 如何使用NVAPI将DX12资源上传到GPU
如何使用NVAPI将DX12资源上传到GPU
如何通过 PCIe 总线优化从 CPU 到 GPU 的 DX12 资源上传是一个老问题,有许多可能的解决方案,每个解决方案都有其优缺点。在这篇文章中,我将展示如何使用 NVAPI 将 DX12 上传堆移动到 CPU-Visible VRAM ( CVV ),这是一个加速 PCIe 有限工作负载的简单解决方案。
CPU-Visible VRAM :工具箱中的新工具
以顶点缓冲区( VB )上载为例,数据不能跨帧重用。将 VB 上载到 GPU 的最简单方法是直接从 GPU 读取 CPU 内存:
首先,应用程序创建 DX12 UPLOAD 堆或等效的 CUSTOM 堆。 DX12 上传堆分配在系统内存中,也称为 CPU 内存,其中 WRITE_COMBINE ( WC )页面针对 CPU 写入进行了优化。 CPU 首先将 VB 数据写入此系统内存堆。
其次,应用程序使用 IASetVertexBuffers 命令将上载堆中的 VB 绑定到 GPU draw 命令。
在 GPU 中执行绘制时,将启动顶点着色器。接下来,顶点属性提取( VAF )单元通过 GPU 的二级缓存读取 VB 数据,二级缓存本身从存储在系统内存中的 DX12 上载堆加载 VB 数据:

图 1 直接从 DX12 上传堆获取 VB 。
来自系统内存的 L2 访问具有高延迟,因此最好在执行 draw 命令之前通过将数据从系统内存复制到 VRAM 来隐藏该延迟。
从 CPU 到 GPU 的预上载可以通过使用 copy 命令来完成,可以使用 COPY 队列异步完成,也可以在主直接队列上同步完成。
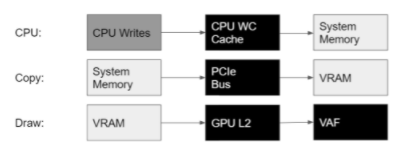
图 2 使用 copy 命令将 VB 预加载到 VRAM
