 使用Redis作为分布式锁的详细方案
使用Redis作为分布式锁的详细方案
有人问,使用 Redis 分布式锁的详细方案是什么?
一个很简单的答案就是去使用 Redission 客户端。Redission 中的锁方案就是 Redis 分布式锁的比较完美的详细方案。
那么,Redission 中的锁方案为什么会比较完美呢?
正好,我用 Redis 做分布式锁经验十分丰富。在实际工作中,也探索过许多种使用 Redis 做分布式锁的方案,经过了无数血泪教训。
所以,在谈及 Redission 锁为什么比较完美之前,先给大家看看我曾经使用 Redis 做分布式锁遇到过的问题。
我曾经用 Redis 做分布式锁想去解决一个用户抢优惠券的问题。这个业务需求是这样的:当用户领完一张优惠券后,优惠券的数量必须相应减一;如果优惠券抢光了,就不允许用户再抢了。
在实现时,先从数据库中先读出优惠券的数量进行判断。当优惠券大于 0,就进行允许领取优惠券。然后,再将优惠券数量减一后,写回数据库。
当时由于请求数量比较多,所以我们使用了三台服务器去做分流。
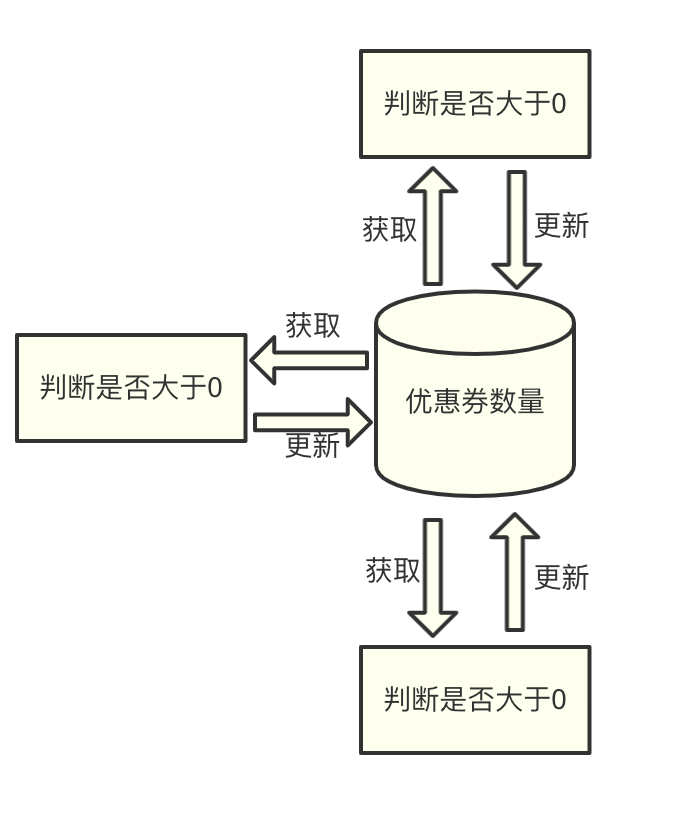
这时候会出现一个问题:
-
如果其中一台服务器上的 A 应用获取到了优惠券的数量之后,由于处理相关业务逻辑未及时更新数据库的优惠券数量;
-
在 A 应用处理业务逻辑的时候,另一台服务器上的B 应用更新了优惠券数量。
-
那么,等 A 应用去更新数据库中优惠券数量时,就会把 B 应用更新的优惠券数量覆盖掉。
看到这里可能有人比较奇怪,为什么这里不直接使用 SQL:
update 优惠券表 set 优惠券数量 = 优惠券数量 - 1 where 优惠券id = xxx
原因是,这样做在没有分布式锁协调下,优惠券数量可能直接会出现负数。
因为当优惠券数量为 1 的时候,如果两个用户通过两台服务器同时发起抢优惠券的请求,都满足优惠券大于 0 的条件,然后都执行这条 SQL 语句,结果优惠券数量直接变成 -1 了。
还有人说可以用乐观锁,比如使用如下 SQL:
update 优惠券表 set 优惠券数量 = 优惠券数量 - 1 where 优惠券id = xxx and version = xx
这种方式就在一定几率下,很可能出现数据一直更新不上导致长时间重试的情况。
所以,经过综合考虑我们就采用了 Redis 分布式锁,通过互斥的方式,以防止多个客户端去同时更新优惠券数量的方案。
当时,我们首先想到的就是使用 Redis 的 setnx 命令,setnx 命令其实就是 set if not exists 的简写。
