 计算机视觉中不同的特征提取方法对比
计算机视觉中不同的特征提取方法对比
概述
特征提取是计算机视觉中的一个重要主题。不论是SLAM、SFM、三维重建等重要应用的底层都是建立在特征点跨图像可靠地提取和匹配之上。特征提取是计算机视觉领域经久不衰的研究热点,总的来说,快速、准确、鲁棒的特征点提取是实现上层任务基本要求。
特征点是图像中梯度变化较为剧烈的像素,比如:角点、边缘等。FAST(Features from Accelerated Segment Test)是一种高速的角点检测算法;而尺度不变特征变换SIFT(Scale-invariant feature transform)仍然可能是最著名的传统局部特征点。也是迄今使用最为广泛的一种特征。特征提取一般包含特征点检测和描述子计算两个过程。描述子是一种度量特征相似度的手段,用来确定不同图像中对应空间同一物体,比如:BRIEF(Binary Robust IndependentElementary Features)描述子。可靠的特征提取应该包含以下特性:
(1)对图像的旋转和尺度变化具有不变性;(2)对三维视角变化和光照变化具有很强的适应性;(3)局部特征在遮挡和场景杂乱时仍保持不变性;(4)特征之间相互区分的能力强,有利于匹配;(5)数量较多,一般500×500的图像能提取出约2000个特征点。
近几年深度学习的兴起使得不少学者试图使用深度网络提取图像特征点,并且取得了阶段性的结果。图1给出了不同特征提取方法的特性。本文中的传统算法以ORB特征为例,深度学习以SuperPoint为例来阐述他们的原理并对比性能。
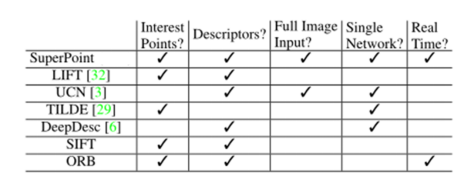
图1 不同的特征提取方法对比
传统算法—ORB特征
尽管SIFT是特征提取中最著名的方法,但是因为其计算量较大而无法在一些实时应用中使用。为了研究一种快速兼顾准确性的特征提取算法,Ethan Rublee等人在2011年提出了ORB特征:“ORB:An Efficient Alternative to SIFT or SURF”。ORB算法分为两部分,分别是特征点提取和特征点描述。ORB特征是将FAST特征点的检测方法与BRIEF特征描述子结合起来,并在它们原来的基础上做了改进与优化。其速度是SIFT的100倍,是SURF的10倍。Fast特征提取从图像中选取一点P,如图2。按以下步骤判断该点是不是特征点:以P为圆心画一个半径为3 pixel的圆;对圆周上的像素点进行灰度值比较,找出灰度值超过 l(P)+h 和低于 l(P)-h 的像素,其中l(P)是P点的灰度, h是给定的阈值;如果有连续n个像素满足条件,则认为P为特征点。一般n设置为9。为了加快特征点的提取,首先检测1、9、5、13位置上的灰度值,如果P是特征点,那么这四个位置上有3个或3个以上的像素满足条件。如果不满足,则直接排除此点。

图2 FAST特征点判断示意图上述步骤检测出的FAST角点数量很大且不确定,因此ORB对其进行改进。对于目标数量K为个关键点,对原始FAST角点分别计算Harris响应值,,然后根据响应值来对特征点进行排序,选取前K个具有最大响应的角点作为最终的角点集合。除此之外,FAST不具有尺度不变性和旋转不变性。ORB算法构建了图像金字塔,对图像进行不同层次的降采样,获得不同分辨率的图像,并在金字塔的每一层上检测角点,从而获得多尺度特征。最后,利用灰度质心法计算特征点的主方向。作者使用矩来计算特征点半径范围内的质心,特征点坐标到质心形成一个向量作为该特征点的方向。矩定义如下:
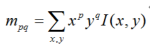
计算图像的0和1阶矩:
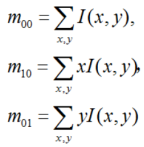