复制引擎可以在复制队列中与其他 GPU 工作同时执行复制命令,并且可以同时使用多个复制队列。但是,使用异步复制队列的一个问题是,您必须注意将队列与 DX12 Fences 同步,这可能很难实现,并且可能会有很大的开销。
在 GTC 2021 的 Nsight Graphics : GPU Trace 的下一级优化建议 会议上,我们宣布 NVIDIA GPU 上 DX12 应用程序的替代解决方案是有效地使用 CPU 线程作为复制引擎。这可以通过使用 NVAPI 在 CVV 中创建 DX12 上载堆来实现。 CPU 然后通过 PCIe 总线将写入此特殊上载堆的数据直接转发到 VRAM (图 3 )。

图 3 在 CPU 线程中使用 CPU 写操作将 VB 预加载到 VRAM
对于 DX12 ,以下 NVAPI 函数可用于查询系统中可用的 CVV 量,并用于分配这种新风格的堆( CPU – 可写 VRAM ,具有快速 CPU 写入和慢速 CPU 读取):
NvAPI_D3D12_QueryCpuVisibleVidmem
NvAPI_D3D12_CreateCommittedResource
NvAPI_D3D12_CreateHeap2
这些新功能需要最新的驱动程序: 466 。 11 或更高版本。
NvAPI_D3D12_QueryCpuVisibleVidmem 应报告以下 CVV 内存量:
使用 Windows 11 (例如,使用 Windows11 内幕预览 )时 NVIDIA RTX 20xx 和 30xx GPU s 的容量为 200-256 MB 。
可调整大小的条_ RTX 30xx GPU s 在 Windows 10 或 Windows 11 中超过 256 MB ,且 NVIDIA 控制面板中的 可调整大小的条_ 报告为 NVIDIA 。有关如何启用可调整大小栏的更多信息,请参阅 GeForce RTX 30 系列通过可调整大小的杆支撑加速性能 。
