 一种有效的无监督深度表示器(Mix2Vec)
一种有效的无监督深度表示器(Mix2Vec)
摘要
本文由深兰科学院撰写,文章将为大家细致讲解一种有效的无监督深度表示器(Mix2Vec),该方法可将异构数据映射到统一的低维向量空间,避免混合异构数据相似度度量偏差问题。同时,该方法基于深度异构信息网络,采用随机混洗预测学习机制,并融合先验分布匹配和结构信息最大化学习目标,学习混合异构的基于向量空间的通用表示,可以用于无监督和有监督的学习任务。
随着机器学习的发展和广泛应用,(无监督或有监督)表示学习被应用于处理复杂(高维、异构等)特征数据。通过将复杂特征数据映射到统一空间,可以有效避免复杂数据中的差异性,并提供方便有效的数据统一处理(例如:距离度量)。
01问题
混合异构数据中的挑战
现实生活中的大量数据都混合了数值型和类别型属性,这些数据往往表现出以下一些典型特征:(1)数据中一些属性是静态的,而另一些是动态的;(2)某些属性经常存在缺失值,且不同数据的缺失值的稀疏程度不同;(3)数据中可能是异构的,不同的属性可能具有不同的分布和结构;(4)实际数据往往没有足够的可用标记信息并且标记此类数据成本太高,或者标签信息(例如:路径和规划)很难用以模型训练。这些数据特征在企业、制造、商业和医疗保健等典型应用的数据中很常见。图1源自于构造的数据,举例展示了混合异构数据中的上述特征。
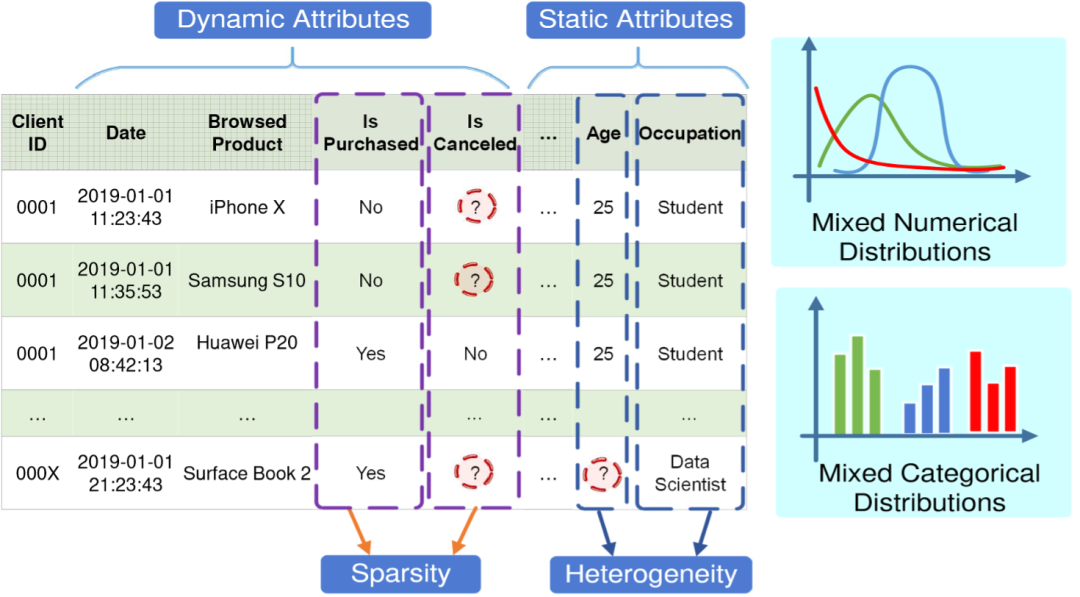
图1 现实生活中混合数据的特征:动态性、稀疏性、异质性
混合数据表示学习主要的挑战是来自多个方面。首先,很难在一个表示模型中处理上述所有特征和学习目标。因为上述每一种数据特征、每一个学习目标在实际中都非常具有挑战性,并且将他们组合在一起会使学习系统非常复杂。因此,现有方法要么将混合数据类型转换为一种类型,要么对于每种数据类型分别学习其向量表示,然后所学的各种类型数据的表示合并作为混合数据的表示。
此外,混合数据可能是静态的,也可能是动态的,并且在结构和分布上呈现出明显的异质性,表示学习在保留原始信息的同时捕获这样的异质性是非常具有挑战性。现有方法通常侧重于单独的解决某一个方面,而不是在一个模型中同时解决上述这些问题。然后,在没有监督信息的情况下,确定哪些信息应考虑到表示中以及验证生成的表示是否有效则都具有一定挑战性。
