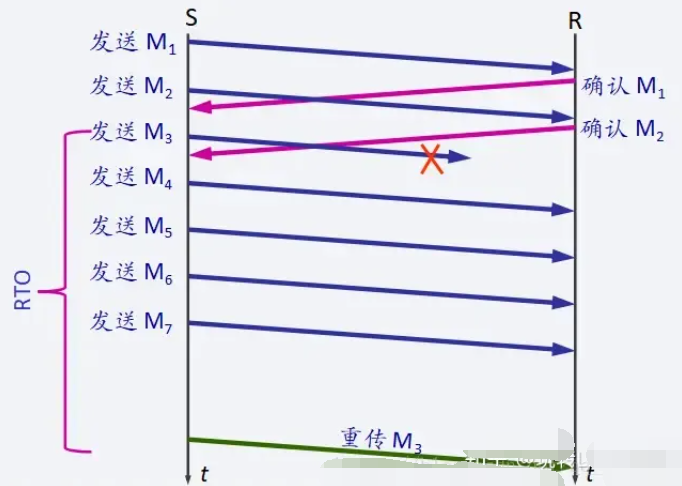
TCP协议威廉希尔官方网站 之自适应重传





 工商网监
工商网监
评论