 插入排序算法的复杂性、性能、分析
插入排序算法的复杂性、性能、分析
算法在数据科学和机器学习领域很常见。算法为社交媒体应用程序、谷歌搜索结果、银行系统等提供动力。因此,数据科学家和 机器学习 实践者在分析、设计和实现算法方面拥有直觉是至关重要的。
当应用于大规模计算任务时,高效算法为公司节省了数百万美元,并减少了内存和能源消耗。本文介绍了一种简单的算法,插入排序。
虽然知道如何实现算法是必不可少的,但本文也包括了数据科学家在选择利用时应该考虑的插入算法的细节。因此,本文提到了算法复杂性、性能、分析、解释和利用等因素。
为什么?
重要的是要记住为什么数据科学家应该在解释和实现之前研究数据结构和算法。
数据科学和 ML 库和包抽象了常用算法的复杂性。此外,由于抽象,需要 100 行代码和一些逻辑推导的算法被简化为简单的方法调用。这并没有放弃数据科学家研究算法开发和数据结构的要求。
当给定一组要使用的预构建算法时,确定哪种算法最适合这种情况需要了解基本算法的参数、性能、限制和鲁棒性。数据科学家可以在分析并在某些情况下重新实现算法后了解所有这些信息。
选择正确的特定于问题的算法和排除算法故障的能力是理解算法的两个最重要的优势。
K-Means 、 BIRCH 和 Mean Shift 都是常用的 clustering 算法,数据科学家决不具备从头开始实施这些算法的知识。尽管如此,数据科学家仍有必要了解每种算法的特性及其对特定数据集的适用性。
例如,基于质心的算法有利于高密度数据集,在这些数据集中可以清楚地定义集群。相反,在处理噪声数据集时,首选基于密度的算法,如 DBSCAN (基于密度的带噪声应用程序空间聚类)。
在排序算法的上下文中,数据科学家遇到了数据湖和数据库,在这些数据湖和数据库中,如果对包含的数据进行排序,则遍历元素以识别关系的效率更高。
识别适用于数据集的库子例程需要了解各种排序算法和首选的数据结构类型。使用数组时,快速排序算法是有利的,但如果数据以链表形式显示,则合并排序的性能更高,尤其是在大数据集的情况下。不过,两者都使用分而治之的策略对数据进行排序。
出身背景
什么是排序算法?
排序问题是数据科学家和其他软件工程师面临的一个众所周知的编程问题。排序问题的主要目的是按升序或降序排列一组对象。排序算法是执行的顺序指令,用于将列表或数组中的元素有效地重新排序为所需的顺序。
分类的目的是什么?
在数据领域中,数据集中元素的结构化组织支持高效遍历和快速查找特定元素或组。在宏观层面上,使用高效算法构建的应用程序转化为引入我们生活的简单性,如导航系统和搜索引擎。
插入排序是什么?
插入排序算法涉及基于列表中每个元素与其相邻元素的迭代比较创建的排序列表。
指向当前元素的索引指示排序的位置。排序开始时(索引= 0 ),将当前值与左侧相邻的值进行比较。如果该值大于当前值,则不修改列表;如果相邻值和当前值是相同的数字,也会出现这种情况。
但是,如果当前值左侧的相邻值较小,则相邻值位置将向左移动,并且仅当其左侧的值较小时才停止向左移动。
该图说明了插入算法在未排序列表上执行的步骤。下图中的列表按升序排列(从低到高)。
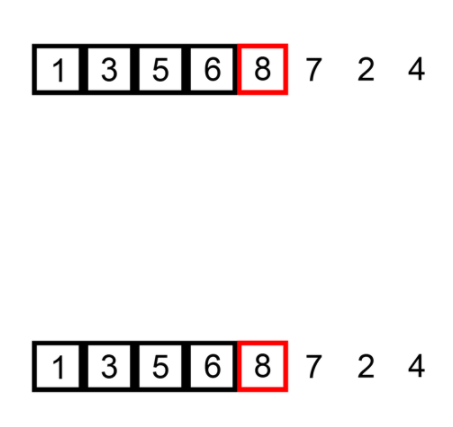
图 1 : GIF 中的插入排序 (此文件在 Creative Commons 下获得许可)。
算法步骤和实现( Python 和 JavaScript )
台阶
要按升序排列元素列表,插入排序算法需要以下操作:
