 移动App与用户隐私安全介绍
移动App与用户隐私安全介绍
IEEE x ATEC科技思享会是由专业威廉希尔官方网站 学会IEEE与前沿科技探索社区ATEC联合主办的威廉希尔官方网站 沙龙。邀请行业专家学者分享前沿探索和威廉希尔官方网站 实践,助力数字化发展。
在万物互联的大数据时代,数据链接了我们生活的方方面面。一方面,大数据极大便利了我们的工作与生活;另一方面,数据的海量化也增加了诸多隐私信息泄露的风险与挑战。本期科技思享会邀请到了四位重磅嘉宾,共同围绕“隐私保护的前沿威廉希尔官方网站 及应用”这个主题,分别从机器学习算法、通讯协议、APP及操作系统等不同层面,就隐私安全风险及威廉希尔官方网站 创新应用展开讨论。
以下是中国科学院信息工程研究所陈恺研究员的演讲,《移动App与用户隐私安全》。
《移动App与用户隐私安全》
很高兴跟大家共同交流,我们今天讲的是《移动APP和用户隐私安全》。
新型恶意代码及攻击
现在的手机跟以前不太一样,十多年前的手机不是智能机,以前的手机上没有太多的传感器,而现在的手机上有很多传感器,比如光线传感器、距离传感器、重力传感器、加速度传感器、磁场传感器等等一系列的传感器,还有像陀螺仪、GPS、指纹传感器、霍尔感应器、气压传感器、以及紫外线传感器等等。而用这些传感器,就有可能借助一些人工智能的威廉希尔官方网站 把用户的行为习惯收集起来。
2019年剑桥大学有一个研究:他利用内置麦克风去录制音频,根据手指敲击屏幕的声音,窃取手机的密码。这看起来很不可思议,用户敲击手机, APP只有一个麦克风的权限,怎么能够窃听密码呢?他们利用这个内置麦克风,最后达到的效果是可以在尝试10次之后,准确恢复54%的四位密码, 20次尝试后准确率可以达到61%,很高的准确率。
这是什么原理呢?
我们可以看到,手机在屏幕上敲密码时,在手机上不同的位置,敲击动作会产生不同的声波,手机利用了上下两个脉冲去接收用户手机敲的震动声波,由于上下共有两个麦克风,所以手机利用不同的声音波形还是能够比较准确的知道用户敲的是哪一个字母。通过一些学习威廉希尔官方网站 ,大概能猜出来用户敲击了键盘的什么位置,从而把字母和位置再关联起来,就知道用户敲的到底是什么字母。当然这个提前可以训练一下。
怎么训练呢?
就是手机在屏幕上可以显示出不同的,比如说九键的数字键或者是字母键盘的键,看看不同的键敲下去以后,它的波形是什么样的,从而能够训练出一个model。后来剑桥的研究人员找了不同的手机、平板电脑,在噪音环境(包括公共休息室、阅览室和图书馆)进行了测试,最后发现是很有效的。他们做了具体的测试,分很多组测试了数字、四位数的密码、随机的英文字母,在最不理想的情况下,模型正确识别单个数字的准确率是随机猜测的3倍,而最佳情况下的单个数字识别率是 100%。所以他们还是能够比较准确的识别出用户敲击了键盘的哪个位置。这个研究就证明了,在实验环境下,恶意APP有机会获得超出权限的信息。
但这并不是不可防御的。怎么去防御呢?
