 借助于Kria SoM部署边缘人工智能
借助于Kria SoM部署边缘人工智能
简介
生产线已步入了快节奏时代, 但要提高交付速度和客户满意度,势必需要在装运前检测制造或包装缺陷。然而,自动化检测设备需要在不降低生产线速度的情况下进行处理和做出决策。所以,我们需要借助于Xilinx Kria K26系统模块 (SoM)等器件的帮助。
Kria K26 SoM允许开发人员利用可编程逻辑与高性能Arm处理器内核相结合的并行特性。Kria SoM的优势在于Xilinx首次为SoC (XCK26) 提供了异构SoC和必要的支持基础设施,如4GB DDR4内存、16GB eMMC、512Mb QSPI、TPM安全模块以及必要的电源基础设施。
为便于与应用接口,此器件提供了可拆分成245个IO的两个240针连接器。
Xilinx还提供了Kria KV260视觉AI入门套件,让开发人员能够快速开始设计。该套件为开发人员提供了拥有以下接口的SoM载卡:
3个MIPI接口
显示端口
1GB以太网
Pmod
此入门套件还随附了一系列应用示例,帮助用户了解开发基于视觉的人工智能应用是一件非常轻松的工作。Kria视觉AI入门套件非常适合需要快速图像处理的应用,例如检测标签是否已正确应用于生产线上的装运箱。
制造业应用案例
接下来让我们将详细地介绍Kria KV260视觉入门套件如何用于制造行业。创建此类应用并不一定需要可编程逻辑设计。然而,却需要进行软件开发,并具有使用Xilinx Vitis AI培训和编译新机器学习模型的能力。首先,我们需要安装和配置Vitis AI。
物料清单