最后,数据本身的质量(缺失值)以及其他包括稀疏性、属性冗余和互补性在内的其他问题进一步增加了完成上述表示学习任务的难度,而现有的研究往往只是处理上述问题中的单个问题。
02动机
混合异构数据表示学习的空缺
通过调研现阶段表示学习的文献资料,可知目前没有一种表示学习方法可以同时解决上述的无监督混合数据表示中挑战。现有方法可以根据其学习目标分为基于下游任务的方法,自我监督的方法和基于重构的方法:
1基于下游任务的方法是学习一种数据表示,以最大化在特定学习任务的学习目标(例如,软聚类)。此类方法学习的表示是为提升特定模型的学习性能而定制的,但往往很难迁移到其他模型和任务上。
2自我监督方法需要在数据中指定特定的关系(例如,相同上下文中的对象相似)以学习数据表示,并且用于表示学习的监督信息是针对单个数据类型、特定域(例如,自然语言处理)和假设(例如,时间一致性),使得这些方法很难应用于混合数据表示学习中。
3基于重构的方法最大化了原始输入及其对应表示之间的相互信息性,以保留与原始输入中足够多的信息。然而,信息保存并不一定能够保证表示质量,而且现有的基于重建的方法集中于研究数值型数据(例如,图像和视频),数值型数据中两个值之间的距离有特定的语义含义(例如,图像中的值的大小的表示更暗或更亮)来体现。对于基于重构的方法来说,很难重建混合数据,因为混合数据中可能存在各种语义含义,甚至有些没有特定的语义含义。
03方法
混合异构数据表示学习的目标和机制
以下将介绍一种新的混合数据表示学习器Mix2Vec:尝试解决上文中所提到的数据特点和学习挑战,旨在通过构建功能强大的混合数据表示器来学习多方面无监督混合数据表示。该表示器具有多种机制来应对上述数据特征和表示学习中的挑战。
Mix2Vec采用以下三种机制来实现上述多方面目标:
1采用随机混洗预测对输入数据进行随机的变换,并最大化原始数据的表示和经过混洗后数据的表示之间的互信息性。
2采用估计分布匹配的方法来将原始输入分布中的先验知识嵌入到学习的表示中。
3采用结构信息增强的方法来使表示中的结构信息量最大化。
这些机制将同时在深层神经表示器Mix2Vec实现,如此一来,Mix2Vec可以有效地将具有上述各种特征的混合数据转换为基于向量空间的表示形式。这种学习的表示形式是通用的,并且对于不同的学习任务是透明且可复用的。
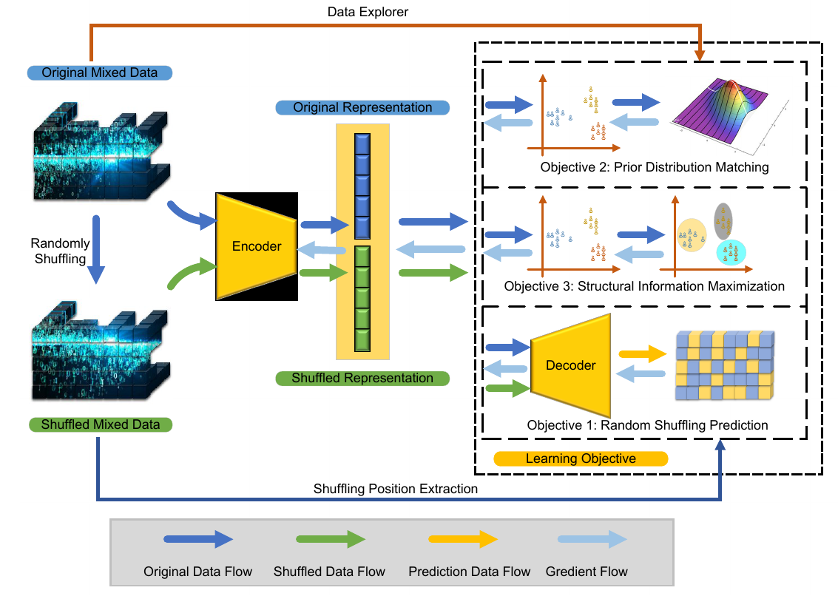