使用 Nsight Graphics 从 CPU-Visible VRAM 检测并量化 GPU 性能增益机会
NVIDIA NSight 图形 2021 。 3 中的 GPU 跟踪工具可轻松检测 GPU 性能提升机会。启用 高级模式 时, GPU 内的 Analysis 面板将根据预测的帧减少百分比,通过修复此 GPU 工作负载中的特定问题,跟踪帧内的颜色代码 perf 标记。
以下是在 RTX NVIDIA 3080 上,从 看门狗:军团 ( DX12 )预发布版本中选择 Analyze 后的帧的外观:
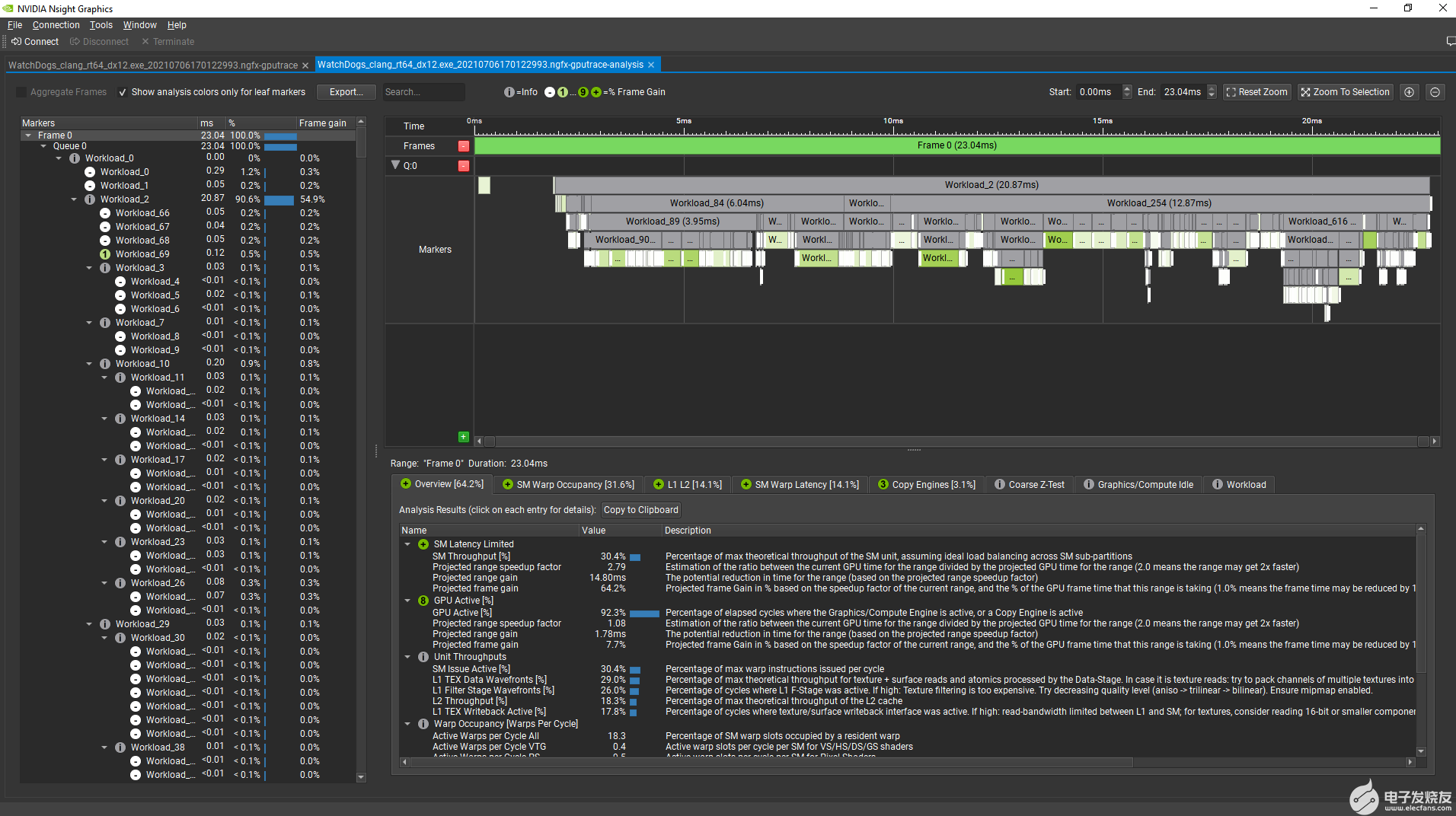
图 4 带有颜色编码 GPU 工作负载的 GPU 跟踪分析工具
(越绿,帧上的预计增益越高)。
现在,选择帧末尾的用户界面绘制命令,分析工具显示,修复 二级未命中到系统内存 性能问题后 GPU 帧时间预计减少 0 。 9% 。该工具还显示,通过二级缓存传输的大多数系统内存流量是由基本引擎请求的,该引擎包括顶点属性获取单元:
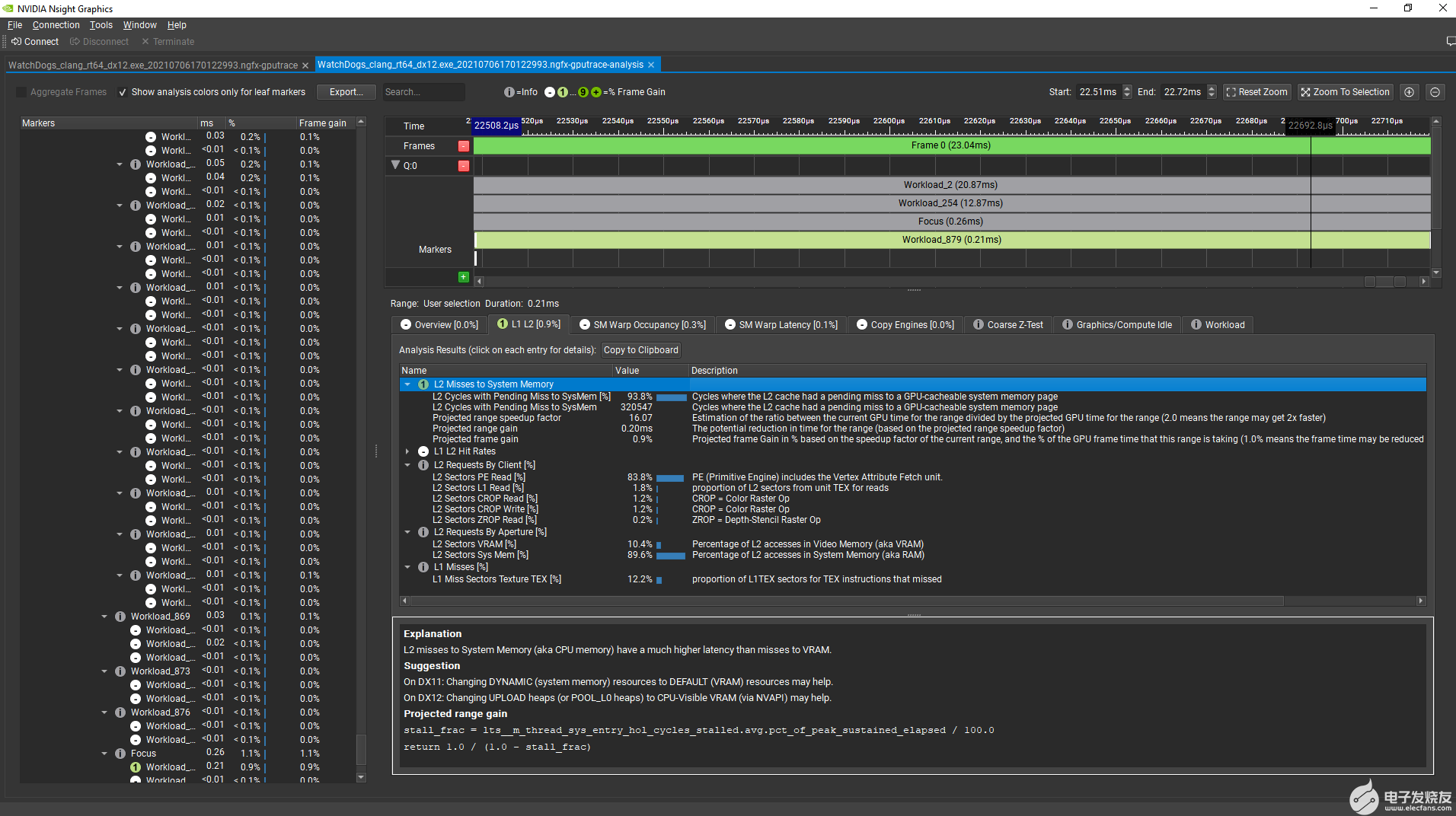
图 5 GPU 跟踪分析工具,关注单个工作负载。
通过在 CVV 中分配此 draw 命令的 VB ,而不是使用常规 DX12 上载堆分配系统内存,此机制的 GPU 时间从 0.2 ms 减少到 0.01 ms 以下。 GPU 帧时间也减少了 0.9% 。在此工作负载中, VB 数据现在直接从 VRAM 获取:

图 6 GPU 跟踪分析工具,在优化了工作负载之后。
使用 Nsight 系统避免 CPU 读取 CPU – 可见 VRAM