当 key 设置值成功后,则返回 1,否则就返回 0。所以,这里 setnx 设置成功可以表示成获取到锁,如果失败,则说明已经有锁,可以被视作获取锁失败。
setnx lock true
如果想要释放锁,执行 del 指令,把 key 删除即可。
del lock
利用这个特性,我们就可以让系统在执行优惠券逻辑之前,先去 Redis 中执行 setnx 指令。再根据指令执行结果,去判断是否获取到锁。如果获取到了,就继续执行业务,执行完再使用 del 指令去释放锁。如果没有获取到,就等待一定时间,重新再去获取锁。
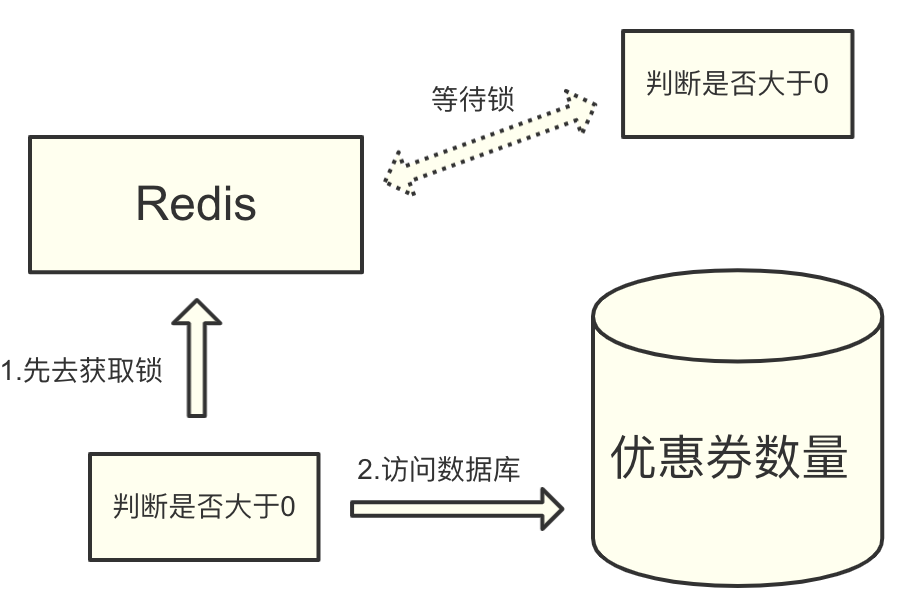
乍一看,这一切没什么问题,使用 setnx 指令确实起到了想要的互斥效果。
但是,这是建立在所有运行环境都是正常的情况下的。一旦运行环境出现了异常,问题就出现了。
试着想一下,持有锁的应用突然崩溃了,或者所在的服务器宕机了,会出现什么情况?
这会造成死锁——持有锁的应用无法释放锁,其他应用根本也没有机会再去获取锁了。这会造成巨大的线上事故。我们要改进方案,解决这个问题。
怎么解决呢?
咱们可以看到,造成死锁的根源是:一旦持有锁的应用出现问题,就不会去释放锁。从这个方向思考,可以在 Redis 上给 key 一个过期时间。
这样的话,即使出现问题,key 也会在一段时间后释放,是不是就解决了这个问题呢?
实际上,大家也确实是这么做的。
不过,由于 setnx 这个指令本身无法设置超时时间,所以一般会采用两种办法来做这件事:
1、采用 lua 脚本
在使用 setnx 指令之后,再使用 expire 命令去给 key 设置过期时间。
if redis.call("SETNX", "lock", "true") == 1 thenlocal expireResult = redis.call("expire", "lock", "10")if expireResult == 1 thenreturn "success"elsereturn "expire failed"endelsereturn "setnx not null"end
2、直接使用 set(key,value,NX,EX,timeout) 指令,同时设置锁和超时时间
redis.call("SET", "lock", "true", "NX", "PX", "10000")
以上两种方法,使用哪种方式都可以。
释放锁的脚本两种方式都一样,直接调用 Redis 的 del 指令即可。
到目前为止,我们的锁既起到了互斥效果,又不会因为某些持有锁的系统出现问题,导致死锁了。
这样就完美了吗?