有一种防御方法就是降低敲击的声音。比如通过给手机贴膜,像敲到膜上很可能震动就会小一些。所以这个时候它可能没办法区分用户敲击了屏幕的不同键,这种情况下就能把用户保护起来了。
但我们如何找到这些存在恶意行为的APP呢?这是我们后面准备研究的内容。
除此之外,造成信息泄露的攻击行为还有很多。比如通过麦克风、扬声器能去做用户行为的一些识别,比如说穿越墙壁、门和窗子,监测多个用户的位置和身体活动,还可以推断出线性和有节奏的活动等等。
威廉希尔官方网站 的发展,使得用户隐私泄露的风险变大了。
Observation:a unique business model
后来我们想了一些办法去抓这类恶意的行为或者有这种潜在威胁的行为。直接去找是挺难的,因为攻击者往往会隐藏他的行为。
我们可以利用这种方法:某些恶意或有潜在威胁的攻击方式,是捆绑在一个正常APP上的,就像攻击者在一个正常的APP上面放了一小块恶意的程。这个时候我们就可以在海量的程序之间两两对比,找到看起来相似的程序,把它的差异拿出来。
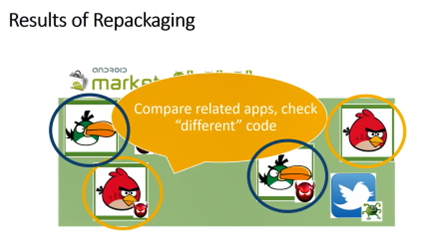
比如上图中这个绿色的小鸟找到了,我们就把两个程序的代码进行比对,找到这个差异的部分,这个差异的部分很可能就是恶意的部分。
另外我们可以把看起来不太一样的软件放在一起。如果这个不太一样的软件里面有一些共有的代码,如果又不是一些library code的话,那很可能是攻击者散布在各个软件里面的攻击代码。这个时候我们就能把这个代码找到了,很可能就是一些潜在有危险的代码。
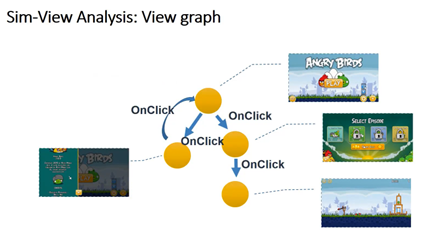
在海量软件里面去把软件两两相比是一件很麻烦的事情。那怎么办呢?
我们就把软件界面的调用图的关系理出来。比如说一个愤怒的小鸟,就是这样的一个调用的图。把第一个界面和后面界面的关系理出来。
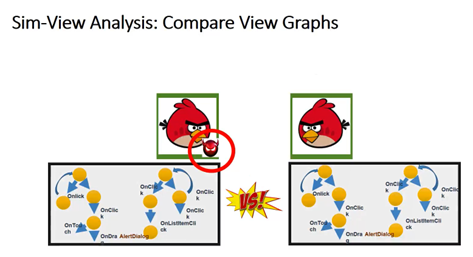
我们就去比较这些图。每一个程序看起来相似的程序里面,这两个图应该是类似的、甚至是一样的,所以我们就把它找出来。因为图和图的比较是很麻烦也比较费力气的一件事,我们得把图的比较变成一个三维的结构体。比如说把这个图每一个节点固定下来,固定下来之后,这样我们就把这个看起来很随意的一张图变成一个能够固定下来的一张图。不管谁画出来,这张图都是一样的。然后这个图我们最后用一个点,也就是这个图的一个质心去表示这张图。这样我们就比较这个图的质心,这样就把原来的一个图的比较变成一个点的比较,效率大大提高了。具体方法我们暂且先不细说了,感兴趣的同学可以来看看我们的论文。
Measurement And Approach
所以我们后来也利用这个方式在官方市场上去找了一百多万的APP互相比较,在GooglePlay上包括40多万的APP,还有其他的中国市场。结果发现像Google这样的市场,有7%的比例很可能是存在有潜在威胁代码,并且它能找到的潜在威胁代码比其他的恶意软件检测工具找到的还要多。这是因为它能够去找未知的这种方式。另外一个特点就是它的性能很高,它分析一个程序只要不到10秒钟就能分析成功。
另外我们还用类似的威廉希尔官方网站 去找苹果其中的一些潜在的恶意的部分,我们就利用了一个原理,什么原理呢?就是我们假设攻击者是贪心的,他把自己的恶意部分不光放在安卓里面,也会放到苹果里面。这个时候我们就做了一个跨平台的映射,把安卓的恶意代码给它映射到苹果。在苹果的程序里面去找这个恶意的部分。
当然这个听起来好像挺难做的,做起来也确实不太容易,为什么呢?因为大家都觉得苹果手机很安全,而且苹果里面做了很多的隐私保护,上面也没有杀毒软件,所以在苹果里面找恶意程序并不好找。后来我们就利用这个方法去找苹果里面的恶意部分。简单来说就是把刚刚安卓找到的恶意部分去做了跨平台的映射,映射到苹果,再在行为的层面上去做一个对应关系去把它找出来。
其实安卓的部分和苹果的部分之间,在功能上还是很相似的,虽然在语言上、结构上很可能都不太一样。比如说安卓是Java写的,苹果是用C代码去写,有很大的差异。但它有行为的相似性,所以还是能够抓到的。最后我们在苹果的官方市场上找了10万个APP去分析,然后谷歌里面也是找了40万个APP,我们找到了苹果的官方市场上大概有2.94%的比例含有对应的安卓的那一部分的潜在恶意行为。在Jailbreak这样的市场上,也就是越狱的市场上,这个比例更高一些,达到5%到10%。所以在越狱市场上有更多的潜在有威胁的行为。
讲到隐私,某些APP通过了解用户的行为记录,推送跟用户隐私密切相关的广告。如果要去关闭的话,往往要经过很多的步骤,我们把这类测试设置称为隐私设置。
但这类设置很少有人去研究,为什么呢?因为传统的这种程序的分析方法很难去做这方面的研究,它需要懂一点语义信息,比如说什么叫做隐私设置。怎么能精准找到隐私设置呢?
