 如何利用立体视觉实现距离估计?
如何利用立体视觉实现距离估计?
/ 导读 /
双目立体视觉(Binocular Stereo Vision)是机器视觉的一种重要形式,它是基于视差原理并利用成像设备从不同的位置获取被测物体的两幅图像,通过计算图像对应点间的位置偏差,来获取物体三维几何信息的方法。
1伪激光雷达-双目立体相机
深度学习和计算机视觉在自动驾驶系统中已经非常流行且被广泛应用。计算机视觉领域在过去的十年里得到了迅猛的发展,特别是在障碍物检测方面。障碍物检测算法,如YOLO或RetinaNet提供了二维边界框,用边界框给出了障碍物在图像中的位置。
目前,大多数的目标检测算法都是基于单目RGB摄像机的,不能返回每个障碍物的距离。为了能够返回每个障碍物的距离,工程师们将相机与激光雷达(LiDAR,光探测和测距)传感器进行融合,后者使用激光来返回深度信息。将计算机视觉信息和激光雷达输出进行传感器的融合。这种方法的问题是使用激光雷达,就会导致价格昂贵。所以经常有人使用的一个双目摄像头进行替代,并使用几何信息来定义每个障碍物的距离,故可以将双目相机获取的数据称之为伪激光雷达
双目视觉利用几何学来构建深度图,并将其与目标检测相结合以获得三维距离。那么如何利用立体视觉实现距离估计?以下是双目障碍物检测的5步伪代码:
标定 2 个摄像头(内外参的标定)
创建极线约束
先构建视差图,然后构建深度图
然后将深度图与障碍物检测算法相结合
估计边界框内像素的深度。
2相机内外参标定
每个摄像机都需要标定。相机的标定是指将三维世界中的[X,Y,Z]坐标的三维点转换为具有[X,Y]坐标的二维像素。这里简单的介绍一下针孔相机模型。顾名思义就是用一个针孔让少量光线穿过相机,从而得到清晰的图像。
针孔相机模型可以设置焦距,使得图像更加的清晰。为了相机标定,我们需要通过摄像机坐标系计算世界坐标点到像素坐标的变换关系。
从世界坐标系到相机坐标的转换称为外参标定,外部参数称为R(旋转矩阵)和T(平移矩阵)。
从摄像机坐标到像素坐标的转换称为内参标定,它获取的是相机的内部参数,如焦距、光心等…
内参我们常称之为K的矩阵。
内参标定,通常使用棋盘和自动算法获得,如下图我们在采集标定板时,将告诉算法棋盘上的一个点(例如世界坐标系点 0, 0 , 0)对应于图像中的一个像素为(545,343)。
为此,相机标定必须用摄像机拍摄棋盘格的图像,在得到一些图像和对应的点之后,标定算法将通过最小化平方误差来确定摄像机的标定矩阵。得到标定参数后为了得到校正后的图像,需要进行畸变校正。畸变可以是径向的,也可以是切向的。畸变校正有助于消除图像失真。
以下是摄像机标定返回的矩阵形式
f是焦距-(u₀,v₀) 是光学中心:这些是固有参数。
我认为每一个计算机视觉工程师都应该必须知道并掌握相机的标定,这是最基本且重要的要求。
在相机标定的过程中涉及到一些齐次坐标转换的问题,这里简单的介绍一下有两个公式可以得到从世界坐标系到像素坐标系的关系:
(1)世界坐标系到相机坐标系的转换(外参标定公式)
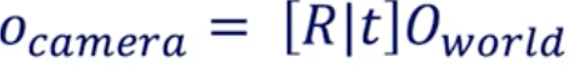
(2)相机坐标系到图像坐标系的转换(内参标定公式)
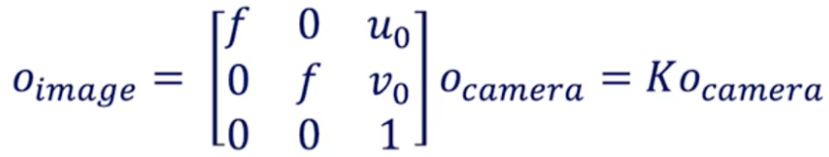
所以从三维空间坐标系到图像坐标系下的关系可以总结为
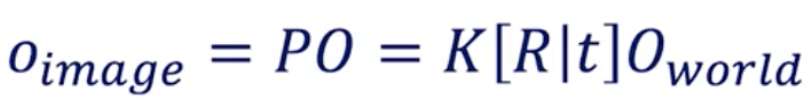
但是我们知道这个公式是齐次坐标才可以这么写,也就是需要将O_world从[X Y Z]修改为[X Y Z 1],加这个“1”后称为齐次坐标。
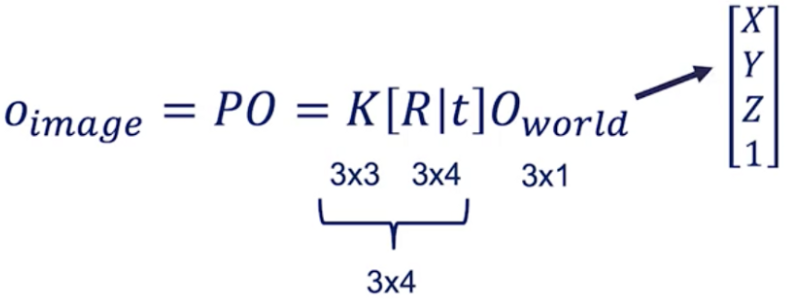
3双目视觉的对极几何
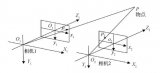
