 OCR算法能较好识别水平排布的常规文本
OCR算法能较好识别水平排布的常规文本
本文简要介绍ECCV 2022录用的论文“When Counting Meets HMER: Counting-Aware Network for Handwritten Mathematical Expression Recognition”的主要工作。该论文旨在缓解目前大部分基于注意力机制的手写数学公式识别算法在处理较长或者空间结构较复杂的数学公式时,容易出现的注意力不准确的情况。本文通过将符号计数任务和手写数学公式识别任务联合优化来增强模型对于符号位置的感知,并验证了联合优化和符号计数结果都对公式识别准确率的提升有贡献。
一、研究背景
OCR威廉希尔官方网站 发展到今天,对于常规文本的识别已经达到了较高的准确率。但是对于在自动阅卷、数字图书馆建设、办公自动化等领域经常出现的手写数学公式,现有OCR算法的识准确率依然不太理想。不同于常规文本,手写数学公式有着复杂的空间结构以及多样化的书写风格,如图1所示。其中复杂的空间结构主要是由数学公式独特的分式、上下标、根号等结构造成的。虽然目前的OCR算法能较好地识别水平排布的常规文本,甚至对于一些多方向以及弯曲文本也能够有不错的识别效果,但是依然不能很好地识别具有复杂空间结构的数学公式。
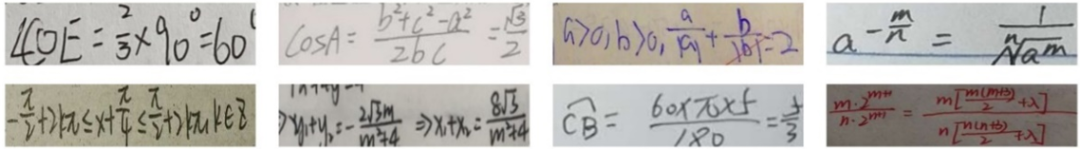
图1 手写数学公式示例
二、研究动机
现有的大部分手写数学公式识别算法采用的是基于注意力机制的编码器-解码器结构,模型在识别每一个符号时,需要注意到图像中该符号对应的位置区域。在识别常规文本时,注意力的移动规律比较单一,往往是从左至右或从右至左。但是在识别数学公式时,注意力在图像中的移动具有更多的可能性。因此,模型在解码较复杂的数学公式时,容易出现注意力不准确的现象,导致重复识别某符号或者是漏识别某符号。