我们后来为了解决这个问题,去做了一个跟用户有关的实验:做了一个设备,列举了很多的settings,然后让用户去标记出来一些对他来说比较隐私的设置。我们把这个设置分成几个层次。这个settings里面有的用户觉得没关系,有的用户可能觉得非常的紧张、非常的难受。所以我们把它做一些分类,分成五档,这样就能够让用户标记好了。我们拿它作为一个训练的model,这样对于一个setting,分析这个setting的语义信息,我们就知道这个setting是不是一个跟用户隐私相关的setting。
第二,我们还得去判断这个setting藏得深不深。如果藏得不深,用户一眼就能看到。我们去判断它藏得深不深。所以我们也是做了一个这样的User Study,让用户去找这个setting。我们看看一些settings好不好找,同样分成五类,从非常好找一直到非常难找,总共分成了五类。然后让用户去写出来一些原因,为什么很难找?尽管某些知名APP的隐私设置体验还是很好的,但我们做实验的时候仍发现某些规范性差的APP隐私设置,我们称为“hidden”,就是比较难找到的,47.12%的比例。用户为什么会找不到这个隐私设置,主要包括跟用户常用的习惯不太一样,。用户从开始界面到最后设置的位置,这个点击的路径,我们称为UI- path,如果过长,用户就会找不到。我们后来就做了一个工具,把用户觉得难找的东西找出来。先找到这些settings,确认它是一个privacy setting,再确认它是一个hidden privacy setting,然后找到了各种features。我们找到了六个原因,包括14个features,这里面有一个比较难的是找UI-path,这个单纯分析code很难分析出来。
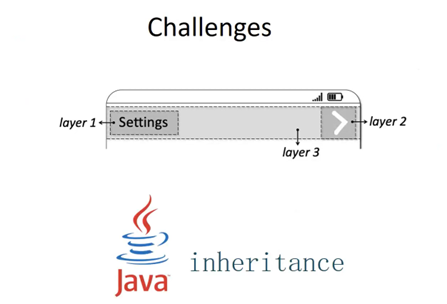
比如说分析code里面,像这个很简单的界面,它有三个layers,有settings的layer,有箭头的layer,还有背景的layer。其实很简单,但是它分成三个layers,分析code就麻烦。但是如果去分析语义是比较简单的。比如用户点完一个按钮,点完下一个界面,出来的界面里面的元素和用户点击的这个按钮应该是有语义上的关联的。通过这种关联,我们就找到大概这个设置是怎么样的,即UI-path是什么样的一个path。当然有时用户会点击一些图标,比如说这个齿轮,我们就得解析这个齿轮是什么语义。这时候我们用了Google的一个Text,就可以猜到它可能是一个什么语义。比如说这个齿轮,Google对这个齿轮的解析就是setting gear,所以一下子就跟setting有关,就拿到了这个图标的语义信息。这个工序是比较准确的,达到93.5%的准确性。分析一个程序大概不到10分钟。
通过具体的分析结果。我们可以看到,随着带有隐私安全性攻击的程序下载量增加,这个privacy setting的比例也越来越多。很多的settings,它是by default的、可能泄露用户隐私,尤其是跟用户社交行为相关的这些settings。
“智能化”聊天机器人
除了这种APP以外,现在大家还常用一种东西叫做“个人助手”,个人语音助手比如说智能音箱,我们可以用智能音箱、用助手去做什么事儿呢?可以听歌,可以问它天气。有时候它会有第三方的skills,第三方的skills可以做什么呢?它可以去给我们买东西、可以做很多敏感的操作。所以我们就去看这个skills,看它会不会有一些敏感的行为。我们看了这些skills以后发现,曾经有研究发现它跟名称相关,它可以去调用一些跟正常的skills的名称一样的skills或者发音相似的skills。因为skill的调用,例如我们调用工商银行,我们说“你能打开工商银行吗”,但事实上如果有一个恶意的skill,它叫“工商银行吗”,那你打开的是什么呢?并不是工商银行,而是这个恶意的skill“工商银行吗”,这个skill就会泄露你重要的行为了。