假设有这样一种情况,如果一个持有锁的应用,其持有的时间超过了我们设定的超时时间会怎样呢?
会出现两种情况:
- 发现系统在 Redis 中设置的 key 还存在;
- 发现系统在 Redis 中设置的 key 不存在。
出现第一种情况比较正常。因为你毕竟执行任务超时了,key 被正常清除也是符合逻辑的。但是最可怕的是第二种情况,发现设置的 key 还存在。这说明什么?说明当前存在的 key,是另外的应用设置的。
这时候如果持有锁超时的应用调用 del 指令去删除锁时,就会把别人设置的锁误删除,这会直接导致系统业务出现问题。
所以,为了解决这个问题,我们需要继续对 Redis 脚本进行改动。
首先,我们要让应用在获取锁的时候,去设置一个只有应用自己知道的独一无二的值。
通过这个唯一值,系统在释放锁的时候,就能识别出这锁是不是自己设置的。如果是自己设置的,就释放锁,也就是删除 key;如果不是,则什么都不做。
脚本如下:
if redis.call("SETNX", "lock", ARGV[1]) == 1 thenlocal expireResult = redis.call("expire", "lock", "10")if expireResult == 1 thenreturn "success"elsereturn "expire failed"endelsereturn "setnx not null"end
或者
redis.call("SET", "lock", ARGV[1], "NX", "PX", "10000")
这里,ARGV[1] 是一个可传入的参数变量,可以传入唯一值。比如一个只有自己知道的 UUID 的值,或者通过雪球算法,生成只有自己持有的唯一 ID。
释放锁的脚本改成这样:
if redis.call("get", "lock") == ARGV[1]thenreturn redis.call("del", "lock")elsereturn 0end
可以看到,从业务角度,无论如何,我们的分布式锁已经可以满足真正的业务需求了。能互斥,不死锁,不会误删除别人的锁,只有自己上的锁,自己可以释放。
一切都是那么美好。
可惜,还有个隐患我们并未排除。这个隐患就是 Redis 自身。
要知道,Lua 脚本都是用在 Redis 的单例上的。一旦 Redis 本身出现了问题,我们的分布式锁就没法用了。分布式锁没法用,对业务的正常运行会造成重大影响,这是我们无法接受的。
所以,我们需要把 Redis 搞成高可用的。一般来讲,解决 Redis 高可用的问题都是使用主从集群。
但是搞主从集群,又会引入新的问题。
主要问题在于,Redis 的主从数据同步有延迟。这种延迟会产生一个边界条件:当主机上的 Redis 已经被人建好了锁,但是锁数据还未同步到从机时,主机宕了。随后,从机提升为主机,此时从机上是没有以前主机设置好的锁数据的——锁丢了。
到这里,终于可以介绍 Redission(开源 Redis 客户端)了,我们来看看它怎么是实现 Redis 分布式锁的。
Redission 实现分布式锁的思想很简单,无论是主从集群还是 Redis Cluster 集群,它会对集群中的每个 Redis,挨个去执行设置 Redis 锁的脚本,也就是集群中的每个 Redis 都会包含设置好的锁数据。
我们通过一个例子来介绍一下。
假设 Redis 集群有 5 台机器,同时根据评估,锁的超时时间设置成 10 秒比较合适。
第 1 步,咱们先算出集群总的等待时间,集群总的等待时间是 5 秒(锁的超时时间 10 秒 / 2)。
第 2 步,用 5 秒除以 5 台机器数量,结果是 1 秒。这个 1 秒是连接每台 Redis 可接受的等待时间。
第 3 步,依次连接 5 台 Redis,并执行 Lua 脚本设置锁,然后再做判断:
- 如果在 5 秒之内,5 台机器都有执行结果,并且半数以上(也就是 3 台)机器设置锁成功,则认为设置锁成功。少于半数机器设置锁成功,则认为失败;
- 如果超过 5 秒,不管几台机器设置锁成功,都认为设置锁失败。比如,前 4 台设置成功一共花了 3 秒,但是最后 1 台机器用了 2 秒也没结果,总的等待时间已经超过了 5 秒,即使半数以上成功,这也算作失败。
再额外多说一句,在很多业务逻辑里,其实对锁的超时时间是没有需求的。比如,凌晨批量执行处理的任务,可能需要分布式锁保证任务不会被重复执行。此时,任务要执行多长时间是不明确的。如果设置分布式锁的超时时间在这里,并没有太大意义。但是,不设置超时时间又会引发死锁问题。