CPU 不应读取常规 DX12 上载堆,而应仅将其写入。与常规堆一样, CVV 堆的 CPU 内存页已启用 写合并 。这提供了快速的 CPU 写入性能,但缓慢的非缓存 CPU 读取性能。此外,由于从 CVV 读取 CPU 会通过 PCIe 、 GPU L2 和 VRAM 进行往返,因此从 CVV 读取的延迟远大于从常规 DX12 上载堆读取的延迟。
要检测应用程序 CPU 的性能是否受到来自 CVV 的 CPU 读取的负面影响,并获取 CPU 调用导致这种情况的信息,我建议使用 Nsight 系统 2021.3 。
示例 1 : CVV CPU 读取 ReadFromSubresource
下面是一个在 Nsight 系统跟踪中从 DX12 ReadFromSubresource 读取灾难性 CPU 的示例。为了捕获此跟踪,在获取跟踪时,我在 Nsight 系统项目配置中启用了新的 收集 GPU 指标 选项,以及默认设置,其中包括 样本目标过程 。
以下是 Nsight Systems 在放大一个代表性帧后显示的内容:
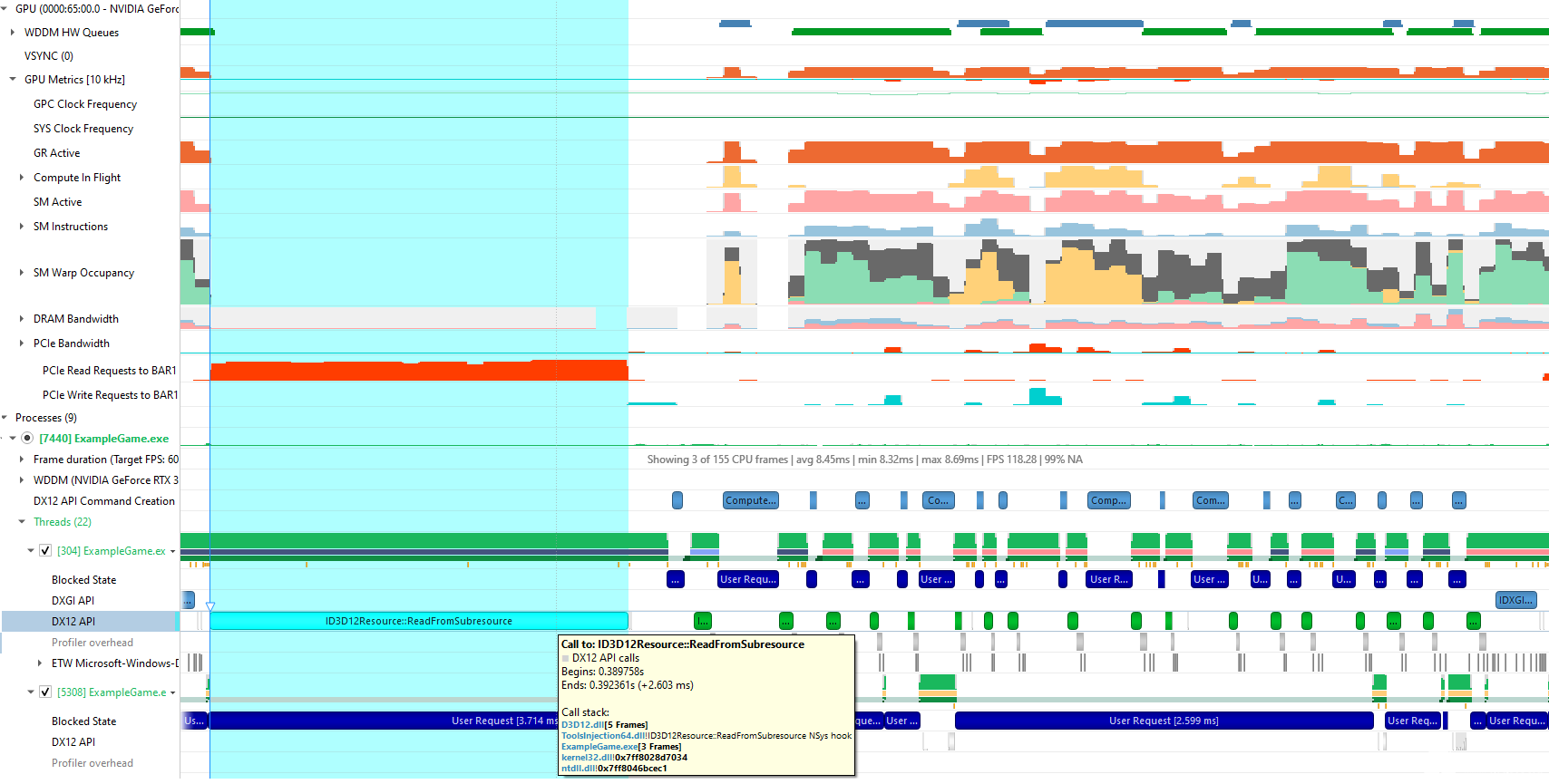
图 7 Nsight 系统显示 2 。 6 ms ReadFromSubresource 调用与来自 BAR1 的高 PCIe 读取请求计数相关的 CPU 线程。
在这种情况下(单个 – GPU 机器), Nsight Systems 中的 对 BAR1 的 PCIe 读取请求 GPU 指标测量发送到 PCIe 的 CPU 读取请求数,以获取 CVV ( BAR1 )中分配的资源。 Nsight Systems 显示 CPU 线程上的长 DX12 ReadFromSubresource 调用与来自 CVV 的大量 PCIe 读取请求之间存在明显的相关性。因此,您可以得出结论,此调用很可能是从 CVV 执行 CPU 回读,并在应用程序中修复此问题。