Kria KV260视觉AI入门套件
创建虚拟机
我们需要本地Linux机器或运行受支持的Linux发行版的虚拟机来运行Vitis AI。
在安装完成后,下载Ubuntu Linux磁盘映像,以便在虚拟机上安装Linux系统。此项目所使用的Ubuntu版本是Ubuntu-18.04.4 Desktop-amd64.iso,点击此处即可下载。
现在可以开始构建虚拟机了。第一步,在VirtualBox Manager中单击New。
这时将显示一个对话框,用于创建新的虚拟机(见图2)。输入虚拟机名称,并将类型和版本分别设置为Linux和64位Linux版本。此外,还可以设置与虚拟机共享的系统内存大小(见图3)。
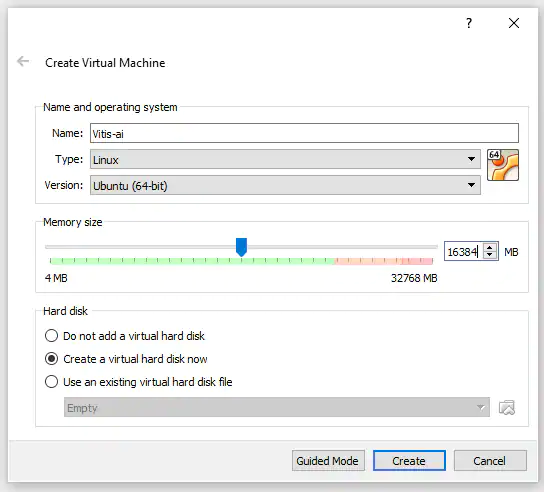
图2:创建虚拟机
单击Create按钮,将显示虚拟硬盘的设置。选择512GB,以允许动态分配物理存储空间。随着磁盘使用量的增加,虚拟硬盘大小将扩展到512GB。该项目将外部固态USB C驱动器用作虚拟硬盘,以确保有足够的可用空间。
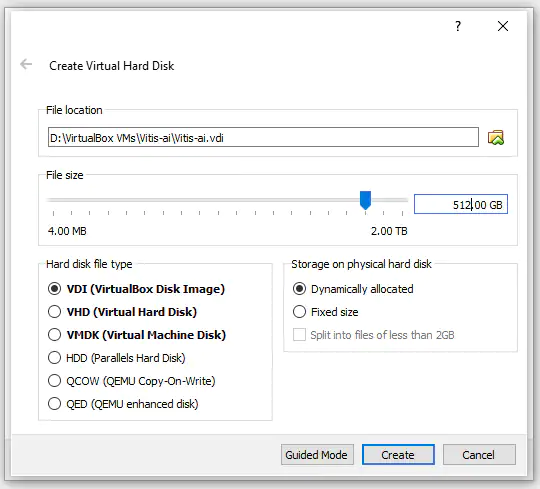
图3:设置存储空间
配置好虚拟机后,接下来就要安装操作系统了。选中新创建的虚拟机,然后单击start按钮启动VM 9(见图4)。
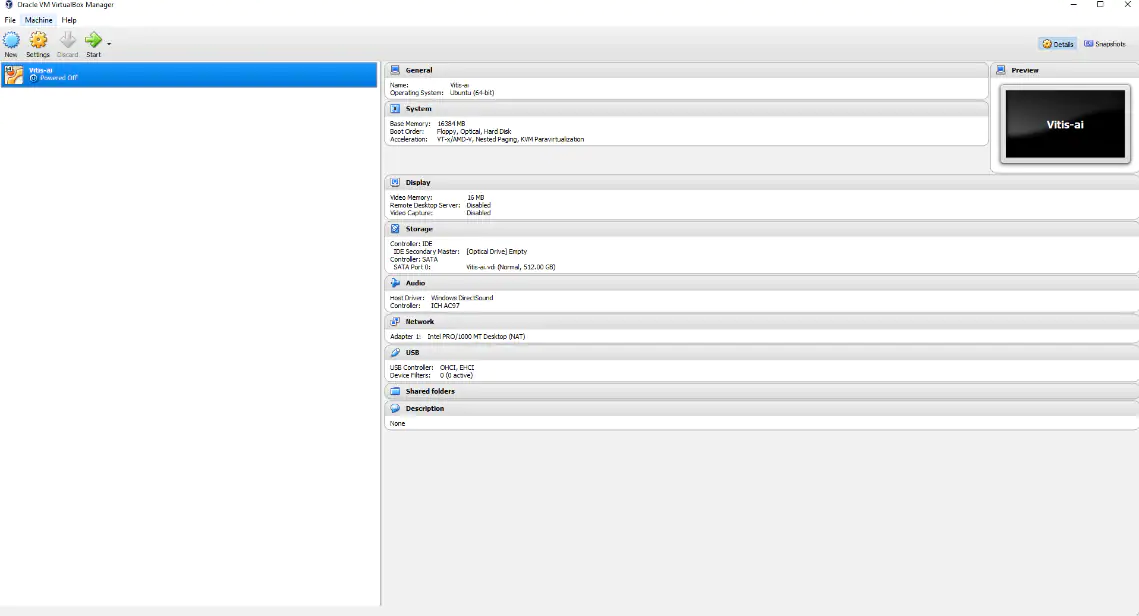
图4:启动虚拟机
在启动虚拟机时,会要求安装之前下载的Ubuntu ISO(见图5)。
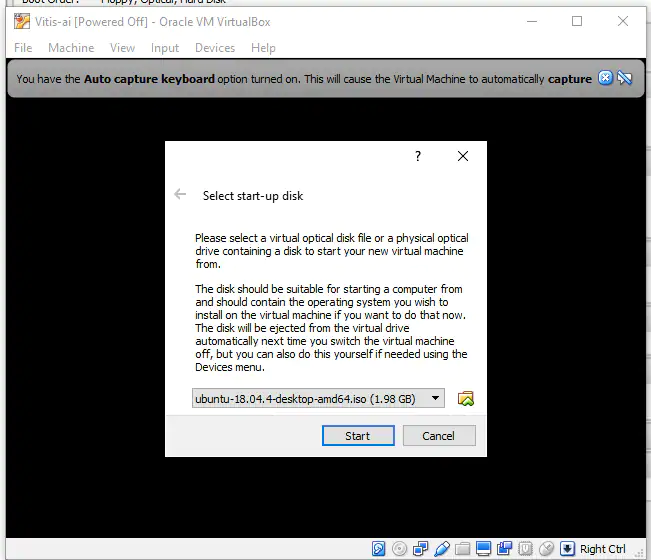
图5:选择安装盘