我们知道双目立体视觉是基于两幅图像来寻找深度的,人类的眼睛就像两个相机,因为两只眼睛从不同的角度观察图像,所以他们可以计算两个视角之间的差异,并建立距离估计。下图是一个双目立体相机的例子
那么我们如何根据双目立体相机如何估计深度?想象一下你有两个摄像头,一个左摄像头和一个右摄像头。这两个摄像头在同一Y轴和Z轴上对齐。那么唯一的区别是它们的X值。
根据上图我们的目标是估计O点(代表图像中的任何像素)的Z值,即距离。X是对齐轴,Y是高度值,Z是深度值,两个蓝色的平面图对应于每个摄像头的图像。假设我们从从俯视的角度来考虑这个问题。
已知:
(1)xL对应于左侧相机图像中的点。xR是与左侧图像中该点的对应位置。(2)b是基线,是两个摄像头之间的距离。
针对左相机,如下图,我们可以得到一个公式:Z = X*f / xL.
针对右相机,如下图,我们可以得到另一个公式:Z = (X — b)*f/xR.
此时根据两个公式我们可以计算出正确的视差d=xL-xR和一个物体的正确XYZ位置。
4视差和深度图
什么是视差?视差是指同一个三维点在两个不同的摄像机角度获得的图像中位置的差异。视差图是指一对立体图像之间明显的像素差异或运动。要体验这一点,试着闭上你的一只眼睛,然后快速地闭上它,同时打开另一只眼睛。离你很近的物体看起来会跳一段很长的距离,而离你较远的物体移动很少,这种运动就是视差。
由于立体视觉,我们可以估计任何物体的深度,假设我们得到了正确的矩阵参数,则可以计算深度图或视差图:
为了计算视差,我们必须从左边的图像中找到每个像素,并将其与右边图像中的每个像素进行匹配。这就是所谓的双目相机的立体匹配的问题。为了解决像素匹配的问题,引入对极几何约束,只需在对极线上搜索它,就不需要二维搜索,对应点一定是位于这条线上,搜索范围缩小到一维。
之所以能够引入对极约束,这是因为两个相机是沿同一轴对齐的。以下是极线搜索的工作原理:
取左图中这一行上的每个像素
在同一极线上比较左图像像素和右图像中的每个像素
选择 cost 最低的像素
计算视差 d
5构建伪激光雷达效果
现在,是时候把这些应用到一个真实的场景中,看看我们如何使用双目立体视觉来估计物体的深度。假设我们有以下两张实际场景下的图片,并且我们我们已经获取了双目相机的外参矩阵。
此时我们计算视差图的步骤。将投影矩阵分解为摄像机内参矩阵
编辑:jq
-
RGB
+关注
关注
4文章
798浏览量
58497 -
计算机视觉
+关注
关注
8文章
1698浏览量
45993 -
深度学习
+关注
关注
73文章
5503浏览量
121152 -
自动驾驶系统
+关注
关注
0文章
65浏览量
6766
原文标题:自动驾驶汽车的伪激光雷达-双目立体视觉
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
产品快讯 | Teledyne FLIR IIS发布最新产品信息

有实现过利用ads1292短距离测量心电信号的吗?这种想法可行吗?
建筑物边缘感知和边缘融合的多视图立体三维重建方法

TLV320ADC3101如何实现立体声-双声道
立体视觉新手必看:英特尔® 实感™ D421深度相机模组

居然还有这样的10.1寸光场裸眼3D视觉训练平板电脑?

机器视觉的应用流程是如何实现的
新品 | Bumblebee X系列用于高精度机器人应用的新型立体视觉产品
Teledyne FLIR IIS推出一款用于高精度机器人的新型立体视觉产品
一文读懂双眼立体显示威廉希尔官方网站 四种主流立体显示威廉希尔官方网站 介绍
银牛微电子3D视觉感知方案赋能小米CyberDog系列仿生四足机器人
通过视觉助手检测PCB板金手指插入到位距离和判断插针歪斜
总投资1.5亿!苏州清研微视立体视觉传感器项目落户安徽芜湖

三维视觉测量威廉希尔官方网站 :被动视觉测量和主动视觉测量
双目立体视觉是什么样的威廉希尔官方网站 ?





 工商网监
工商网监
评论