图2 Mix2Vec学习机制
给定混合数据的输入,无监督表示学习将学习一种映射函数,在无监督的情况下以将混合输入转换为连续表示。假定X和Y分别为混合数据原始输入空间和连续表示空间,无监督学习的任务是学习一系列可微分参数方程。对于Mixe2Vec而言,给定来自原始输入空间的n个样本,即,需要学习一个编码器来实现以下三个目标:
01互信息最大化(Mutual Information Maximization)
最大化输入及其表示之间的互信息,在Mix2Vec中通过随机混洗预测(Random Shuffling Prediction,RSP)目标机制来实现;
02先验分布匹配(Prior Distribution Matching,PDM)
强制数据表示的分布匹配某一先验分布,使得学习的数据表示具有所需的特征;
03结构信息量最大化(Structural Informativeness Maximization,SIM)
最大化表示中的结构信息量,这是对上述目标的补充,有利于从原始输入中保留结构信息。
图2显示了Mix2Vec表示学习的工作流程,其中展示了上述待实现的三个目标以及为不同目标实现的机制。对于目标1,本工作中将原始输入随机混洗变成为新输入,并且将原始输入和对应混洗后的输入都编码为其对应的数据表示,而后通过解码器从原始输入和对应的混洗后输入的数据表示中预测混洗位置(属性);对于目标2,基于从输入中获得的先验知识,将从原始输入编码的数据表示的分布与先验分布相匹配;最后,对于目标3,最大化学习到数据表示的结构信息。将上述三个目标组合起来构成Mix2Vec整体的学习目标和机制,共同指导混合异构数据的表示学习。
04验证
Mix2Vec学习效果
通过可视化包括Mix2Vec及其变体(不同的超参数)在内的所有表示器所学到的数据表示,以显示学习到的数据表示的可分离性。为了将数据集所学到的表示可视化为二维空间,实验中引入了t分布的随机邻居嵌入可视化法方法,将高维表示向量转换为二维表示向量。
实验中,为每个数据集随机抽取600个这些二维向量,并在图3中展示它们的位置,图3展示在Churn上的可视化效果。
从图中结果可知,Mix2Vec可以生成包含更多信息的高度结构化表示,从单个目标的可视化效果来看,RSP擅长捕获单个信息,PDM提供先验匹配,SIM突出结构表示,符合Mix2Vec在设置之初融合三个目标的原因。
