 NVIDIA T4 GPU加速VIVO推荐系统部署
NVIDIA T4 GPU加速VIVO推荐系统部署
案例简介及其应用背景
VIVO AI中台的最终目的是为2.6亿+ VIVO用户提供极致的智能服务,而NVIDIA则为VIVO推荐系统提供强大的算力支持以实践优化。
推荐系统的大规模部署带来了诸多工程化挑战,借助NVIDIA TensorRT, Triton and MPS (Multi-Process Service) 及单张T4 GPU推理卡,其性能优于约6台以上的78核CPU服务器,成本方面也降低75%。
团队共实践和比较了三种不同的工程方案,其中,性价比最高的“通用GPU方案”充分发挥了MPS和TensorFlow的性能,开创性地解决了推荐场景的难题,包含:如何满足频繁的算法迭代需求,如何开发不支持的运算操作插件,以及如何改善低效的推理服务性能等。
VIVO AI平台致力于建设完整的人工智能中台,搭建全面的、行业领先的大规模分布式机器学习平台,应用于内容推荐、商业变现、搜索等多种业务场景,为2.6亿+ VIVO用户提供极致的智能服务。
VIVO AI中台始终服务于企业往智能化深度发展的需求,在数据中台基础上增加了一体化智能服务的概念。并且立足于数据的获取、存储、特征处理、分析、模型构建、训练、评估等智能服务相关的任务环节,使其高度组件化、配置化、自动化。
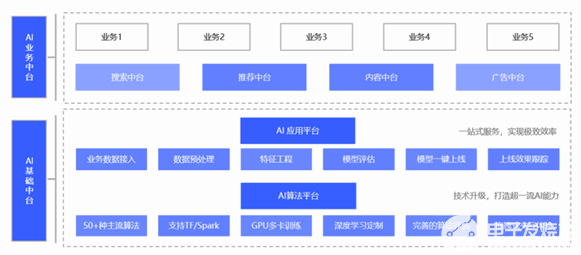
Figure 1. AI中台系统架构图 (图片来源于VIVO研究院授权)
在整个AI中台架构中,推荐中台则作为最重要的核心,也是最具商业价值的部分,不仅需承载VIVO亿级用户,日活千万的数据量也包含在内。本文从推荐系统工程化的角度,解读了以下三方面内容:VIVO 的智能推荐系统是如何运行的?在实际应用场景中遇到过什么挑战?NVIDIA GPU如何加速推荐系统的部署?
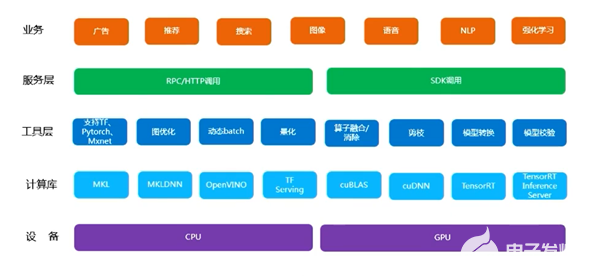
Figure 2. 推荐中台系统架构图 (图片来源于VIVO研究院授权)
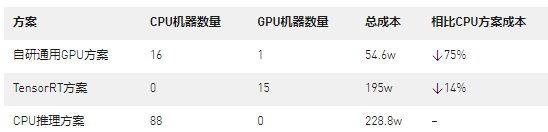
经过验证,本方案可以有效解决推荐业务中GPU通用性问题;同时能更高效的利用GPU。目前已经在部分推荐业务中落地。经过压测,性能方面,单张T4 GPU推理卡,性能优于约6台以上的78核CPU服务器。成本方面,VIVO自研通用GPU方案,在TensorRT方案基础上,取得了更高的QPS和更低的延迟,可节省成本约75%!
本案例主要应用到 NVIDIA T4 GPU 和相关工具包括NVIDA TensorRT, Triton, MPS等。
客户简介
VIVO是一家以设计驱动创造伟大产品,打造以智能终端和智慧服务为核心的科技公司,也是一家全球性的移动互联网智能终端公司。致力于为消费者打造拥有极致拍照、畅快游戏、Hi-Fi音乐的智能手机产品。根据《2020胡润中国10强消费电子企业》报告显示,VIVO以1750亿人民币排名第3位。
客户挑战