为了缓解上述现象,本文提出将符号计数引入手写数学公式识别。这种做法主要基于以下两方面的考虑:1)符号计数(如图2(a)所示)可以隐式地提供符号位置信息,这种位置信息可以使得注意力更加准确(如图2(b)所示)。2)符号计数结果可以作为额外的全局信息来提升公式识别的准确率。
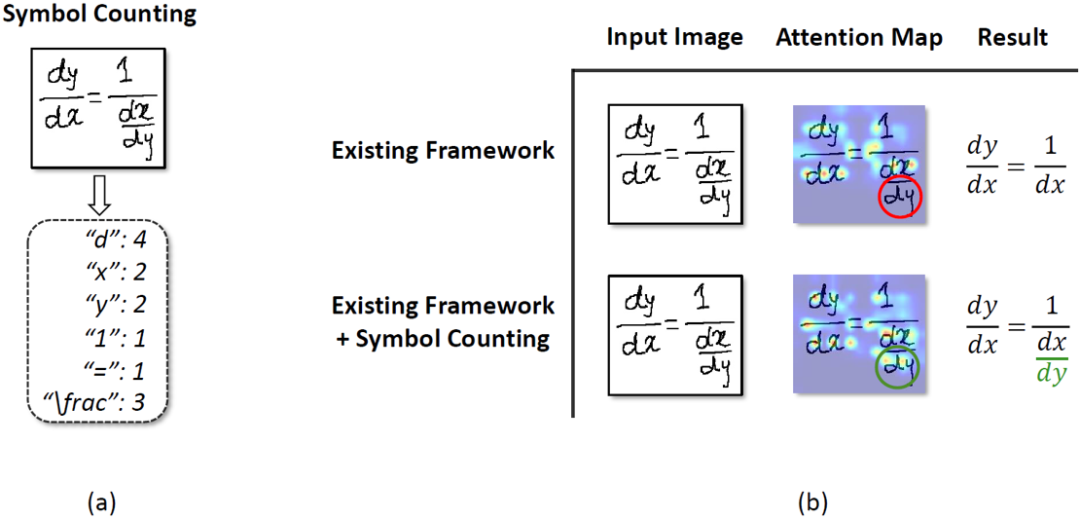
图2 (a)符号计数任务;(b)符号计数任务让模型拥有更准确的注意力
三、方法简述
模型整体框架:如图3所示,CAN模型由主干特征提取网络、多尺度计数模块(MSCM)和结合计数的注意力解码器(CCAD)构成。主干特征提取网络采用的是DenseNet[1]。对于给定的输入图像,主干特征提取网络提取出2D特征图F。随后该特征图F被输入到多尺度计数模块MSCM,输出计数向量V。特征图F和计数向量V都会被输入到结合计数的注意力解码器CCAD来产生最终的预测结果。
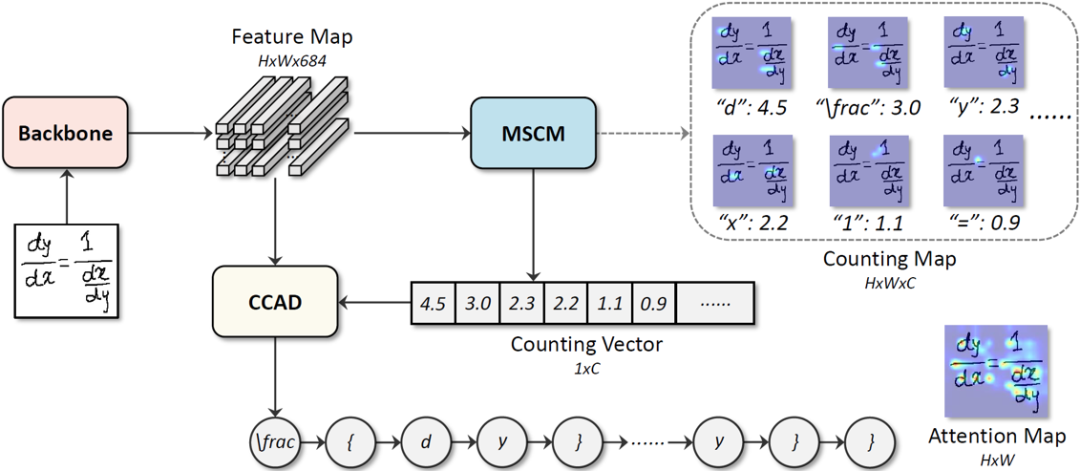
图3 CAN模型整体框架
多尺度计数模块:在人群计数等任务中,部分方法采用弱监督的范式,在不需要使用人群位置标注的情况下预测人群密度图。本文借鉴了这一做法,在只使用公式识别原始标注(即LaTeX序列)而不使用符号位置标注的情况下进行多类符号计数。针对符号计数任务,该计数模块做了两方面独特的设计:1)用计数图的通道数表征类别数,并在得到计数图前使用Sigmoid激活函数将每个元素的值限制在(0,1)的范围内,这样在对计数图进行H和W维度上的加和后,可以直接表征各类符号的计数值。2)针对手写数学公式符号大小多变的特点,采用多尺度的方式提取特征以提高符号计数准确率。
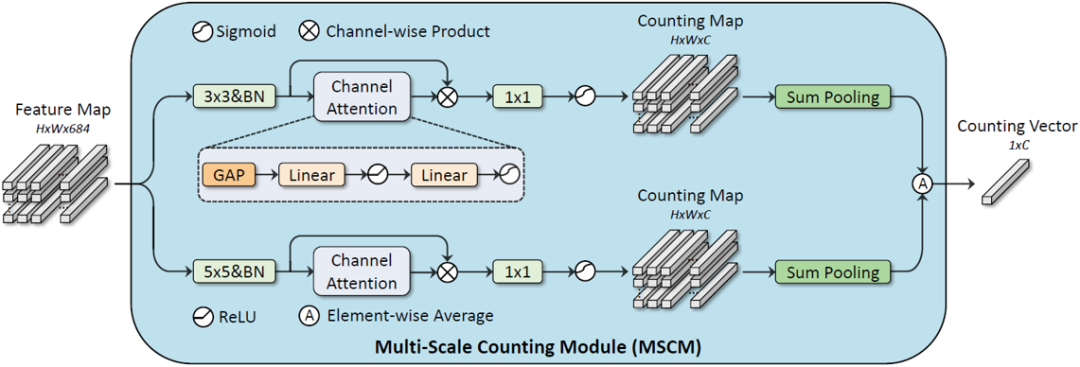
图4 多尺度计数模块MSCM
结合计数的注意力解码器:为了加强模型对于空间位置的感知,使用位置编码表征特征图中不同空间位置。另外,不同于之前大部分公式识别方法只使用局部特征进行符号预测的做法,在进行符号类别预测时引入符号计数结果作为额外的全局信息来提升识别准确率。