所以,解决这种问题的通用办法是,每个持有锁的客户端都启动一个后台线程,通过执行特定的 Lua 脚本,去不断地刷新 Redis 中的 key 超时时间,使得在任务执行完成前,key 不会被清除掉。
脚本如下:
if redis.call("get", "lock") == ARGV[1]thenreturn redis.call("expire", "lock", "10")elsereturn 0end
其中,ARGV[1] 是可传入的参数变量,表示持有锁的系统的唯一值,也就是只有持有锁的客户端才能刷新 key 的超时时间。
到此为止,一个完整的分布式锁才算实现完毕。总结实现方案如下:
- 使用 set 命令设置锁标记,必须有超时时间,以便客户端崩溃,也可以释放锁;
- 对于不需要超时时间的,需要自己实现一个能不断刷新锁超时时间的线程;
- 每个获取锁的客户端,在 Redis 中设置的 value 必须是独一无二的,以便识别出是由哪个客户端设置的锁;
- 分布式集群中,直接每台机器设置一样的超时时间和锁标记;
- 为了保证集群设置的锁不会因为网络问题导致某些已经设置的锁出现超时的情况,必须合理设置网络等待时间和锁超时时间。
这个分布式锁满足如下四个条件:
- 任意时刻只能有一个客户端持有锁;
- 不能发生死锁,有一个客户端持有锁期间出现了问题没有解锁,也能保证后面别的客户端继续去持有锁;
- 加锁和解锁必须是同一个客户端,客户端自己加的锁只能自己去解;
- 只要大多数 Redis 节点正常,客户端就能正常使用锁。
当然,在 Redission 中的脚本,为了保证锁的可重入,又对 Lua 脚本做了一定的修改,现在把完整的 Lua 脚本贴在下面。
获取锁的 Lua 脚本:
if (redis.call('exists', KEYS[1]) == 0) thenredis.call('hincrby', KEYS[1], ARGV[2], 1);redis.call('pexpire', KEYS[1], ARGV[1]);return nil;end;if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) thenredis.call('hincrby', KEYS[1], ARGV[2], 1);redis.call('pexpire', KEYS[1], ARGV[1]);return nil;end;return redis.call('pttl', KEYS[1]);
对应的刷新锁超时时间的脚本:
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) thenredis.call('pexpire', KEYS[1], ARGV[1]);return 1;end;return 0;
对应的释放锁的脚本:
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) thenreturn nil;end;local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);if (counter > 0) thenredis.call('pexpire', KEYS[1], ARGV[2]);return 0;elseredis.call('del', KEYS[1]);redis.call('publish', KEYS[2], ARGV[1]);return 1;end;return nil;
到现在为止,使用 Redis 作为分布式锁的详细方案就写完了。
我既写了一步一坑的坎坷经历,也写明了各个问题和解决问题的细节,希望大家看完能有所收获。
最后再给大家提个醒,使用 Redis 集群做分布式锁有一定的争议性。还需要大家在实际用的时候,根据现实情况,做出更好的选择和取舍。
原文标题:面试题详解:用 Redis 实现分布式锁的血泪史
文章出处:【微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
-
服务器
+关注
关注
12文章
9129浏览量
85348 -
数据库
+关注
关注
7文章
3795浏览量
64366 -
Redis
+关注
关注
0文章
374浏览量
10871
原文标题:面试题详解:用 Redis 实现分布式锁的血泪史
文章出处:【微信号:LinuxHub,微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论