 如何使用BERT模型进行抽取式摘要
如何使用BERT模型进行抽取式摘要
写在前面
paper:https://arxiv.org/pdf/1903.10318.pdf
github:https://github.com/nlpyang/BertSum
后面,又发表于EMNLP2019,为《Text Summarization with Pretrained Encoders》,增加了生成式(抽象式,Abstractive)摘要部分,并对第一版论文进行了部分内容的补充与删减。
paper:https://aclanthology.org/D19-1387.pdf
github:https://github.com/nlpyang/PreSumm
介绍
文本摘要任务主要分为抽象式摘要(abstractive summarization)和抽取式摘要(extractive summarization)。在抽象式摘要中,目标摘要所包含的词或短语会不在原文中,通常需要进行文本重写等操作进行生成;而抽取式摘要,就是通过复制和重组文档中最重要的内容(一般为句子)来形成摘要。那么如何获取并选择文档中重要句子,就是抽取式摘要的关键。
传统抽取式摘要方法包括Lead-3和TextRank,传统深度学习方法一般采用LSTM或GRU模型进行重要句子的判断与选择,而本文采用预训练语言模型BERT进行抽取式摘要。
模型结构BertSum模型
结构如下图所示
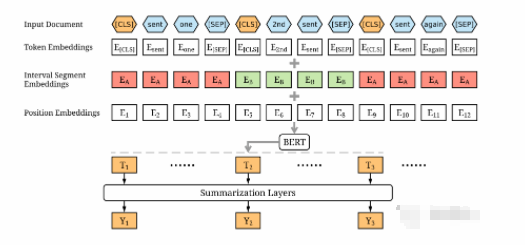
主要由句子编码层和摘要判断层组成,其中,「句子编码层」通过BERT模型获取文档中每个句子的句向量编码,「摘要判断层」通过三种不同的结构进行选择判断,为每个句子进行打分,最终选取最优的top-n个句子作为文档摘要。
句子编码层
由于BERT模型MLM预训练机制,使得其输出向量为每个token的向量;即使分隔符可以区分输入的不同句子,但是仅有两个标签(句子A或句子B),与抽取式摘要需要分隔多个句子大不相同;因此对BERT模型的输入进行了修改,如下:
将文档中的每个句子前后均插入[CLS]和[SEP]标记,并将每个句子前的[CLS]标记进入模型后的输出向量,作为该句子的句向量表征。例如:文档为”我爱南京。我喜欢NLP。我学习摘要。“,输入序列为”[CLS]我爱南京。[SEP][CLS]我喜欢NLP。[SEP][CLS]我学习摘要。[SEP]“
采用Segment Embeddings区分文档中的多个句子,将奇数句子和偶数句子的Segment Embeddings分别设置为和,例如:文档为,那么Segment Embeddings为。
摘要判断层
从句子编码层获取文档中每个句子的句向量后,构建了3种摘要判断层,以通过获取每个句子在文档级特征下的重要性。对于每个句子,计算出最终的预测分数,模型的损失是相对于金标签的二元交叉熵。
Simple Classifier,仅在BERT输出上添加一个线性全连接层,并使用一个sigmoid函数获得预测分数,如下:
Transformer,在BERT输出后增加额外的Transformer层,进一步提取专注于摘要任务的文档级特征,如下:
其中,为句子的句向量,,PosEmb函数为在句向量中增加位置信息函数,MHAtt函数为多头注意力函数,为Transformer的层数。最后仍然接一个sigmoid函数的全连接层,
最终选择为2。
LSTM,在BERT输出增加额外的LSTM层,进一步提取专注于摘要任务的文档级特征,如下:
其中,分别为遗忘门、输入门和输出门;分别为隐藏向量、记忆向量和输出向量;分别为不同的layer normalization操作。最后仍然接一个sigmoid函数的全连接层,
实验细节训练集构建
由于目前文本摘要的数据大多为抽象式文本摘要数据集,不适合训练抽取摘要模型。论文利用贪心算法构建每个文档抽取式摘要对应的句子集合,即通过算法贪婪地选择能使ROUGE分数最大化的句子集合。将选中的句子集合中的句子的标签设为1,其余的句子为0。
模型预测
在模型预测阶段,将文档按照句子进行切分,采用BertSum模型获取每个句子的得分,然后根据分数从高到低对这些句子进行排序,并选择前3个句子作为摘要。
在句子选择阶段,采用Trigram Blocking机制来减少摘要的冗余,即对应当前已组成摘要S和侯选句子c,如果S和c直接存在tri-gram相同片段,则跳过句子c,也就是句子c不会增加在已组成摘要S中。
数据超出BERT限制
BERT模型由于最大长度为512,而现实中文档长度常常会超出。在《Text Summarization with Pretrained Encoders》文中提到,在BERT模型中添加更多的位置嵌入来克服这个限制,并且位置嵌入是随机初始化的,并在训练时与其他参数同时进行微调。
实验结果主要对比了LEAD、REFRESH、NEUSUM、PGN以及DCA方法,较当时方法,该论文效果确实不错,如下表所示,
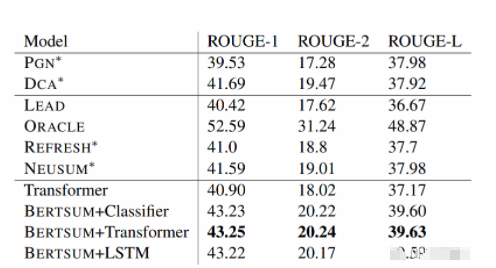
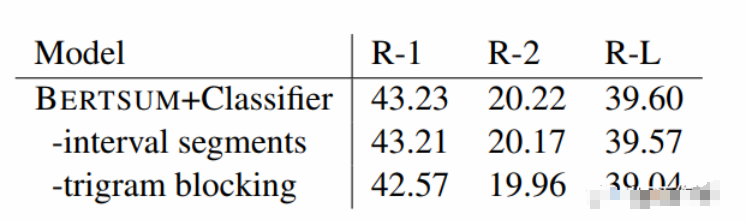
在三种摘要判断层中,Transformer的效果最优。并且进行了进一步的消融实验,发现采用不同的Segment Embeddings会给结果带来一些提升,但是Trigram Blocking机制更为关键,具体如下表所示。
总结个人认为该论文是一篇较为经典的BERT模型应用论文,当时2019年看的时候就进行了尝试,并且也将其用到了一些项目中。
放假ing,但是也要学习。
原文标题:BertSum-基于BERT模型的抽取式文本摘要
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
结构
+关注
关注
1文章
117浏览量
21593 -
函数
+关注
关注
3文章
4329浏览量
62576 -
模型
+关注
关注
1文章
3229浏览量
48813
原文标题:BertSum-基于BERT模型的抽取式文本摘要
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
自动识别事件类别的中文事件抽取威廉希尔官方网站 研究
基于XML的WEB信息抽取模型设计
BERT模型的PyTorch实现
简述基于神经网络的抽取式摘要方法
图解BERT预训练模型!
模型NLP事件抽取方法总结

NLP:关系抽取到底在乎什么
融合BERT词向量与TextRank的关键词抽取方法
抽取式摘要方法中如何合理设置抽取单元?
基于BERT+Bo-LSTM+Attention的病历短文分类模型

基于BERT的中文科技NLP预训练模型
基于Zero-Shot的多语言抽取式文本摘要模型
Instruct-UIE:信息抽取统一大模型






 工商网监
工商网监
评论