在虚拟硬盘上安装Ubuntu操作系统。选择安装Ubuntu(见图6)。
图6:安装Ubuntu
在选择好Ubuntu的位置和配置选项后, 进行键盘配置(见图7)。
图7:选择本地化设置
选择最小安装(见图8),因为我们不需要使用办公软件、媒体播放器或玩游戏。
图8:选择最小安装
在安装期间擦除磁盘并安装Ubuntu(见图9)。
图9:擦除磁盘
单击continue继续操作(见图10)。
图10:启用磁盘改写
选择您所在的地理位置与时区(见图11)。
图11:设置时区
最后,输入Ubuntu计算机名、用户名及密码(见图12)。
图12:设置帐户名和密码
安装完成后,重启虚拟机(见图13)。
图13:重启虚拟机
重启后,登录并开始安装Vitis AI。
安装Vitis和Vitis AI
对于运行Linux的虚拟机,接下来需要安装Vitis和Vitis AI。安装Vitis时,需要用到在下载时创建的Xilinx帐户。Vitis安装时间较长,所以我们会先安装它。
打开Xilinx下载页面,选择Linux Self Extracting Web Installer(见图15)。
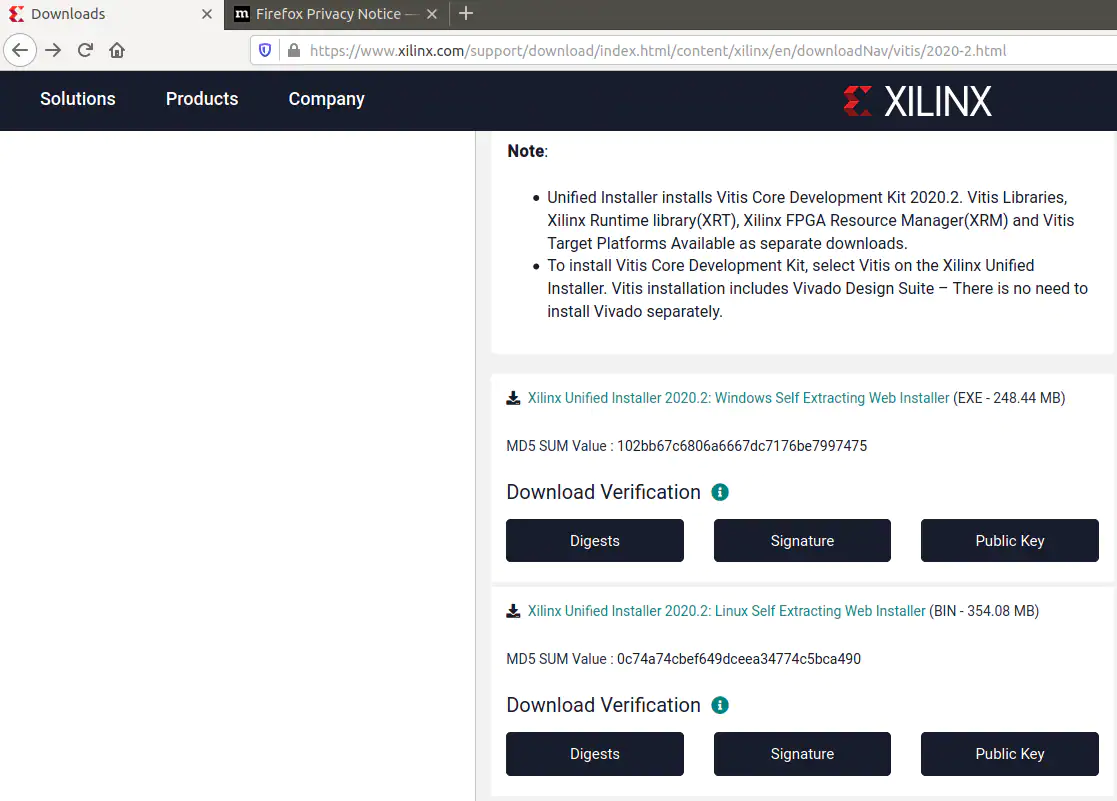
图15:Xilinx Linux Installer
下载web安装程序后,找到下载位置,选择应用程序,右键单击以更改权限,使其能够作为应用程序执行(见图16)。
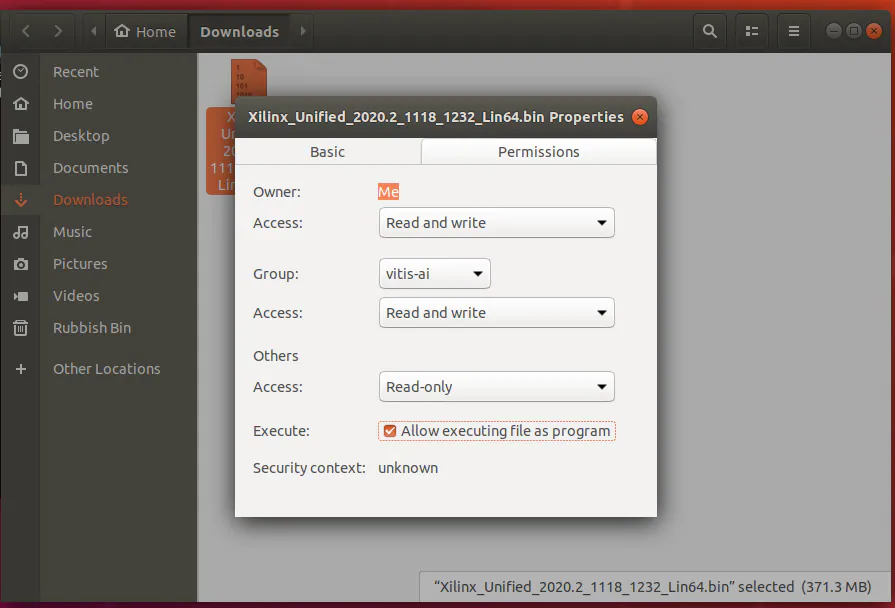
图16:设置适当权限
现在可以使用终端窗口来安装Vitis,所需时间取决于虚拟机和internet连接性能。