在工程实践中,VIVO推荐系统面临的第一个问题是如何平滑的把多种推荐业务逻辑从CPU平台向GPU平台迁移。鉴于当前已经存在多个推荐业务场景,包括应用商店,手机浏览器,负一屏信息流等。每个场景都有自己的算法模型和业务流程,如何把多种分散的智能服务整合到一个统一的推荐中台,同时要兼顾当前的业务的无损迁移是一个巨大的挑战。
一直以来,CPU是客户主要的支撑推荐业务场景的主流硬件平台。但VIVO工程团队却发现在推理服务中,CPU的表现始终无法达到要求标准,不仅算力较弱,应对复杂模型时,响应延迟和QPS也无法满足实时性和高并发的需求。
此时,客户尝试改用NVIDIA GPU来实现推荐业务的推理服务,有效解决CPU算力和性能的瓶颈的同时,也期待更大的成本优势。经过大量的工程实践,结果表明,单台基于NVIDIA T4 GPU的推理服务器,性能可以等同于24台CPU机器。毋庸置疑, GPU的整体表现皆具有性能和成本的优势。据此,客户也认为使用GPU作为推荐业务场景的推理平台,已成为了公司乃至行业的共识。
应用方案
由于GPU芯片架构的独特性,不经优化的原始TensorFlow模型,很难高效利用GPU的算力。为了解决这个问题,VIVO工程团队投入了大量的人力和时间进行推荐模型优化及转换。而首先着手设计的是TensorRT方案,即是使用NVIDIA推理加速工具TensorRT,结合 Triton的serving方式,以最大化GPU整体收益。
具体来说,把训练导出的TensorFlow模型经过Onnx转换成TensorRT模型,进而使用NVIDIA提供的推理服务框架Triton加载TensorRT模型。业务代码使用VIVO封装Triton的JNI接口,将业务请求输入TensorRT模型去做推理计算。
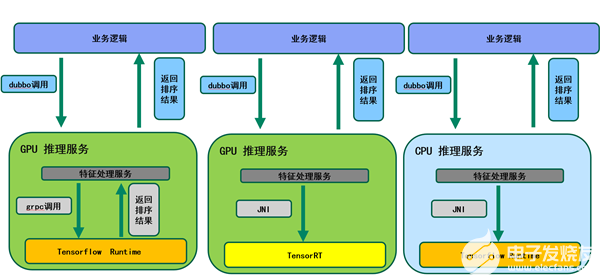
Figure 3. 推荐业务流程图 (图片来源于VIVO研究院授权)
实测结果表明,该方案取得了预期的线上收益。性能方面,单张T4 GPU推理卡,性能优于约6台以上的78核CPU服务器。以如下场景为例,在相同的精排服务请求:QPS为600,BatchSize为3000时,不同方案的成本,TensorRT方案可节省成本约14%:
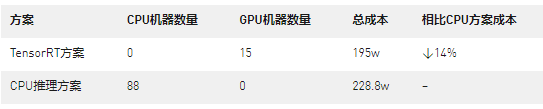
为了进一步提升线上收益,最大化GPU利用率,NVIDIA机器学习团队配合 VIVO继续优化现有效果,探索更多的威廉希尔官方网站 方案可行性。
经过深入探讨,我们发现目前的方案(Triton+TensorRT)确实可以有效利用GPU,但是也存在一些问题。比如很多推荐业务场景,算法模型迭代更新频率高,工程化开发周期无法满足频繁更新的需求。此外,部分推荐模型存在算子不支持的情况,需要手动开发TensorRT plugin,短时间内也无法上线。总体来说,这样的开发流程通用性不够好,也较难有效的支持算法持续迭代。
因此,我们迫切需要实现一套机制,既要保证GPU的推理性能,更要具备良好的通用性。经过多次工程化尝试,我们针对性提出适合自身的推荐系统推理加速方案,即VIVO自研通用GPU方案。
本方案通过多进程 + MPS + TensorFlow runtime的方式,有效的提高了GPU的使用率,且部分场景无需转换TensorRT模型。该方案的主要设计目标是:
多进程模型,管理和守护模型服务进程,有序的更新模型
添加原生TensorFlow中不支持GPU的算子
加载模型时,动态替换原来的不支持GPU的算子
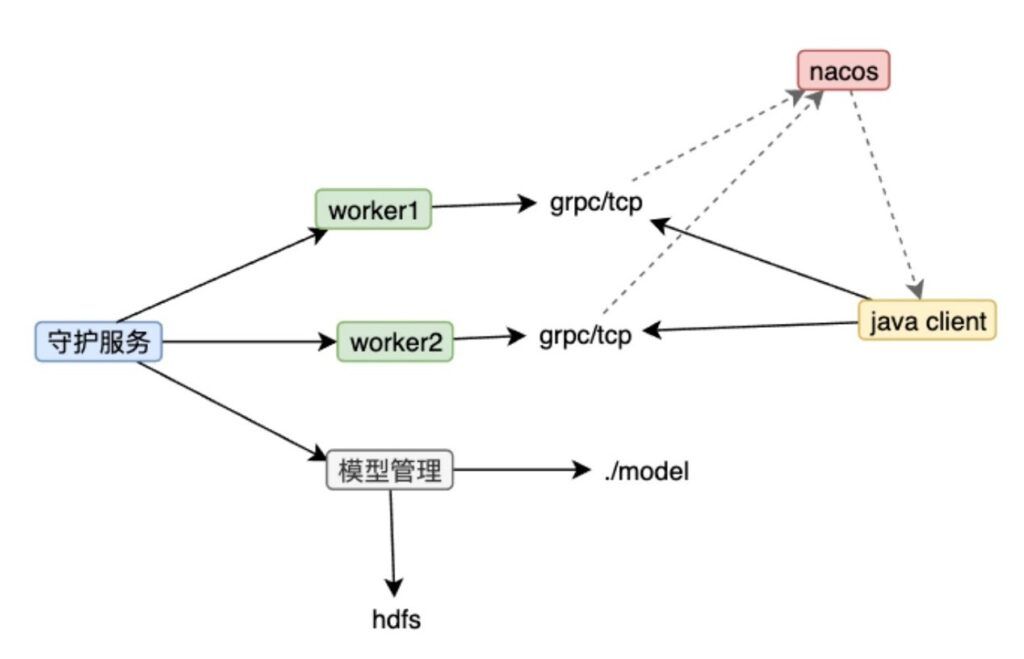
Figure 4. 自研通用GPU方案示意图 (图片来源于VIVO研究院授权)
此外,考虑到具体工程实践中,VIVO算法部门和工程部门需要同步开发,如何解耦算法工程团队和推理加速团队的开发任务,因此推出了可配置的推理引擎服务,加速迭代开发效率。
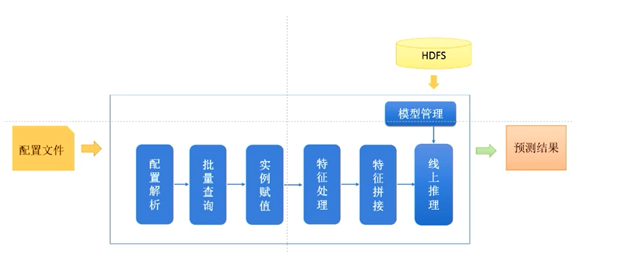
Figure 5. 自研可配置推理引擎示意图 (图片来源于VIVO研究院授权)
方案效果及影响
经过验证,本方案可以有效解决推荐业务中GPU通用性问题;同时能更高效的利用GPU。目前已经在部分推荐业务中落地。经过压测,VIVO自研通用GPU方案,在TensorRT方案基础上,取得了更高的QPS和更低的延迟,可节省成本约75%!
下表详细对比了在相同精排请求:QPS为600,BatchSize为3000时,不同方案的成本。
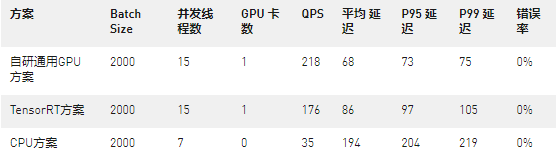
同时,我们测试了负一屏信息流推荐场景,结果同样表明,无论是QPS或是推理延迟(测试选用业界标准P99/P95指标),自研通用GPU方案都优于TensorRT方案和CPU方案。
展望未来,VIVO推荐系统工程团队会继续探索新威廉希尔官方网站 ,持续积累 GPU工程经验,并且沉淀到平台中,最终赋能到各个业务线。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
10859浏览量
211683 -
NVIDIA
+关注
关注
14文章
4985浏览量
103025 -
gpu
+关注
关注
28文章
4735浏览量
128919
发布评论请先 登录
相关推荐
《CST Studio Suite 2024 GPU加速计算指南》
华迅光通AI计算加速800G光模块部署
AMD与NVIDIA GPU优缺点
GPU加速计算平台是什么

NVIDIA突破美国禁令,将在中东部署其高性能AI/HPC GPU加速卡
MathWorks 与 NVIDIA 联手加速医疗威廉希尔官方网站 领域中软件定义工作流的开发
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
NVIDIA加速微软最新的Phi-3 Mini开源语言模型
利用NVIDIA组件提升GPU推理的吞吐
RTX 5880 Ada Generation GPU与RTX™ A6000 GPU对比

NVIDIA数字人威廉希尔官方网站 加速部署生成式AI驱动的游戏角色

Edge Impulse发布新工具,助 NVIDIA 模型大规模部署
NVIDIA将在今年第二季度发布Blackwell架构的新一代GPU加速器“B100”

如何选择NVIDIA GPU和虚拟化软件的组合方案呢?






 工商网监
工商网监
评论