 一种缓解负采样偏差的对比学习句表示框架DCLR
一种缓解负采样偏差的对比学习句表示框架DCLR
本文针对句表示对比学习中的负采样偏差进行研究,提出了一种针对错负例和各向异性问题的去偏句表示对比学习框架。该框架包括一种惩罚假负例的实例加权方法以及一种基于噪声的负例生成方法,有效缓解了句表示任务中的负采样偏差问题,提升了表示空间的均匀性。
论文题目:Debiased Contrastive Learning of Unsupervised Sentence Representations
论文下载地址:https://arxiv.org/abs/2205.00656
论文开源代码:https://github.com/rucaibox/dclr
引言
作为自然语言处理(NLP)领域的一项基本任务,无监督句表示学习(unsupervised sentence representation learning)旨在得到高质量的句表示,以用于各种下游任务,特别是低资源领域或计算成本较高的任务,如 zero-shot 文本语义匹配、大规模语义相似性计算等等。
考虑到预训练语言模型原始句表示的各向异性问题,对比学习被引入到句表示任务中。然而,以往工作的大多采用批次内负采样或训练数据随机负采样,这可能会造成采样偏差(sampling bias),导致不恰当的负例(假负例或各向异性的负例)被用来进行对比学习,最终损害表示空间的对齐度(alignment)和均匀性(uniformity)。
为了解决以上问题,我们提出了一种新的句表示学习框架 DCLR(Debiased Contrastive Learning of Unsupervised Sentence Representations)。在 DCLR 中,我们设计了一种惩罚假负例的实例加权方法以及一种基于噪声的负例生成方法,有效缓解了句表示任务中的负采样偏差问题,提升了表示空间的对齐度和均匀性。
背景与动机
近年来,预训练语言模型在各种 NLP 任务上取得了令人瞩目的表现。然而,一些研究发现,由预训练模型得出的原始句表示相似度都很高,在向量空间中并不是均匀分布的,而是构成了一个狭窄的锥体,这在很大程度上限制了句表示的表达能力。
为了得到分布均匀的句表示,对比学习被应用于句表示学习中。对比学习的目标是从数据中学习到一个优质的语义表示空间。优质的语义表示空间需要正例表示分布足够接近,同时语义表示尽量均匀地分布在超球面上,具体可以用以下两种指标来衡量:
1、对齐度(alignment)计算原始表示与正例表示的平均距离。
2、均匀性(uniformity)计算表示整体在超球面上分布的均匀程度。
因此,对比学习的思想为拉近语义相似的正例表示以提高对齐度,同时推开不相关的负例以提高整个表示空间的均匀性。
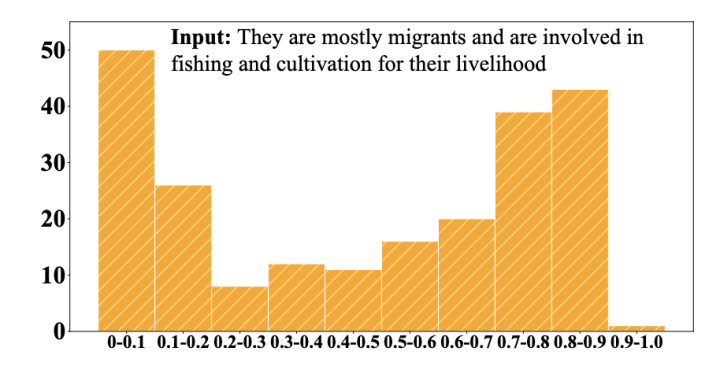
以往的基于对比学习的句表示学习工作大多使用 batch 内数据作为负例或从训练数据中随机采样负例。然而,这类方式可能会造成抽样偏差(sampling bias),导致不恰当的负例(例如假负例或各向异性的负例)被用来学习句表示,这将损害表征空间的对齐性和统一性。上图是 SimCSE 编码的输入句表示与批次内其它样本表示的余弦相似度分布。可以看到,有接近一半的相似度高于 0.7,直接在向量空间中推远这些负例很有可能损害模型的语义表示能力。