则特征点的邻域质心为:
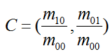
进一步得到特征点主方向:
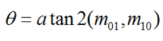
描述子计算BRIEF算法计算出来的是一个二进制串的特征描述符,具有高速、低存储的特点。具体步骤是在一个特征点的邻域内,选择n对像素点pi、qi(i=1,2,…,n)。然后比较每个点对的灰度值的大小。如果I(pi)》 I(qi),则生成二进制串中的1,否则为0。所有的点对都进行比较,则生成长度为n的二进制串。一般n取128、256或512。另外,为了增加特征描述符的抗噪性,算法首先需要对图像进行高斯平滑处理。在选取点对的时候,作者测试了5种模式来寻找一种特征点匹配的最优模式(pattern)。

图3 测试分布方法最终的结论是,第二种模式(b)可以取得较好的匹配结果。
深度学习的方法—SuperPoint
深度学习解决特征点提取的思路是利用深度神经网络提取特征点而不是手工设计特征,它的特征检测性能与训练样本、网络结构紧密相关。一般分为特征检测模块和描述子计算模块。在这里以应用较为广泛的SuperPoint为例介绍该方法的主要思路。该方法采用了自监督的全卷积网络框架,训练得到特征点(keypoint)和描述子(descriptors)。自监督指的是该网络训练使用的数据集也是通过深度学习的方法构造的。该网络可分为三个部分(见图1),(a)是BaseDetector(特征点检测网络),(b)是真值自标定模块。(c)是SuperPoint网络,输出特征点和描述子。虽然是基于深度学习的框架,但是该方法在Titan X GPU上可以输出70HZ的检测结果,完全满足实时性的要求。
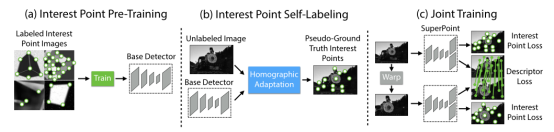
图4 SuperPoint 网络结构示意图下面分别介绍一下三个部分:BaseDetector特征点检测:首先创建一个大规模的合成数据集:由渲染的三角形、四边形、线、立方体、棋盘和星星组成的合成数据,每个都有真实的角点位置。渲染合成图像后,将单应变换应用于每个图像以增加训练数据集。单应变换对应着变换后角点真实位置。为了增强其泛化能力,作者还在图片中人为添加了一些噪声和不具有特征点的形状,比如椭圆等。该数据集用于训练 MagicPoint 卷积神经网络,即BaseDetector。注意这里的检测出的特征点不是SuperPoint,还需要经过Homographic Adaptation操作。
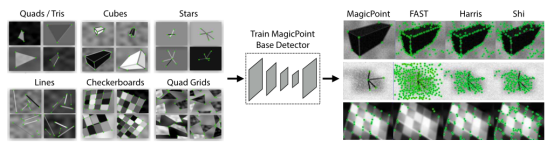
图5 预训练示意图特征检测性能表现如下表:
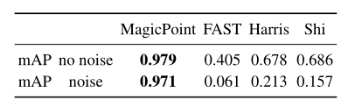
图 6 MagicPoint 模型在检测简单几何形状的角点方面优于经典检测器真值自标定:Homographic Adaptation 旨在实现兴趣点检测器的自我监督训练。它多次将输入图像进行单应变换,以帮助兴趣点检测器从许多不同的视点和尺度看到场景。以提高检测器的性能并生成伪真实特征点。
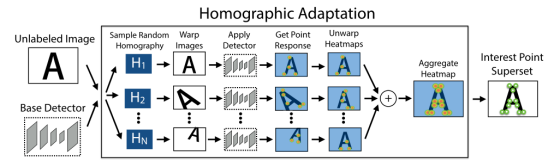
图7 Homographic Adaptation操作Homographic Adaptation可以提高卷积神经网络训练的特征点检测器的几何一致性。该过程可以反复重复,以不断自我监督和改进特征点检测器。在我们所有的实验中,我们将Homographic Adaptation 与 MagicPoint 检测器结合使用后的模型称为 SuperPoint。