通过以下sudo命令来安装此工具(见图17)。
sudo 。/Xilinx_Unified_2020.2_1118_1232_Lin64.bin
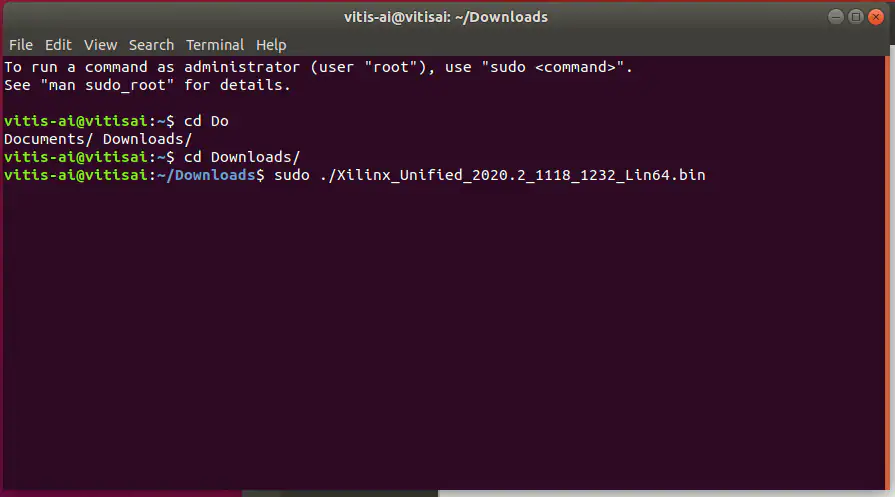
图17:运行安装程序
此时将启动Vitis Installer(见图18)。
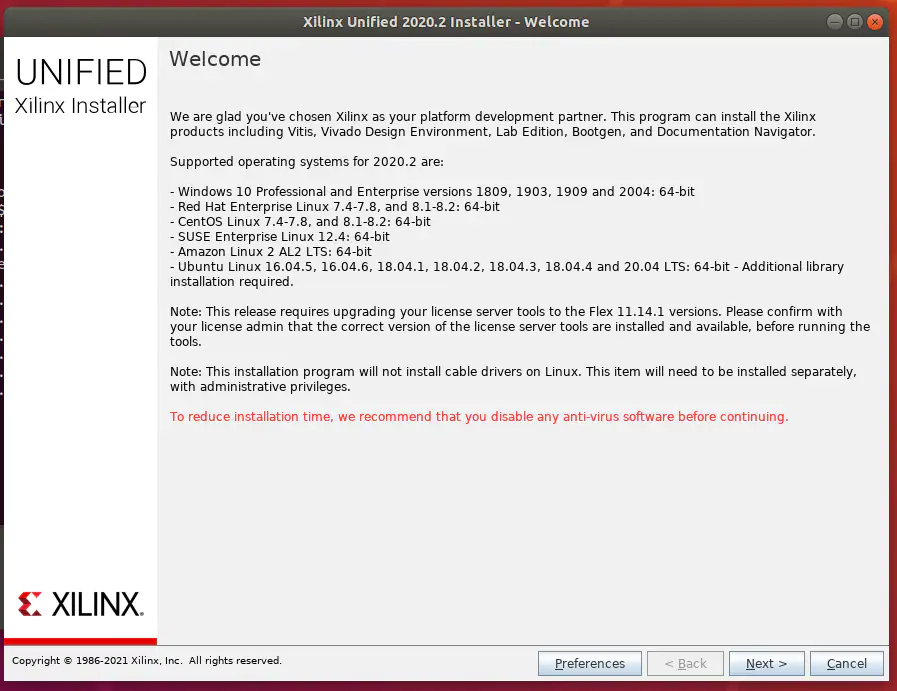
图18:启动安装程序
登录您的帐户(见图19)。
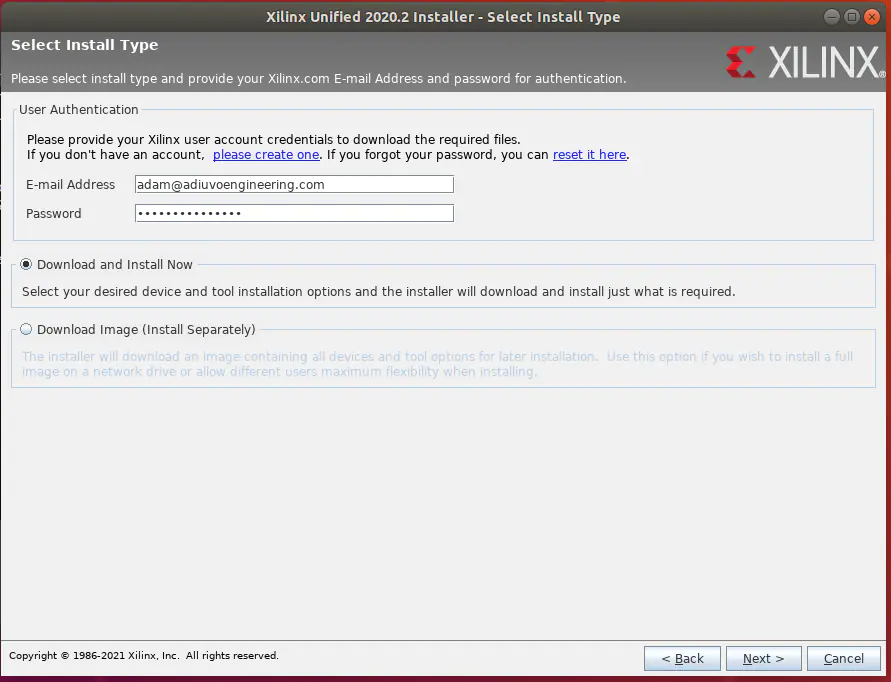
图19:登录您的Xilinx帐户
选择Vitis作为目标应用程序, 同时还会安装Vivado(见图20)。
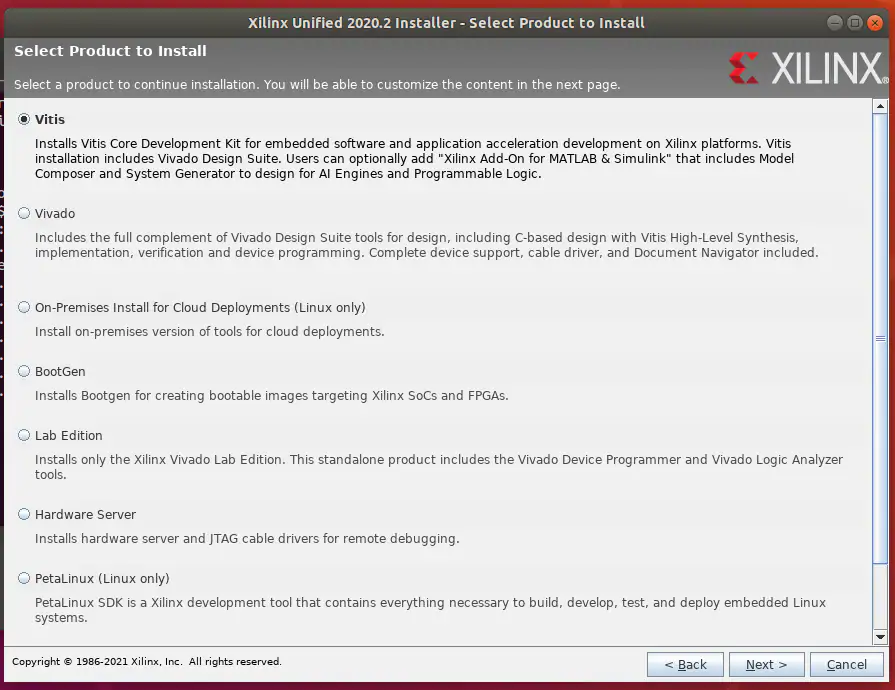
图20:安装Vitis与Vivado
为了节省安装空间,应取消选择除SoC以外的所有设备(见图21)。
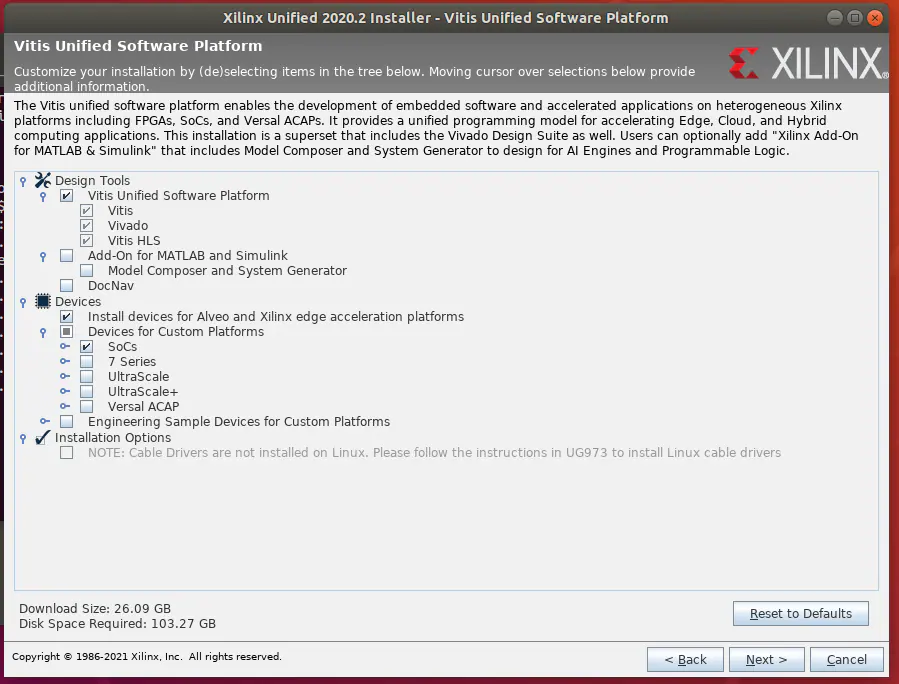
图21:最大程度节省安装空间
接受安装条件和条款(见图22)。
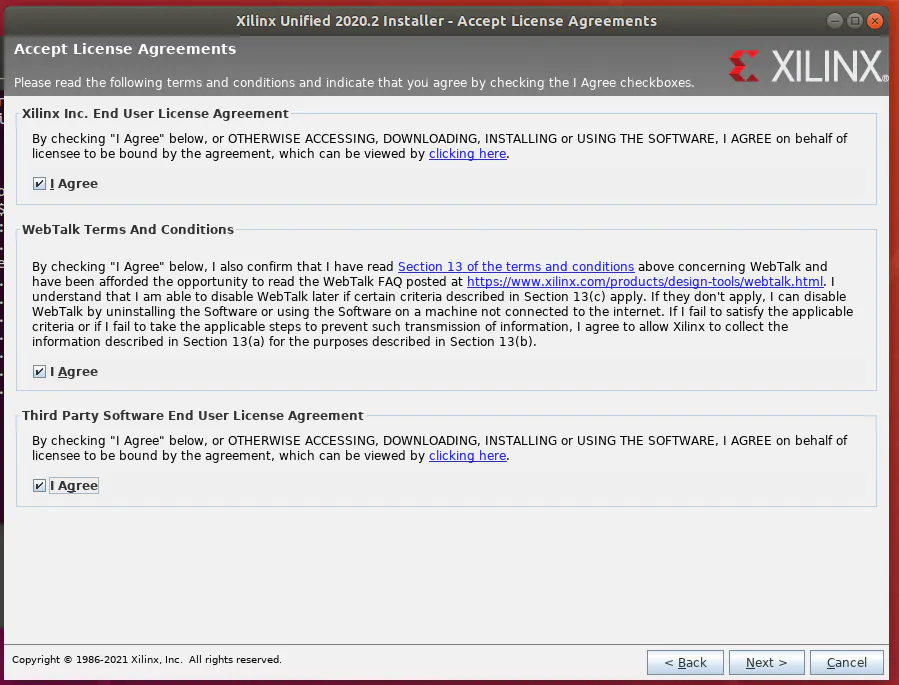
图22:接受安装条件和条款
选择安装目录, 建议使用默认位置(见图23)。
图23:选择安装位置
在Installation Summary中,选择Install并等待安装完毕(见图24)。
图24:完成安装
安装完成后,需要运行以下脚本以安装所有相关项:
sudo /Vitis//scripts/installLibs.sh