示例 2 : CVV CPU 从映射指针读取
CPU 从 CVV 读取的数据不限于 DX12 命令。当使用 DX12 资源映射调用返回的任何 CPU 内存指针时,它们可能发生在任何 CPU 线程中。这就是为什么建议使用 Nsight 系统对其进行调试,因为除了选定的 GPU 硬件指标外, Nsight 系统还可以定期对每个 CPU 线程的调用堆栈进行采样。
以下是 Nsight 系统的一个示例,其中显示了从 CVV 进行的 CPU 读取与没有 DX12 API 调用相关,但与 CPU 线程活动开始相关:
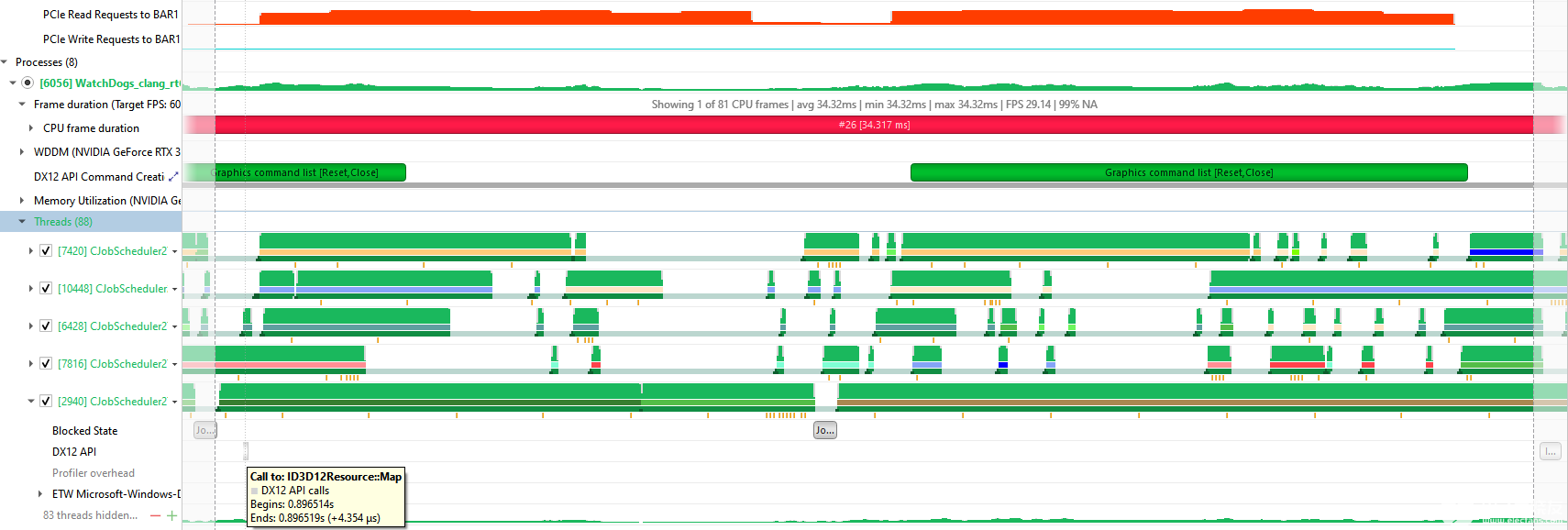
图 8 Nsight Systems 显示了执行映射调用的 CPU 线程与对 BAR1 的 PCIe 读取请求之间的相关性,之后该相关性立即增加。
通过悬停在 CPU 线程下面的橙色采样点,您可以看到该线程正在执行一个名为 RenderCollectedTrees 的 C ++方法,这对查找正在进行 CVV 堆读/写操作的代码是有帮助的:

图 9 Nsight Systems 显示 CPU 线程的调用堆栈采样点,该线程与对 BAR1 的高 PCIe 读取请求相关。
在这种情况下,提高性能的一种方法是对 CPU 内存的单独块执行读/写访问,而不是在 DX12 上载堆中。完成所有读/写更新后,从 CPU 读/写内存向上载堆执行 memcpy 调用。
结论
在 Windows 11 PC 上运行的所有 PC 游戏都可以在 NVIDIA RTX 20xx 和 30xx GPU s 上使用 256 MB 的 CVV 。 NVAPI 可用于查询系统中可用 CVV 内存的总量,并在此空间中分配 DX12 内存。如果 CPU 从未从原始 DX12 上载堆读取数据,则只需更改分配堆的代码即可将 DX12 上载堆替换为 CVV 堆。