图8 Iterative Homographic AdaptationSuperPoint网络:SuperPoint 是全卷积神经网络架构,它在全尺寸图像上运行,并在单次前向传递中产生带有固定长度描述符的特征点检测(见图 9)。该模型有一个共享的编码器来处理和减少输入图像的维数。在编码器之后,该架构分为两个解码器“头”,它们学习特定任务的权重——一个用于特征检测,另一个用于描述子计算。大多数网络参数在两个任务之间共享,这与传统系统不同,传统系统首先检测兴趣点,然后计算描述符,并且缺乏在两个任务之间共享计算和表示的能力。
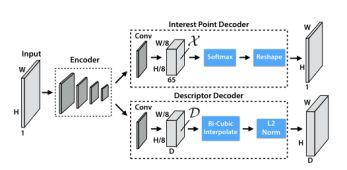
图 9 SuperPoint DecodersSuperPoint 架构使用类似VGG编码器来降低图像的维度。编码器由卷积层、通过池化的空间下采样和非线性激活函数组成。解码器对图片的每个像素都计算一个概率,这个概率表示的就是其为特征点的可能性大小。描述子输出网络也是一个解码器。先学习半稠密的描述子(不使用稠密的方式是为了减少计算量和内存),然后进行双三次插值算法(bicubic interpolation)得到完整描述子,最后再使用L2标准化(L2-normalizes)得到单位长度的描述。最终损失是两个中间损失的总和:一个用于兴趣点检测器 Lp,另一个用于描述符 Ld。我们使用成对的合成图像,它们具有真实特征点位置和来自与两幅图像相关的随机生成的单应性 H 的地面实况对应关系。同时优化两个损失,如图 4c 所示。使用λ来平衡最终的损失:
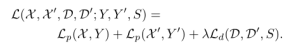
实验效果对比:
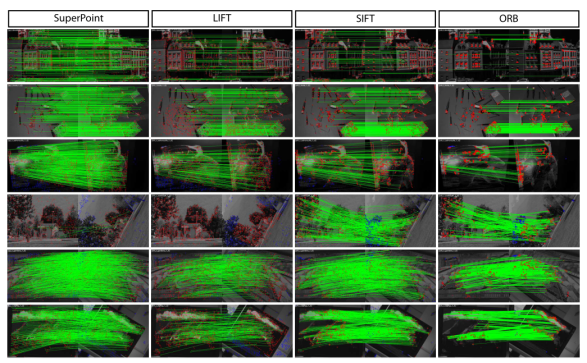
图10 不同的特征检测方法定性比较
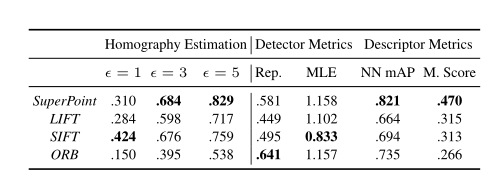
图 11 检测器和描述符性能的相关指标
结论
在特征检测上,传统方法通过大量经验设计出了特征检测方法和描述子。尽管这些特征在光照变化剧烈,旋转幅度大等情况下还存在鲁棒性问题,但仍然是目前应用最多、最成熟的方法,比如ORB-SLAM使用的ORB特征、VINS-Mono使用的FAST特征等都是传统的特征点。深度学习的方法在特征检测上表现了优异的性能,但是:(1)存在模型不可解释性的问题;(2)在检测和匹配精度上仍然没有超过最经典的SIFT算法。(3)大部分深度学习的方案在CPU上运实时性差,需要GPU的加速。(4)训练需要大量不同场景的图像数据,训练困难。本文最后的Homograpyhy Estimation指标,SuperPiont超过了传统算法,但是评估的是单应变换精度。单应变换在并不能涵盖所有的图像变换。比如具有一般性质的基础矩阵或者本质矩阵的变换,SurperPoint表现可能不如传统方法。
原文标题:特征提取:传统算法 vs 深度学习
文章出处:【微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
-
计算机视觉
+关注
关注
8文章
1698浏览量
45980 -
计算模块
+关注
关注
0文章
16浏览量
6195 -
深度学习
+关注
关注
73文章
5500浏览量
121113
原文标题:特征提取:传统算法 vs 深度学习
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
计算机视觉有哪些优缺点
图像识别算法的核心威廉希尔官方网站 是什么
计算机视觉的工作原理和应用
机器人视觉与计算机视觉的区别与联系
计算机视觉与人工智能的关系是什么
计算机视觉与智能感知是干嘛的
计算机视觉怎么给图像分类
深度学习在计算机视觉领域的应用
机器视觉与计算机视觉的区别
计算机视觉的主要研究方向
计算机视觉的十大算法






 工商网监
工商网监
评论