接下来,安装Vitis AI。在本例中,我们将安装Vitis AI以从CPU而不是GPU运行,因而会影响训练性能。
首先要安装docker, 请按照此处的说明进行操作。注意,可能需要在安装完成后重启虚拟机。
接下来,请使用以下命令安装Git:
sudo apt update sudo apt install git
选择/创建Vitis-AI的安装目录。使用以下命令克隆Vitis-AI:
git clone https://github.com/Xilinx/Vitis-AI.git
一旦克隆好Vitis-AI存储库,请将其改为存储目录,并提取docker映像。
cd Vitis-AI docker pull xilinx/vitis-ai:latest
从docker下载最新的Vitis-AI映像将需要几分钟的时间。
在提取docker映像之后,我们需要构建交叉编译系统。可以通过运行Vitis-AI/setup/mpsoc/VART中的脚本来完成此操作(见图25)。
cd Vitis-AI/setup/mpsoc/VART 。/host_cross_compiler_setup_2020.2.sh
图25:安装SDK路径
运行脚本后,请确保运行指定的命令以启用交叉编译环境。
我们可以通过编译一个演示程序来测试是否正确安装了Vitis AI。在本例中,我们采用的是demo/VART/Resnet50目录下提供的resnet50应用程序。请使用以下命令编译应用程序:
Bash -x build.sh
如果您在终端窗口中没有看到错误,并且可执行文件出现在目录中,则说明Vitis AI安装成功(见图26):