这个skill的分析和传统APP的分析不太一样。比如说安装时,传统的APP是装到手机上的,它有代码在手机上,你可以对代码做分析。但是skill它是通过一种调用的方式去调用它,它的代码并不在你的智能音箱上,它只是一个服务,所以对它进行分析并不太容易。另外一个难点就是这一类skills的分析需要使用自然语言,你得不停的跟它对话。它是一个全黑盒的,你用自然语言能够让它理解、你还得理解它的自然语言,这样对它做分析。所以一直没有研究对这个skill的行为进行分析。
我们尝试去看看这个skill到底会不会做一些有害用户的事情。操作的具体方法是:首先你需要跟skill进行对话,你要有第一句话,我们把第一句话称为“Utterances”,之后得跟它交互,交互就得理解它问的问题以及回答它问的问题,不停的交互才能把它的行为枚举出来。Utterances怎么来呢?我们就想到用户的第一句话是怎么跟skill交互的。用户交互的时候通常会问“Help”,或者找到这个skill的官网,看看这个skill的范例,这个例子里面是怎么使用。所以我们也找到skill的官网,从官网里面去看它大概是怎么使用,然后通过自然语言理解威廉希尔官方网站 ,把skill的使用方法拿出来,所以能够启动调用这个skill的工作、跟它对话。
之后,我们就要理解并回答它的问题。我们把这个问题分成5种类型,包括Yes/No问题、选择题、WH问题,还有Instruction问题和Mix问题。Mix就是把这几类混合起来,然后针对每种类型分别处理,具体做的过程就不细说了。简单来说就是问一个问题,下面可能有若干个答案,每个答案下面又有若干的问题,所以它会形成一种树状结构。我们最后找到了亚马逊上的28000多个skills,还有谷歌上的1000多个skills,分析了超过5200个小时,其中有9000多个skills的名称不满足亚马逊的要求,有100多个skills和开发者的skills相互冲突,换句话说它可能会问到一些敏感的问题。还有68个skills也很有趣,它会悄悄的录音。所谓的悄悄录音是指当用户跟它说“stop”时,这个skills并不stop,它没有停下来,它会把你交互的过程发到远端的服务器上去。其中有一些skills很奇怪,比如说你跟它说停止的时候,它会说 “OK” 或者 “cannot find this skill”,但是这个skill仍然是在工作,所以这个时候就在悄悄的录音了。
Skill的审核机制探索
后来我们就想,这个skills既然这么有害,它怎么会通过它的审核系统放到市场上呢?所以我们就在看这个skills的审核系统到底是什么样的评审系统。我们去分析了亚马逊和谷歌。我们首先想确定这个skills它到底是谁在审核呢?是一个用户还是一个机器人在审核呢?如果是用户人在审核,那可能会好一点,人看的会细一点。如果是个机器的,它很可能会有一些错误,或者是人和机器结合起来再审核吗?我们就在做这件事情——怎么去区分人和机器呢?这个用到了图灵测试。
我们问了对方一个谜语,我们编了一个skill,skill里面藏了一个谜语,问问对方,看他审核时,到底能不能回答出来。我们猜如果是人的话,猜谜语应该能猜出来。机器的话,猜谜语很可能猜不出来,这样就能够做区分了。但是等我们真正做实验的时候,发现人有时候也猜不出谜语,这个谜语有时候太难了。那怎么办呢?这时我们就发现了人和机器还是不太一样。虽然人有时候猜错答案,但答案多少比较相近。比如说有一个问题,他说“I have wings, I am able to fly, I’m not a bird yet”,这个答案是Airplane,但是人会猜成Butterfly,机器可能会猜成Milk,显然Butterfly和最后的答案是比较接近的。
所以我们就分析这个答案的语义,当然是用到一些知识库以及和谜面之间的关联度,最后把它猜出来,可能是一个人。
通过这种方式,我们发现亚马逊里面大概有1.9%的比例,是用人在做的。谷歌里面大概有55%的比例是人在做,剩下来的都是机器。换句话说,亚马逊里面有接近于98%的比例,测试的过程都是机器在测而不是人。我们甚至能够分析这些机器和人的工作时间是不是在周末。然后我们也能看到机器的Test是怎么去审核一个skill呢?