从未排序元素的列表开始。
从第一项到最后一项遍历未排序元素的列表。
在每个步骤中,将当前元素与前面所有位置左侧的元素进行比较。
如果当前元素小于前面列出的任何元素,则将其向左移动一个位置。
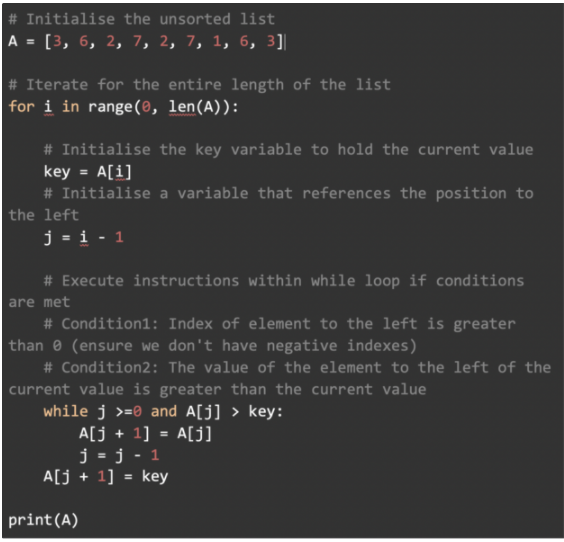
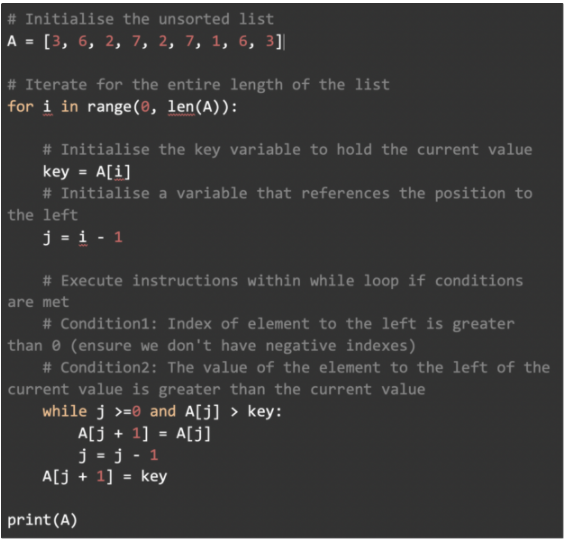
Python 实现
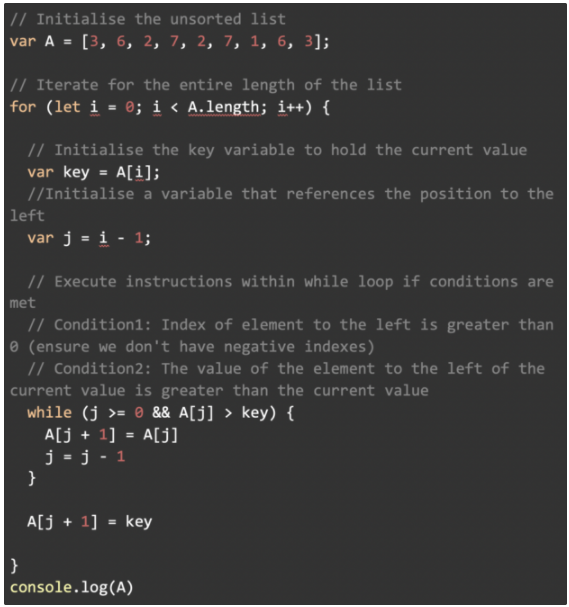
JavaScript 实现
性能和复杂性
在计算机科学领域,“大 O ”表示法是一种测量算法复杂性的策略。在这里,我们不会对大 O 符号太过威廉希尔官方网站 化。不过,值得注意的是,计算机科学家使用这个数学符号来根据时间和空间需求对算法进行量化。
大 O 表示法是根据输入定义的函数。字母“ n ”通常表示函数输入的大小。简单地说, n 表示列表中的元素数。在不同的场景中,实践者关心函数的最坏情况、最佳情况或平均复杂度。
插入排序算法的最坏情况(和平均情况)复杂度为 O ( n ²)。这意味着,在最坏的情况下,对列表进行排序所需的时间与列表中元素数量的平方成正比。
插入排序算法的最佳时间复杂度为 O ( n )时间复杂度。这意味着对列表进行排序所需的时间与列表中元素的数量成正比;当列表的顺序已经正确时,就是这种情况。在这种情况下,只有一次迭代,因为当列表已经有序时,内部循环操作是微不足道的。
插入排序常用于排列小列表。另一方面,插入排序并不是处理包含大量元素的大型列表的最有效方法。值得注意的是,在使用链表时,最好使用插入排序算法。虽然该算法可以应用于数组中结构化的数据,但其他排序算法,如快速排序,也可以应用于其他排序算法。
总结
最简单的排序方法之一是插入排序,它涉及一次一个元素构建一个排序列表。通过将每个未检查的元素插入排序列表中,在小于它和大于它的元素之间进行排序。正如本文所演示的,这是一个简单的算法,可以在多种语言中掌握和应用。
通过清晰地描述插入排序算法,伴随着所涉及的算法程序的逐步分解。数据科学家能够更好地实现插入排序算法,并探索其他类似的排序算法,如快速排序和气泡排序等。
对于许多数据科学家来说,算法可能是一个敏感的话题。这可能是由于主题的复杂性。“算法”一词有时与复杂性有关。有了适当的工具、培训和时间,即使是最复杂的算法,当您有足够的时间、信息和资源时也很容易理解。算法是数据科学中使用的基本工具,不容忽视。
关于作者
Richmond Alake 是一名机器学习和计算机视觉工程师,他与多家初创公司和公司合作,整合深度学习模型,以解决商业应用中的计算机视觉任务。
审核编辑:郭婷
-
计算机
+关注
关注
19文章
7489浏览量
87877 -
机器学习
+关注
关注
66文章
8408浏览量
132580
发布评论请先 登录
相关推荐
芯片的失效性分析与应对方法

集成电路电磁兼容性及应对措施相关分析(一) — 电子系统性能要求与ESD问题
光伏连接器外壳:超越简单塑料的复杂性与重要性

时间复杂度为 O(n^2) 的排序算法

浅谈逻辑分析仪的威廉希尔官方网站 原理和应用领域
为什么电路要设计得这么复杂?
飞凌OK-全志T527开发板nbench性能测试
戴尔科技如何帮助客户克服多云环境的复杂性


FPGA实现双调排序算法的探索与实践

C语言实现经典排序算法概览

解决选择合适安全控制器的复杂性





 工商网监
工商网监
评论