图26:编译引擎
现在,我们需要开发数据集,以显示正确和错误黏贴的标签。
创建数据集
为了训练神经网络,我们首先需要一组正确和错误图像的数据集。我们以几个正确和错误地黏贴了贸泽标签的箱子为例。为了获得多样化的图像,我们从多个角度拍摄了正确和错误黏贴标签的箱子。
这些图像被整理成两个目录——一个是正确的标签,另一个是错误的标签。
对于捕获到的图像,我们需要训练一个神经网络。在本例中,我们将使用Edge Impulse。请注意,您需要为Edge Impulse创建一个免费的帐户。
在Edge Impulse端,首先要创建一个新项目(见图29)。
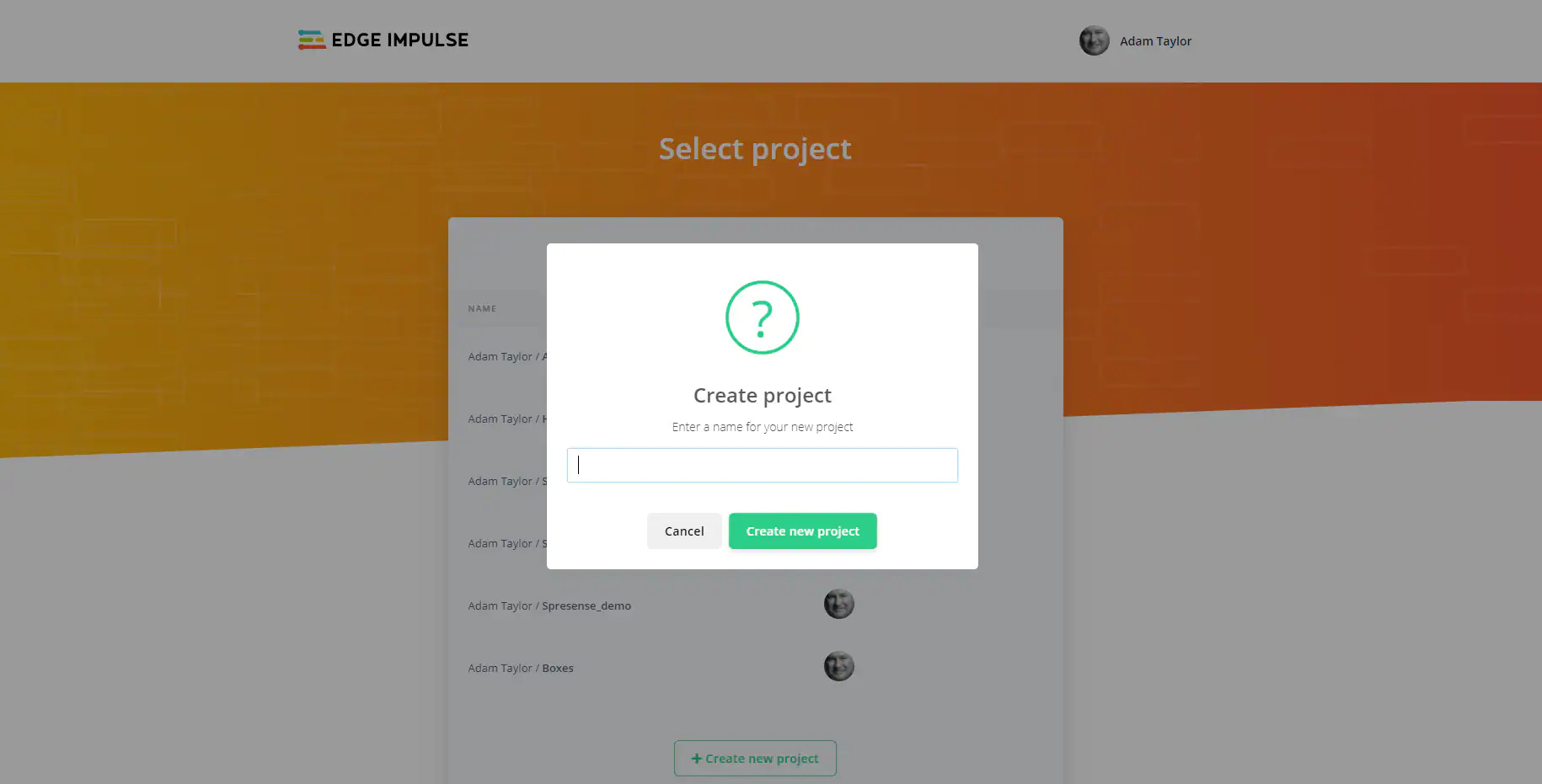
图29:创建Edge Impulse项目
新项目创建后,可以上传标记为正确和错误的图像文件夹。首先选择正确目录中的所有文件并进行上传,标记为Label_Correct。随后,上传错误的图像并将其标记为Label_Incorrect(见图30)。
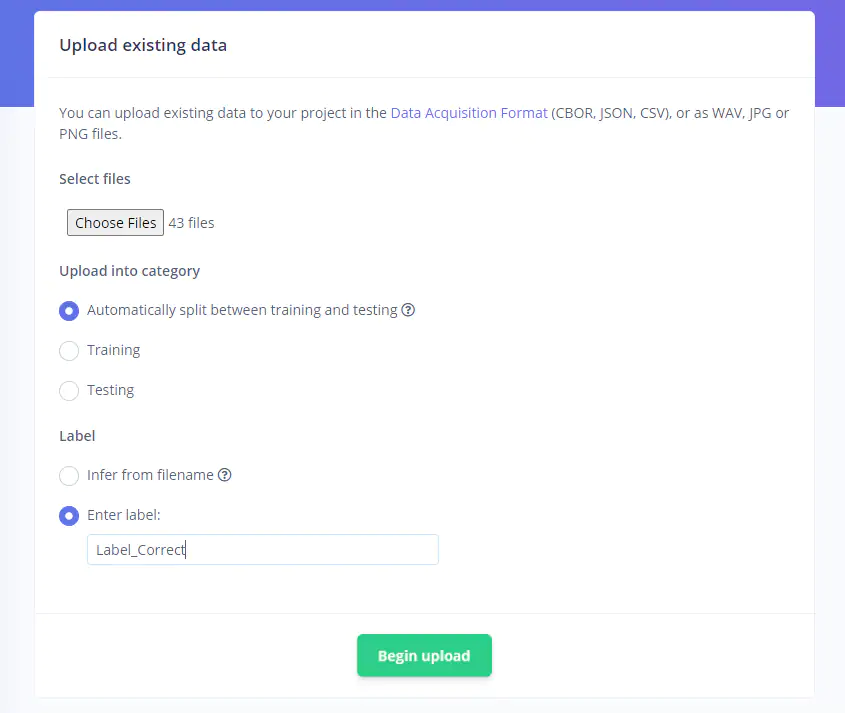
图30:上传数据
所有图像都上传完成后,接下来就要定义Impulse。选择宽度和高度均为224像素的输入图像。选择图像,输入Transfer Learning,然后保存Impulse(见图31)。
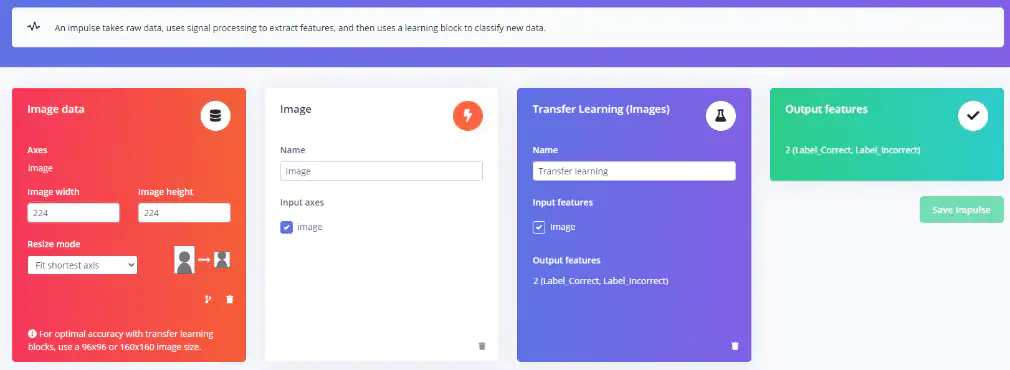
图31:设置Impulse
然后,我们可以通过生成特征和训练Impulse来训练模型(见图32)。