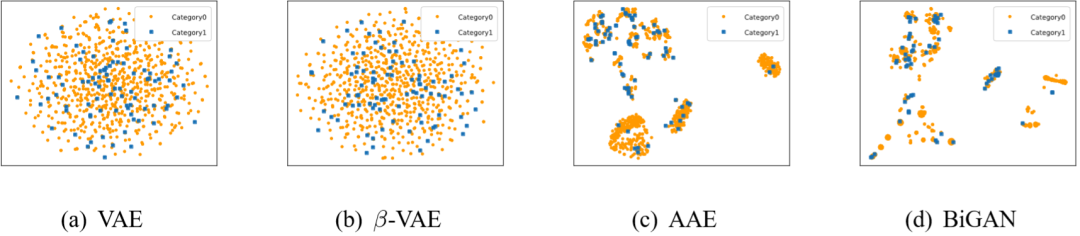
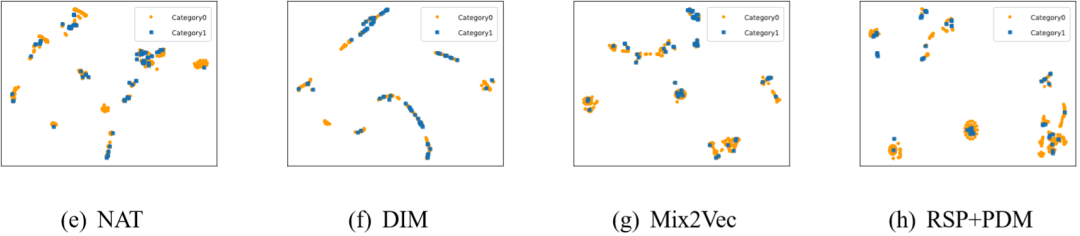
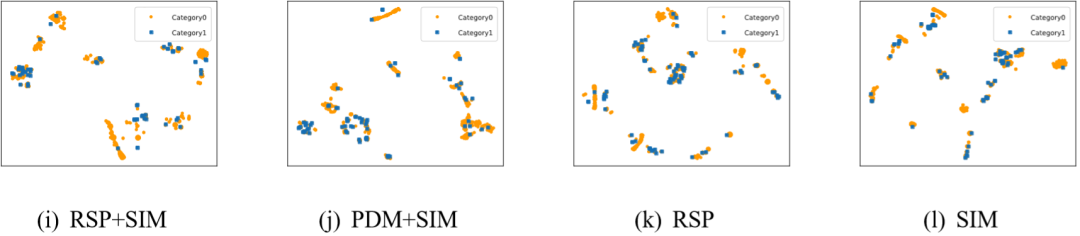
图3 Mix2Vec在Churn上数据表示的结果可视化
05结论
在现实世界中,以无监督的方式进行混合异构数据表示是非常苛刻的挑战。该工作中针对具有稀疏性、动态性和异构性等复杂特征的混合数据,引入了一种有效的无监督表示方法Mix2Vec。Mix2Vec通过预测输入的随机混洗操作,将数据表示的分布与输入分布匹配,并增强数据表示中的结构信息。Mix2Vec可以生成复杂的混合数据的通用且可重复使用的数据表示,以满足多个方面的目标,包括解决上述混合数据的特征、支持信息表示质量以及实现不同学习任务的更好学习性能。
下一期将介绍Mix2Vec每个机制具体实现方法,以及Mix2Vec在不同下游任务上的性能。
请继续关注此频道以获取最新的研究成果!
原文标题:威廉希尔官方网站 冲击波| 异构数据的无监督表示学习(一)
文章出处:【微信公众号:DeepBlue深兰科技】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
数据
+关注
关注
8文章
7006浏览量
88955 -
模型
+关注
关注
1文章
3229浏览量
48813 -
机器学习
+关注
关注
66文章
8408浏览量
132576 -
深兰科技
+关注
关注
1文章
55浏览量
5959
原文标题:威廉希尔官方网站 冲击波| 异构数据的无监督表示学习(一)
文章出处:【微信号:kmdian,微信公众号:深兰科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
时空引导下的时间序列自监督学习框架

一种基于深度学习的二维拉曼光谱算法

JK触发器是一种什么稳态电路
边沿式d触发器是一种什么稳态电路
一种供电总线威廉希尔官方网站 POWERBUS二总线
一种无透镜成像的新方法

为什么深度睡眠期间RTC定时器会丢失呢?
基于FPGA的类脑计算平台 —PYNQ 集群的无监督图像识别类脑计算系统
无监督深度学习实现单次非相干全息3D成像






 工商网监
工商网监
评论