因此,本文聚焦于如何降低负采样偏差,从而使得对比学习得到向量分布对齐、均匀的句表示。
方法简介
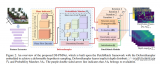
DCLR 聚焦于减少句表示对比学习中负采样偏差的影响。在这个框架中,我们设计了一种基于噪声的负例生成策略和一种惩罚假负例的实例加权方法。
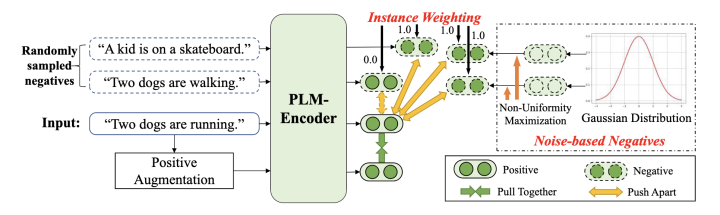
基于噪声的负例生成
对于每个输入句 ,我们首先基于高斯分布初始化个噪声向量作为负例表示:
其中为标准差。因为这些噪声向量是从上述高斯分布中随机初始化的,所以它们均匀地分布在语义空间中。因此,模型可以通过学习这些负例来提高语义空间的均匀性。
为了提高生成负例的质量,我们考虑迭代更新负例,以捕捉语义空间中的非均匀性点。受虚拟对抗训练(virtual adversarial training, VAT)的启发,我们设计了一个非均匀性(non-uniformity)损失最大化的目标函数以产生梯度来改善这些负例。具体来说,目标函数表示为基于噪声的负例与正例表示的对比学习损失:
其中是温度超参数,是余弦相似度。对于每个负例 ,我们通过 t 步梯度上升法对其进行优化:
其中为学习率,是 L2 范数。表示通过最大化非均匀性目标函数产生的的梯度。这样一来,基于噪音的负例将朝着句表示空间的非均匀点优化。学习与这些负例的对比可以进一步提高表示空间的均匀性。
带有实例加权的对比学习
除了上述基于噪音的负例,我们也遵循现有工作,使用其它批次内样本表示作为负例。然而,如前文所述,批次内负例可能包含与正例有类似语义的例子,即假负例。为了缓解这个问题,我们提出了一种实例加权的方法来惩罚假负例。由于我们无法获得真实的负例标签,我们利用补充模型 SimCSE 来计算每个负例的权重。给定 或 {hat{h}}中的一个负例表示 和原始句表示 ,我们使用补全模型来计算权重:
其中 是实例加权阈值,是余弦相似度函数。通过上式,与原句表示有较高语义相似性的负例将被视为假负例,并将被赋予 0 权重作为惩罚。基于以上权重,我们用去偏的交叉熵对比学习损失函数来优化句表示:
我们的方法使用了 SimCSE 的 dropout 正例增广策略,但也适用于其它多种正例增广策略。
实验
数据集
遵循以往的工作,我们在 7 个标准语义文本相似度任务上进行实验。这些数据集由成对句子样本构成,其相似性分数被标记为 0 到 5。标签分数和句表示预测分数之间的相关性由 Spearman 相关度来衡量。
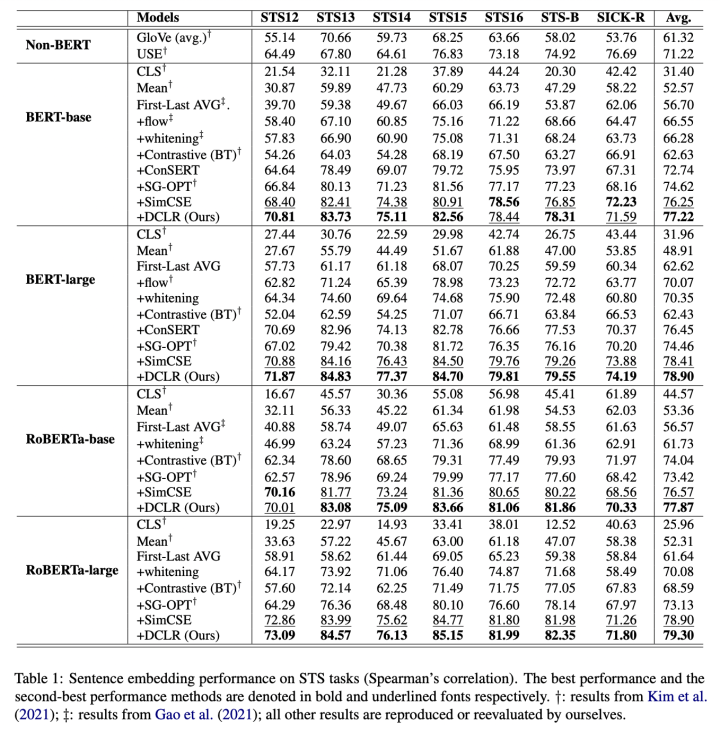
主实验
我们在 7 个数据集上进行了语义相似度测试,并与现有 baseline 进行比较。可以看到,DCLR 的性能在绝大部分实验中优于基线模型。
分析与扩展
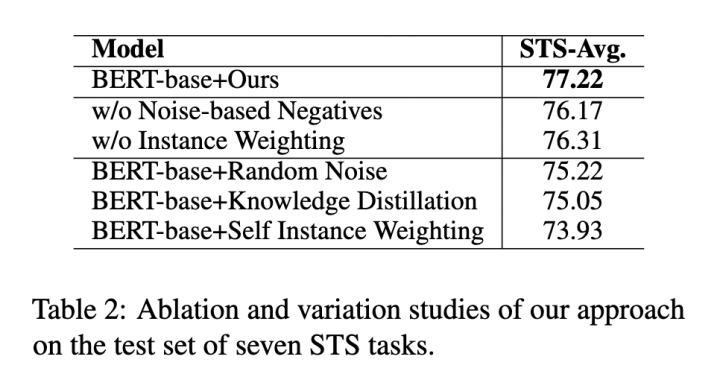
DCLR 框架包含两个去偏负采样策略,为了验证其有效性,我们对两部分分别进行了消融实验。除此之外,我们还考虑其它三种策略:
1、Random Noise 直接从高斯分布中生成负例,不进行梯度优化。
2、Knowledge Distillation 使用 SimCSE 作为教师模型在训练过程中向学生模型蒸馏知识。
3、Self Instance Weighting 将模型自己作为补全模型为实例计算权重。
结果显示 DCLR 的性能优于各类变种,表明所提策略的合理性。
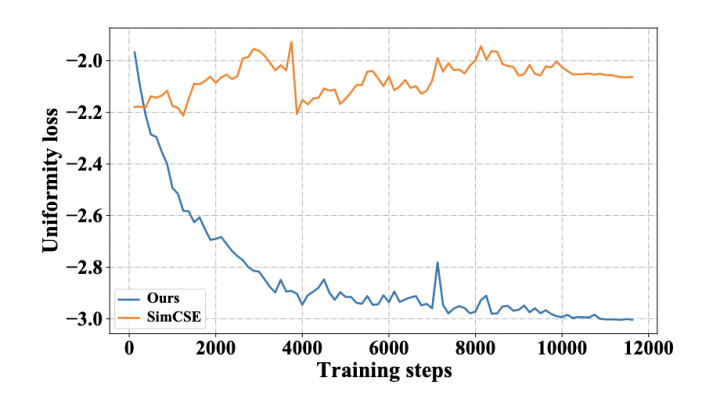
均匀性是句表示的一个理想特征。我们比较了 DCLR 和 SimCSE 基于 BERT-base 在训练期间的均匀性损失曲线。遵循 SimCSE,均匀性损失函数为:
其中 是所有句表示的分布。如图所示,随着训练进行,DCLR 的均匀性损失下降,而 SimCSE 没有明显的下降趋势。这可能表明 DCLR 中基于噪声的负例采样方法能够有效改善语义空间的均匀性。
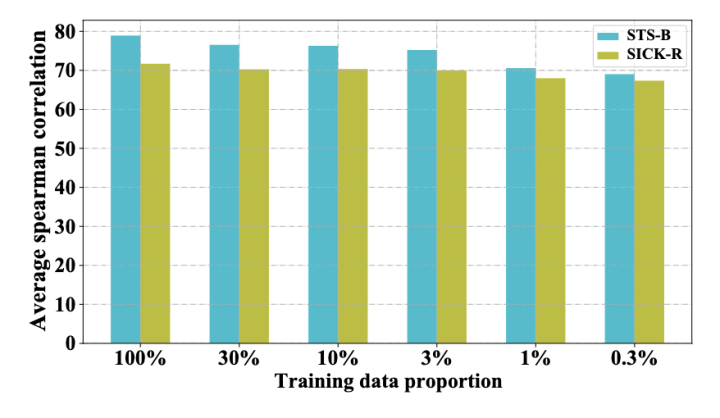
为了验证 DCLR 在少样本场景下的健壮性,我们在 0.3% 到 100% 的数据量设定下训练模型。结果表明,即使在相对极端的数据设定(0.3%)下,我们的模型性能也仅仅在两个任务中分别下降了了 9% 和 4%,这显示了模型在少样本场景中的有效性。
六. 总结
本文提出了一种缓解负采样偏差的对比学习句表示框架 DCLR。DCLR 采用一种可梯度更新的噪声负例生成方法来提高语义空间的均匀性,同时使用实例加权的方法缓解假负例问题,提升语义空间对齐度。实验表明,该方法在大部分任务设定下优于其它基线模型。
在未来,我们将探索其他减少句表示任务中对比学习偏差的方法(例如去偏预训练)。此外,我们还将考虑将我们的方法应用于多语言或多模态的表示学习。
审核编辑 :李倩
-
框架
+关注
关注
0文章
403浏览量
17489 -
语言模型
+关注
关注
0文章
524浏览量
10277 -
nlp
+关注
关注
1文章
488浏览量
22038
原文标题:ACL2022 | 无监督句表示的去偏对比学习
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
介绍一种 WiMax 双下变频 IF 采样接收机设计方案
将ADS1294用于数据采集,偶尔出现实际采样率与设定采样率之间存在3%的固定偏差,为什么?
一种面向飞行试验的数据融合框架

Dubbo源码浅析(一)—RPC框架与Dubbo
TLV9062IDR的电流采样电路,请问运放本身偏差大小是否正常?
INA826高端采样同一电流点有偏差是什么原因导致的?
NVIDIA推出全新深度学习框架fVDB
TensorFlow与PyTorch深度学习框架的比较与选择
用stm32f4的以太网传输ADC采用数据,ADC采样数据会发生偏差的原因?
一种高效的KV缓存压缩框架--GEAR

GD32断上电采样相同电压有偏差如何处理?

等效时间采样示波器与实时示波器的对比,有什么不同?
框架与芯片粘接中两种涂胶

PatchMatch MVS求解器中深度估计的挑战性问题





 工商网监
工商网监
评论