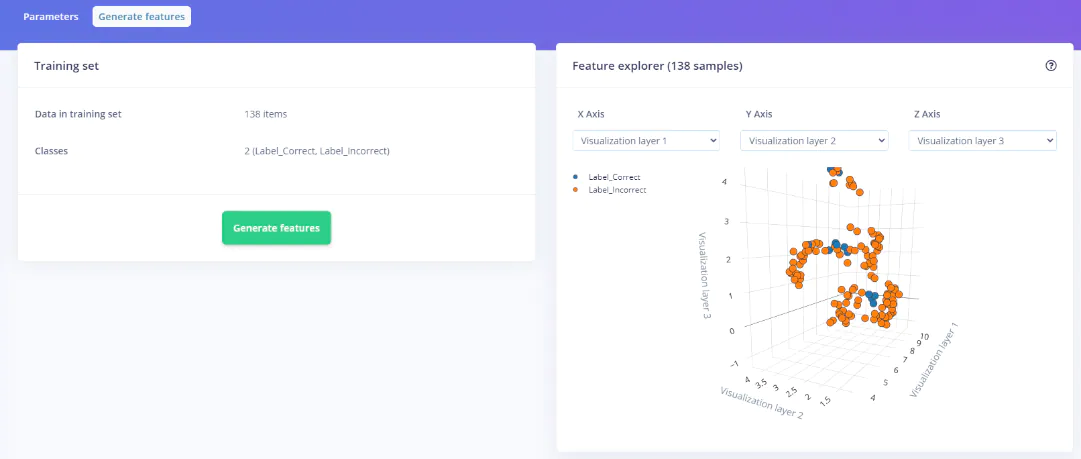
图32:生成特征
选择模型MobileNetV2 160x160 1.0,等效模型位于Xilinx Model Zoo下(见图33)。
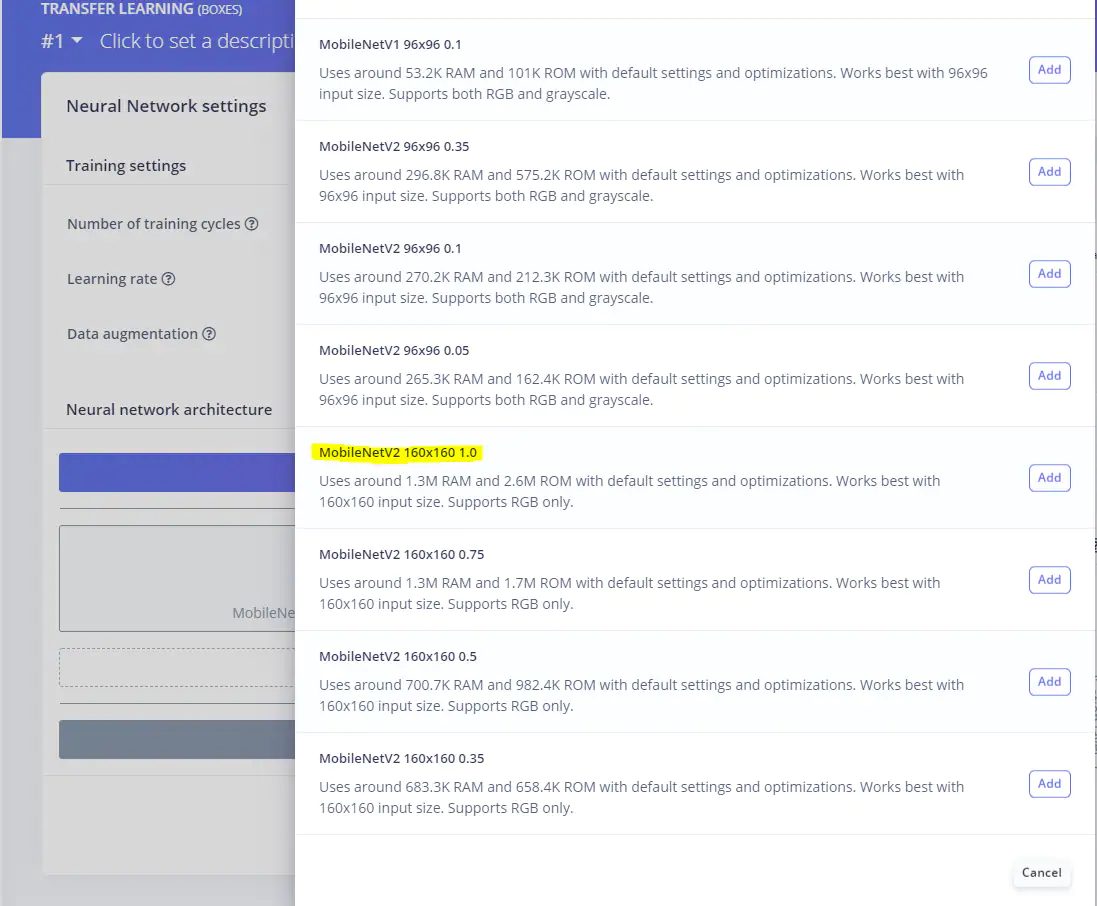
图33:选择正确的模型
可能需要几分钟的时间来训练模型。训练完成后,返回概览页面,选择下载迁移学习模型(见图34)。
这将包括保存的模型和.zip文件中的变量(检查点)。
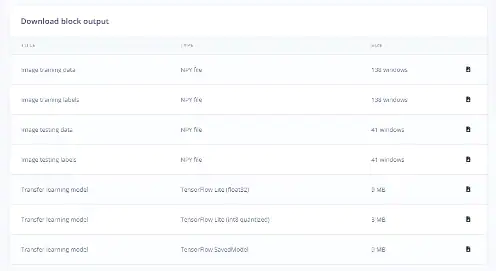
图34:下载保存的模型
量化并编译模型
接下来使用Vitis AI对模型进行量化和编译。在虚拟机中,我们可以通过发出以下命令来运行Vitis AI(见图35)。
。/docker_runs.sh Xilinx/vitis-ai-cpu:latest
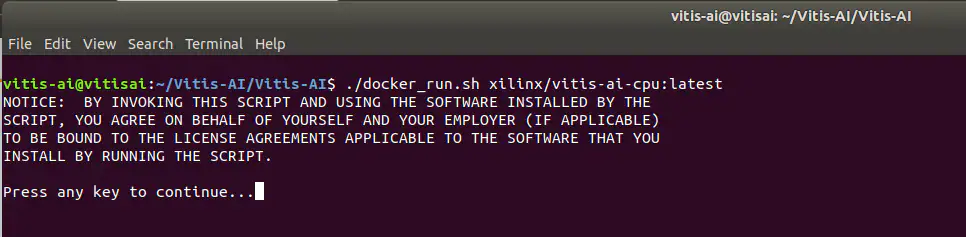
图35:启动Vitis AI
加载Vitis AI后,使用以下命令激活TensorFlow(见图36)。
conda activate vitis-ai-tensorflow
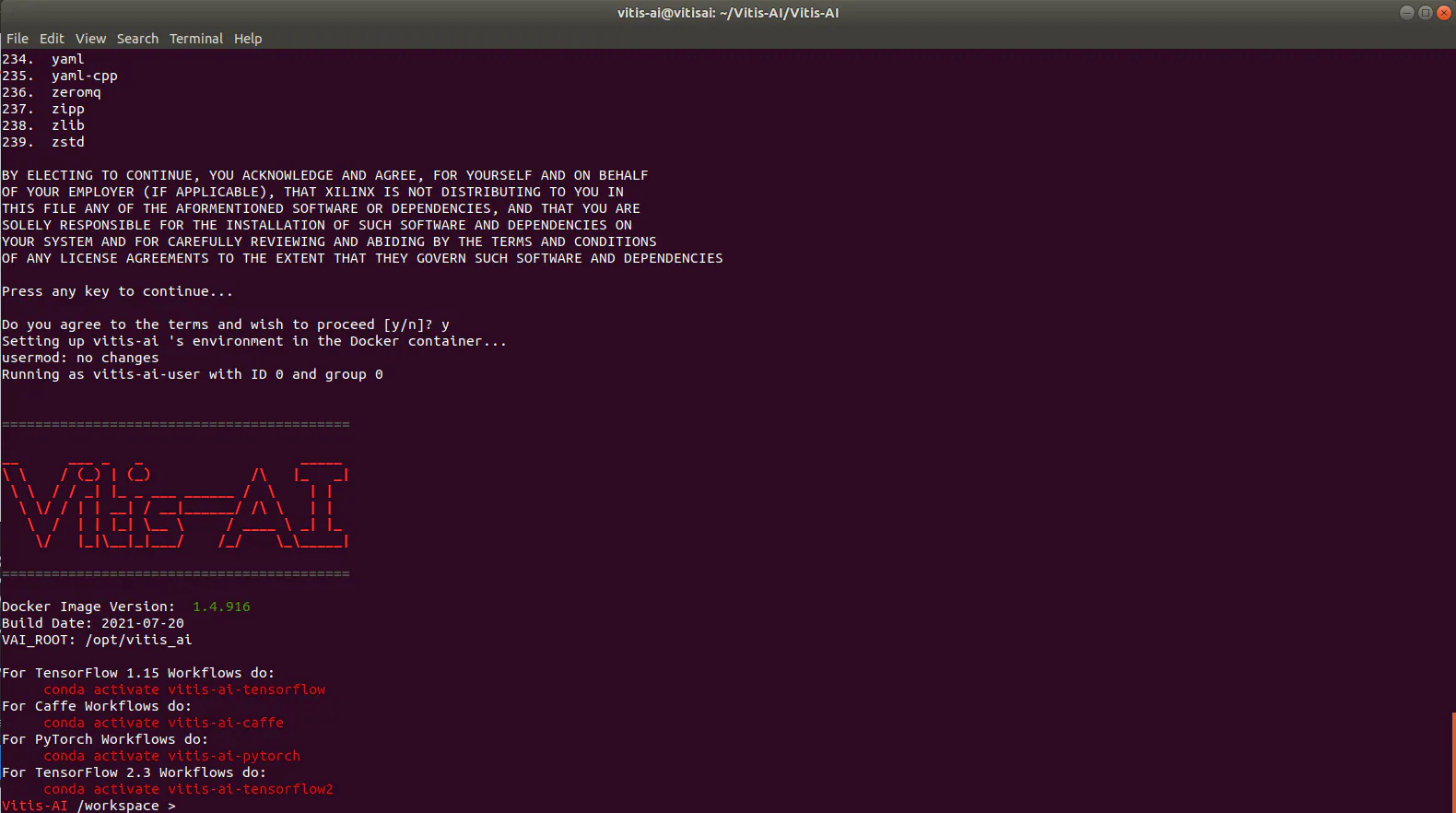
图36:激活Vitis AI TensorFlow
接下来,冻结将检查点的信息合并到冻结模型文件的模型(见图37)。

图37:编译冻结模型
一旦模型作为冻结模型输出,我们就可以使用编译器编译输出模型,以部署到系统中。
我们可以从Xilinx Model Zoo中包含的YAML文件中了解输出节点的信息(见图38)。