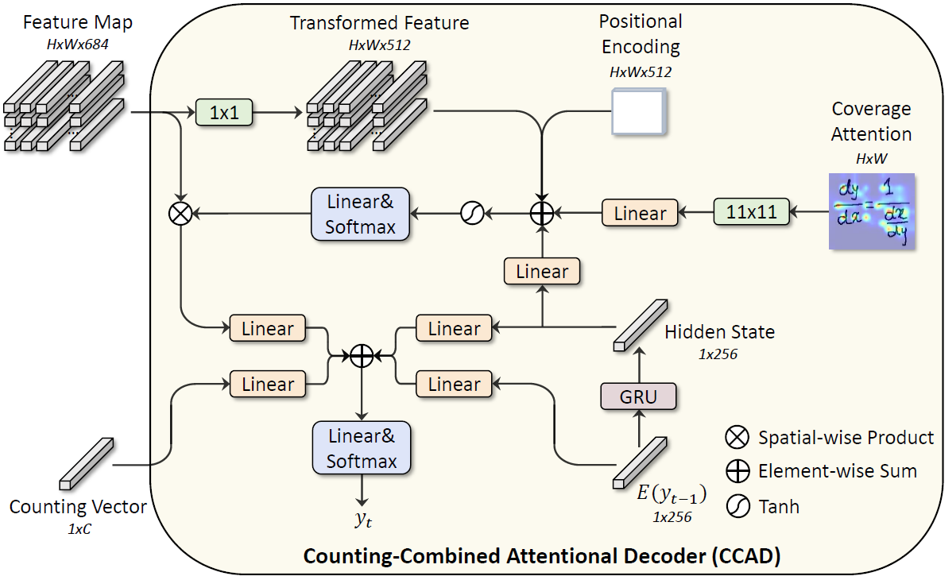
图5 结合计数的注意力解码器CCAD
四、实验结果
在广泛使用的CROHME数据集以及新出现的HME100K[2]数据集上都进行了实验并与之前的最优方法做了比较。如表1和表2所示,可以看出CAN取得了目前最高的识别准确率。此外,使用经典模型DWAP[3]作为baseline得到的CAN-DWAP以及使用之前最优模型ABM[4]作为baseline得到的CAN-ABM,其结果都分别优于对应的baseline模型,这说明本文所提出的方法可以被应用在目前大部分编码器-解码器结构的公式识别模型上并提升它们的识别准确率。
表1 在CROHME数据集上的结果 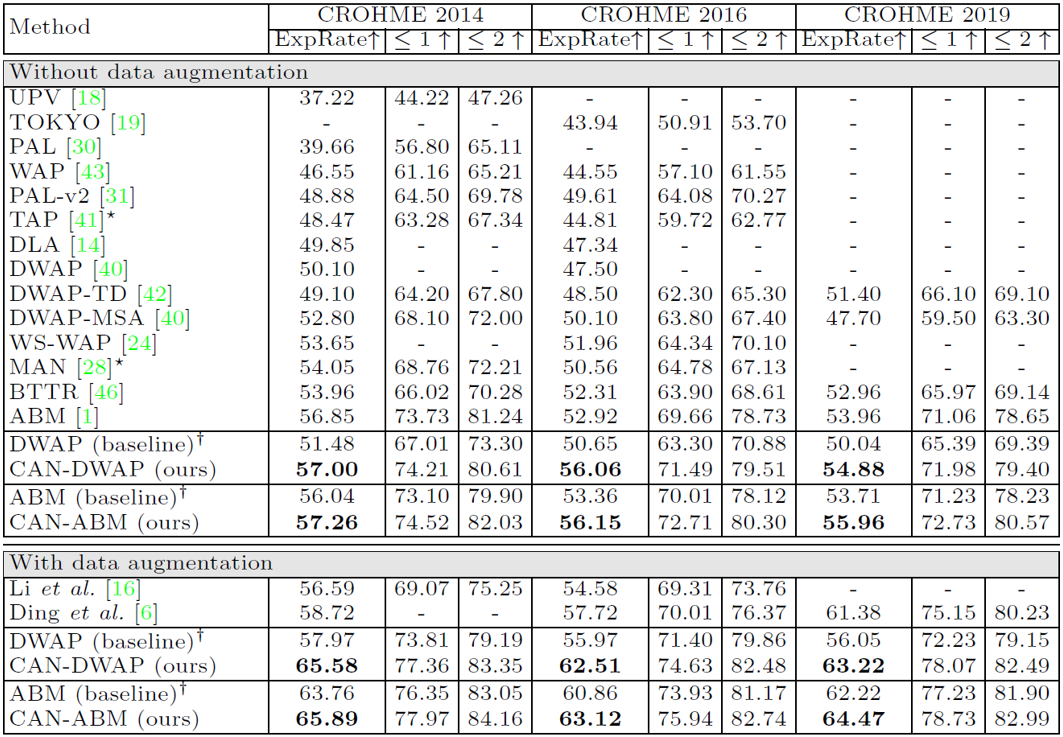 表2 在HME100K数据集上的结果
表2 在HME100K数据集上的结果 
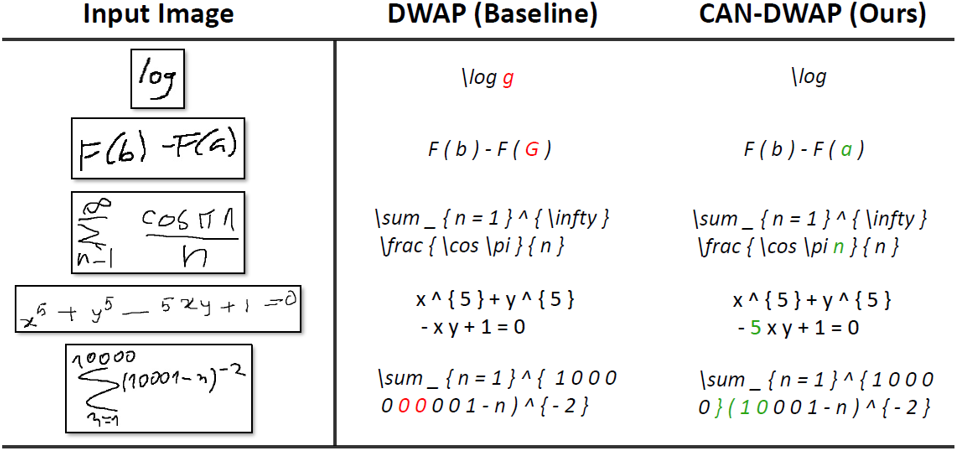
图6 在CROHME数据集上DWAP和CAN-DWAP的识别结果展示
对于模型各部分带来的提升,本文做了消融实验。如表3所示,加入位置编码、将两种任务联合优化以及融合符号计数结果进行预测都能提升模型对于手写数学公式的识别准确率。此外,为了验证采用多尺度的方式提取特征的有效性以及研究符号计数结果对于公式识别准确率的影响,本文做了实验进行验证。如表4所示,使用大小不同的卷积核提取多尺度特征有助于获得更高的符号计数准确率。并且计数结果越准确,对公式识别的提升也越大。表5则展示了当使用符号计数的GT(Ground Truth)时对于模型识别准确率的提升。
表3 模型各部分带来的提升

表4 计数模块中卷积核大小的影响
 表5 符号计数结果对公式识别准确率的影响
表5 符号计数结果对公式识别准确率的影响 