要检测将 DX12 上载堆移动到 CVV 时 Nsight 图形 的性能提升机会,建议使用 GPU 中的 GPU 跟踪分析工具。要检测和调试从 CVV 读取 CPU 时的性能损失,我建议在启用 GPU 指标的情况下使用 Nsight 系统 。
关于作者
Louis Bavoil 自 2007 年以来一直在 NVIDIA 的开发者威廉希尔官方网站 小组工作,从事 GPU 性能优化和 GameWorks 软件开发的混合工作,目标是帮助提高 PC 游戏的生产价值。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4985浏览量
103033 -
gpu
+关注
关注
28文章
4736浏览量
128932 -
WINDOWS
+关注
关注
3文章
3544浏览量
88668
发布评论请先 登录
相关推荐
GPU加速云服务器怎么用的
怎么把电表监测到的数据上传平台?

请问各位3256EVM-U通过麦克风采集到的数据能上传到电脑吗?
求助,如何将定制的2级引导加载程序上传到指定的2级引导区?
如何使用httpclient.c中的ESP8266和http_post将文件上传到服务器?
ESP下载工具必须连接到哪个UART才能检测到它并可以将固件上传到它?
ESP32-LyraTD-MSC pipeline_raw_http例子能够跑起来,wav也能上传到服务端,为什么没有声音?
FPGA在深度学习应用中或将取代GPU
DX11游戏抽查测评,2024英特尔锐炫又进步了吗?
性价比拉满!英特尔锐炫新驱动,提升可达418%!

【AWTK开源智能串口屏方案】设计UI界面并上传到串口屏






 工商网监
工商网监
评论