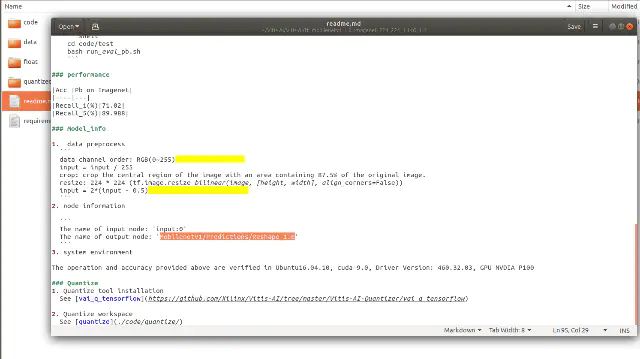
图38:探索模型
要检查冻结的网表,则需要安装Netron。此外,理解量化过程的输入和输出节点名称也很重要(见图39)。
图39:安装Netron
有了量化网表,我们可以将量化网表编译为部署在Kria SoM上的模型(见图40)。
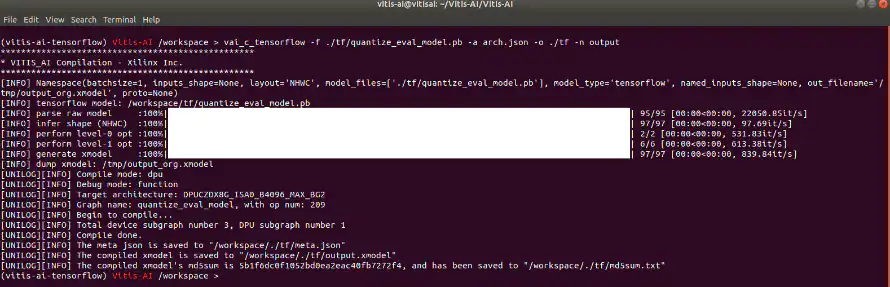
图40:编译模型/
借助于SCP/FTP,我们可以将编译后的模型上载到以下目录中的Kria文件系统:
/usr/share/vitis_ai_library/models/
上传好模型后,可以生成一个软件应用程序,用于测试神经网络。这时,我们可以将几个正确和错误的图像上载到Kria SoM,来测试应用程序。
结语
该项目展示了对于工业AI/ML应用,在Kria SoM中训练和部署神经网络是一件非常简单的事情, 其应用潜力也是无限的。未来可能需要更新软件以利用gstreamer框架,并像在生产线上一样对实时图像进行分类。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
19275浏览量
229739 -
连接器
+关注
关注
98文章
14502浏览量
136484 -
人工智能
+关注
关注
1791文章
47242浏览量
238355
发布评论请先 登录
相关推荐
边缘人工智能与视觉联盟在年度最佳产品典礼上授予Blaize®, Inc.最佳边缘人工智能处理工具奖









 工商网监
工商网监
评论