符号计数对于公式识别有促进作用,那么反过来公式识别能否提升符号计数的准确率呢?本文对这一问题也做了探讨,实验结果和符号计数可视化结果如表6和图7所示,可以看出公式识别任务也可以提升符号计数的准确率。本文认为这是因为公式识别的解码过程提供了符号计数任务缺少的上下文语义信息。
表6 公式识别对符号计数准确率的影响

 图7 符号计数结果及计数图可视化
图7 符号计数结果及计数图可视化
五、文本结论
本文设计了一种新颖的多尺度计数模块,该计数模块能够在只使用公式识别原始标注(即LaTeX序列)而不使用符号位置标注的情况下进行多类别符号计数。通过将该符号计数模块插入到现有的基于注意力机制的编码器-解码器结构的公式识别网络中,能够提升现有模型的公式识别准确率。此外,本文还验证了公式识别任务也能通过联合优化来提升符号计数的准确率。
-
编码器
+关注
关注
45文章
3639浏览量
134437 -
模型
+关注
关注
1文章
3229浏览量
48812 -
OCR
+关注
关注
0文章
144浏览量
16350
原文标题:ECCV 2022 | 白翔团队提出CAN:手写数学公式识别新算法
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
提供银行卡识别API免费接入的OCR SDK开发者平台
首发 | 告别手动录入,开放平台OCR上线印刷文字识别!
c#+halcon1.5 ocr字符识别
自编通用视觉框架实现基本算子以及OCR识别功能
Python OCR 识别库-ddddocr
【KV260视觉入门套件试用体验】七、VITis AI字符和文本检测(OCR&Textmountain)
基于FPGA的OCR文字识别威廉希尔官方网站 的深度解析
关于开放平台OCR上线印刷文字识别的介绍
一篇包罗万象的场景文本检测算法综述
OCR识别威廉希尔官方网站
一篇包罗万象的场景文本检测算法综述
机器视觉运动控制一体机应用例程|OCR字符识别应用

OCR实战教程
easyocr:超级简单且强大的OCR文本识别工具

OCR如何自动识别图片文字





 工商网监
工商网监
评论