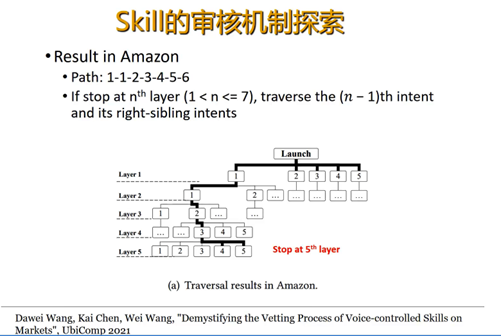
比如说这个树的每一个节点是一个问题,就像我们前面画的,不同的问题下面有答案,每个答案又对着问题。就是亚马逊审核skill的一个过程,它审核对于第一层的问题,每个问题都会去审核。至于第二层到第三层……到后面层,它每一层只审核一个问题,除了最后一层,最后一层是审核一部分的问题,它有自己的规律,谷歌也有规律。谷歌的规律是它只审核这一个层次的最后一个问题。所以就是这样,它并没有全部审核很多skills里面的问题,这也就造成了一部分的问题,存在隐私上面可能会泄露或者问了一些不好的问题,但是仍然能够通过审核在市场上架,就是这个原因。
总结
最后总结一下,现在某些含有隐私安全攻击的APP在收集用户的隐私,但是也有不同的方法可以去查看包括隐私设置藏的比较深的这种方式,我们也正在探索怎么去查看。另外就是智能音箱,有些智能音箱会有skill这类行为,这时候就需要对这个skill的中间的语言进行语义分析,才能够找到这些敏感的行为。另外就是这个里面我们用到了很多的AI方面的威廉希尔官方网站 ,AI去赋能传统的安全、去做智能化的恶意代码的检测,而这些事情可能是一些传统方式比较难做到的一些事情,包括语义的分析。当然在其他地方,包括黑客的知识、经验的传承,智能化的漏洞的发现利用等等。另一方面,人工智能本身现在也存在一些安全的问题,像对抗样本、神经网络后门、还有模型隐私问题,这也得到了大家的关注。
-
传感器
+关注
关注
2550文章
51047浏览量
753163 -
APP
+关注
关注
33文章
1573浏览量
72459 -
隐私
+关注
关注
0文章
27浏览量
10160
原文标题:【中科院陈恺分享】移动App与用户隐私安全
文章出处:【微信号:IEEE_China,微信公众号:IEEE电气电子工程师】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
智能语音开关:离线控制,守护隐私的新选择

暴露IP地址会影响网络隐私安全吗?

IP地址安全与隐私保护
平衡创新与伦理:AI时代的隐私保护和算法公平
苹果再筑隐私防线:iPhone自动强密码引领安全新风尚
蓝牙模块的安全性与隐私保护
理想汽车澄清偷拍传闻,重申保护用户隐私安全
讯维融合通信系统:智能通信威廉希尔官方网站 的安全与隐私保障
一眼看懂鸿蒙OS 应用隐私保护
APP盾的防御机制及应用场景






 工商网监
工商网监
评论